

在上一篇文章中,我们介绍了,对于安全技术开发者,如何快速的基于 Rosetta 等隐私 AI 框架所提供的一系列接口,将自己的安全协议集成落地到上层的 AI 应用中来。在这一篇文章中,我们将介绍为了保护用户的隐私数据,在隐私 AI 框架的计算任务全流程中,数据是如何以密文形式流动,同时仍正确完成加法、乘法等计算步骤的。
隐私 AI 系统存在的目的就是赋能 AI,使得各种 AI 场景下对用户隐私数据的使用都是安全的。那么,这样的系统就需要提供充分的保障,从理论到工程实现的每一个阶段都应该是经得起推敲、抵抗得住各种攻击的。不能简单的认为只需要各方先在本地自己的数据上计算出一个模型,然后将模型结果交换一下计算下其模型参数的平均值,就不会泄露各方的隐私数据了。现代密码学(Cryptography)是建立在严格的数学定义、计算复杂度假设和证明基础之上的,其中 MPC (Multi-Party Computation)方向是专门研究多个参与方如何正确、安全的进行联合计算的子领域, Rosetta、TF Encrypted 等隐私 AI 框架都采用了 MPC 技术以提供可靠的安全性。下面我们就结合具体案例看的看下在 Rosetta 中隐私数据是如何得到安全保护的。
案例
Alice, Bob 和 Charley 三人最近需要在他们的 AI 系统中引入对数据的隐私保护能力。他们很重视安全性,所以他们想通过一个简单的例子 —— 乘法(multiply),来验证下隐私 AI 框架是否真正做到了隐私安全。
他们约定:Alice 的输入为 1.2345;Bob 的输入为 5.4321;而 Charley 拿到相乘的结果。
他们按照 Rosetta 提供的教程,快速编写了如下代码(脚本名为 rosetta-mul.py):
接着,他们各自打开一个终端,分别进行如下操作:
Alice (P0) 在终端敲下如下命令行,并根据提示输入自己的私有数据:
Bob (P1) 执行同样的操作,输入的也是只有自己才知晓的私有数据:
Charley (P2) 在终端敲下如下命令行,等一会儿就可以得到所期望的计算结果:
注:
对于 Charley 来说,由于没有数据,故不会提示输入。
Alice 和 Bob 的本地输出都会是
z: [b'0.000000'], 而不会拿到正确的结果。
可以看出,Charley 拿到的最终结果与逻辑上明文结果(6.70592745)相比,误差(0.00001745)可以忽略不计。系统的正确性得到了验证。
如果想让误差更小,可以通过配置提升精度,或使用 128-bit 的数据类型。具体操作可以参考文档。
上面短短的几行代码,虽然结果是正确的,但是他们三人对于系统安全性方面仍有一些困惑:
Alice、Bob 的私有输入会不会被另外两方知道?
Charley 拿到的结果会不会被 Alice 、 Bob 知道?
整个程序运行过程中,有没有其他数据的泄漏?
如果前几问的回答都是否定的,那 Charley 又是如何得到明文?
在回答这些问题之前,为简化描述、突出本质,我们需要简单介绍一下 MPC 实际落地中常用的安全假设。
假定系统中有 3 个节点,P0/P1/P2,其中 P0/P1 为数据参与方,而P2 是辅助节点,用于随机数生成。
只考虑半诚实(
Semi-Honest)安全模型,即三方都会遵守协议执行的流程,并且其中诚实者占多数(Honest-Majority),也就是说三个节点中只会有一个“坏人”。更为复杂的恶意(Malicious)模型等安全场景可参考其他相关论文。内部数据类型为 64 位无符号整型,即
uint64_t(这在理论上对应着在环 )。
下面我们就按照 输入–计算–输出 的顺序,详细介绍 Rosetta 中数据的表示与流动,以及所用到相关技术与算法在工程上的优化实现。
隐私数据的输入
隐私计算问题,首先要解决的是隐私数据的输入。
在上述案例中,是通过如下两行代码来完成私有数据的安全输入的:
如代码所示,
rtt.private_console_input是 Rosetta 众多 API 之一,Rosetta 还提供了rtt.private_input、rtt.PrivateDataset等 API,用来处理隐私数据的输入。
这里发生了什么?x,y 的值会是什么?
