

《I Heart Logs 》出版于 2014 年,是一本很短小的书。作者 Jay Kreps,是前 LinkedIn 的 Principal Staff Engineer,也是 LinkedIn 许多著名开源项目的负责人及联合作者,如 Kafka、Voldemort 等。他是现任 Confluent 的 CEO,主要工作在于围绕实时数据提供企业级服务支持。这本书算是 Jay Kreps 过去多年实践的思考结晶。本文主要是对书中的一些看法、观点的梳理,有兴趣可以阅读原著或博客。
注:本文大部分图片、内容来自于原著或原博客。
日志即数据
在讨论日志之前,首先要明确日志的含义。这里的日志并非指我们常用的非结构化或半结构化的服务日志,而更接近数据库中常见的结构化的提交日志 (commit log/journal/WAL),这些日志通常是只往后追加数据,这里的序号暗含着逻辑时间,标识着连续日志产生的逻辑先后顺序:
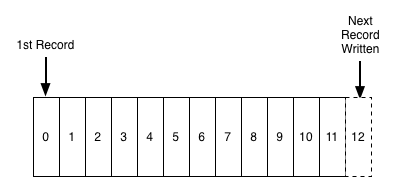
数据库中的日志
日志在数据库中常常被用来实现故障恢复、数据复制、最终一致性等。一个事务提交成功与否在日志提交成功时就可以确定,只要 WAL 落盘,便可告诉客户端提交成功,即便数据库发生故障,也能从 WAL 日志中恢复数据;日志 (如 BinLog) 的 pub/sub 机制可以用来在主节点与复制节点之间同步数据,通过同步的进度可以知道不同复制节点的同步进度,此外日志的逻辑顺序保证了主节点与复制节点之间数据的一致性。
分布式系统中的日志
数据库利用日志来解决的问题,也是所有分布式系统需要解决的根本问题,如刚才提到的故障恢复、数据同步、数据一致性等等,可以称之为以日志为中心 (log-centric) 的解决方案。更严谨地说:
如果两个相同的 (identical)、确定 (deterministic) 的进程以相同的状态启动,按相同的顺序获取相同的输入,它们将最终达到相同的状态。
这就是状态机复制原则 (state machine replication principle)。多个这样的进程,就组成了我们熟知的各种分布式系统。
日志为中心的设计
日志为中心的设计可以分为两种:主备 (primary backup) 和状态机复制 (state machine replication),如下图所示:
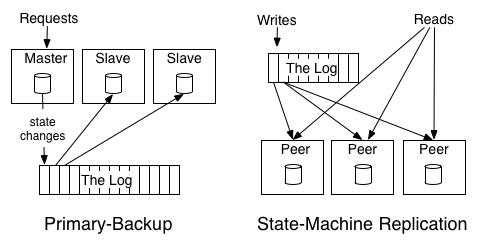
在主备模式中,主节点接收所有的读写请求,每条写入的数据被记录到日志中,从节点通过订阅日志、执行操作来同步数据状态。如果主节点发生故障,就在从节点中选择一个作为新的主节点;在状态机复制中,不存在主节点,所有的写操作先进入日志,所有节点都通过订阅日志,执行操作来生成本地状态。
日志与共识
我们提到的日志与共识算法中的日志似乎也有些相似,但也有所不同。共识通常指系统中的所有节点连续达成共识,在每个时刻只能达成一个共识,这些共识是线性一致的;在实践中,系统通常需要同时做多个决定,这些决定之间并没有绝对的先后顺序或因果关系。因此相较于共识,日志的抽象对于常见的分布式系统来说更加自然。
我们往往过于关注复杂的共识算法实现,而没有注意到日志抽象的实践意义,这一点比较反常。比如,当人们谈论 hash table 的时候,很少关注背后的实现是 murmur hash with linear probing 还是其它实现变种。未来,想必日志抽象会将更加常见,背后也将有很多算法和实现相互竞争,以提供最好的服务保证和最优的系统性能。
数据表与日志的对偶性
日志记录着数据表的变化,数据表记录着数据的最新状态。完整的操作日志可以让我们做时空穿梭,回溯到数据的任何一个历史状态。这与代码的版本管理系统有些类似,实际上代码仓库本身就是一个可以回退到任何历史状态的数据库。
更大的分布式数据库
实际上,我们可以将企业中的所有数据、数据流以及数据系统合起来看作是一个巨型分布式数据库。所有原始数据表就是数据库中的基础数据;所有面向查询的系统都是基于这个数据库之上建立的索引,如 Redis、ElasticSearch、Hive tables 等等;流式处理系统,如 Flink、Storm、Samza,是这个数据库中基于触发器的实体化视图机制 (trigger-and-view materialization mechanism);日志系统就是数据库的操作日志,记录数据的变化。
实践中,为了解决特定领域问题的数据系统层出不穷,主要原因在于要构建一个通用的分布式数据库难度巨大,将问题投影到具体的某个场景上能减小系统设计的复杂度,使得系统的构建变得容易。
拆分还是合并?
