

今天将分享的内容分为以下 4 个方面:
一、缘起
二、介绍多样的容器化技术
三、Redis 介绍
四、Redis 容器化方案的对比
一、缘起
首先我们先聊一下为什么今天我会分享这个主题。我和朋友一起组织了一个 Redis 技术交流群,到现在已经经营了 6 年左右的时间,其中某一天在群里有一个小伙伴就抛出来一个问题:
他问大家线上的 Redis 有没有使用 Docker 安装?Docker 使用 Host 的网络模式、磁盘使用本地挂载模式这种方案怎么样?这里的话我们暂时先不说这个方案如何,因为在今天的分享之后,我相信大家对于这个方案应该会有一个更清晰的认识和评价。
二、介绍多样的容器化技术
1、chroot 和 jails
在容器化技术方面,其实历史很久远了。虽然我们现在用的容器化技术,或者说 k8s,还有云原生的概念是近几年才火起来的,但是实际上就容器化技术的发展来说,其实是很早的了。比如说最早的时候来自 chroot,chroot 大家可能都用过,或者都有了解过,在 1979 年的时候它是来自 Unix,它主要的功能是可以修改进程和子进程的/。
通过使用 chroot 达到什么样效果呢?使用 chroot 加某一个目录,然后再启动一个进程,那么这个进程自己所看到的 / ,就是我们平时所说的 / 目录,这个 / 就会是我们刚才指定的文件夹,或者说刚才指定的路径。这样子的话可以有效的保护我们操作系统上面的一些文件,或者说权限和安全相关的东西。
在 2000 年的时候,出现了一个新的技术,叫做 jails,其实它已经具备了 sandbox,就是沙箱环境的雏形。使用 jails 的话,可以让一个进程或者说创建的环境拥有独立的网络接口和 IP 地址,而当我们提到使用 jails 的话,我们肯定会想到一个问题,就是如果你有了独立的网络接口和 IP 地址,这样的话就不能发原始的套接字,通常跟原始的套接字接触得比较多的就是我们使用的 Ping 命令。默认的情况下,这样子是不允许使用原始的套接字的,而有自己的网络接口和 IP 地址,这个感觉上就像是我们常用的虚拟机。

2、Linux VServer 和 OpenVZ
接下来在 2001 年的时候,在 Linux 社区当中就出现了一个新的技术叫做 Linux VServer。Linux VServer 有时候可以简写成 lvs,但是和我们平时用到的 4 层的代理 lvs 其实是不一样的。它其实是对 Linux 内核的一种 Patch,它是需要修改 Linux 内核,修改完成之后,我们可以让它支持系统级的虚拟化,同时使用 Linux VServer 的话,它可以共享系统调用,它是没有仿真开销的,也就是说我们常用的一些系统调用、系统调用的一些函数都是可以共享的。
在 2005 年的时候,出现的一个新的技术—OpenVZ。OpenVZ 其实和 Linux VServer 有很大的相似点,它也是对内核的一种 Patch,这两种技术最大的变化就是它对 Linux 打了很多的 Patch,加了很多新的功能,但是在 2005 年的时候,没有把这些全部都合并到 Linux 的主干当中,而且在使用 OpenVZ 的时候,它可以允许每个进程可以有自己的/proc 或者说自己的/sys。
其实我们大家都知道在 Linux 当中,比如说启动一个进程,你在他的/proc/self 下面,你就可以看到进程相关的信息。如果你有了自己独立的/proc,其实你就可以达到和其他的进程隔离开的效果。
接下来另外一个显著的特点就是它有独立的 users 和 groups,也就是说你可以有独立的用户或者独立的组,而且这个是可以和系统当中其他的用户或者组独立开的。
其次的话 OpenVZ 是有商业使用的,就是有很多国外的主机和各种 VPS 都是用 OpenVZ 这种技术方案。

