

Apache Flink 社区迎来了激动人心的两位数位版本号,Flink 1.10.0 正式宣告发布!作为 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。
Flink 1.10 同时还标志着对 Blink[1] 的整合宣告完成,随着对 Hive 的生产级别集成及对 TPC-DS 的全面覆盖,Flink 在增强流式 SQL 处理能力的同时也具备了成熟的批处理能力。本篇博客将对此次版本升级中的主要新特性及优化、值得注意的重要变化以及使用新版本的预期效果逐一进行介绍。
官网下载链接:
https://flink.apache.org/downloads.html
新版本的二进制发布包和源码包已经可以在最新的 Flink 官网下载页面[2]找到。更多细节请参考完整的版本更新日志[3]以及最新的用户文档[4]。欢迎您下载试用此版本,并将您的反馈意见通过 Flink 邮件列表[5]或 JIRA[6] 与社区分享。
新特性及优化
内存管理及配置优化
Flink 目前的 TaskExecutor 内存模型存在着一些缺陷,导致优化资源利用率比较困难,例如:
流和批处理内存占用的配置模型不同;
流处理中的 RocksDB state backend 需要依赖用户进行复杂的配置。
为了让内存配置变的对于用户更加清晰、直观,Flink 1.10 对 TaskExecutor 的内存模型和配置逻辑进行了较大的改动 (FLIP-49 [7])。这些改动使得 Flink 能够更好地适配所有部署环境(例如 Kubernetes, Yarn, Mesos),让用户能够更加严格的控制其内存开销。
■ Managed 内存扩展
Managed 内存的范围有所扩展,还涵盖了 RocksDB state backend 使用的内存。尽管批处理作业既可以使用堆内内存也可以使用堆外内存,使用 RocksDB state backend 的流处理作业却只能利用堆外内存。因此为了让用户执行流和批处理作业时无需更改集群的配置,我们规定从现在起 managed 内存只能在堆外。
■ 简化 RocksDB 配置
此前,配置像 RocksDB 这样的堆外 state backend 需要进行大量的手动调试,例如减小 JVM 堆空间、设置 Flink 使用堆外内存等。现在,Flink 的开箱配置即可支持这一切,且只需要简单地改变 managed 内存的大小即可调整 RocksDB state backend 的内存预算。
另一个重要的优化是,Flink 现在可以限制 RocksDB 的 native 内存占用(FLINK-7289 [8]),以避免超过总的内存预算——这对于 Kubernetes 等容器化部署环境尤为重要。关于如何开启、调试该特性,请参考 RocksDB 调试[9]。
注:FLIP-49 改变了集群的资源配置过程,因此从以前的 Flink 版本升级时可能需要对集群配置进行调整。详细的变更日志及调试指南请参考文档[10]。
统一的作业提交逻辑
在此之前,提交作业是由执行环境负责的,且与不同的部署目标(例如 Yarn, Kubernetes, Mesos)紧密相关。这导致用户需要针对不同环境保留多套配置,增加了管理的成本。
在 Flink 1.10 中,作业提交逻辑被抽象到了通用的 Executor 接口(FLIP-73 [11])。新增加的 ExecutorCLI (FLIP-81 [12])引入了为任意执行目标[13]指定配置参数的统一方法。此外,随着引入 JobClient(FLINK-74 [14])负责获取 JobExecutionResult,获取作业执行结果的逻辑也得以与作业提交解耦。
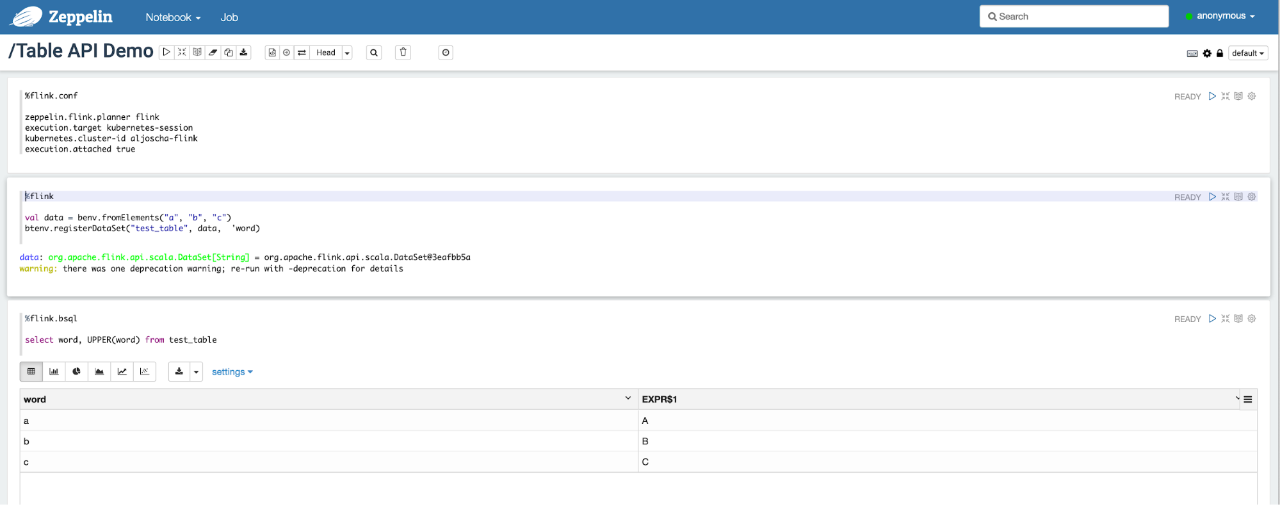
上述改变向用户提供了统一的 Flink 入口,使得在 Apache Beam 或 Zeppelin notebooks 等下游框架中以编程方式使用 Flink 变的更加容易。对于需要在多种不同环境使用 Flink 的用户而言,新的基于配置的执行过程同样显著降低了冗余代码量以及维护开销。
原生 Kubernetes 集成(Beta)
对于想要在容器化环境中尝试 Flink 的用户来说,想要在 Kubernetes 上部署和管理一个 Flink standalone 集群,首先需要对容器、算子及像 kubectl 这样的环境工具有所了解。
