

本文最初发表在 determined.ai 博客,由 InfoQ 中文站翻译并分享。
在这个由两部分组成的博文系列中,我们将演示如何加速跨多 GPU 的自然语言处理深度学习模型训练,将 BERT 用于 SQuAD1 【1】模型训练时间从近 7 个小时缩短到仅 30 分钟!
在本文中,我们将激发在自然语言处理中进行深度学习和分布式训练的需求,强调对有效的分布式训练最重要的因素,并提供了在Determind中运行的一系列 BERT 微调实验的实证结果。在本文系列的第二部分中,我们将概述针对同一个自然语言处理任务的优化分布式数据加载和模型评估的技术。
面向 NLP 的深度学习的“种子”
像 BERT、XLNet 和 GPT-3 这样的神经语言模型在过去几年里屡次成为头条新闻。为什么会这样呢?
针对常见的自然语言处理任务,如实体识别、问答系统,机器学习算法通常需要特征向量作为输入。自然语言输入被表示为向量,从这一点开始,我们训练模型来对文本进行分类、对文档进行聚类、回答问题等【2】。
过去十年的大量研究表明,语言建模作为下游自然语言处理任务模型最终质量的驱动因素,具有重要意义。反观上个世纪的统计语言模型,像bag-of-words和tf-idf,对于自然语言处理任务,尤其是吸引我们的人工智能完备(AI-complete)自然语言处理任务来说,有效地封顶了技术水平,使其远未达到“惊天动地”的地步。
我依然记得,在上世纪 90 年代末第一次尝试 Babel Fish 机器翻译引擎时,我得出结论是,天网还很遥远——Babel Fish 经常给人一种这样的感觉,它更像是一个逐字查找字典引擎,而不是语言理解和翻译的人工智能。
自那以后,对许多自然语言处理任务来说,上述限制已经解除(可以说是消失了),我们在搜索网页或与 Alexa 进行对话时,不断地亲身体验到这些好处。2018 年,随着一类新的语言模型的问世,自然语言处理的发展呈现了爆炸式的增长:首先是基于长短期记忆人工神经网络(LSTM)的ELMo,其次是基于 Transformer 架构的BERT。这些语言模型的新思路是依赖于单词上下文;而以前的非上下文词嵌入,如word2vec和GloVe,将给定单词精确地编码为一个向量,而芝麻街(Sesame Street)模型被设计用来捕捉语言的细微差别,而非上下文词嵌入从定义上来说是无法做到的。
神经语言模型的训练成本
最先进的语言模型的训练成本可能高得惊人。像 BERT 和 XLNet 这样的模型需要学习数以亿计的参数——从头开始训练许多神经语言模型的计算成本对大多数组织来说是令人望而却步的。例如,XLNet需要在 512 个 TPU v3 上进行 5.5 天的训练。在 GCP 上复制它的成本将会超过 50 万美元。语言模型的复杂性和训练成本只会增加,比如,OpenAI 在 2020 年 5 月推出的 GPT-3 模型,可以学习 1750 亿个参数,估计训练成本将超过 1200 万美元。
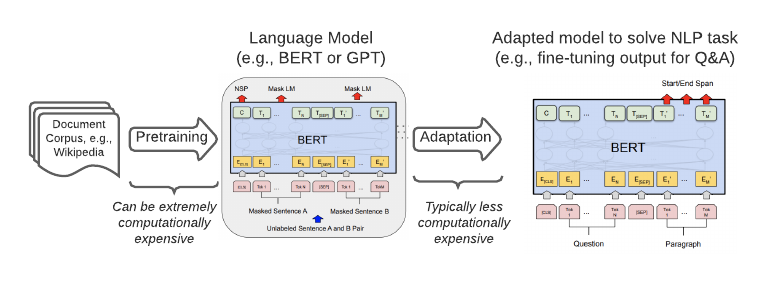
自然语言处理的循序迁移学习工作流示例。通常,昂贵的预训练会产生一个普遍有用的语言模型,可用于解决特定的下游自然语言处理任务。( 来源:《BERT:面向语言理解的深度双向 Transformer 的预训练》(BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding)")
由于研究社区和支持语言模型研究的组织的贡献,任何人都可以免费使用高质量的预训练模型。不仅模型检查点是可用的,而且更广泛的机器学习库生态系统,使得只需几行代码就可以在你所选择的框架中直接使用这些预训练模型。因此,在合理的预算下,上述针对自然语言处理的顺序迁移学习方法是很容易实现的。在我们的例子中,我们为 SQuAD 训练了 BERT,来生成一个可以提取关于给定段落问题答案的模型。每个实验需要不到 20 美元的计算成本来进行 GCP 训练,我们得到了高质量的 F1 成绩,在 87% ~89% 的范围中。为了便于比较,人类的表现为86.8%,而最先进的技术表现为93%。
基线:单 GPU 训练