3、namespace 和 cgroups
到了 2002 年的时候,新的技术是 namespace。在 Linux 当中我们有了新的技术叫做 namespace,namespace 可以达到进程组内的特定资源的隔离。因为我们平时用到的 namespace 其实有很多种,比如说有 PID、net 等,而且如果你不在相同的 namespace 下面的话,是看不到其他进程特定的资源的。
到了 2013 年的时候,产生了一个新的 namespace 的特性,就是 user namespace。其实当有了 user namespace,就和上文提到的 OpenVZ 实现的独立用户和组的功能是比较像的。
对于 namespace 的操作当中,通常会有三种。
1)Clone
可以指定子进程在什么 namespace 下面。
2)Unshare
它是与其他进程不共享的,unshare 再加一个-net,就可以与其他的进程独立开,不共享自己的 net,不共享自己的网络的 namespace。
3)Setns
就是为进程设置 namespace。
到了 2008 年,cgroups 开始被引入到 Linux 内核当中,它可以用于隔离进程组的资源使用,比如说可以隔离 CPU、内存、磁盘,还有网络,尤其是他在 2013 年和 user namespace 进行了一次组合之后,并且进行了重新的设计,这个时候,就变得更现代化了,就像我们现在经常使用到的 Docker 的相关特性,其实都来自于这个时候。所以说 cgroups 和 namespace 构成现代容器技术的基础。

4、LXC 和 CloudFoundry
在 2008 年的时候,新的一项技术叫做 LXC, 我们也会叫他 Linux Container(以下均简称 LXC)。上文我们提到了很多容器化的技术,比如 Linux VServer、OpenVZ,但是这些都是通过打 Patch 来实现的,而 LXC 是首个可以直接和上游的 Linux 内核共同工作的。
LXC 是可以支持特权容器的,意思就是说可以在机器上面去做 uid map、gid map,去做映射,而且不需要都拿 root 用户去启动,这样子就具备了很大的便利性。而且这种方式可以让你的被攻击面大大缩小。LXC 支持的这几种比较常规的操作,就是 LXC-start,可以用来启动 container,LXC-attach 就可以进入 container 当中。
到 2011 年的时候,CloudFoundry 开始出现了,他实际上是使用了 LXC 和 Warden 这两项技术的组合,在这个时候不得不提到的,就是他的技术架构是 CS 的模式,也就是说还有一个客户端和 server 端,而 Warden 容器,它通常是有两层,一层是只读 os 的,就是只读的操作系统的文件系统,另外一层是用于应用程序和其依赖的非持久化的读写层,就是这两层的组合。
我们之前提到的技术,大多数都是针对于某一台机器的,就是对于单机的。CloudFoundry 它最大的不同就是它可以管理跨计算机的容器集群,这其实就已经有了现代容器技术的相关特性了。

5、LMCTFY 和 systemd-nspawn
在 2013 年的时候, Google 开源了自己的容器化的解决方案,叫做 LMCTFY。这个方案是可以支持 CPU、内存还有设备的隔离。而且它是支持子容器的,可以让应用程序去感知到自己当前是处在容器当中的。另外还可以再为自己创建一个子容器,但是随着 2013 年发展之后,它逐渐发现只依靠自己不停的做这些技术,就相当于单打独斗,发展始终是有限的,所以它逐步的将自己的主要精力放在抽象和移植上,把自己的核心特性都移植到了 libcontainer。而 libcontainer 之后就是 Docker 的运行时的一个核心,再之后就是被 Docker 捐到了 OCI,再然后就发展到了 runC。这部分内容我们稍后再详细讲解。
大家都知道服务器它肯定是有一个 PID 为 1 的进程。就是它的初始进程、守护进程,而现代的操作系统的话,大多数大家都使用的是 systemd,同样 systemd 它也提供了一种容器化的解决方案,叫做 systemd-nspawn。这个技术的话,它是可以和 systemd 相关的工具链进行结合的。
systemd 除了有我们平时用到的 systemctl 之类的,还有 systemd machine ctl,它可以去管理机器,这个机器支持两种主要的接口,一种是管理容器相关的接口,另外一种是管理虚拟机相关的接口。
而我们通常来讲,就是说 systemd 提供的容器技术解决方案,它是允许我们通过 machine ctl 去容器去进行交互的,比如说你可以通过 machine ctl start,去启动一个 systemd 支持的容器,或者通过 machine ctl stop,去关掉它,而在这种技术下,它是支持资源还有网络等隔离的,其实它最主要的是 systemd ns,它其实是使用 namespace 去做隔离。对于资源方面是来自于 systemd,systemd 是可以使用 cgroups 去做资源隔离的,其实这也是这两种两种技术方案的组合。

