

Kubernetes Serivce 是一组具有相同 label Pod 集合的抽象(可以简单的理解为集群内的 LB),集群内外的各个服务可以通过 Service 进行互相通信。但是 Service 的类型有多种,每种类型的 Service 适合怎样的场景以及 kube-proxy 是如何实现 Service 负载均衡的将是本文讨论的重点。
1 Service 和 kube-proxy 在 kubernetes 集群中的工作原理
在介绍 Service 和 kube-proxy 之前,先绍下它们在 Kubernetes 集群中所起到的作用。
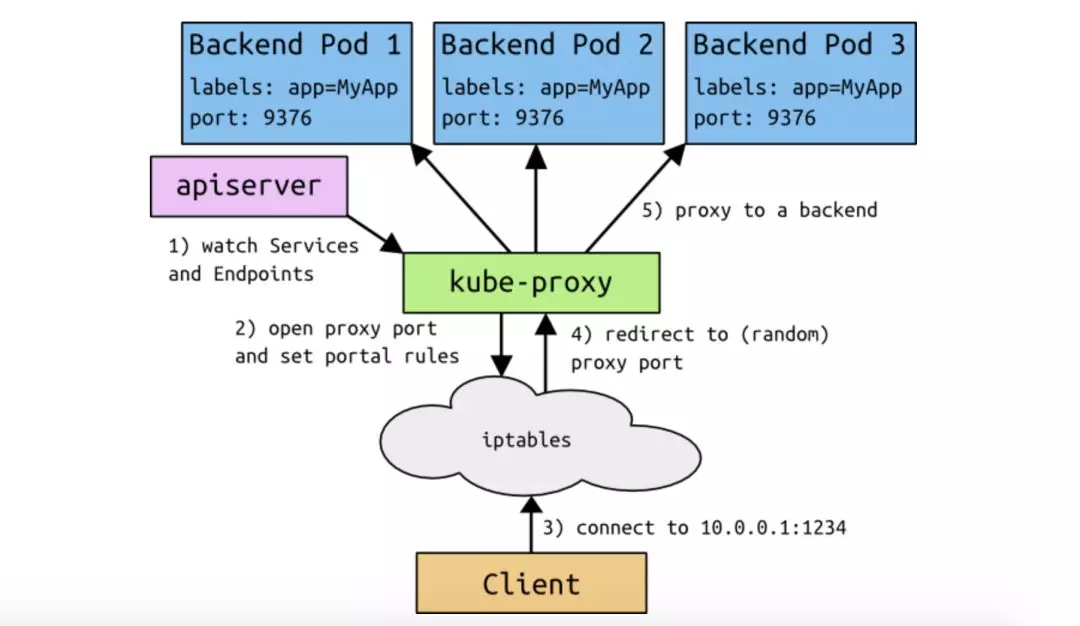
让我们分析下上面这张图:
运行在每个 Node 节点的 kube-proxy 会实时的 watch Services 和 Endpoints 对象。
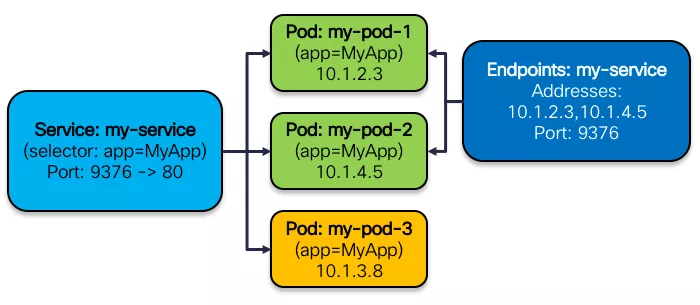
当用户在 kubernetes 集群中创建了含有 label 的 Service 之后,同时会在集群中创建出一个同名的 Endpoints 对象,用于存储该 Service 下的 Pod IP. 它们的关系如下图所示:
2.每个运行在 Node 节点的 kube-proxy 感知到 Services 和 Endpoints 的变化之后,会在各自的 Node 节点设置相关的 iptables 或 IPVS 规则,用于之后用户通过 Service 的 ClusterIP 去访问该 Service 下的服务。
3.当 kube-proxy 把需要的规则设置完成之后,用户便可以在集群内的 Node 或客户端 Pod 上通过 ClusterIP 经过 iptables 或 IPVS 设置的规则进行路由和转发,最终将客户端请求发送到真实的后端 Pod。
对于 kube-proxy 如何设置 Iptables 和 IPVS 策略后续会讲。接下来先介绍下每种不同类型的 Service 的使用场景。
2 Service 类型
当前 Kubernetes Service 支持如下几种类型,并在介绍类型的同时便可以了解每种类型的 Service 的具体使用场景。
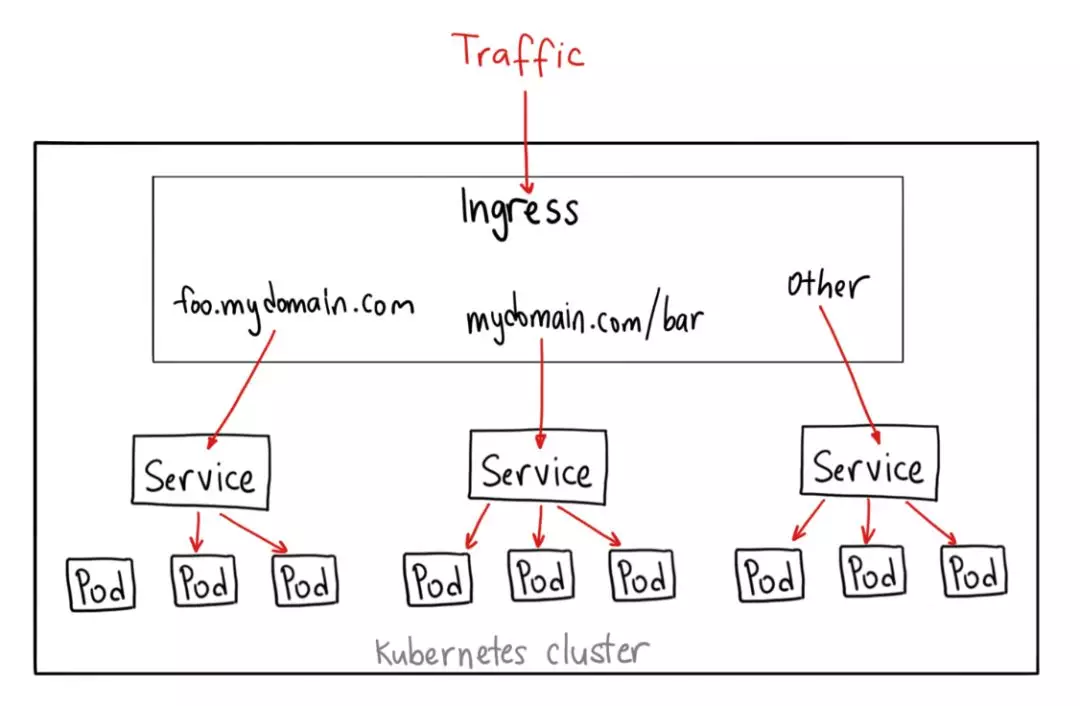