在 Flink 1.10 中,我们推出了初步的支持 session 模式的主动 Kubernetes 集成(FLINK-9953 [15])。其中,“主动”指 Flink ResourceManager (K8sResMngr) 原生地与 Kubernetes 通信,像 Flink 在 Yarn 和 Mesos 上一样按需申请 pod。用户可以利用 namespace,在多租户环境中以较少的资源开销启动 Flink。这需要用户提前配置好 RBAC 角色和有足够权限的服务账号。
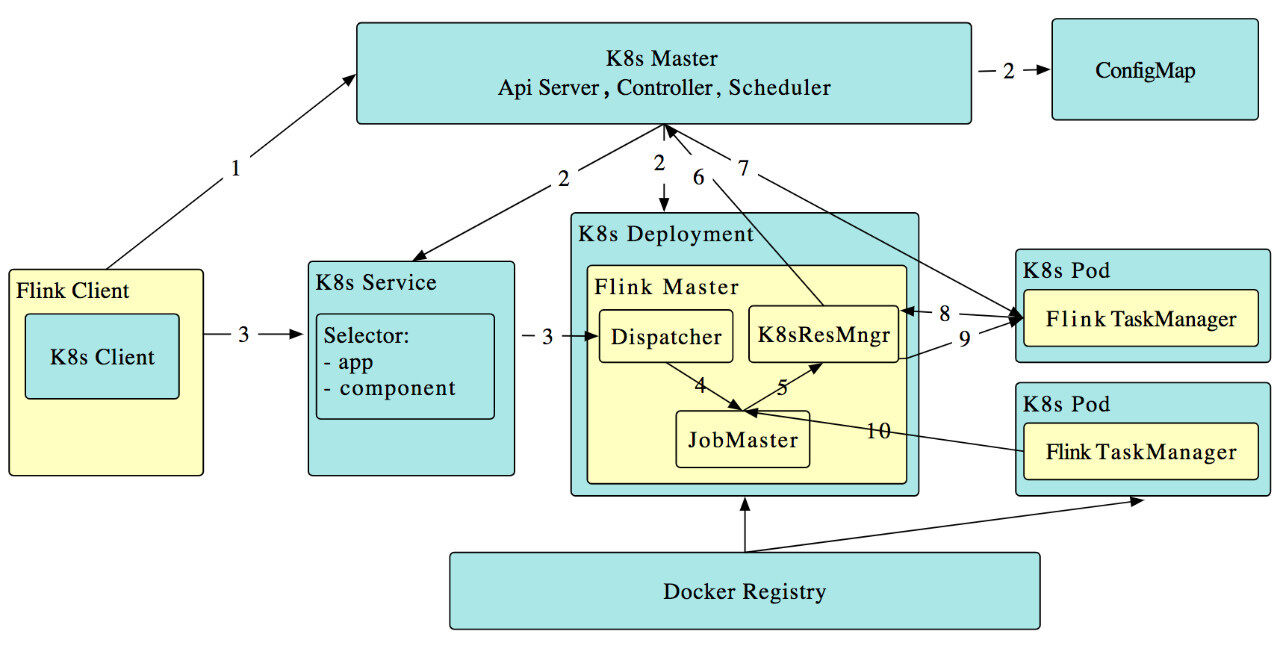
正如在统一的作业提交逻辑一节中提到的,Flink 1.10 将命令行参数映射到了统一的配置。因此,用户可以参阅 Kubernetes 配置选项,在命令行中使用以下命令向 Kubernetes 提交 Flink 作业。
如果你希望第一时间尝试这一特性,欢迎参考相关文档[16]、试用并与社区分享你的反馈意见。
Table API/SQL: 生产可用的 Hive 集成
Flink 1.9 推出了预览版的 Hive 集成。该版本允许用户使用 SQL DDL 将 Flink 特有的元数据持久化到 Hive Metastore、调用 Hive 中定义的 UDF 以及读、写 Hive 中的表。Flink 1.10 进一步开发和完善了这一特性,带来了全面兼容 Hive 主要版本[17]的生产可用的 Hive 集成。
■ Batch SQL 原生分区支持
此前,Flink 只支持写入未分区的 Hive 表。在 Flink 1.10 中,Flink SQL 扩展支持了 INSERT OVERWRITE 和 PARTITION 的语法(FLIP-63 [18]),允许用户写入 Hive 中的静态和动态分区。
写入静态分区
写入动态分区
对分区表的全面支持,使得用户在读取数据时能够受益于分区剪枝,减少了需要扫描的数据量,从而大幅提升了这些操作的性能。
■ 其他优化
除了分区剪枝,Flink 1.10 的 Hive 集成还引入了许多数据读取[19]方面的优化,例如:
投影下推:Flink 采用了投影下推技术,通过在扫描表时忽略不必要的域,最小化 Flink 和 Hive 表之间的数据传输量。这一优化在表的列数较多时尤为有效。
LIMIT 下推:对于包含 LIMIT 语句的查询,Flink 在所有可能的地方限制返回的数据条数,以降低通过网络传输的数据量。
读取数据时的 ORC 向量化:为了提高读取 ORC 文件的性能,对于 Hive 2.0.0 及以上版本以及非复合数据类型的列,Flink 现在默认使用原生的 ORC 向量化读取器。
■ 将可插拔模块作为 Flink 内置对象(Beta)
Flink 1.10 在 Flink table 核心引入了通用的可插拔模块机制,目前主要应用于系统内置函数(FLIP-68 [20])。通过模块,用户可以扩展 Flink 的系统对象,例如像使用 Flink 系统函数一样使用 Hive 内置函数。新版本中包含一个预先实现好的 HiveModule,能够支持多个 Hive 版本,当然用户也可以选择编写自己的可插拔模块 [21]。
其他 Table API/SQL 优化
■ SQL DDL 中的 watermark 和计算列
Flink 1.10 在 SQL DDL 中增加了针对流处理定义时间属性及产生 watermark 的语法扩展(FLIP-66 [22])。这使得用户可以在用 DDL 语句创建的表上进行基于时间的操作(例如窗口)以及定义 watermark 策略[23]。
■ 其他 SQL DDL 扩展
Flink 现在严格区分临时/持久、系统/目录函数(FLIP-57 [24])。这不仅消除了函数引用中的歧义,还带来了确定的函数解析顺序(例如,当存在命名冲突时,比起目录函数、持久函数 Flink 会优先使用系统函数、临时函数)。
在 FLIP-57 的基础上,我们扩展了 SQL DDL 的语法,支持创建目录函数、临时函数以及临时系统函数(FLIP-79 [25]):
关于目前完整的 Flink SQL DDL 支持,请参考最新的文档[26]。
注:为了今后正确地处理和保证元对象(表、视图、函数)上的行为一致性,Flink 废弃了 Table API 中的部分对象申明方法,以使留下的方法更加接近标准的 SQL DDL(FLIP-64 [27])。
■ 批处理完整的 TPC-DS 覆盖
TPC-DS 是广泛使用的业界标准决策支持 benchmark,用于衡量基于 SQL 的数据处理引擎性能。Flink 1.10 端到端地支持所有 TPC-DS 查询(FLINK-11491 [28]),标志着 Flink SQL 引擎已经具备满足现代数据仓库及其他类似的处理需求的能力。