让我们首先在单块 GPU 上为 SQuAD 训练一个 BERT 模型。在这个Python 示例中,我们使用了 Hugging Face 的Transformer库的预训练模型、特征化和数据加载方法,以及引用超参数。在单块 GPU 上进行训练,大约需要两个轮数(epoch),验证数据集的 F1 得分为 88.4%。这结果还算不错,但是这个训练花去了 7 个多小时!等待结果需要很长的时间,而且这还只是一个使用固定超参数的常见基准自然语言处理任务。如果你或你的团队需要训练更多的数据、调整超参数,为其他自然语言处理任务训练模型,或者为自定义的下游任务开发和调试模型,那么话费一天活更长的时间来训练摸个模型,将会使进度变得非常缓慢。
应用分布式训练
在本文的其余部分,我们将展示如何使用determinated 的分布式训练功能,以大约 14 倍的速度执行相同的训练任务,同时达到相同的模型正确率!在这个过程中,我们将揭示影响扩展性能的关键因素,并为有效的分布式训练提供实用的指导。
借助 determined 的标准化模型范例,在多块 GPU 上训练一个模型不需要更改代码。接下来的每个结果,无论是在一台机器上使用 2 块 GPU 进行训练,还是在多台机器上使用 16 块 GPU 进行训练,都只需更改配置即可。
让我们看看如何在午休时间而不是一整天的工作时间里,通过在 determined 上进行分布式训练来训练上述同样的模型。在这篇博文中,我们专注于优化训练循环。在本文系列的第二部分中,我们将重点讨论训练工作流中影响整体运行时间的其他组件,即数据加载和验证。为此,以下时间并不包括数据加载和验证的时间。
扩展初步结果
下面的图表显示了从 1 块 NVIDA K80 GPU 扩展到 8 块 NVIDIA K80 GPU(都在 GCP 的单机上)的训练时间。在这些实验中,我们固定了每块 GPU 的批次大小和训练轮数的总数量。
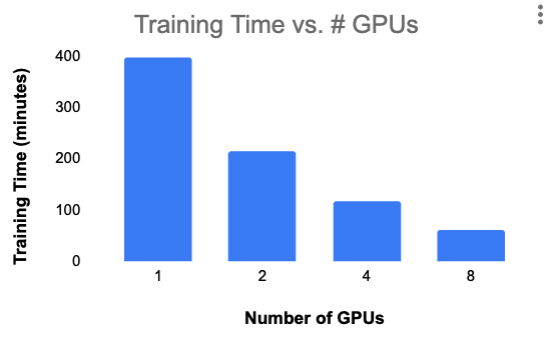
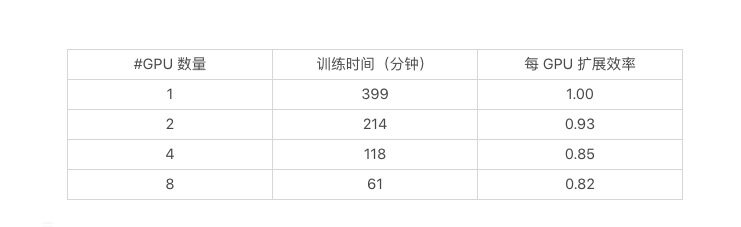
这是一个不错的初步结果,尽管我们没能实现线性扩展,但我们做到了将扩展效率保持在 80% 以上,而且我们还设法将 BERT SQuAD 模型的训练时间缩短到一个小时。我们在所有四个实验的验证数据集上获得了 87% ~88% 的 F1 得分。
做得更好:梯度聚合和 RAdam
在上面的结果中,随着训练并行度的增加,扩展效率呈现明显的下降趋势。这是怎么回事儿?也许我们可以接受这样扩展的结果,但如果我们有一个更重的训练工作量,想分配到 64 块 GPU 呢?这种趋势对我们并不利。
对于可能发生的情况,一种自然的理论是,训练是受通信限制的。为了将训练分布在 8 块 GPU 上,Determined 将训练数据集分成 8 个碎片,独立训练 8 个模型(每块 GPU 一个)的小批次,然后聚合并进行通信传递梯度更新,以使将模型的所有 8 个副本都具有相同的权重。然后,我们对每一个批次都重复这个正向传递和反向传递,然后进行梯度聚合的过程。正如我们在博文和产品文档所讨论的那样,像大批量训练这样的通信减少技术,可以帮助减少训练时间。当 GPU 通过 PCI-E 而不是更高带宽(但更昂贵)的 NVLink 连接时,这种技术就特别有前途。
让我们看看这一理论是否适用于我们的模型。使用 Determined,你可以通过配置的改变来调整每槽的批次大小,但请记住,就算是很小的增加,也会很快耗尽 GPU 的内存,因为正向传递和反向传递所需的居间态与模型的大小呈线性关系,而且还与批次大小有关。相反,我们要保持 GPU 的内存需求适中,以便能够在低成本的 NVIDIA K80 上运行。我们通过利用 Determined 的分布式训练优化实现了这一目标,降低了 GPU 间通信和每块 GPU 的内存需求。这个聚合频率配置选项指定在跨 GPU 通过通信传递梯度更新之前要执行的正向传递和反向传递的次数。在下表中,我们看到增加聚合频率确实有助于运行时:
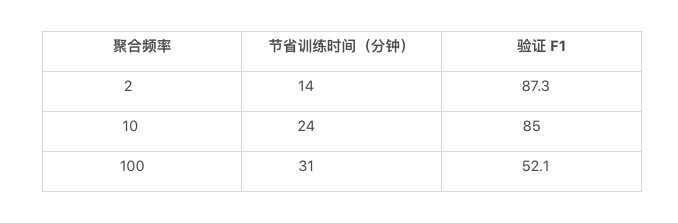