这个巨型分布式数据库的未来会向什么方向发展?作者认为有 3 种可能:
当前状态的延续,不同的系统继续处于割裂发展的状态,用非系统性的方案解决系统之间的数据集成问题
所有系统逐渐走向一统,也就不存在系统之间的数据集成问题
将开源项目视作乐高积木,每个团队根据需求构建自己的巨型分布式数据库
重要的积木:日志
在构建企业独特的巨型分布式数据库时,如果有了日志这块积木,其它系统的设计复杂度将得到降低。具体地说,日志系统可以用来:
序列化并发更新,处理数据一致性问题
支持节点间数据复制
向外部系统提供事务提交的语义
向外部系统提供日志订阅功能
向故障节点提供故障恢复能力
解决数据负载在节点间的平衡问题
…
解决了这些问题,巨型分布式数据库的查询层就只需要完成索引构建、暴露统一 API 的工作。抽象地思考,这个系统可以简单地分为两部分,Log 和 Serving Nodes:
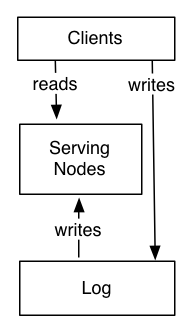
所有的数据直接写入 Log (或被 Serving Nodes 代理),然后所有的 Serving Nodes 通过订阅 Log 来建立索引,向外提供数据服务。这种设计就是以日志为中心 (log-centric) 的设计:
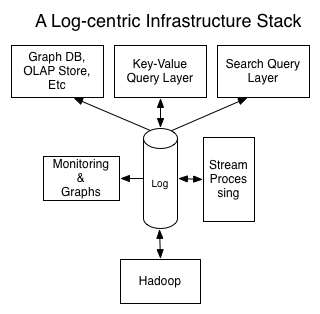
这个系统本身可以直接通过流处理器 (stream processor),将日志流直接或与其它数据结合,一同提供给其它索引服务。尽管 Kafka、BookKeeper、Pulsar 这些都是日志服务的候选,但这里所述的以日志为中心的设计仅仅是一种思想,你甚至可以利用类似 DynamoDB 来构建这样的日志服务,只不过你可能需要做一些额外的工作来支持日志应该提供的功能和保证。