ClusterIP
ClusterIP 类型的 Service 是 Kubernetes 集群默认的 Service, 它只能用于集群内部通信。不能用于外部通信。
ClusterIP Service 类型的结构如下图所示:
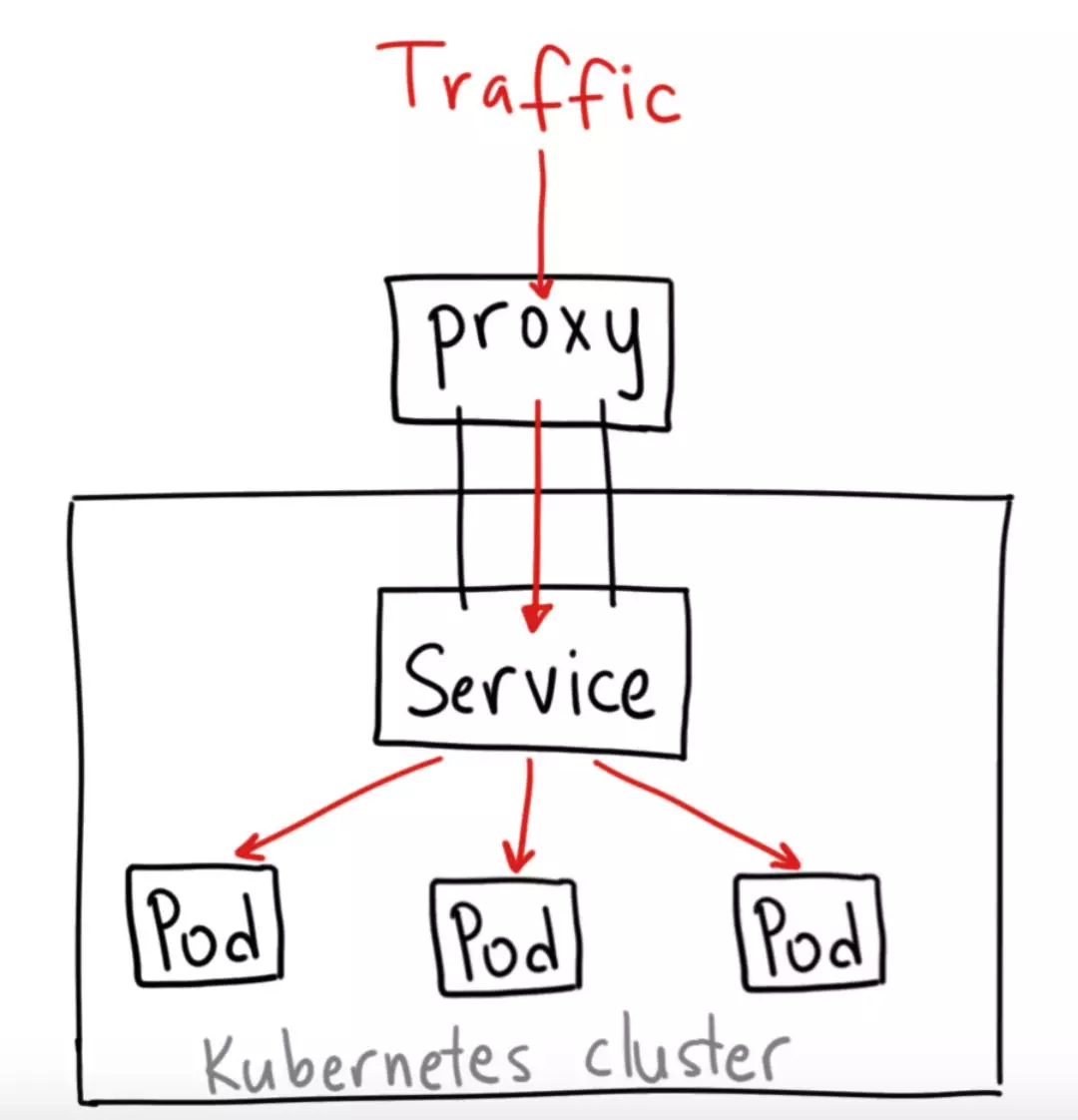
NodePort
如果你想要在集群外访问集群内部的服务,你可以使用这种类型的 Service。NodePort 类型的 Service 会在集群内部的所有 Node 节点打开一个指定的端口。之后所有的流量直接发送到这个端口之后,就会转发的 Service 去对真实的服务进行访问。
NodePort Service 类型的结构如下图所示:
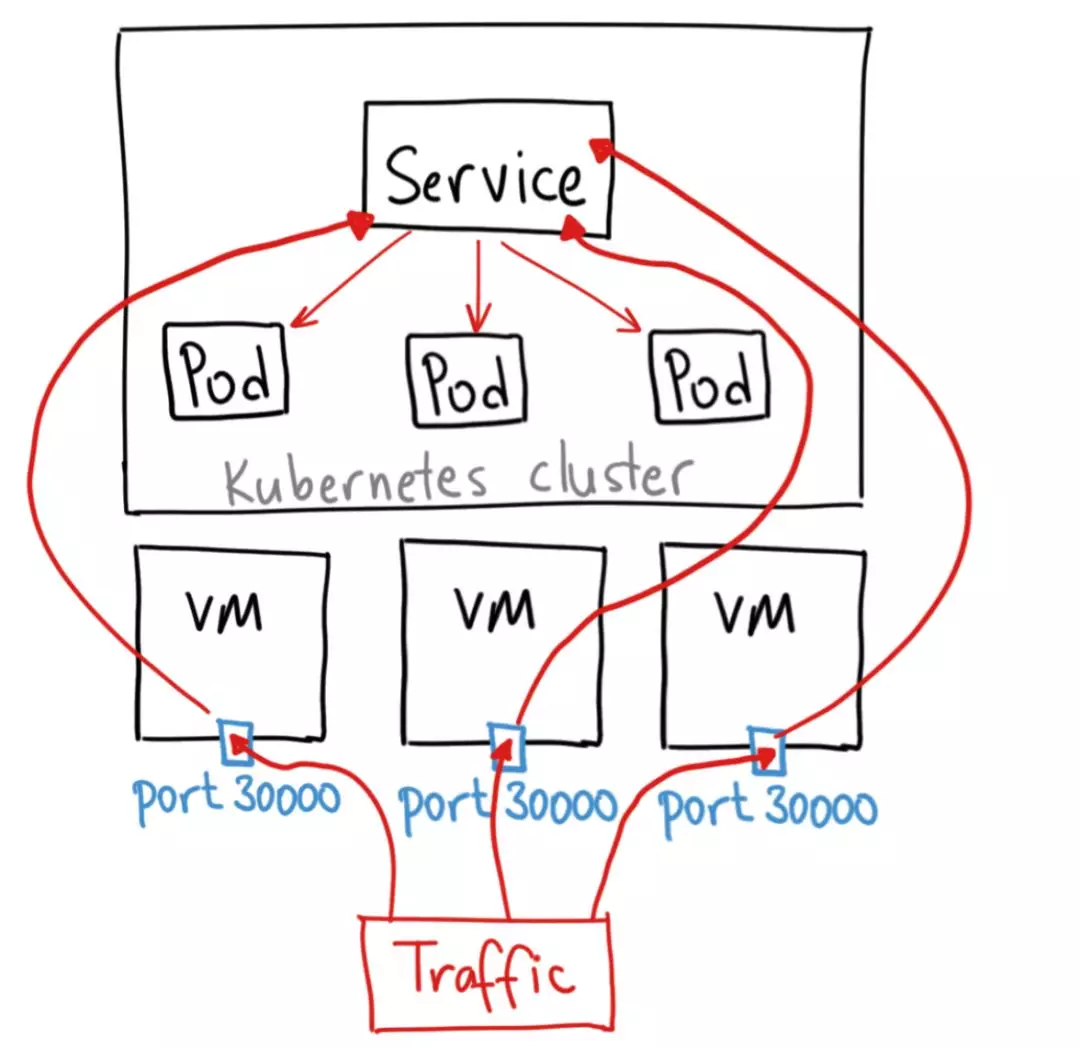
LoadBalancer
LoadBalancer 类型的 Service 通常和云厂商的 LB 结合一起使用,用于将集群内部的服务暴露到外网,云厂商的 LoadBalancer 会给用户分配一个 IP,之后通过该 IP 的流量会转发到你的 Service.
