

为了要实时监控公有云运行状态, 并将其以直观的图表展示, 甚至当业务出现故障还需要进行对策预案响应和自动恢复等操作。华为云是如何保证了每天超高并发访问,数亿数据写入,海量数据存储的有效监控和管理呢?听我们细细道来。
① 什么是 Cassandra?
Apache Cassandra 是一款扩展性优良的 NoSQL 数据库,最初是由 Facebook 内部研发用于存储每天海量的 news feeds 的,后来开源之后由 apache 接管。它的去中心化设计保证了非常优秀的线性扩展能力(Scale-out), 基于 google BigTable 的存储数据结构设计天然的支持超大规模的数据量存储特别是 Wide Column 类型的数据结构化。同时原生的 TTL 能力使得它作为监控类业务的指标数据存储相对于同类型的其他数据库有比较突出的优势。
②只有合适的才是最好的
云监控尚在设计阶段的时候,我们对数据库已经有了两种争论:SQL 和 NoSQL,当然在如今随随便便一个手机 app 都能产生大量数据的时代,第一个争论很快就不存在了,SQL 对于监控数据有很多天然的瓶颈(结构化扩展性差,写效率低,扩容困难等等),于是 NoSQL 就成了第二个争论点:到底用什么?我们仔细分析后发现只有 Cassandra 这款数据库能满足我们对于监控数据的所有诉求:线性扩展,TTL,写入性能高,集群部署无单点故障(single point of failure),可调的数据一致性以及前车之鉴(大量第三方监控服务提供商作为使用者的背书)。
③怎么存储数据?
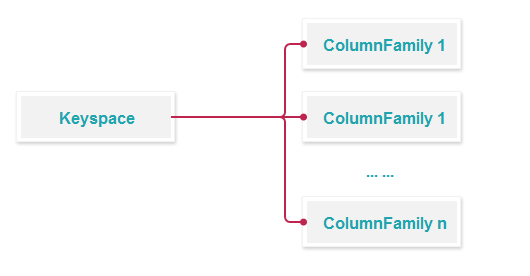
Cassandra 是典型的 Wide column 数据库,也就是俗称的列库(业界类似的有 DynamoDB,Hbase 等),在 Cassandra 里面第一级存储单位是 Keyspace,下来是 ColumnFamily (2.0 以前,之后叫 Table)。然后是 row key, column (thrift 模型)或者 row column(2.0 以上通用模型)具体是这样:
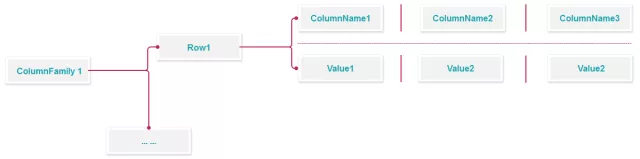
在上面这样的模型下,每一个 row 可以近乎变态的不断是写入数据 Column,最大可以到 2B 的数据量,所以非常适合做 time series 的数据类型(监控,news feeds,跟帖之类)简单的说来,一个指标的数据可以存成如下的形式:

并且 n 可以最大到 2B,所以对于连续的基于时间的指标数据,这种天然的数据结构是非常适合的。由于 cassandra 支持基于多种维度的 TTL,所以我们不用担心当是写入数据过多会把数据库写爆的问题,只要定义好每个 Row 的 TTL,自然到了时间相应的 Column 和其所对应的 value 就会被自动删除,释放资源。
④云监控的最佳实践
云监控在 Cassandra 上存储的数据主要分为两个部分,监控指标数据,和元数据。这两种数据在业务上有本质的区别:
指标数据的需求是写入量非常大,读取量也不小,并且每天写入超过 4 亿次(还在增长),对最终一致性有要求,但是并不要求每次读写都要一致。因此在这部分数据上我们采用了如下策略:
LocalOne 表示每次读写,只要在一个副本(Replica)拿到结果就返回,不会等待其他副本返回数据,这对海量并发的写入和查找是比较高效的做法。
KeyCache 和 RowCache 分别是为了提高读效率而添加的内部 cache 机制,由于指标数据量非常大,打开这两个会导致内存迅速写满,并且在 LocalOne 的情况下,这两个开关的开启实际上对我们性能的优化起到的帮助没有想象的大,因此关闭是可以的。
元数据(配置信息)的需求是写入量小,读取量也小,但是对可靠性和一致性要求比较高,因为这些都是用户在云监控上面的关键信息(告警配置,通知组配置等等),我们采取如下策略:
为什么写的时候会有 LocalOne 呢?因为云监控采用自适应适配机制,对新写入系统内不存在的指标是不会做任何干预的,但是为了记录指标名称等配置信息,这些信息是不会写在监控数据内的,因此就会有一条数据被反复写很多次的情况,这样对元数据整个 Keyspace 是非常大的 IO 挑战,如果用 LocalQuorum 来写,会大幅降低我们的集群性能,所以在这里用 LocalOne 是比较合适的。
在读取元数据的时候,必须要保证数据的一致性,所以我们选取的 LocalQuorum(Quorum 的意思是每次必须返回副本数(n+1)/2 个结果才会生效。
KeyCache 和 RowCache 由于我们元数据不会经常改动,并且量级较小,在 Quorum 的读策略下,开启这两个能有效提高访问性能。
本文转载自 华为云产品与解决方案 公众号。
原文链接:https://mp.weixin.qq.com/s/GZplCs7Ei8Jzj_TKsueo1A

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论