PyFlink: 支持原生用户自定义函数(UDF)
作为 Flink 全面支持 Python 的第一步,在之前版本中我们发布了预览版的 PyFlink。在新版本中,我们专注于让用户在 Table API/SQL 中注册并使用自定义函数(UDF,另 UDTF / UDAF 规划中)(FLIP-58 [29])。

如果你对这一特性的底层实现(基于 Apache Beam 的可移植框架 [30])感兴趣,请参考 FLIP-58 的 Architecture 章节以及 FLIP-78 [31]。这些数据结构为支持 Pandas 以及今后将 PyFlink 引入到 DataStream API 奠定了基础。
从 Flink 1.10 开始,用户只要执行以下命令就可以轻松地通过 pip 安装 PyFlink:
更多 PyFlink 规划中的优化,请参考 FLINK-14500[32],同时欢迎加入有关用户需求的讨论[33]。
重要变更
FLINK-10725[34]:Flink 现在可以使用 Java 11 编译和运行。
FLINK-15495[35]:SQL 客户端现在默认使用 Blink planner,向用户提供最新的特性及优化。Table API 同样计划在下个版本中从旧的 planner 切换到 Blink planner,我们建议用户现在就开始尝试和熟悉 Blink planner。
FLINK-13025[36]:新的 Elasticsearch sink connector[37] 全面支持 Elasticsearch 7.x 版本。
FLINK-15115[38]:Kafka 0.8 和 0.9 的 connector 已被标记为废弃并不再主动支持。如果你还在使用这些版本或有其他相关问题,请通过 @dev 邮件列表联系我们。
FLINK-14516[39]:非基于信用的网络流控制已被移除,同时移除的还有配置项“taskmanager.network.credit.model”。今后,Flink 将总是使用基于信用的网络流控制。
FLINK-12122[40]:在 Flink 1.5.0 中,FLIP-6[41] 改变了 slot 在 TaskManager 之间的分布方式。要想使用此前的调度策略,既尽可能将负载分散到所有当前可用的 TaskManager,用户可以在 flink-conf.yaml 中设置 “cluster.evenly-spread-out-slots: true”。
FLINK-11956[42]:
s3-hadoop 和 s3-presto 文件系统不再使用类重定位加载方式,而是使用插件方式加载,同时无缝集成所有认证提供者。我们强烈建议其他文件系统也只使用插件加载方式,并将陆续移除重定位加载方式。
Flink 1.9 推出了新的 Web UI,同时保留了原来的 Web UI 以备不时之需。截至目前,我们没有收到关于新的 UI 存在问题的反馈,因此社区投票决定[43]在 Flink 1.10 中移除旧的 Web UI。
发行说明
准备升级到 Flink 1.10 的用户,请参考发行说明[44]中的详细变更及新特性列表。对于标注为 @Public 的 API,此版本与此前的 1.x 版本 API 兼容。
参考链接:
[2] https://flink.apache.org/downloads.html
[3] https://issues.apache.org/jira/secure/ReleaseNote.jspa?projectId=12315522&version=12345845
[4] https://ci.apache.org/projects/flink/flink-docs-release-1.10/
[5] https://flink.apache.org/community.html#mailing-lists
[6] https://issues.apache.org/jira/projects/FLINK/summary
[8] https://issues.apache.org/jira/browse/FLINK-7289
[10] https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/mem_setup.html
[12] https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=133631524)
