

据 Sysdig 发布的容器报告,容器以及如 Kubernetes 等编排工具的使用增长了51%以上,大家开始将工作负载在集群中进行托管并管理。鉴于集群中短暂的状态,对于端到端的集群有一个十分重要的需求,即能够详细监控节点、容器以及 pod。
IT 工程师需要管理应用程序、集群(节点和数据),并且需要减少手动配置 service、目标和数据存储的工作量,同时在应用程序每次关闭和返回时进行监控。这就需要一个无缝部署以及管理高可用监控系统(如 Prometheus),其中可以与 Operator 一起处理抓取目标的动态配置、服务发现以及用于告警集群中各种目标的配置规则。同时,使用 Operator 模式编写代码以减少人工干预。
本文,我们将关注 Prometheus Operator 是如何工作的,service monitor 在 Prometheus Operator 中是如何发现目标和获取指标的。
在集群监控中 Prometheus Operator 所扮演的角色
能够使用原生 Kubernetes 配置选项无缝安装 Prometheus Operator
能够在 Kubernetes 命名空间中创建和摧毁一个 Prometheus 实例,某个特定的应用程序或者团队能够轻松地使用 Operator
能够预配置配置文件,包括 Kubernetes 资源的版本、持久性、保留策略和 replica
能够使用标签发现目标 service,并根据熟悉的 Kubernetes 标签查询自动生成监控目标配置。
例如:当 pod /service 销毁并返回时,Prometheus Operator 可以自动创建新的配置文件,无需人工干预。
在 Operator 模式下所需的组件
Custom Resource Definition(CRD) :创建一个新的自定义资源,包括可指定的名称和模式,无需任何编程。Kubernetes API 提供和处理自定义资源的存储。
自定义资源 :扩展 Kubernetes API 或允许将自定义 API 引入 kubernetes 集群的对象。
自定义控制器 :以新的方式处理内置的 Kubernetes 对象,如 Deployment、Service 等,或管理自定义资源,如同管理本机 Kubernetes 组件
Operator 模式 (适用于 CRD 和自定义控制器):Operator 基于 Kubernetes 资源和控制器增加了允许 Operator 执行常见应用程序任务的配置。
Operator 的工作流程
Operator 在后台执行以下操作以管理自定义资源:
1、CRD 创建:CRD 定义规范和元数据,基于该规范和元数据应创建自定义资源。当创建 CRD 的请求时,使用 Kubernetes 内部模式类型(OpenAPI v3 模式)验证元数据,然后创建自定义资源定义(CRD)对象
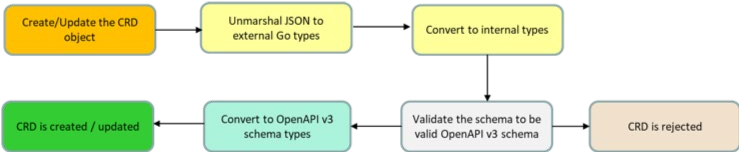
2、自定义资源创建根据元数据和 CRD 规范验证对象,并相应地创建自定义对象创建。

3、Operator(自定义控制器)开始监控 event 及其状态变更,并基于 CRD 管理自定义资源。它可以提供 event 在自定义资源上执行 CRUD 操作,因此每当更改自定义资源的状态时,都能被触发相应的 event。
服务发现及自动配置获取的目标
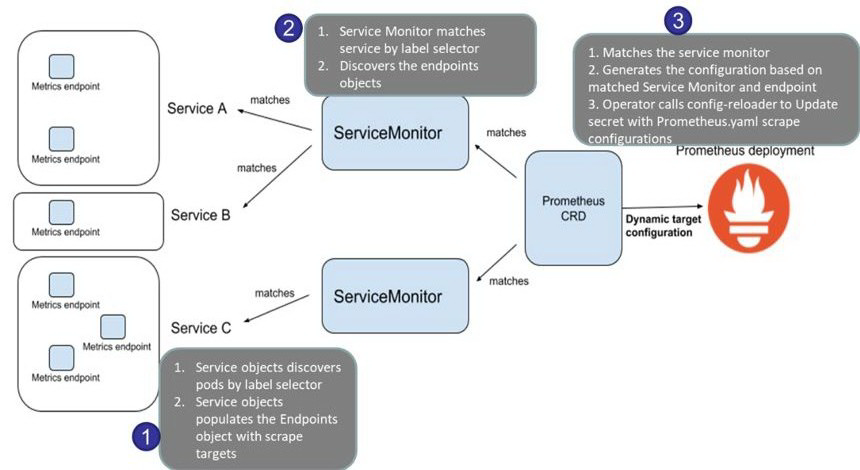
Prometheus Operator 使用 Service Monitor CRD 执行自动发现和自动配置获取的目标。
ServiceMonitoring 包括以下组件:
Service:实际上是 service/deployment,它在定义的端点、端口暴露指标,并使用对应的标签进行标识。每当 service 或 pod 发生故障时,该 service 以相同的标签返回,因此使得它可被 service monitor 发现。
Service Monitor:可基于匹配的标签发现 service 的自定义资源。Servicemonitor 处于部署了 Prometheus CRD 的命名空间中,但通过使用 NamespaceSelector,它依旧能够发现部署在其他命名空间中的 service。
Prometheus CRD:基于标签与 service monitor 相匹配并且能够生成 Prometheus 的配置。
Prometheus Operator:它可调用 config-reloader 组件以自动更新 yaml 配置,其中包含抓取目标的详细信息。
接下来我们来看一个简单的使用案例,以此理解 Prometheus Operator 时如何监控 service 的。
使用案例
使用 Prometheus Operator 进行 Gerrit 服务监控
Gerrit 是一个代码 review 工具,主要用于 DevOps CI 流水线,在代码入库前对每个提交进行审阅。本文假设 Gerrit 已经在 Kubernetes 集群中运行,因此不再赘述 Gerrit 在 Kubernetes 作为服务运行的步骤。
如果你还没有 Prometheus Operator,可以使用 helm chart 来安装或直接使用 Rancher,在 Rancher2.2 及以上的版本中,Rancher 会在新添加的集群中部署一个 Prometheus Operator。以下组件将会被默认下载安装:
prometheus-operator
prometheus
alertmanager
node-exporter
kube-state-metrics
grafana
service monitors to scrape internal kubernetes components
>>>kube-apiserver
>>>kube-scheduler
>>>kube-controller-manager
>>>etcd
>>>kube-dns/coredns
以下步骤将展示 Prometheus Operator 如何自动发现运行在 Kubernetes 集群上的 Gerrit 服务以及如何从 Gerrit 中抓取指标。
使用 Gerrit-Prometheus 插件暴露指标
可以使用 Prometheus jar 插件暴露 Gerrit 指标,但需要提前将该插件安装在 Gerrit 实例上运行。
Prometheus jar 插件下载地址:
https://gerrit-ci.gerritforge.com/,将 jar 放在 Gerrit 插件目录中:/var/gerrit/review_site/plugins/,并重启 gerrit 服务。
在管理员的 web 界面校验 Prometheus 插件:Gerrit -> Plugins -> Prometheus plugin。
创建一个账号和组并给予查看指标的访问权限
以管理员权限登录到 Gerrit 的 web 界面,访问:Projects>List>All-Projects。点击【Access】标签,再点击【edit】按钮。
在 block global capabilities 中,点击【Add Permission】并且在下拉列表中选择【View Metrics】。