6、Docker
而在 2013 年 Docker 也出现了。通常来讲,Docker 是容器时代的引领者,为什么这么说呢?因为 Docker 在 2013 年出现的时候,他首先提到了标准化的部署单元,就是 Docker image。同时它还推出了 DockerHub,就是中央镜像仓库。允许所有人通过 DockerHub 去下载预先已经构建好的 Docker image,并且通过一行 Docker run 就可以启动这个容器。
在众多使用起来比较繁琐、比较复杂的技术下,Docker 这时提出来,你只需要一行 Docker run,就可以启动一个容器,它大大简化了大家启动容器的复杂度,提升了便捷性。
所以 Docker 这项技术就开始风靡全球。而 Docker 它主要提供的一些功能是什么呢?比如说资源的隔离和管理。而且 Docker 在 0.9 之前,它的容器运行时是 LXC,在 0.9 之后,他就开始把 LXC 替换掉,替换成了 libcontainer,而这个 libcontainer 其实就是我们在上文提到的 Google 的 LMCTFY。再之后 libcontainer 捐给了 OCI。而那之后 Docker 现在的容器运行时是什么呢?是 containerd。containerd 的更下层是 runc,runc 的核心其实就是 libcontainer。
而到了 2014 年的时候, Google 发现大多数的容器化解决方案,其实都只提供了单机的解决方案,同时由于 Docker 也是 CS 架构的,所以它需要有一个 Docker demand,它是需要有守护进程存在的,而这个守护进程的话,是需要用 root 用户去启动的,而 root 用户启动的守护进程,其实是增加了被攻击面,所以 Docker 的安全问题也被很多人诟病。
在这个时候 Google 就发现了这个点,并且把自己的 Borg 系统去做了开源,开源版本就是 Kubernetes。Google 还联合了一些公司,组建了一个云原生基金会(CNCF)。

7、Kubernetes
通常来讲 Kubernetes 是云原生应用的基石,也就是说在 Kubernetes 出现之后,我们的云原生技术开始逐步地发展起来,逐步地引领了潮流,Kubernetes 提供了一些主要的特性。
它可以支持比较灵活的调度、控制和管理,而这个调度程序的话,除了它默认的以外,也可以比较方便的去对它做扩展,比如说我们可以自己去写自己的调度程序,或者说亲和性、反亲和性,这些其实都是我们比较常用到的一些特性。
还有包括他提供的一些服务,比如说内置的 DNS、kube-DNS 或者说现在的 CoreDNS,通过域名的方式去做服务发现,以及 Kubernetes 当中有很多的控制器。它可以将集群的状态调整至我们预期的状态,就比如说有一个 pod 挂掉了,它可以自动的把它再恢复到我们预期想要的样子。
另外就是它支持丰富的资源种类,比如说几个主要的层级,最小的是 pod,再往上有 deployment,或者有 StatefulSets,类似于这样子的资源。
最后一点是它让我们更加喜欢它的因素,就是它有丰富的 CRD 的拓展,即可以通过自己去写一些自定义的资源,然后对它进行扩展,比如 CRD。