[13] https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/cli.html#deployment-targets
[14] https://cwiki.apache.org/confluence/display/FLINK/FLIP-74%3A+Flink+JobClient+API)
[15] https://jira.apache.org/jira/browse/FLINK-9953
[16] https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/deployment/native_kubernetes.html
[17] https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/hive/#supported-hive-versions
[18] https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support
[21] https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/modules.html
[22] https://cwiki.apache.org/confluence/display/FLINK/FLIP-66%3A+Support+Time+Attribute+in+SQL+DDL
[23] https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/sql/create.html#create-table
[24] https://cwiki.apache.org/confluence/display/FLINK/FLIP-57%3A+Rework+FunctionCatalog
[25] https://cwiki.apache.org/confluence/display/FLINK/FLIP-79+Flink+Function+DDL+Support
[26] https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/sql/
[28] https://issues.apache.org/jira/browse/FLINK-11491
[30] https://beam.apache.org/roadmap/portability/
[32] https://issues.apache.org/jira/browse/FLINK-14500
[34] https://issues.apache.org/jira/browse/FLINK-10725
[35] https://jira.apache.org/jira/browse/FLINK-15495
[36] https://issues.apache.org/jira/browse/FLINK-13025)]
[38] https://issues.apache.org/jira/browse/FLINK-15115
[39] https://issues.apache.org/jira/browse/FLINK-13884
[40] https://issues.apache.org/jira/browse/FLINK-12122
[41] https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=65147077
[42] https://issues.apache.org/jira/browse/FLINK-11956
[43] http://apache-flink-mailing-list-archive.1008284.n3.nabble.com/DISCUSS-Remove-old-WebUI-td35218.html
[44] https://ci.apache.org/projects/flink/flink-docs-release-1.10/release-notes/flink-1.10.html
原文链接:
https://flink.apache.org/news/2020/02/11/release-1.10.0.html

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论