在进入剖析之前,先来了解一个重要的概念 —— 秘密分享。
秘密分享
什么是 秘密分享(Secret Sharing)[1]?先来看一种简单的两方 additive 的构造:
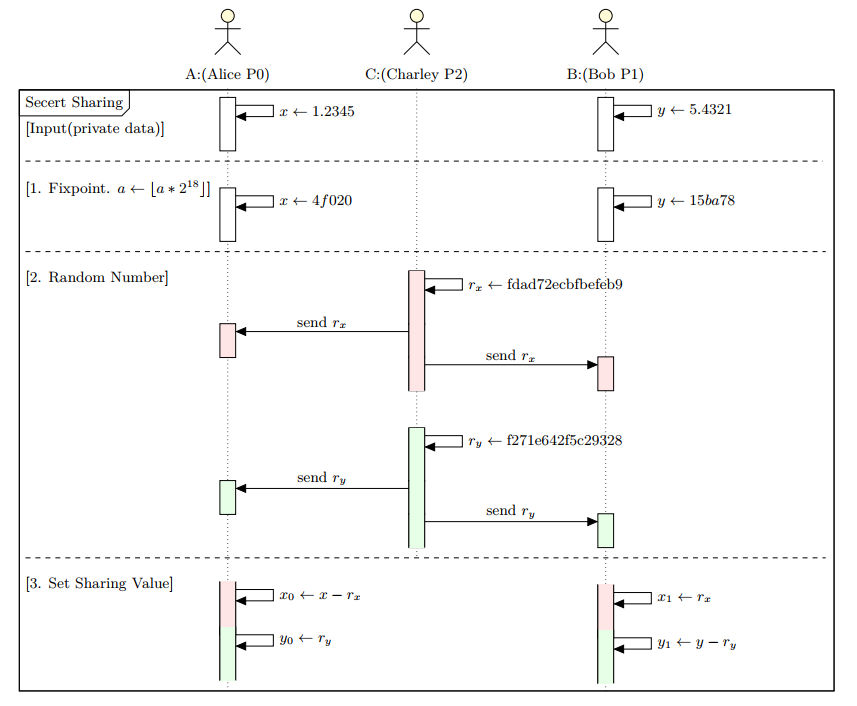
给定一个数 x,定义 share(x) = (x0, x1) = (x − r, r),其中 r 是随机数,并且与 x 独立。可以看到,x = x0 + x1 = x -r + r。原始数据 x 的秘密分享值 (x0, x1) 将会由两个数据参与方 (P0, P1) 各自保存。
在秘密分享的方案中,所有的数据,包括中间数值都会分享在两个参与方之间。直观的看,参与的两方不会得到任何的明文信息。理论上,只需要在环 上支持加法和乘法,就可以进一步通过组合来支持上层各种更复杂的函数。下文我们会看到关于乘法的详细解析,读者可以回过头来再看这段话。
那工程上是如何处理的呢?假设 P0 有一个私有数据 x,三方之间可以简单交互一下实现:
方案 1:
P2生成一个随机数r,发送给P0/P1。然后P0本地设置x0 = x - r,P1本地设置x1 = r。此时share(x) = (x0, x1) = (x - r, r),与上面的定义一致。
这是方案之一,后文基于这个方案进行讲解。在本文最后,我们会提一下实际落地时的进一步优化方案。
回到主线,结合 方案 1,我们以 Alice 的输入值 x = 1.2345 为例看下具体过程。
第一步,浮点数转定点数。
对于有数据输入的一方,需要先将真实的浮点数转成定点数。
浮点数转定点数:即浮点数乘以一个固定的缩放因子(scale,一般为)使其变成定点数(取其整数部分,舍弃小数部分)。当最后需要还原真实的原始浮点数时,用定点数除以缩放因子即可。
我们先选定一个缩放因子,这里取 scale = 。
经过缩放后,得到 x = 1.2345 * (1<<18) = 323616.768,取整数部分即 323616,用于后续计算。
这里是有精度损失的,但在精度允许的范围内,不会影响后面的计算。
第二步,生成随机数 r。 也叫掩码(Masking value),用来隐藏真实值。
P2 生成一个随机数 r,是一个 64-bit 空间的无符号整数。(如,r = fdad72ecbfbefeb9。这里用十六进制表示,下同)
P2 将 r 发送给 P0,P1。此时,P0,P1 都拥有一个相同的随机数 r 了。
第三步,设置秘密分享值。
按秘密分享 方案 1 的定义,P0 本地设置 x0 = x - r,P1 本地设置 x1 = r。所以有:
P0:x0 = 4f020 - fdad72ecbfbefeb9 = 2528d134045f167
P1:x1 = fdad72ecbfbefeb9
4f020是 323616 的十六进制表示。如果计算结果大于 64 bit 的空间范围,需要对结果取模(64 位空间)。下同。
至此,我们获得了关于 x 的分享值,share(x) = (x0, x1) = (x - r, r) = (2528d134045f167, fdad72ecbfbefeb9)。
感兴趣的读者朋友可以验证一下 (x0 + x1) mod 。
同理,我们对 Bob 的输入值进行一样的处理。
上面三步,其实就是 private_console_input 的工作机制与过程。经过处理后,各方本地都存储着如下值:
我们用
Xi,Yi表示X,Y在Pi的分享值。(下同)
P2为何是 0 呢?在本方案中P2作为一个辅助节点,不参与真正的逻辑计算。
我们可以看到,在处理隐私数据输入的整个过程中,P0 无法知道 y 值,P1 无法知道 x 值,P2 无法知道 x 或 y 值。
最后,我们总结一下这三个主要阶段:
密文上的协同计算
这是计算的核心。
上一步,我们保证了输入的安全,没有信息的泄漏,各方无法单独拿到其他节点的私有输入。
接下来,看一下计算的代码,只有一行:
在这个计算的过程中发生了什么?下面结合乘法(Multiply) 算子原理进行实例讲解。
Multiply 算子原理
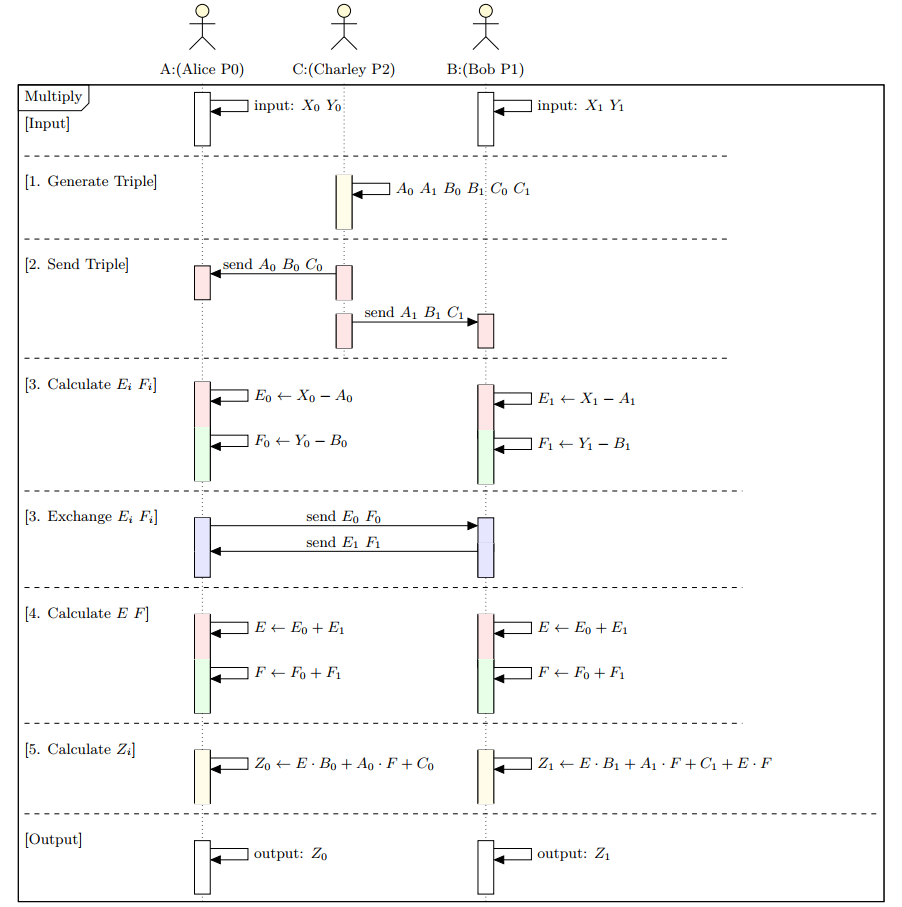
乘法相对较为复杂,我们结合经典的 Beaver Triple 方法[2]加以介绍。该方法是由密码学家 Donald Beaver 在 1991 年提出,主要思想是通过乘法。协议基本原理如下:
输入: P0 拥有 X,Y 的秘密分享值 X0,Y0;P1 拥有 X,Y 的秘密分享值 X1,Y1。
这里有
share(X) = (X0, X1),share(Y) = (Y0, Y1)。在此案例中,这里的输入,就对接上一节所述的"隐私输入"的输出结果。
计算步骤:
P2本地生成一组随机数A,B,C,且满足C = A * B。
A,B,C 的生成步骤:P2 随机生成 A0,A1,B0,B1,C0,令 A = A0 + A1, B = B0 + B1,得到 C = A * B, C1 = C - C0。其中 Ai,Bi,Ci 是 A,B,C 的分享值。 这些都是在 P2 本地完成的。这也就是 P2 做为辅助节点的作用(用于随机数生成)。