8、更多的容器化技术
除了刚才我们提到的这些主要的技术以外,其实还有很多我们没有提到的一些容器化的技术,比如说像 runc,上文我们没有太多的介绍,还有 containerd。containerd 其实也是 Docker 开源出来的自己的核心,他的目标是做一个标准化工业可用的容器运行时,还有 CoreOS 开源出来的解决方案叫做 rkt。而 rkt 瞄准的点就是上文提到的 Docker 相关的安全问题。但是 rkt 现在项目已经终止了。
还有红帽(Red Hat)开源出来的 podman, podman 是一种可以用它来启动容器,可以用它去管理容器,而且没有守护进程,所以就安全性来讲的话,podman 可以说比 Docker 的安全性直观上来看的话会好一些,但是它的便捷性来讲的话,就要大打折扣了。比如说容器的重启、开机起之类的,但是我们都是有一些不同的解决方案的。
在 2017 年的时候,这个时候有一个 Kata Container,而这个 Kata Container 它有一段发展过程,最开始是英特尔,英特尔在搞自己的容器运行时,还有一家初创公司叫做 hyper.sh,这家公司也在搞自己的容器运行时,这两家公司瞄准的都是做更安全的容器,他们使用的底层的技术都是基于 K8S。而之后这两家公司做了合并,hyper.sh 它开源出来的一个解决方案是 runv,被英特尔看上了之后就诞生了 Kata Container。在 2018 年的时候,AWS 开源出来自己的 Firecracker。
这两项技术和我们上文提到的机器上的容器化技术其实大有不同,因为它的底层其实相当于是虚拟机,而我们通常来讲,都认为它是轻量级虚拟机的一种容器化的技术。以上就是关于多样的容器化技术的介绍。
三、Redis 介绍
接下来进入关于 Redis 相关的介绍,以下是从 Redis 的官网上面摘抄的一段介绍。
1、Redis 使用的主要场景
其实 Redis 现在是使用最广泛的一种 KV 型数据库。而我们在使用它的时候,主要的使用场景可能有以下几种:
把它当缓存使用,把它放在数据库之前,把它当做缓存去使用;
把它当 DB 来用,这种就是需要把真正的拿它来存数据做持久化。
做消息队列,它支持的数据类型也比较多,这里就不再做介绍了。
2、Redis 的特点
它是一个单线程的模型,它其实是可以有多个线程的,但是它的 worker 线程只有一个,在 Redis6.0 开始,它支持了 io 多线程,但 io 多线程只是可以有多线程去处理有网络相关的部分,实际上你真正去处理数据还是单线程,所以整体而言,我们仍然把它叫做单线程模型。
Redis 的数据其实都在内存里头,它是一个内存型的数据库。
与 HA 相关, Redis 想要做 HA,我们以前在做 Redis 的 HA 主要靠 Redis sentinel,而后面在 Redis 出来 cluster 之后,我们主要靠 Redis cluster 去做 HA,这是两种主要 HA 的解决方案。

四、Redis 容器化方案的对比
当我们提到做 Redis 运维相关的时候,我们有哪些需要考虑的点:
部署,如何快速的部署,如何能够快速的部署,而且还要去管理监听的端口,让端口不起冲突,还有日志和持久化文件之类的,这部分都属于部署相关的内容;
扩/缩容,也是我们经常会遇到的问题;
监控和报警;
故障和恢复。
以上都是我们最关注的几个方面。我接下来就对这几个方面去做一些介绍。
1、部署
当我们提到去做单机多实例的时候,Redis 作单机多实例去部署的时候,首先第一点就是我们希望能够有进程级别的资源隔离,我们某一个节点上面所有部署的 Redis 实例,可以有自己的资源,可以不受别的实例的影响,这就是对于进程级别的资源隔离。
进程级别的资源隔离,它其实主要分为两个方面,一方面是 CPU,另一方面是内存,其次的话我们希望在单机上面我们也可以有自己的端口管理,或者说我们可以有独立的网络资源隔离的相关的技术。
在这种情况下,首先我们提到说进程级别的资源隔离,我们介绍了那么多的容器化相关技术,我们已经知道了,支持进程级别的资源隔离的话,有最简单的一种方案就是用 cgroups,如果想要去做网络资源隔离的话,我们有 namespace,也就是说所有支持 cgroups 和 namespace 的这种计划的解决方案,都可以满足我们这个地方的需求。
再有一种方案就是虚拟化的方案,也就是我们上文提到比如说 Kata Container,Kata Container 这种基于虚拟化的方式,因为虚拟化的方案其实大家都有所接触,大家都知道就是虚拟化的这种技术,其实默认情况下,刚开始全部都做隔离。
所以对于部署而言,如果你使用的是比如说像 Docker,比如说你想使用的像 systemd-nspawn 这些它都可以既用到 cgroups,又用到了 namespace,是都可以去用的,只不过是你需要考虑一些便捷性,比如说你如果是使用 Docker 的话,进行一个 Docker 命令跑过去,然后只要让它映射到不同的端口,其实就结束了。
如果你使用是 systemd-nspawn,这样子的话,你需要去写一些配置文件。如果你要是去用一些虚拟化的解决方案的话,同样的也需要去准备一些镜像。