LoadBalancer Service 类型的结构如下图所示:
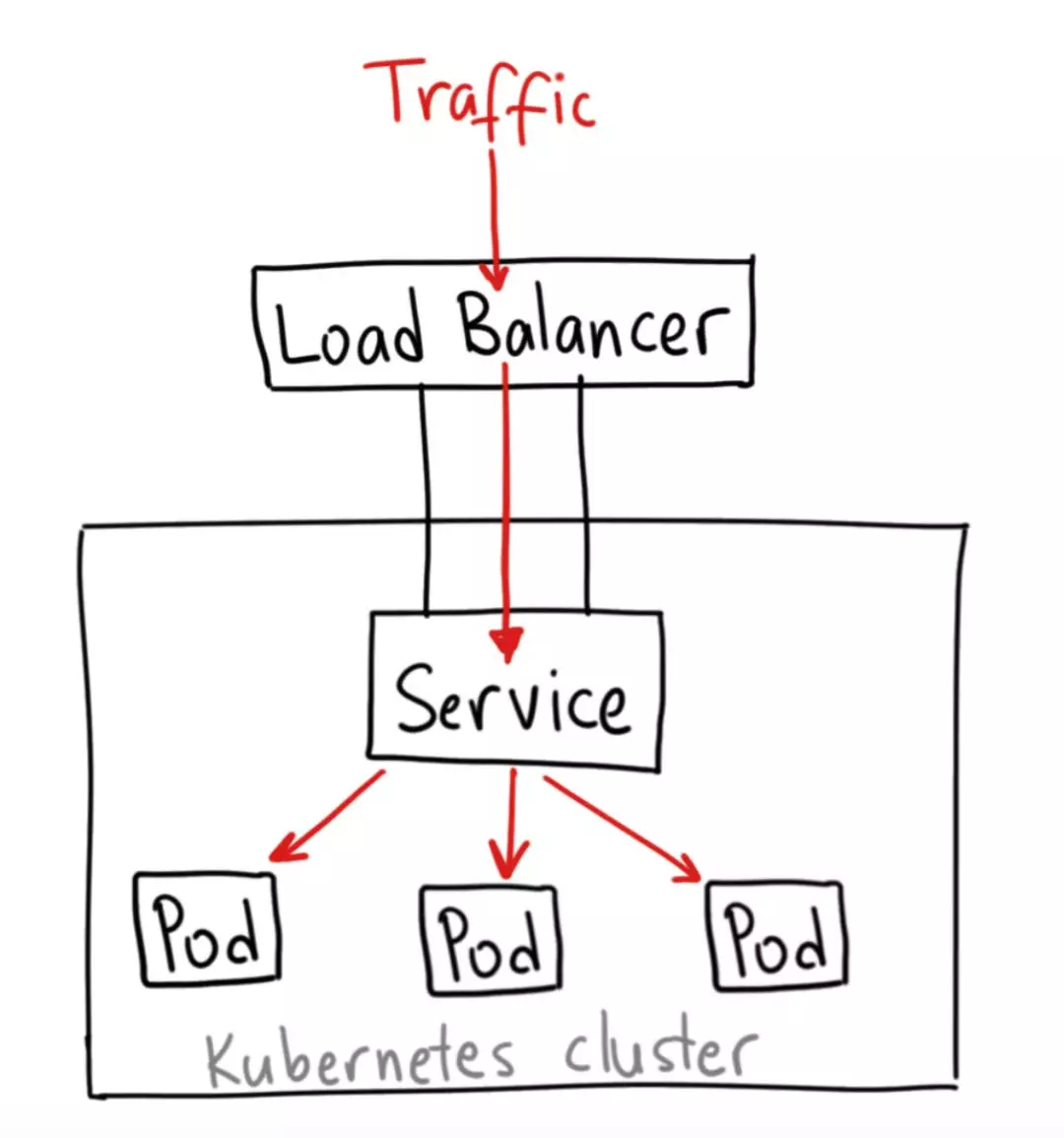
Ingress
Ingress 其实不是 Service 的一个类型,但是它可以作用于多个 Service,作为集群内部服务的入口。
Ingress 能做许多不同的事,比如根据不同的路由,将请求转发到不同的 Service 上等等。
Ingress 的结构如下图所示:
3 Service 服务发现
Service 当前支持两种类型的服务发现机制,一种是通过环境变量,另一种是通过 DNS。在这两种方案中,建议使用后者。
环境变量
当一个 Pod 创建完成之后,kubelet 会在该 Pod 中注册该集群已经创建的所有 Service 相关的环境变量,但是需要注意的是,Service 创建之前的所有的 POD 是不会注册该 Service 的环境变量的,所以在平时使用时,建议通过 DNS 的方式进行 Service 之间的服务发现。
DNS
可以在集群中部署 CoreDNS 服务(旧版本的 kubernetes 集群使用的是 kubeDNS), 来达到集群内部的 Pod 通过 DNS 的方式进行集群内部各个服务之间的通讯。
当前 kubernetes 集群默认使用 CoreDNS 作为默认的 DNS 服务,主要原因是 CoreDNS 是基于 Plugin 的方式进行扩展的简单,灵活。并且不完全被 Kubernetes 所捆绑。
4 Service 负载均衡
在本文的最初已经介绍了 service 和 kube-proxy 在集群中是如何配合来达到服务的负载均衡。kube-proxy 在其中起到了关键性的作用,kube-proxy 作为一个控制器,作为 k8s 和 Linux kernel Netfilter 交互的一个枢纽。监听 kubernetes 集群 Services 和 Endpoints 对象的变化,并根据 kube-proxy 不同的模式(iptables or ipvs), 对内核设置不同的规则,来实现路由转发。接下来分别介绍下 kube-proxy 基于 Iptables 和 IPVS 两种模式实现 Service 负载均衡的工作机制。