在 Gerrit 中为用户生成一个 token。
选择我们此前创建的组“Prometheus Metrics“,点击【Add】按钮。
滑至页面底部并点击【Save Changes】按钮。
创建 secret 以访问 Gerrit 服务
在 Gerrit 中生成 token 之后,你可以使用用户 id 和 token 来生成 Base64 编码格式的用户 id 和 token,用于将凭证存储在 Kubernetes 中。
使用 secret 的详细信息创建一个 yaml 并在 Kubernetes 中创建 secret。
kubectl apply -f gerrit-secret.yaml

将标签应用到服务
使用两个标签标记 Gerrit 服务,例如:app: gerrit and release: prometheus-operator
为 Gerrit 创建 Service Monitor
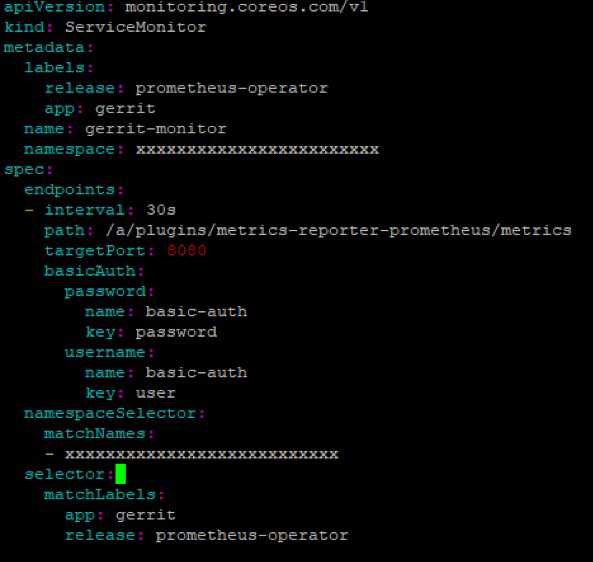
在 servicemonitoring 添加端点的详细信息以发现 Gerrit 服务指标以及具有匹配标签的的 selector,如下所示:
带标签的 service selector
Selector 下的标签是用于标识服务的标签:
ServiceMonitor selector
元数据部分下的标签是指用于通过 Prometheus CRD 识别服务监视器的标签。
Namespaceselector: 在 Gerrit 服务所运行的 Kubernetes 集群中提供命名空间。Service 可以在任何命名空间中运行,但 service monitor 只能在 Prometheus Operator 运行的命名空间创建,这样 Prometheus CRD 就可以识别 service monitor 对象。
在 Prometheus 中匹配 Service Monitor selector
使用以下命令验证 Prometheus 对象中 Service Monitor selector 的部分:
注意:如果 Prometheus-operator 使用 helm 部署,标签 release=Prometheus-operator 已经应用到 Prometheus 对象上。我们依旧需要在 service monitor 中匹配这个标签,因为 Prometheus CRD 需要确定合适的 service monitor。
以上 servicemonitor 创建步骤可以使用 prometheus-operator helm 自定义 values.yaml 来完成。
自动发现 Gerrit 服务
标签更新之后,Prometheus 自定义对象将会自动调用 config-reloader 来读取终端并更新 Prometheus 配置文件。这是 Prometheus Operator 的一个好处,无需手动介入创建 Prometheus 配置文件和更新抓取的配置。
1、 打开 Prometheus url:http://prometheusip:nodeport
kubectl get svc prometheus 以获取 nodeport 详细信息并用节点的详细信息来替代 IP。
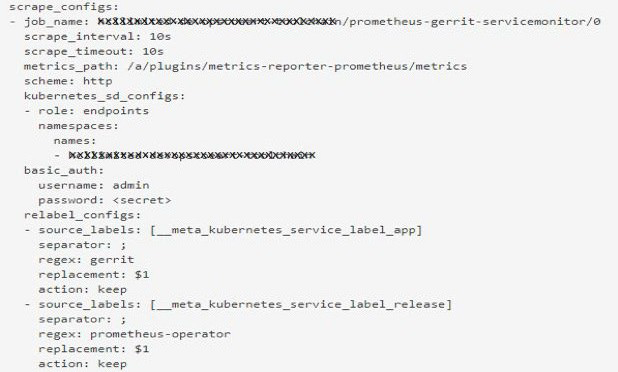
2、 访问菜单:Status -> Configuration,来查看使用抓取配置自动加载的 Prometheus 配置。在 scrape_configs 部分,可以查看 Gerrit service monitor 的详细信息,如下所示:
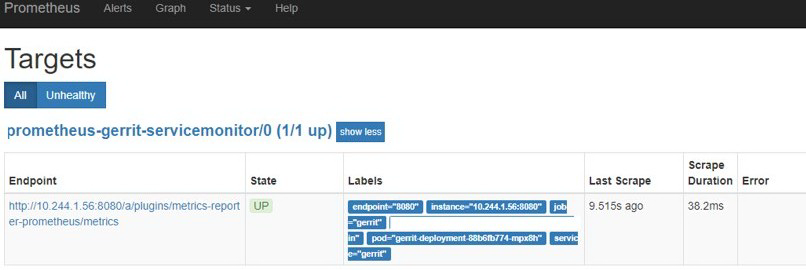
3、 访问菜单 -> Status -> Targets or Service Discovery。如果 service monitor 已经成功抓取 Gerrit 的指标,目标应该显示为健康[1/1up]。
在 Grafana 中的 Gerrit 健康指标
Gerrit 暴露了各种指标,如 JVM 运行时间、线程内存、heap size、error 等。这些都可以在 Grafana 仪表板中配置以监控 Gerrit 的性能和运行状况(如下所示)。
Gerrit 指标在 scrape url 下暴露:
http://gerrit-svcip:nodeport/a/plugins/metrics-reporter-prometheus/metrics
kubectl get svc prometheus-获取 service 节点端口。
将 gerrit-svcip、nodeport 替换为 gerrit 服务的 gerrit IP / nodeport 的详细信息,暴露的指标将如下所示。
指标的值可以在 Prometheus -> Graph 中的表达字段进行评估,如:caches_disk_cached_git_tags
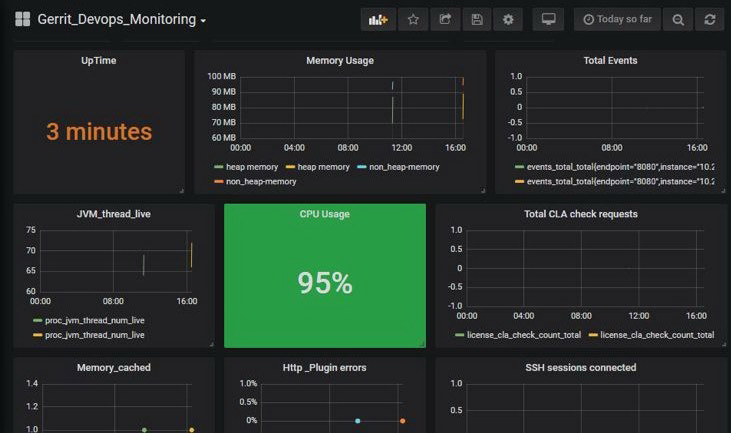
在 Grafana 中配置指标以监控 Gerrit 的健康状况,选择数据源为 Prometheus 并在 dashboard 中配置 widget。一些已经配置的关键指标有 JVM_threads、Uptime、Http_Plugin errors、内存使用情况、事件等。
Prometheus Operator 有助于 Prometheus 的无缝部署和管理、抓取目标的动态配置、服务发现、可扩展性、以及内置的 SRE 专业知识,这可以加速集群监控。
开箱即用的 Prometheus
2018 年年末,Rancher Labs 宣布加强对 Prometheus 的支持,这将为跨多个 Kubernetes 集群和多个隔离租户环境提供更高的可见性。在 Rancher2.2 及以上的版本中,每当添加一个新的 Kubernetes 集群到 Rancher 中,Rancher 都将在集群中部署一个 Prometheus operator,然后在集群中创建一个 Prometheus 部署。此外,还支持以下两个功能:
集群范围内的 Prometheus 部署将被用于存储集群指标(如 CPU 节点和内存消耗),并存储从单个用户部署的应用程序中收集的项目级指标。
项目级的 Grafana 与 Prometheus 的通信将通过安全代理完成,该代理可为 Prometheus 实现多租户。安全代理工具 PromQL 语句可确保仅能通过用户项目的命名空间进行查询。
Rancher 对 Prometheus 的增强支持, 可确保为所有 Kubernetes 集群、所有项目和所有用户进行高效的部署和有效的监测。 安全代理确保不在多租户之间重复共享数据,并且对多租户进行隔离。除此之外,Rancher 还收集使用 Prometheus 处理的数据公开端点的任意自定义指标。所有指标均可用于 Rancher 内部的告警和决策,通过通知用户的 Slack 及 PagerDuty 进行简单操作,通过启动工作负载的横向扩展最终增加负载进行复杂操作。Rancher 现在还拥有完全安全隔离和 RBAC 的集群级和项目级的指标和仪表盘。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论