2、扩/缩容
关于扩/缩容,其实会有两种最主要的场景,一种场景就是单实例 maxmemory 调整,就是我们最大内存的调整。还有一种是对于我们的集群化的集群解决方案,就是 Redis Cluster。对于这种集群规模,我们有扩/缩容的话,会有两方面的变化。
一方面是 Node,就是我们的节点的变更,如果会新增节点,也可能会去移除节点。
另外一种就是 Slot 的变更,就是希望把我的 slot 去做一些迁移,当然这些和 Node 节点会是相关的,因为当我们去做扩容的时候,我们把 Redis Cluster 当中的一些 Node 节点增多,增多了之后,就可以不给他分配 Slot,或者说我想要让某些 Slot 集中到某些节点上面,其实这些需求也是同样存在的。
那我们来看一下,如果你当时想要去做 maxmemory 的调整,如果我们是前提已经做了容器化,想通过 cgroups 去对它做资源的限制,就需要有一个可以支持动态调整 cgroups 配额的解决方案。
比如说我们用到 Docker update,它是可以直接修改某个实例,或者说其中的某一个容器的 cgroups 资源的一些限制,比如说我们可以 Docker update,给它指定新的内存,可以限制它最大可用内存,当你把它的可用内存数调大,接下来你就可以对实例去调整它的 maxmemory ,也就是说对于单实例 maxmemory,其实最主要的就是需要有 cgroups 的技术,向 cgroups 的技术提供一些支持。
对于集群节点的变更的话,这个部分稍后再做详细介绍。

3、监控报警
第三点就是监控报警,不管是使用物理机也好,或者使用云环境也好,或者使用任何解决方案都好,监控报警我们最想要得到的效果就是,它可以自动发现。
我们希望当启动一个实例之后,我们就可以立马知道这个实例 A 他已经起来了,并且知道他的状态是什么,而监控报警的话,这部分其实是不依赖于特定的容器化技术的,就即使是在纯粹的物理机上部署,也可以通过一些解决方案自动的发现它,自动的把它注册到我们的监控系统当中去,所以它是属于监控报警的这部分,其实它是不依赖于特定的容器技术的,但唯一的一个问题就是说假如说使用了容器化的方案,可以让常用的 Redis exporter,配合 Prometheus 去做监控,可以让 Redis exporter 和 Redis server,这两个进程可以处于同一个网络的命名空间。
如果他们两个处于同一个网络的命名空间的话,可以直接通过 127.0.0.1:6379,然后直接去联通它,如果我们使用的是 k8s 的话,可以直接把它俩放到一个 pod 当中,但是这些都无关紧要,因为它是不依赖于特定的容器化技术的,你可以使用任何你想要用的技术,都可以去做监控和报警。

4、故障恢复
最后我们提到的部分是故障和恢复。在这个部分我认为最主要的有三个方面:
第一个是实例的重启。
有可能在某些情况下,某些场景下,你的实例在运行过程当中它可能会宕掉,如果你想让他自动重启的话,你需要有一个进程管理的工具。对于我们而言,上文我们提到了 systemd,systemd 是可以支持对于某一个进程的自动拉起的,还可以支持进程挂掉之后自动拉起, 可以 restart,或者你使用 Docker,它也有一个 restart policy,可以指定他为 always 或者指定为 on-failure,然后让它在挂掉的时候再把它给拉起来。
如果你使用的是 k8s,那么就更简单了,可以自动拉起来。
第二个是主从切换。
主从切换相对来说是一个常态,但在这里我也把它列到故障恢复当中,是因为可能在主从切换的过程当中,有可能你的集群状况已经不健康了,是会有这种情况存在的。那主从切换的时候我们需要做什么?第一方面,需要让他能够有数据的持久化,另一方面在主从切换的时候,有可能会遇到一种情况,就是资源不够,导致主从切换失败,在这种情况下,其实和我们上文前面提到的扩/缩容其实是相关的,所以在这种情况下就必须得给他加资源,而最好的办法是可以自动给他加资源。
在 k8s 当中,想要让它自动加资源,我们通常会给他设置它的 request 和 limit,就是资源的配额,希望它能自动的加起来,我们通常把他叫做 vpa。
第三个是数据恢复。
通常来讲,比如说我们开了 RDB 和 AOF,而且希望我们的数据可以保存下来,以便于在我们数据恢复的时候可以直接开始使用。所以数据持久化也是一方面。

