

数值运算是数据库中十分常见的需求,例如计算数量、重量、价格等,为了适应多样化运算场景,数据库系统通常支持精准的数字类型和近似的数字类型,当我们需要精确地表示小数并计算小数时,通常会考虑使用 Decimal 数据类型。区别于浮点小数,Decimal 作为定点小数类型,可以支持高精度的小数运算,因此适用于各种高精度计算的场景,常见的应用场景有以下几种:
金融行业:在金融交易中经常涉及到小数,比如利息、金额的计算,金融场景对数字准确的要求极高,因此精确的小数运算是必要的。
财务软件:财务软件通常需要进行复杂的财务计算,Decimal 类型可以提供精确的小数计算,避免计算过程中产生的舍入误差。
科学计算、工程计算等其他场景。
DecimalV3 功能介绍
在 Apache Doris 1.2.1 之前的版本中,我们已对 Decimal(precision, scale)(precision<=27) 数据类型进行了支持,随着 Apache Doris 用户的持续增长,银行、证券、基金等金融领域的用户也随之快速增长,对高精度的小数计算场景也提出了更高的要求,旧的 Decimal 数据类型已无法满足。因此,我们在 Apache Doris 1.2.1 推出了精度更高、速度更快的 DecimalV3(precision, scale)(precision<=38),实现了真正意义上的高精度定点数,相比于老版本中的 Decimal ,DecimalV3 有以下核心优势:
可表示范围更大。DECIMALV3 对 Precision 和 Scale 的取值范围进行扩充。
内存占用更低,性能更高。老版本的 Decimal 需要占用 16 Bytes 的内存,而 DecimalV3 对内存可进行自适应调整,如下所示。
更完备的精度推演。
精度推演规则
DECIMALV3 有一套很复杂的类型推演规则,针对不同的表达式,会应用不同规则进行精度推演,下面来介绍一下推演规则:
四则运算
加法 / 减法:DECIMALV3(a, b) + DECIMALV3(x, y) -> DECIMALV3(max(a - b, x - y) + max(b, y), max(b, y)),即整数部分和小数部分都分别使用两个操作数中较大的值。
乘法:DECIMALV3(a, b) * DECIMALV3(x, y) -> DECIMALV3(a + x, b + y)
除法:DECIMALV3(a, b) / DECIMALV3(x, y) -> DECIMALV3(a + y, b)
