

VentureBeat消息,IBM Research 的研究人员在近期发表的一篇论文中,提出了一种文本分类任务的数据扩充新方法。该方法被研究人员称为基于语言模型的数据增强(LAMBADA),原理是使用一个预先训练过的机器学习模型来合成文本分类任务所需要的标记数据。IBM 研究人员声称,LAMBADA 可以提高分类器在各种数据集上的性能,并显著地改进了数据扩充的最新技术,特别是那些适用于数据很少的文本分类任务的技术。

文本分类是 NLP 中的一个基础研究领域。它包含有很多其他的任务,比如意图分类、情感分析、话题分类、关系分类等。想要为分类器模型获得一个良好的拟合,需要大量的标记数据。然而,在很多情况下,尤其是在为特定应用开发人工智能系统时,带标签的数据往往是稀缺且昂贵的。
那么,怎样才能拥有足够多且可供深度学习模型训练用的数据呢?
IBM 研究人员在近期发表的一篇论文中给出了一个有些“特别”的答案。
预训练模型是解决文本数据扩充的新途径?
当数据不足时,数据扩充是处理该情况的常用策略,它从现有的训练数据中合成新的数据,借此提高下游模型的性能。然而扩充训练数据在文本领域往往比在视觉领域更具挑战性。
文本数据扩充时,所采用的通常方法(如:用同义词替换单个单词、删除一个单词、改变词序等),往往会使文本无效或者产生歧义,在语法和语义上都有可能出现错误。
对此,IBM 研究人员表示:尽管在这种情况下通过使用深度学习方法来改善文本分类看起来有些自相矛盾,但预训练模型为解决该任务开辟了新途径。
IBM 研究人员在近期的论文中提出了一种新的方法——基于语言模型的数据扩充(LAMBADA)。该方法可以用于综合标记数据,进而改进文本分类任务。研究人员声称,当只有少量标记数据可用时,LAMBADA 的表现非常优秀。
据了解,LAMBADA 利用了一个生成模型(OpenAI 的 GPT),它预先训练了大量的文本,使自身能够捕获语言的结构,从而产生连贯的句子。研究人员会在现有的小数据集上对模型进行微调,并使用微调后的模型合成新的标记句。再然后,研究人员会在相同的原始小型数据集上训练分类器,并让它过滤合成数据语料库,只保留那些看起来“足够定性”的数据,然后在“现有的”以及“合成后的数据”上重新训练分类器。
测试结果
IBM 研究人员使用三种不同的分类器(BERT、LSTM、SVM)将 LAMBADA 方法与 Baseline 进行比较,同时也对比了在训练样本数量不同的情况下分类器的表现(每个类别分别为 5、10、20、50 和 100)。
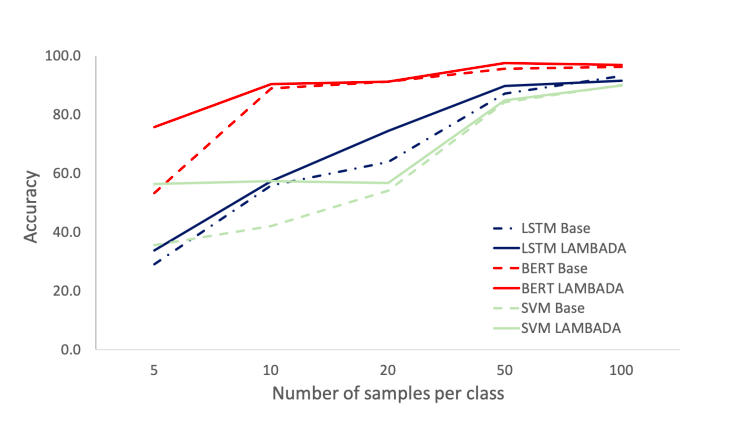
为了进一步验证结果的准确性,IBM 的研究人员在 5 个样本的前提下,将 Baseline 与 LAMBADA 在三个数据集(ATIS、TREC、WVA)和三个分类器(每个类别使用五个样本)进行了比较,并得到下面的数据。

Airline Travel Information Systems (ATIS)
提供有关语言理解研究中广泛使用的与飞行有关的信息的查询的数据集。 由于大多数数据属于航班类别,因此 ATIS 被描述为不平衡数据集。
Text Retrieval Conference (TREC)
信息检索社区中用于问题分类的著名数据集,由基于事实的开放域问题组成,分为广泛的语义类别。
IBM Watson Virtual Assistant (WVA)
用于意图分类的商业数据集,包括来自电信客户支持聊天机器人系统的数据。
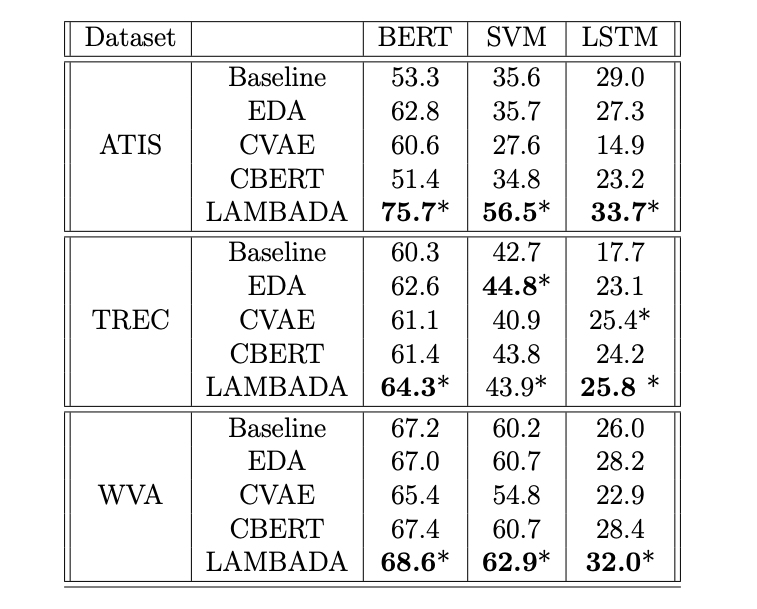
接下来,研究人员又将 LAMBADA 与其他的数据扩充方法进行了比较。结果显示,LAMBADA 的测试结果明显优于 ATIS 和 WVA 数据集中的其他生成算法。
在带有 BERT 分类器的数据集中,LAMBADA 的测试结果明显优于其他方法;在带有 SVM 分类器的 TREC 数据集上,LAMBADA 的测试结果与 EDA 相当;在具有 LSTM 分类器的 TREC 数据集,LAMBADA 的测试结果与 CVAE 相当。
总结
“LAMBADA 不需要额外的未标记数据……令人惊讶的是,与简单的弱标记方法相比,对于大多数分类器来说,LAMBADA 实现了更好的准确性,”IBM 研究人员在论文中写道。“显然,生成的数据集比从原始数据集提取的样本更有助于提高分类器的准确性。”
总而言之,LAMBADA 的作用主要体现在三个方面:
统计上提高分类器的准确性。
在缺乏数据的情况下,性能优于最先进的数据扩充方法。
当不存在未标记的数据时,建议使用一种更令人信服的方法替代半监督技术。

前InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论