我们去做容器化的时候,我们需要考虑哪些点?如果说你是使用 Docker 的话,你需要去挂一个券,然后你可以把这个数据去做持久化,比如说你使用 systemd-nspawn 也需要有一个文件目录去把这个数据做持续化。
如果你使用的是 k8s 的话,在挂券的时候,你会有各种各样的选择,比如说你可以去挂 ceph 的 RDB、s3 或者一个本地的某一个文件目录。但是为了更高的可靠性,可能会使用副本数更多的分布式存储。
5、Node 节点变更
接下来,我们来聊一下上文我们在提到服务扩/缩容的时候,提到的关于 Node 节点变更,比如说我想要让我的某一个 Redis cluster,去扩充一些节点,扩充节点的时候,那就意味着你必须能够加入集群,能够和集群正常通信,这才说明你真正的加入到了集群当中。
而我们也知道在 Redis cluster 当中,你要去做集群,最大的一个问题就是 k8s,k8s 当中做服务发现其实它都是大多数通过一个域名,而我们的 Redis 当中,比如说我们的 NodeIP,它其实只支持 IP,它并不支持我们的域名。
所以如果说 Node 节点变更,需要做的事情就是允许我们动态地去把 NodeIP 写到我们的集群配置当中。
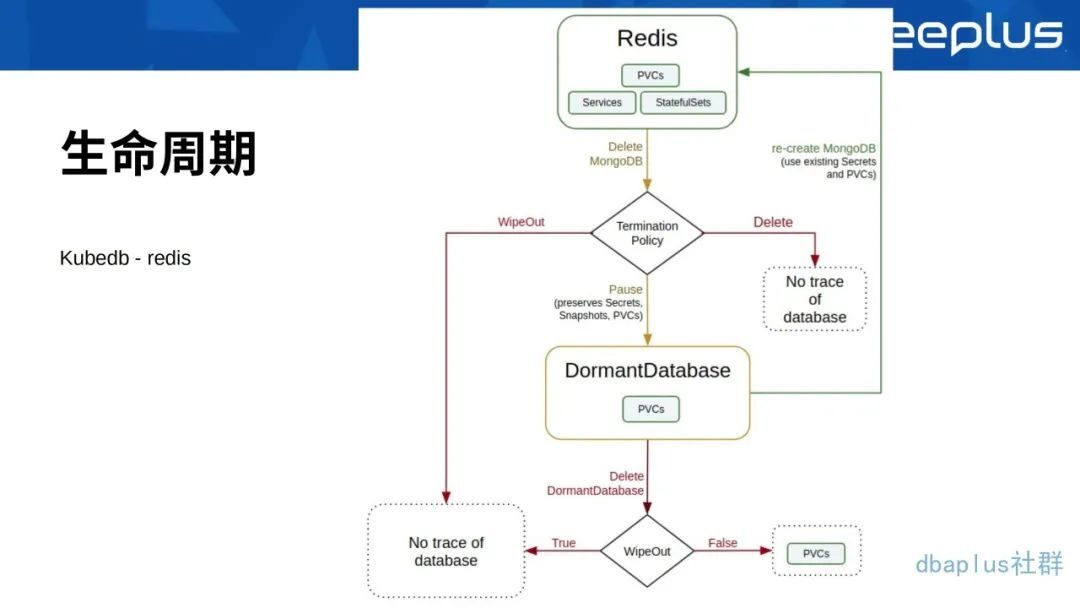
如果想要让它有一个完整的生命周期,以下截图是来自于一个叫 Kubedb 的 operator,在下图中可以看到,Redis 这个地方提供了最主要的三个部分:
PVCs,PVCs 就是做数据的持久化。
Services,Services 就是做服务发现。
StatefulSets,StatefulSets 其实就是 k8s 当中的一种资源,而这资源它对于我们的有状态应用会更友好一些。
其实在整个内容当中还有一点没有介绍的是什么呢?就是 Redis 背后的公司叫做 Redis Labs,它提供了一种商业化的方案,就是 Redis Enterprise 一种解决方案。其实也是在 k8s 的解决方案之上的,也是用了 Redis operator。他的方案和 Kubedb 这种方案基本类似,因为核心还都是用的 StatefulSets,然后再加上自己的 Controller,去完成这个事情。
五、总结
我们来看一下今天的总结。如果是我们单机使用的话,我们可以交给 Docker 或者其他支持 cgroups 或者 namespace 资源管理的工具。因为当你使用了 cgroups、namespace 的话,你可以做到资源的隔离,可以避免网络的端口的冲突之类的事情都可以实现。
而如果是像我在上文提到的小伙伴提到的那个问题:他打算使用主机的网络,仅仅是想让 Docker 去做一个进程管理,而且你也不希望引入新的内容。那么 systemd 或者 systemd-nspawn 都是可以考虑的,因为这也是容器化的解决方案。
如果是在复杂场景下的调度和管理的话,比如想要有很大的规模,并且想要有更灵活的调度和管理,我推荐你使用的是 Kubernetes operator,比如说 Kubedb,其实也是一种解决方案。如果你的场景没有那么复杂,比较简单,其实原生的 Kubernetes StatefulSets 稍微做一些调整和修改,也是可以满足你的需求。