Iptables 实现负载均衡
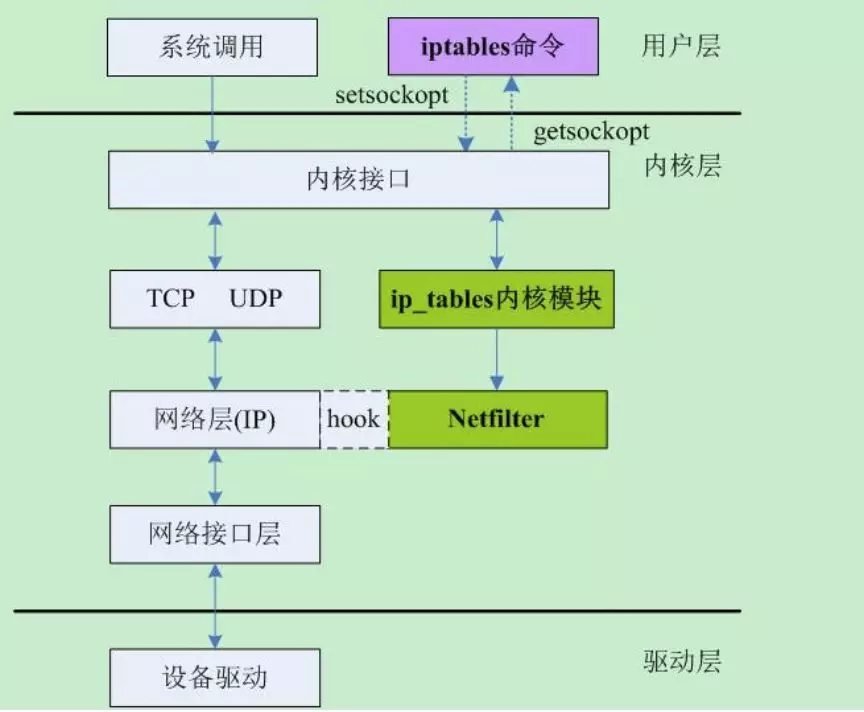
Iptables 是一个用户态程序,通过配置 Netfilter 规则来构建 Linux 内核防火墙。Netfilter 是 Linux 内核的网络包管理框架,提供了一整套的 hook 函数的管理机制,使得诸如数据包过滤,网络地址转换(NAT)和基于协议类型的连接跟踪成为了可能,Netfilter 在内核中的位置如下图所示。
接下来介绍 kube-proxy 是如何利用 Iptables 做负载均衡的。数据包在 Iptables 中的匹配流程如下图所示:
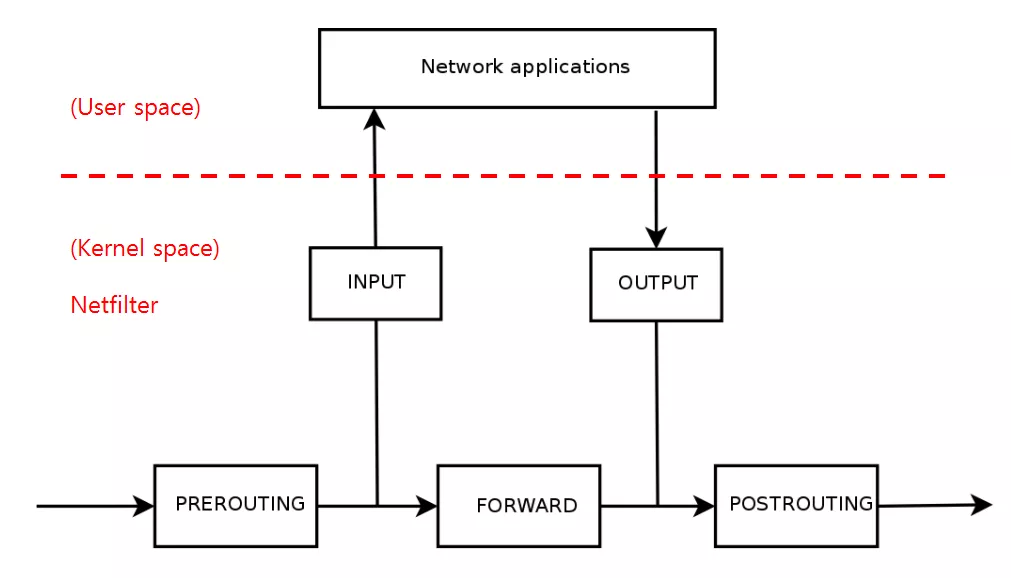
在 Iptables 模式下,kube-proxy 通过在目标 node 节点上的 Iptables 中的 NAT 表的 PREROUTIN 和 POSTROUTING 链中创建一系列的自定义链(这些自定义链主要是”KUBE-SERVICE”链, “KUBE-POSTROUTING”链,每个服务对应的”KUBE-SVC-XXXXXX”链和”KUBE-SEP-XXXX”链),然后通过这些自定义链对流经到该 Node 的数据包做 DNAT 和 SNAT 操作从而实现路由,负载均衡和地址转化,如下图所示:
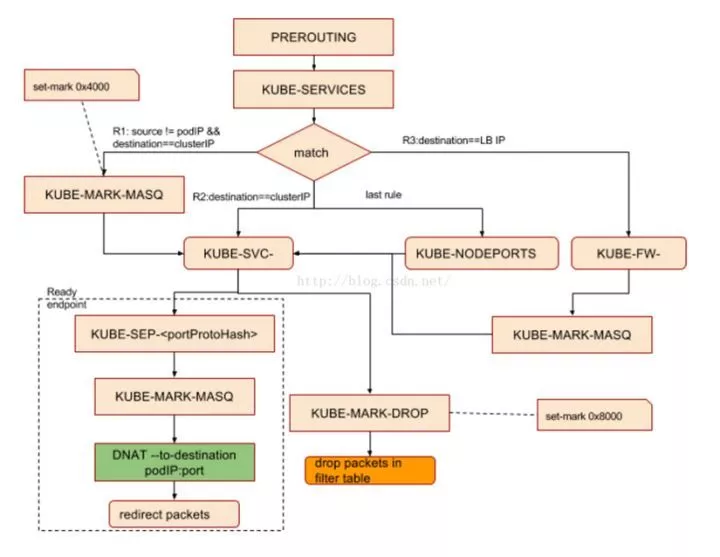
kube-proxy 中,客户端的请求数据包在 Iptables 规则中具体的匹配过程为:
1.PREROUTING 链或者 OUTPUT 链(集群内的 Pod 通过 clusterIP 访问 Service 时经过 OUTPUT 链, 而当集群外主机通过 NodePort 方式访问 Service 时,通过 PREROUTING 链,两个链都会跳转到 KUBE-SERVICE 链)


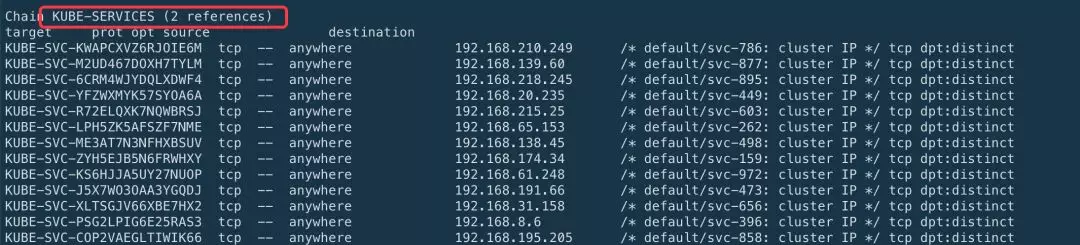
2.KUBE-SERVICES 链(每一个 Service 所暴露的每一个端口在 KUBE-SERVICES 链中都会对应一条相应的规则,当 Service 的数量达到一定规模时,KUBE-SERVICES 链中的规则的数据将会非常的大,而 Iptables 在进行查找匹配时是线性查找,这将耗费很长时间,时间复杂度 O(n))