日志与流处理、批处理
数据集成
数据集成 (Data Integration) 的意思是:
让企业中的所有服务和系统能访问其需要的任意企业数据
我们可以类比马斯洛需求层次理论,将企业对数据的需求也看作是一个金字塔状的结构:
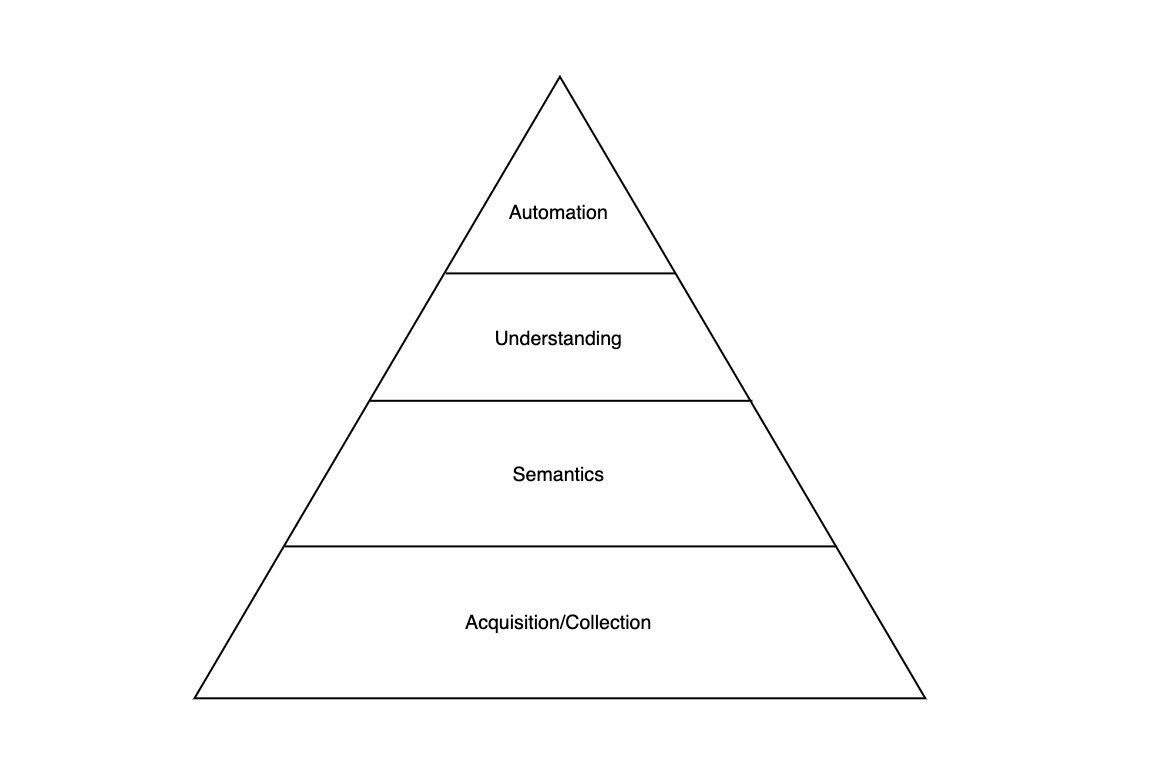
最底层是数据的收集和查询,让所有上层服务能够以简单、标准的形式读写。一旦数据的最基本需求得到满足,就可以基于此进一步做数据语义解析、数据理解和自动化。
数据集成的难点主要在以下两个方面:
数据的多元化:用户行为数据、机器指标统计、IoT 相关数据等
数据系统的爆炸式增长:OLAP、搜索引擎、对象存储、批处理系统、图数据库等
解决问题的方式有很多种,作者认为最自然的一种方案就是采用日志:
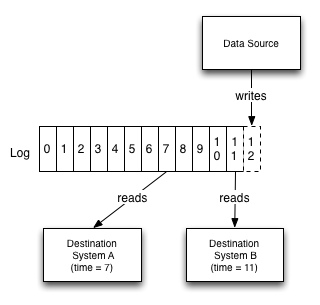
每个数据源都可以按照它的日志来建模,将数据源上发生的事件看作是连续的日志事件,即所谓的日志流。所有需要这些数据的系统就各自去订阅日志流,各自按照自己的需求、节奏来选择消费数据的量和速度。
批处理与流处理
书中提到一个很不错的例子:人口普查。人口普查的做法很像归并排序,先在最低级别的行政区域内挨家挨户搜集信息,聚合数据,然后逐层向上汇报,最终得到人口估计值。但这个过程通常十分漫长,每一层级人口数据的聚合都需要等待下级汇报的结果,等到最终得到人口普查结果时,其实又已经有很多人口出生了。这是典型的批处理场景。如果是流式处理该怎么做?每当有一个人出生或死亡,就直接上报到统计中心,由统计中心动态地聚合数据,理想情况下可以得到人口在每个时刻的规模。这就是典型的流处理场景。