聚合运算
SUM / MULTI_DISTINCT_SUM:SUM(DECIMALV3(a, b)) -> DECIMALV3(38, b)。
AVG:AVG(DECIMALV3(a, b)) -> DECIMALV3(38, max(b, 4))(鉴于每个系统 AVG 的精度不同,且不同用户对精度的需求也不一样,经调研,决定选择与 SQLServer 相同的策略,因此选择“4”既能保证较好的性能,也不会有较大的精度损失。)
默认规则
除上述提到的函数外,其余表达式都使用默认规则进行精度推演。即对于表达式 expr(DECIMALV3(a, b)),结果类型同样也是 DECIMALV3(a, b)。
结果精度调整
上述几种规则为当前 Doris 的默认行为,而不同场景对 DECIMALV3 的精度要求各不相同,远超出以上几种规则。当用户有不同的精度需求,可以通过以下方式进行精度调整:
当期望的结果精度大于默认精度时,可通过调整入参精度来调整结果精度。例如用户期望计算
AVG(col)得到 DECIMALV3(x, y)作为结果,其中col的类型为 DECIMALV3(a, b),则可以改写表达式为AVG(CAST(col as DECIMALV3(x, y)))。当期望的结果精度小于默认精度时,可通过对输出结果求近似得到想要的精度。例如用户期望计算