这里
A,B,C一般被称为三元组(Beaver’s Triple)。
比如,某次生成的随机数如下:
感兴趣的读者朋友可以验证一下。如
A = A0 + A1=2373edde1a0e5dcd+ad483b77e4e5db41=d0bc2955fef4390e。这个A是个随机数。
P2将上一步生成的随机数的秘密分享值分别发送给P0,P1。
即将 A0,B0,C0 发送给 P0;将 A1,B1,C1 发送给 P1。
此时,P0,P1 拥有如下值:
P0计算E0和F0;P1计算E1和F1。并交换Ei,Fi。
P0 本地计算 E0 = X0 - A0, F0 = Y0 - B0。
P1 本地计算 E1 = X1 - A1, F1 = Y1 - B1。
此时,P0,P1 拥有如下值:
交换 Ei,Fi。
P0 将 E0,F0 发送给 P1;P1 将 E1,F1 发送给 P0。此时,P0,P1 都拥有 E0,F0,E1,F1。
P0,P1本地计算 得到E和F。
P0,P1 各自本地计算 E = E0 + E1, F = F0 + F1。
P0本地计算Z0;P1本地计算Z1。
现在,P0 已经拥有 A0,B0,C0,E,F;P1 已经拥有 A1,B1,C1,E,F。有了这些就可以计算出 Z = X * Y 的秘密分享值 Z0,Z1 了。 即:
P0 本地计算 Z0 = E * B0 + A0 * F + C0;
P1 本地计算 Z1 = E * B1 + A1 * F + C1 + E * F。
正确性可以通过以下恒等式加以验证:
输出: P0,P1 分别持有 Z = X * Y 的秘密分享值 Z0,Z1。
我们可以看到,从输入到计算再到输出,整个过程中,没有泄漏任何隐私数据。
整个算子计算结束时, P0 单独拥有 X0,Y0,A0,B0,C0,E0,F0,E1,F1,E,F,Z0,P1 单独拥有 X1,Y1,A1,B1,C1,E0,F0,E1,F1,E,F,Z1,P2 单独拥有 A0,B0,C0,A1,B1,C1,三方都无法单独得到 X 或 Y 或 Z。
最后,我们总结一下(1~5 对应着上面的步骤):
获取明文结果
从输入到计算再到输出,各节点只能看到本地所单独拥有的秘密分享值(一些毫无规律的 64 位随机数),从上文也可以看到,节点是无法独自得到任何隐私数据的。那么,当计算结束后,如果想得到结果的明文,怎么获取呢?
Rosetta 提供了一个恢复明文的接口,使用很简单。
那这个 rtt.SecureReveal 是如何工作的呢?