3.KUBE-SVC-XXXXX 链 (在 KUBE-SVC-XXXXX 链中(后面那串 hash 值由 Service 的虚 IP 生成),会以一定的概率匹配下面的某一条规则执行,通过 statistic 模块为每个后端设置权重,已实现负载均衡的目的,每个 KUBE-SEP-XXXXX 链代表 Service 后面的一个具体的 Pod(后面那串 hash 值由后端 Pod 实际 IP 生成),这样便实现了负载均衡的目的)

4.KUBE-SEP-XXXX 链 (通过 DNAT,将数据包的目的 IP 修改为服务端的 Pod IP)

5.POSTROUTING 链

6.KUBE_POSTROUTING 链 (对标记的数据包做 SNAT)

通过上面的这个设置便实现了基于 Iptables 实现了负载均衡。但是 Iptbles 做负载均衡存在一些问题:
规则线性匹配时延:
KUBE-SERVICES 链挂了一长串 KUBE-SVC-*链,访问每个 service,要遍历每条链直到匹配,时间复杂度 O(N)
规则更新时延:
非增量式,需要先 iptables-save 拷贝 Iptables 状态,然后再更新部分规则,最后再通过 iptables-restore 写入到内核。当规则数到达一定程度时,这个过程就会变得非常缓慢。
可扩展性:
当系统存在大量的 Iptables 规则链时,增加/删除规则会出现 kernel lock,这时只能等待。
可用性: 服务扩容/缩容时, Iptables 规则的刷新会导致连接断开,服务不可用。
为了解决 Iptables 当前存在的这些问题,华为开源团队的同学为社区贡献了 IPVS 模式,接下来介绍下 IPVS 是如何实现负载均衡的。
IPVS 实现负载均衡
IPVS 是 LVS 项目的一部分,是一款运行在 Linux kernel 当中的 4 层负载均衡器,性能异常优秀。使用调优后的内核,可以轻松处理每秒 10 万次以上的转发请求。
IPVS 具有以下特点:
传输层 Load Balancer, LVS 负载均衡器的实现。