日志与 ETL、数仓
数据仓库以适合离线数据分析的方式将企业内部的所有数据结构化地集成到一起,这是一个伟大的想法。数仓的建设需要周期性地从各种源数据库中抽取 (Extract) 数据,转化 (Transform) 成更好理解的形式,最后加载 (Load) 进中心化的数据仓库。一个存储所有企业数据的中心数据仓库内部拥有许多等待挖掘的价值。
然而,这种通过批处理的将数据整合到一起的方式并不能解决所有问题,其短板在于,一些消费数据的系统需要更加实时的反馈,比如搜索引擎建立索引、推荐系统持续优化、监控系统实时观察。将数据集成到一起的思想仍然是伟大的,但我们也许能够找到弥补批处理方案缺点的其它方案,来满足特点不同的数据需求,这就是日志为中心的方案。
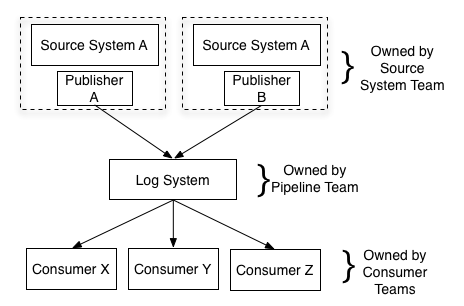
在这样的设计中,原来在 ETL 中的数据转化的工作应该放到哪个位置?大致有以下几种选择:
数据生产者在将数据写入日志系统前
对原始日志进行实时流式处理
在最终加载到数据消费系统时
其实这里我们并不需要做三选一的决定,而是将 ETL 的工作分类后分别放入这三部分中。数据生产者在生产数据时,需将数据转化成与系统内部逻辑无关的数据结构;在实时流式处理的过程中,可以将数据补充 (如 join) 的工作放入其中;在数据消费系统可以做最终的数据聚合 (aggregation)。
日志与流处理