其实非常简单:如果本方想要知道明文,只需要对方把他的秘密分享值发给我,然后本地相加即可。
比如,上一节结尾处,我们知道了各方 (P0/P1/P2) 的分享值如下:
结合实例,Charley (P2) 想要获取结果明文,那么,P0,P1 将各自的分享值 Z0,Z1 发给 P2,然后 P2 本地相加即可。即: 1db35d14c12a + ffffe24ca30611b0 = 1ad2da (1757914)。我们将此值进一步再转换为浮点数,就可以得到我们想要的用户态的明文值了: 1757914 / (1 << 18)= 6.7059097 !
效率优化
上面介绍的 秘密分享 与 multiply 算子 都是基于最基本的算法原理,在时间上和通信上的开销还是比较大的,在实际工程实现中,还可以进一步进行优化以提升性能。在介绍优化方案之前,先了解一下 什么是 PRF?
PRF[3],Pseudo-Random Function。 简单来说,即给定一个随机种子 key,一个计数器 counter,执行 PRF(key, counter) ,会得到一个相同的随机数。
补充说明一下。例如,
P0,P1执行PRF(key01, counter01),会产生一个相同的随机数。这里的key01,counter01对于P0,P1来说是一致的。程序会维护这两个值,对使用者来说是透明的。
关于秘密分享
来看看优化版本(假设: P0 有一个私有数据 x)。
方案 2(优化版):
P0,P1使用PRF(key01, counter)本地同时生成一个相同的随机数r。然后P0本地设置x0 = x - r,P1本地设置x1 = r。此时share(x) = (x0, x1) = (x - r, r),与定义一致。此版本无需P2的参与。没有通信开销。
目前 Rosetta 开源版本中使用的正是此方案。
方案 3(优化版):
P0设置x0 = x,P1设置x1 = 0即可。此时share(x) = (x, 0)。此版本无需P2的参与。没有通信开销,也没有计算开销。
上述各个版本(包括方案 1),都是可行且安全的。可以看到P1/P2 并不知道 P0 的原始输入值。
关于 Multiply 算子
Multiply 算子中输入,输出部分没有变化,主要是计算步骤中的第 1 步与第 2 步有些许变化,以减少通信量。这里也只描述这两步,其余与前文相同。
在上文的描述中,我们知道 P2 生成三元组后,需要将其分享值发送给 P0,P1。当我们有了 PRF 后,可以这么做:
P0,P2使用PRF(key02, counter02)同时生成A0,B0,C0;P0,P1使用PRF(key12, counter12)同时生成A1,B1。然后,
P2令A = A0 + A1, B = B0 + B1,得到C = A * B, C1 = C - C0。P2将C1发送给P1。P2的任务完成。目前 Rosetta 开源版本中使用的是此方案。
相比于原始版本,优化版本只需要发送 C1,不用再发送 A0,A1,B0,B1,C0。
在 Rosetta 中,我们还针对具体的各个不同的算子进行了一系列的算法、工程优化,欢迎感兴趣的读者来进一步了解。
小结
安全性是隐私 AI 框架的根本,在本篇文章中,我们结合隐私数据输入的处理和密文上乘法的实现,介绍了“随机数” 形式的密文是如何在多方之间流动,同时“神奇”的仍能保证计算逻辑的正确性的。我们这里对于安全性的说明是直观上的描述,而实际上,这些算法的安全性都是有严格数学证明的。感兴趣的读者可以进一步去探索相关的论文。
Rosetta 将持续集成安全可靠的密码学算法协议作为“隐私计算引擎”到框架后端中,也欢迎广大开发者参与到隐私 AI 的生态建设中来。
参考文献
[1] 秘密共享,https://en.wikipedia.org/wiki/Secret_sharing
[2] Beaver, Donald. “Efficient multiparty protocols using circuit randomization.” Annual International Cryptology Conference. Springer, Berlin, Heidelberg, 1991.
[3] PRF 的一个简单介绍,https://crypto.stanford.edu/pbc/notes/crypto/prf.html
作者介绍:
Rosetta 技术团队,一群专注于技术、玩转算法、追求高效的工程师。Rosetta 是一款基于主流深度学习框架 TensorFlow 的隐私 AI 框架,作为矩阵元公司大规模商业落地的重要引擎,它承载和结合了隐私计算、区块链和 AI 三种典型技术。目前 Rosetta 已经在 Github 开源(https://github.com/LatticeX-Foundation/Rosetta) ,欢迎关注并参与到 Rosetta 社区中来。
系列文章:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论