与 Iptables 同样基于 Netfilter, 但是使用的是 hash 表。
支持 TCP, UDP, SCTP 协议,支持 IPV4, IPV6。
支持多种负载均衡策略:
rr: round-robin
lc: least connection
dh: destination hashing
sh: source hashing
sed: shortest expected delay
nq: never queue
支持会话保持
LVS 的工作原理如下图所示:
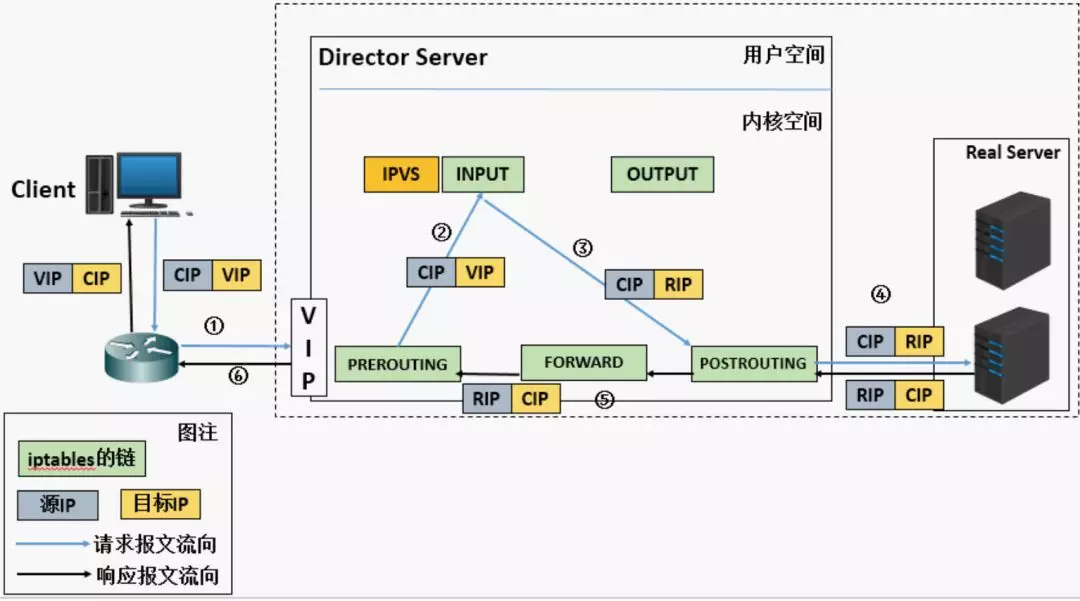
1.当客户端的请求到达负载均衡器的内核空间时,首先会达到 PREROUTING 链。
2.当内核发现请求的数据包的目的地址是本机时,将数据包送往 INPUT 链。
3.当数据包达到 INPUT 链时, 首先会被 IPVS 检查,如果数据包里面的目的地址及端口没有在 IPVS 规则里面,则这条数据包将被放行至用户空间。
4.如果数据包里面的目的地址和端口在 IPVS 规则里面,那么这条数据报文的目的地址会被修改为通过负责均衡算法选好的后后端服务器(DNAT),并发往 POSROUTING 链。
5.最后经由 POSTROUTING 链发往后端的服务器。
LVS 主要由三种工作模式, 分别是 NAT, DR, Tunnel 模式,而在 kube-proxy 中,IPVS 工作在 NAT 模式,所以下面主要对 NAT 模式进行介绍:
还是分析上面的那张图:
客户端将请求发往前端的负载均衡器,请求报文源地址是 CIP(客户端 IP), 目的地址是 VIP(负载均衡器前端地址)
负载均衡器收到报文之后,发现请求的是在规则里面存在的地址,那么它将请求的报文的目的地址改为后端服务器的 RIP 地址,并将报文根据响应的负责均衡策略发送出去
报文发送到 Real Server 后,由于报文的目的地址是自己,所有会响应请求,并将响应的报文返回给 LVS
然后 LVS 将此报文的源地址修改本机的 IP 地址并发送给客户端
介绍完基本的工作原理之后,下面我们看看如何在 kube-proxy 中使用 IPVS 模式进行负载均衡。首先需要在启动 kube-proxy 的参数中指定如下参数:
设置完这些参数之后,重启启动 kube-proxy 服务即可。当创建 ClusterIP 类型的 Service 时,IPVS 模式的 kube-proxy 会做下面几件事儿:
创建虚拟网卡,默认是 kube-ipvs0
绑定 service IP 地址到虚拟网卡 kube-ipvs0
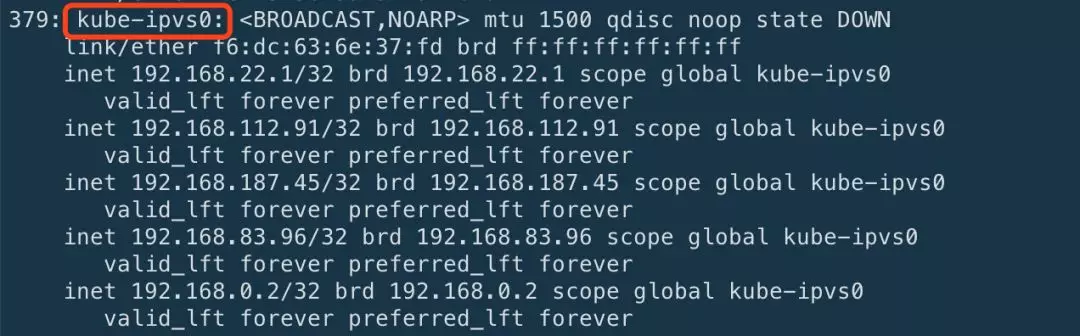
为每一个 Service IP 地址创建 IPVS 虚拟服务器

同时 IPVS 还支持会话保持功能,通过在创建 Srevice 对象时,指定 service.spec.sessionAffinity 参数为 ClusterIP 默认是 None 和 指定 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 参数为需要的时间,默认是 10800s。
下面是一个创建 Service,指定会话保持的一个具体的例子:
之后通过 ipvsadm -L 即可查看会话保持功能是否设置成功。这样 kube-proxy 便可以通过 IPVS 的模式实现负载均衡。

5 总结
kube-proxy 在使用 iptables 和 ipvs 实现对 Service 的负载均衡,但是通过 iptables 的实现方式,由于 Iptables 本身的特性,新增规则,更新规则是非增量式的,需要先 iptables-save 然后在内存中更新规则,在内核中修改规则,在 iptables-restore,并且 Iptables 在进行规则查找匹配时是线性查找,这将耗费很长时间,时间复杂度 O(n)。而使用 IPVS 的实现方式,其连接过程的时间复杂度是 O(1)。基本就是说连接的效率与集群 Service 的数量是无关的。因此随着集群内部 Service 的不断增加,IPVS 的性能优势就体现出来了。
本文转载自公众号 360 云计算(ID:hulktalk)。
原文链接:
https://mp.weixin.qq.com/s/BLWc6WRwOt8NSKWBk18INw

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论