为什么需要日志
日志与流处理是两个互相独立的概念。我们可以让分布式系统中的不同进程直接通信,直接实现流处理,那么我们为什么需要日志?有三个方面原因:
每个数据集可以被多个需求方订阅
维护单个消费者消费数据的先后顺序
提供缓冲区,让生产和消费的过程解耦
The Lambda Architecture
Nathan Marz 基于以日志为中心的思想,提出了 Lambda Architecture,来同时满足流处理和批处理需求,如下图所示:
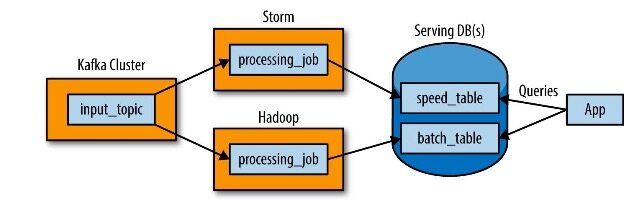
数据流同时被打向两个系统,流处理系统和批处理系统。你需要分别在流处理系统和批处理系统实现两次相同的写入处理逻辑,两个系统处理后写入最终向外提供查询接口的数据库中 (可能是不同的数据库)。Lambda Architecture 的好处在于,原始的输入数据会被原封不动地保留,同时也为重处理 (reprocessing) 留下空间,重处理是很重要的的功能,逻辑会随着业务变化而变化,这时候就需要对历史数据重处理,解决存量问题。
Lambda Architecture 的劣势在于需要维护两份类似的处理逻辑,一份用于流处理,一份用于批处理。当然也许你希望基于流处理和批处理再抽象出一层通用语言,就能复用逻辑。但这并不现实,即便是 ORM 的场景,将不同关系型数据库的接口聚合,都会遇到各种抽象泄漏的情况,就更不用说这种底层差异更大的数据系统场景了。
用流处理代替批处理
如果我们能用流处理代替批处理,就能让架构更加简洁,设计更加统一,开发者也无须维护两份相似的处理逻辑:
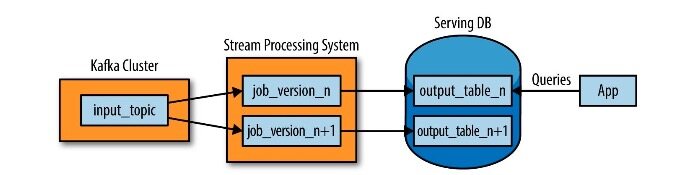
其实整个过程很简单:
使用类似 Kafka 的日志系统保存你需要重新处理的一段时间内的日志,订阅者就可以从任意时间点开始重处理数据。假如你希望提供重处理最近 30 天数据的能力,就将 Kafka 的留存策略设置成 30 天。
当你想要重处理时,启动一个新的 job 从头开始消费数据,执行处理逻辑,并将结果写出到新表 (output_table_n+1)
当新的 job 处理完成或追上旧的 job 时,就可以让应用从新的表中读取数据
最后将旧的 job 停止,并删除旧表
有状态的流处理
有时在流处理的过程中我们还需要 join 其它数据来获取所需信息,如果处理每条数据都需要访问数据库,将使得整个过程变得缓慢。以 LinkedIn 的一个应用场景为例,Who viewed your profile,即查看谁访问过我的个人资料:
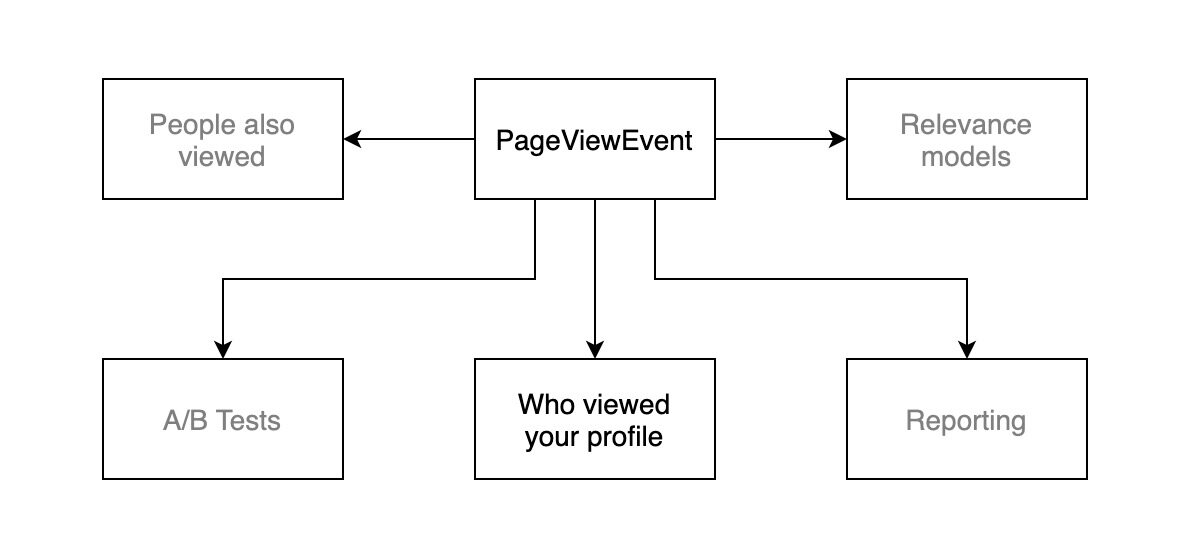
原始数据就是用户访问的事件流,每个事件的数据结构大致如下:
这时在订阅并处理事件数据时,就需要将 viewer 的 profile 信息填充上:
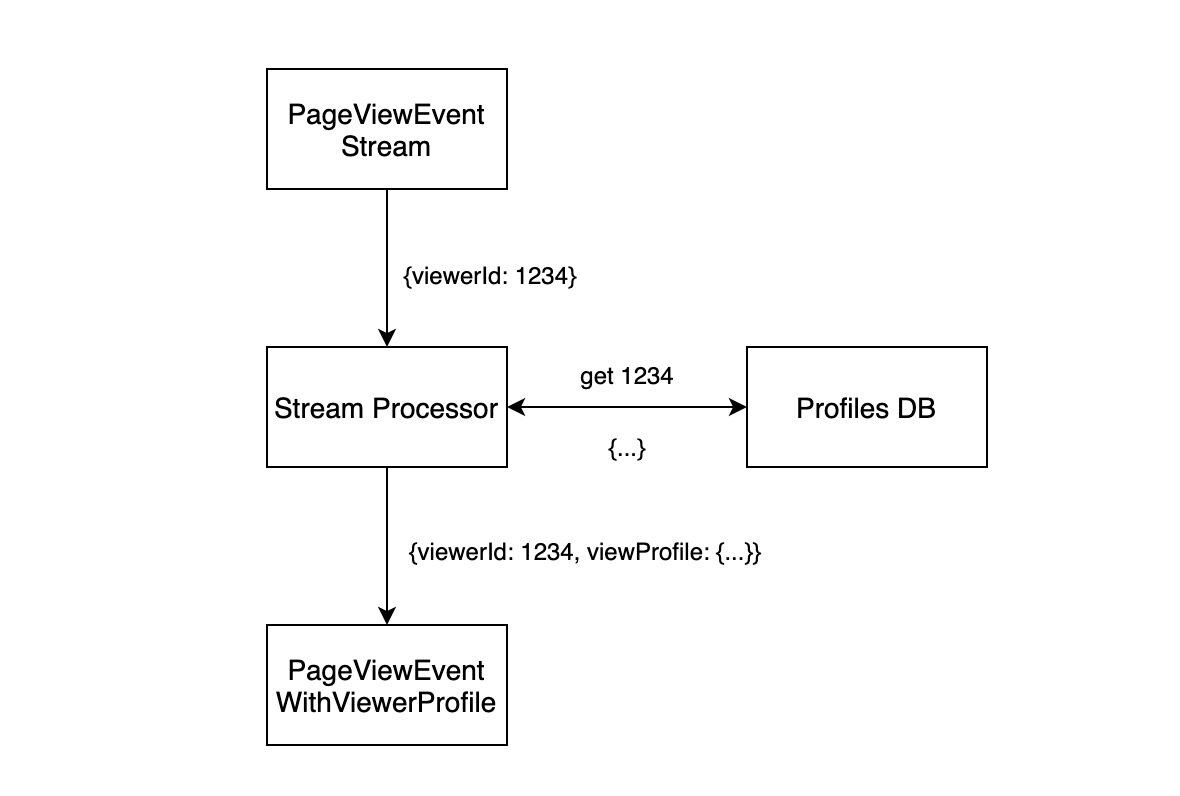
最简单的方法就是从数据库取,那么每次重新处理就是一次全量数据获取,可能还会影响线上 OLTP 服务的稳定性。自然而然地,我们又想到在数据库和流处理之间加一层缓存:
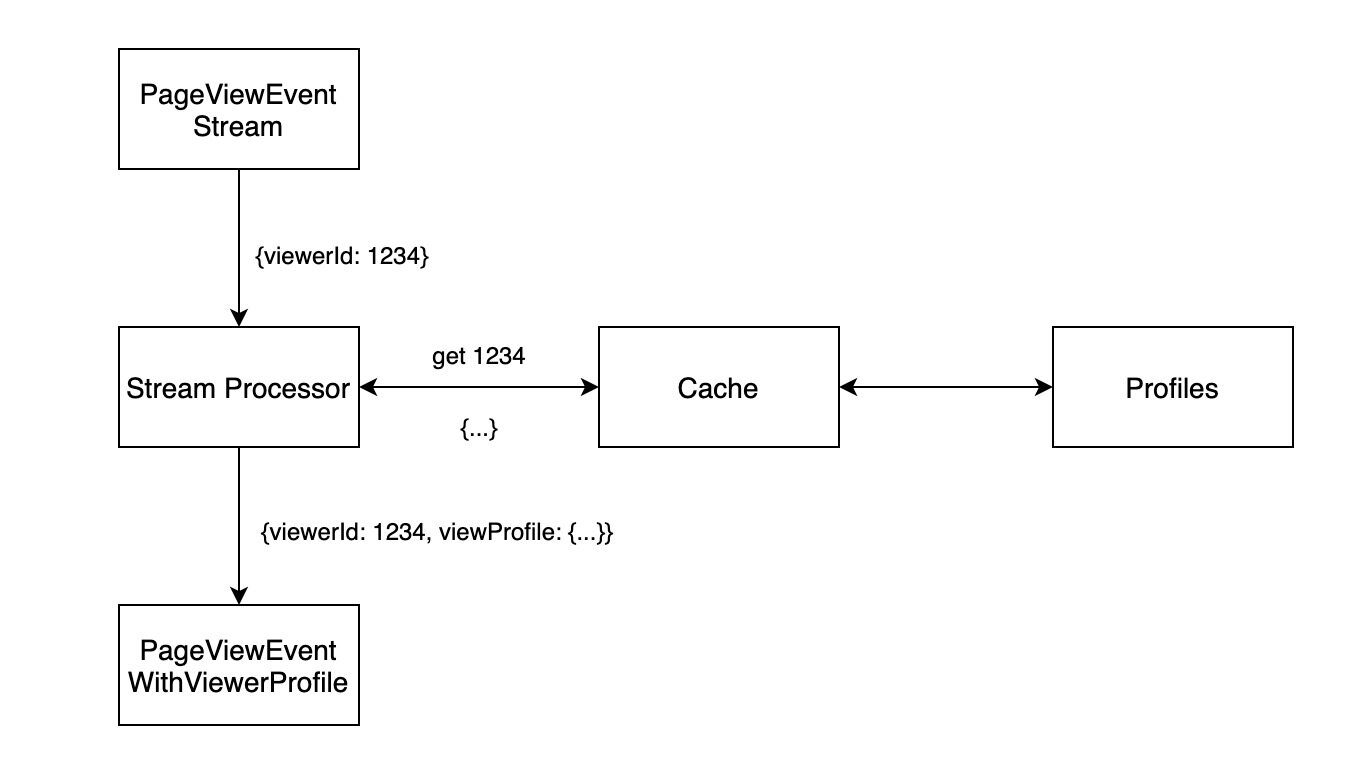
那么我们何不将缓存做进流处理器中?