AVG(col)得到 DECIMALV3(x, y)作为结果,其中col的类型为 DECIMALV3(a, b),则可以改写表达式为ROUND(AVG(col), y)。
使用演示
这里我们采用 Bitcoin 的数据集对 DecimalV3 进行演示。
Bitcoin 的数据集部分示例如下:
Unix - 时间戳
Date - 时间
Symbol - 时间序列数据所指代的交易品种
Open - 该时间段的开盘价
High - 该时间段的最高价
Low - 该时间段的最低价
Close - 该时间段的收盘价
Volume BTC - BTC 金额
Volume USD - USD 金额

以下是在 Doris 中的建表存储数据,其中小数的列分别用 DecimalV3 进行存储:
我们来计算一下 2022 年 1 月 1 日这一天的平均 Volume_BTC/Volume_USD 以及总的 Volume_BTC/Volume_USD:
通过 SQL 的执行结果可以看到,通过 DecimalV3,在 Volume_USD 这一列的平均结果和总和上,实现了保留 30 位的小数。而旧的 Decimal 类型在这个例子中只能实现保留不超过 20 位。
性能对比
我们采用 TPC-H Benchmark 100G 来对比 DecimalV3 与老版本 Decimal 的执行速度、存储占用、内存占用等性能。
我们在两个库分别对新版 DecimalV3 和老版本 Decimal 进行建表。建表完成如下:
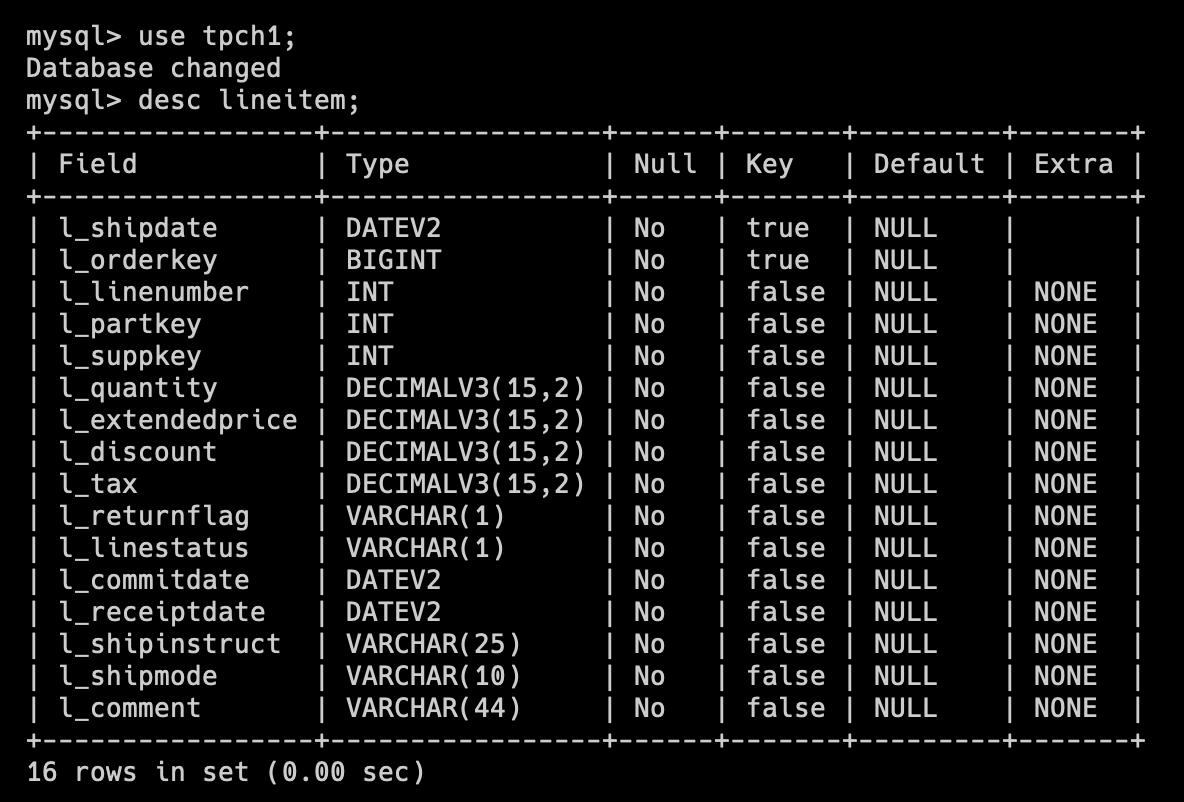
tpch1 库为 DecimalV3
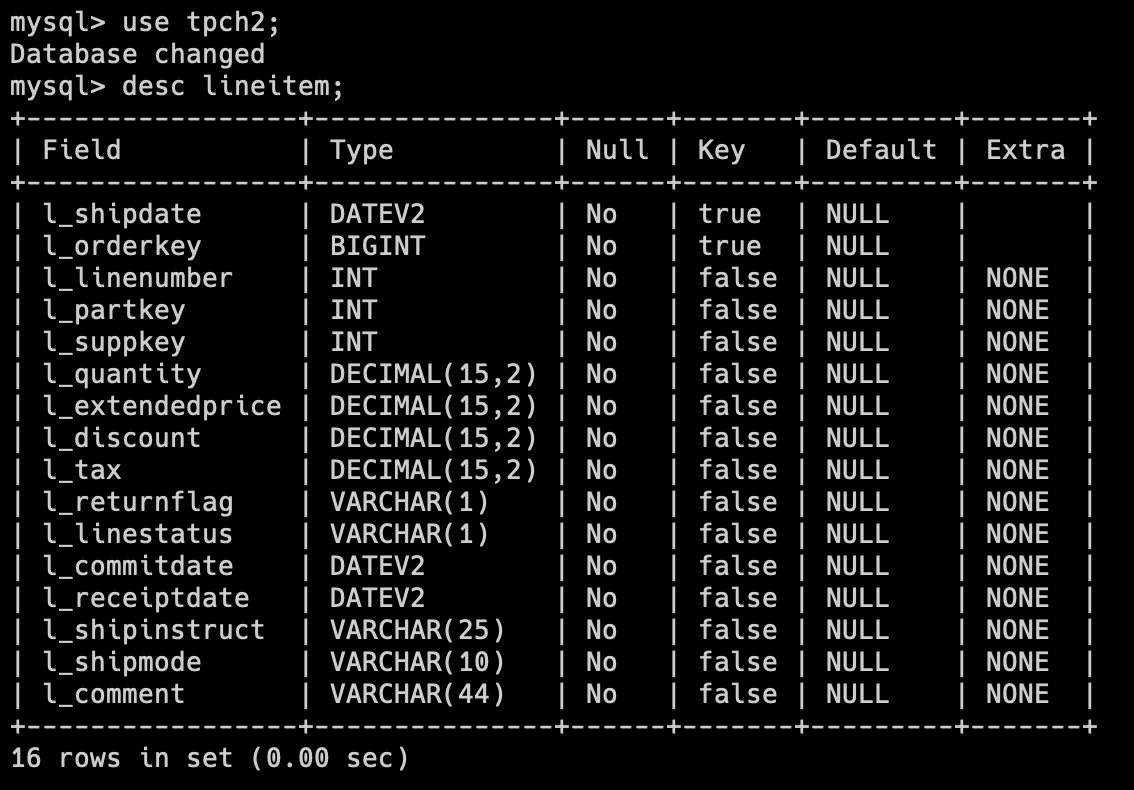
tpch2 库为老版本 Decimal
执行速度
采用 TPC-H Benchmark 对执行速度进行测试:
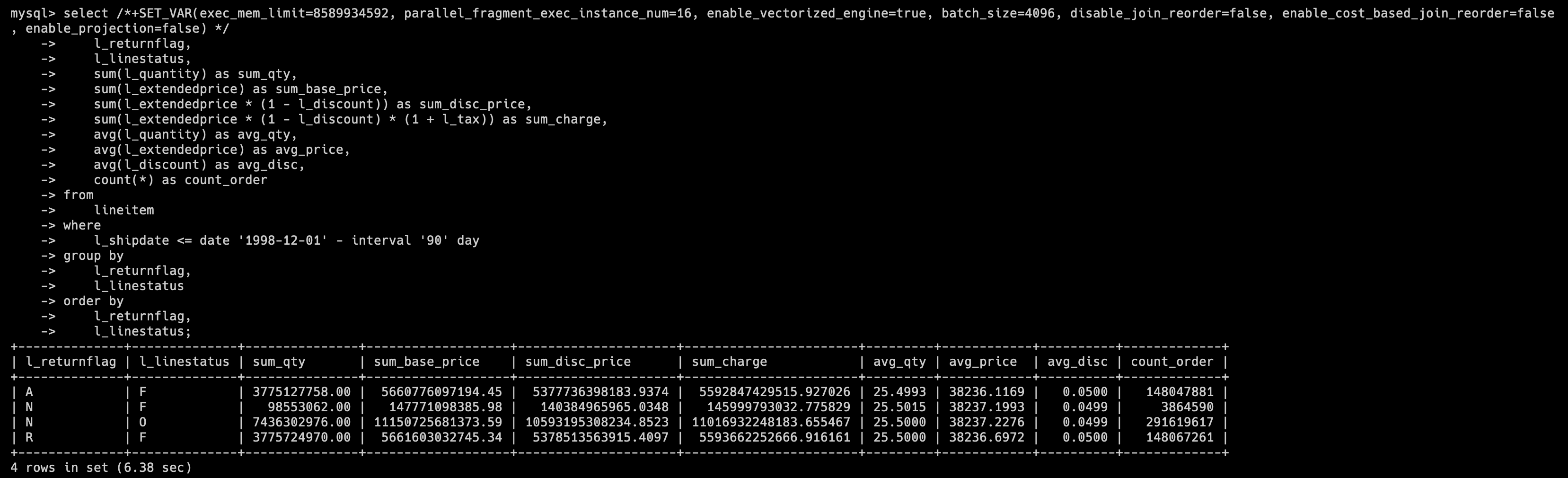
tpch1 库(DecimalV3)的 SQL 执行结果为 6.38s
tpch2 库(老版本 Decimal)的 SQL 执行结果为 8.13s
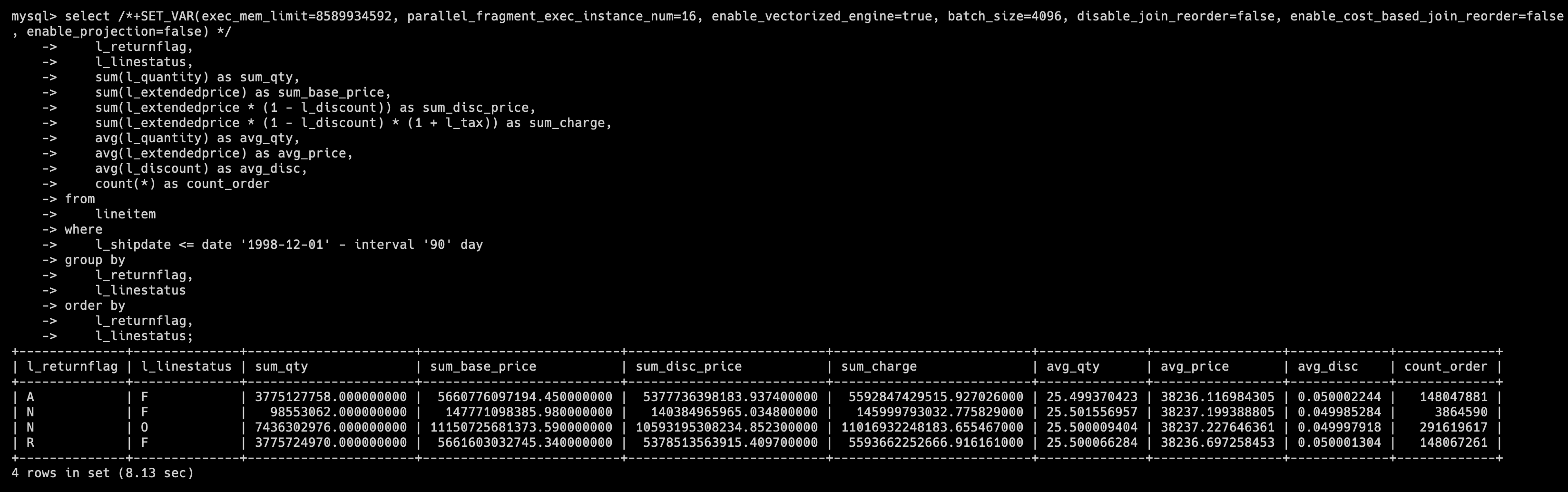
SQL Q1 所查询的表是上述展示字段的表 Lineitem,我们可以看到在 DecimalV3 的情况下,查询 速度较老版本有 27.4% 的提升。