这太棒了!如果我们可以将训练时间减少 31 分钟,那么我们的每 GPU 的扩展效率将从 0.93 提高到完美的 1。不过,我遗漏了一些东西——对于上面的三行,我们的验证数据集 F1 得分分别为 87.3%、85% 和 52.1%。
差一点点就成功了。这是怎么回事呢?因为大批次的随机梯度下降并不总是“有效”,特别是,在这种情况下,很难找到学习率的最佳点。有时,线性缩放规则(Linear Scaling Rule)会起作用,如果我们将批次大小乘以 k,我们还得将(先前调整过的)学习率乘以 k。在我们的例子中,使用AdamW优化器,线性缩放根本没有帮助;事实上,当应用线性缩放规则时,我们的 F1 得分甚至会更糟。学习率预热策略也会有所帮助,在大批次训练中,早期使用较小的学习率。不过,根据我们的经验,RAdam优化器更适合大批次训练,而不需要进行大量的学习率调整。当我们换成RAdam 实现时,我们的结果看起来要好得多:

在这种情况下,我们可以看到,即使相当基金的聚合频率为 10,也可以保持验证性能。并为我们提供从 1 块 GPU 到 2 块 GPU 的完美训练扩展。在聚合频率为 100 的情况下,结果表明,即使训练时间加速达到了收益递减的地步,RAdam 仍然足够健壮,即使在极端情况下,也有相当好的表现。实际上,我们建议测试聚合频率低于 16,以便在不牺牲模型性能的同时缩短训练时间。
超动力的多机训练
我们已经取得了长足的进步,利用 Determined 的分布式训练的能力,为 SQuAD 训练 BERT 的时间从单块 GPU 上的近 7 个小时缩短到单台机器上 8 块 GPU 上的不到 1 个小时。
为了进一步缩短训练时间,我们还能够做些什么呢?特别是考虑到 GCP 上的单个实例最多允许8 块 GPU 的事实。有了 Determined,模型开发人员可以像在单机上进行多块 GPU 训练一样,轻松扩展到多机训练。当基线单块 GPU 训练时间需要几天到几周的时候,这一点就特别有价值了。
在为 SQuAD 训练 BERT 的情况下,在两个实例中将训练扩展到 16 块 GPU 时,我们将训练时间进一步减少到 30 分钟。与我们的第一个单块 GPU 训练工作相比,我们实现了每 GPU 扩展效率为 0.83 。
值得注意的是,当我们扩展到多台机器时,通信限制对我们的影响变得更大,以至于如果要保持有效批次大小不变的话,那么在 16 块 GPU 上的训练时间实际上会大雨在单机上 8 块 GPU 上的训练时间。通过将聚合频率增加到 2,并使用 RAdam 优化器,我们可以更好的进行扩展,在验证数据集上的 F1 得分仍然达到了 87%。
下一步打算
在本文中,我们使用了 Determined 对分布式训练的支持,对 BERT 的训练时间进行了优化,从近 7 个小时缩短到仅 30 分钟。除了切换到 RAdam 优化器之外,我们在不改变模型本身的一行代码的情况下就实现了这些性能的提升!
在本文中,我们专注的是优化训练循环。在下一篇文章中,我们将跳出训练循环,进一步优化分布式环境下的模型训练。我们将利用一些即将推出的产品增强功能来实现这一目标,敬请期待。
我希望本文已经向读者表明,在真实世界的自然语言处理的迁移学习用例上,使用 Determined 进行分布式训练既简单,又极具价值。如果你想让模型的训练工作在午休时间即可完成,而不是通宵达旦,请不妨一试!
尾注
【1】 SQuAD,是Stanford Question Answering Dataset(斯坦福问答数据集)的缩写。该数据集是一个流行的阅读理解基准数据集,用于从给定段落中提取问题答案。
【2】 这就是顺序迁移学习(Sequential Transfer Learning,STL)的范式,其中一个(通常成本昂贵)预训练任务完成一次,由此产生的预训练模型是我们训练下游适应任务训练模型的起点。这篇博文对自然语言处理中的顺序迁移学习和其他风格的迁移学习做了很好的解释。
原文链接:
https://determined.ai/blog/faster-nlp-with-deep-learning-distributed-training/

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论