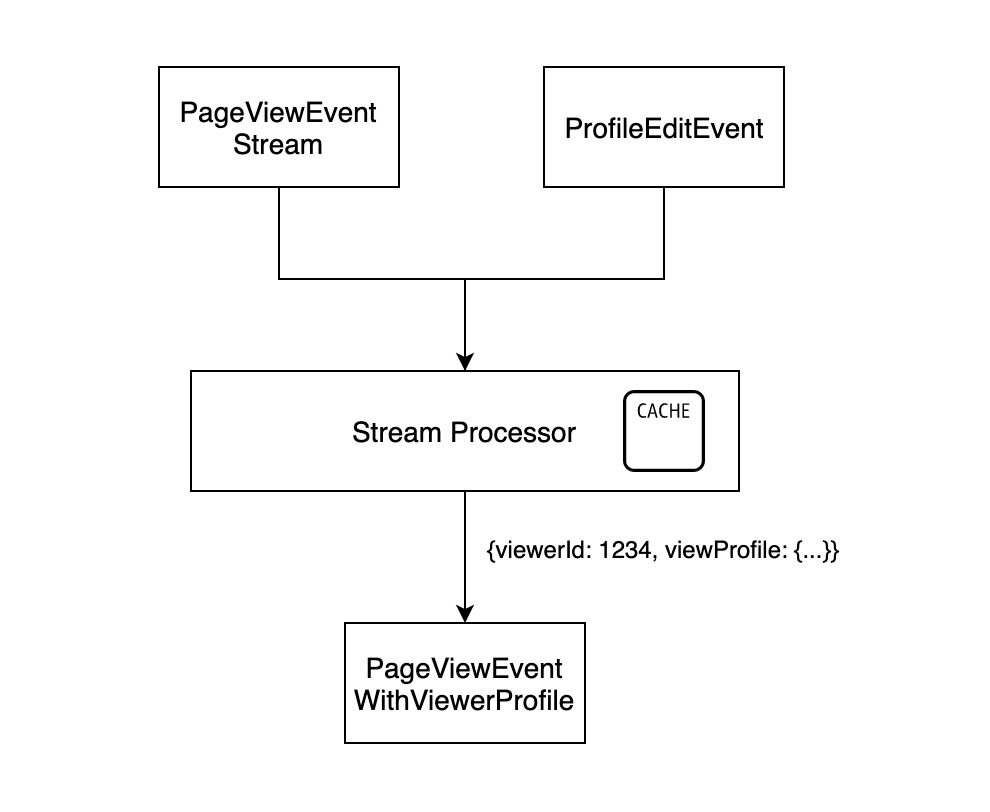
然后订阅 profile 的修改事件 (ProfileEditEvent),更新流处理器本地的数据库,这样还能保证数据的最终一致,避免访问线上 OLTP 服务。这就是有状态的流处理。
小结
本书将企业中的数据、数据流、各种数据服务系统看作是一个巨型的分布式数据库,日志就是这个数据库系统的操作日志,记录着所有历史增量数据,并以此为基础,提出以日志为中心的设计思想,并讨论了许多数据处理场景的不同处理方案,耐人寻味。
参考文献
Big Data: Principles and best practices of scalable realtime data systems
Building real-time data products at LinkedIn with Apache Samza
The Log: What every software engineer should know about real-time data’s unifying abstraction

中国开源发展研究分析 2022
本次报告为开发者,技术管理者,开源社区运营、市场,开源办公室工作人员带来信息上的增量以及对开源趋势、...









评论 4 条评论