存储占用
tpch1 库(DecimalV3)的 Lineitem 表的存储占用为 18.475GB
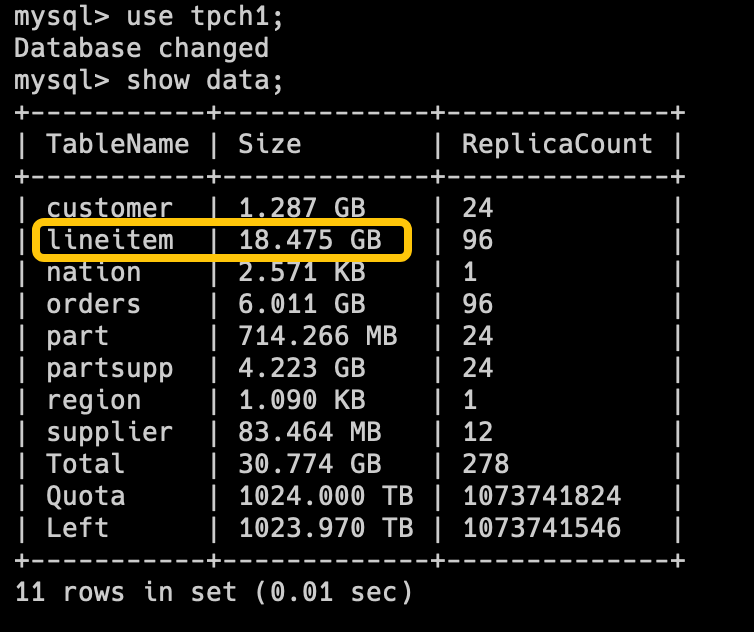
tpch2 库(老版本 Decimal)的 Lineitem 表的存储占用为 20.893GB

可以看到在有四个字段由 Decimal 改为 DecimalV3 的情况下,存储占用有 13.1%的降低。
内存占用
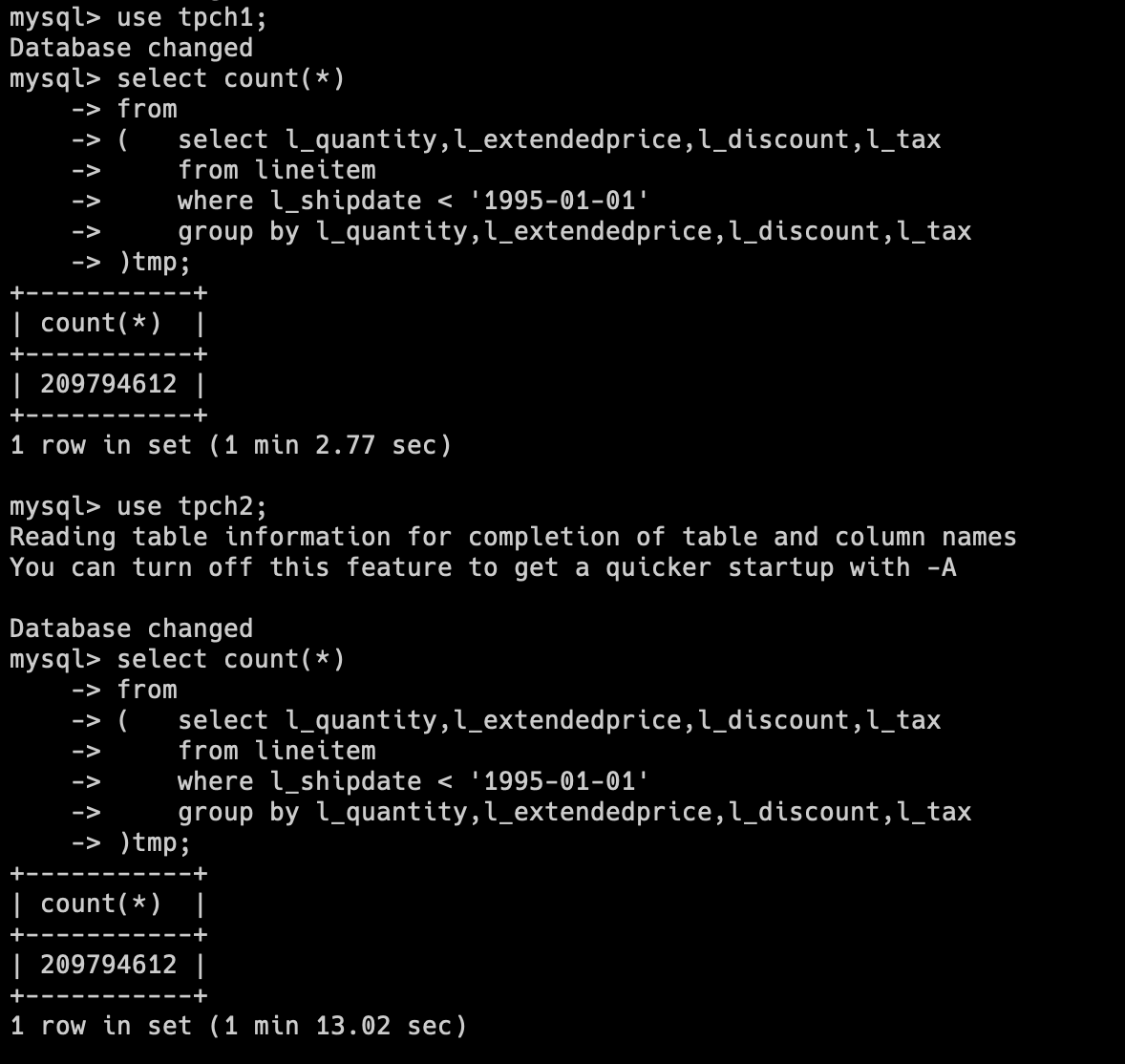
内存占用测试我们同样使用 Lineitem 表,采用自己改写的一条 SQL
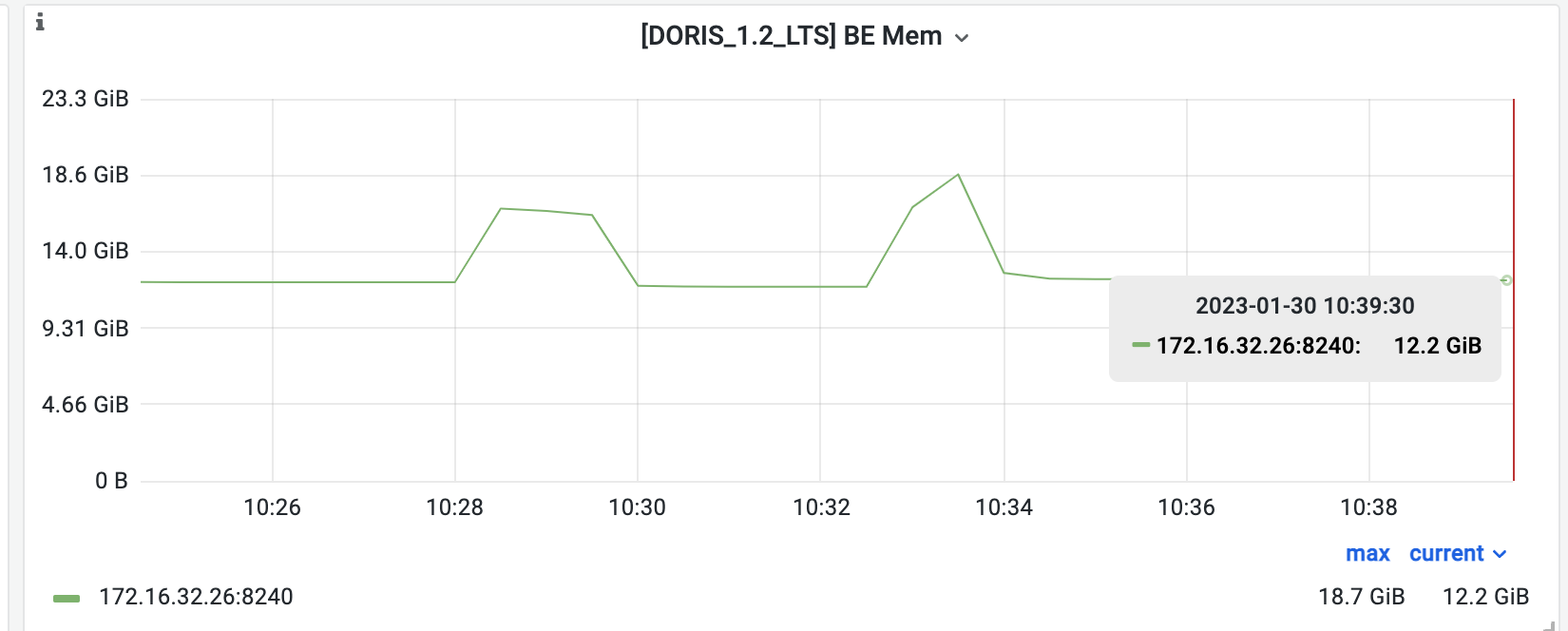
下图的 Grafana 监控中可以看到执行测试前的 Doris 内存稳定为 12.2GB
分别在两个库执行上述 SQL
在 tpch1 库(DecimalV3)下执行,内存占用峰值为 26.6GB
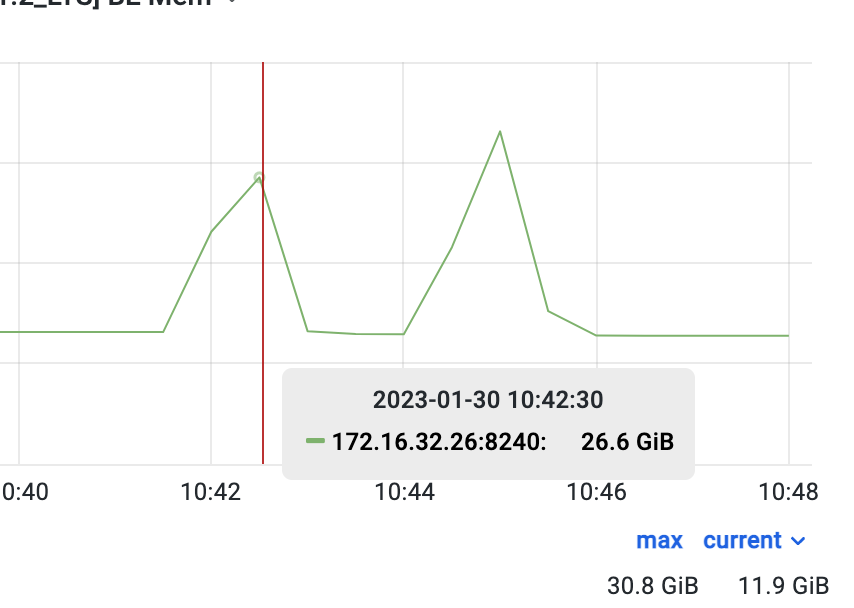
内存回落正常后,在 tpch2 库(老版本 Decimal)下执行,内存占用峰值为 30.8GB
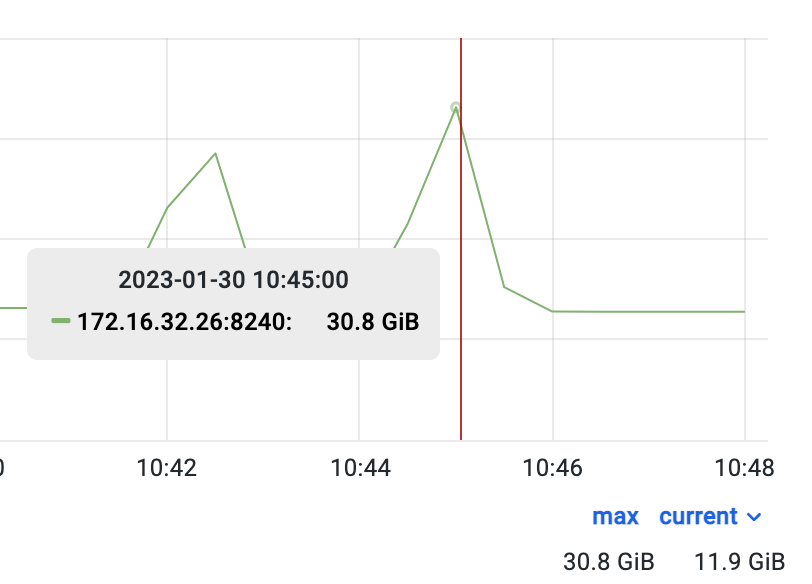
从上方三张图中可以看到,这条 SQL 在 DecimalV3 的情况下不仅内存占用降低了 15.8%,执行时间也缩短了 10s。
总结
Apache Doris 1.2.1 版本推出的 DecimalV3 实现了更高的精度,更高的性能,更完备的精度推演,使得 Doris 更加适用于金融财务、科学计算等有精确计算需求的应用场景,结合 Apache Doris 强大的分析计算性能,给相关用户及行业提供了更准确、完善的数据服务。
接下来,社区还将实现 JDBC 外表对 DecimalV3 类型的支持,JDBC Catalog 可以通过标准 JDBC 协议,连接其他数据源,连接后 Doris 会自动同步数据源下的 Database 和 Table 的元数据,以便快速访问这些外部数据。基于 JDBC 的通用性,结合 Apache Doris 的 高性能分析能力,实现对各类数据库数据联邦查询的高精度计算。
作者介绍:
钟永康,SelectDB 生态研发工程师
李文强,SelectDB 数据库内核研发工程师,Apache Doris Committer

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论