以上就是我今天分享的主要内容了,感谢大家的参与。
>>>>
Q&A
Q1:请问 Redis 集群假如用三台物理机做,每台运行 2 个实例,如何保障每台物理机的实例不是互为主从的?
A1 :这个问题其实我们通常情况下大家也都会遇到。第一点如果你是使用物理机来做,并且你每台机器上面运行两个实例,三台机器每个机器上面运行 2 个实例,一共有 6 个实例。这 6 个实例你是否可以保证它每个互相都不为主从的,其实是可以直接保证。
唯一的问题就是假如说这是一个集群,然后发生故障转移,发生节点的主动切换,就非常有可能存在你的主从发生了变更。其实这个地方的话其实我更加建议,如果你发现了这种问题的话,你手动去做切换,因为物理机环境去做这个事情,目前我还没看到有什么特别好的解决办法。
Q2 : 请问 k8s 中扩容时,如何增加新节点。扩容和分配 slot 的步骤如何自动化的进行?
A2 :我们分开两步来讲,第一部分是增加新节点,增加新节点的话,刚才我其实在过程里头已经提到了,增加完新的节点之后,首先你一定要让它能够和集群去做通信,然而这个地方就是需要你去修改集群的配置文件,然后你需要他有一个 NodeIP,因为之间是通过 IP 去做通信的,所以你需要去修改它的配置文件,把它的 NodeIP 加进去,这样子他才可以和集群当中的其他节点去做通信,然而这个部分的话,我更推荐的是用 operator 去做。
Q3 : 请问如果不用 Redis operator,也不使用分布式存储,k8s 如何部署 cluster 集群呢?
A3 :不用 Redis operator 其实也是可以的,刚才我也介绍过,有两种模式,一种模式就是用 StatefulSets,这种模式的话相对来说会比较稳妥一些。同时它的最主要的部分仍然是修改配置,你需要在你的 Redis 的容器镜像当中,你可以给它加一个 init 容器,然后可以在这个部分先给他做一次修改配置的操作,这是可以的。修改完配置的操作之后,再把它给拉起来,这样子他才可以加入到集群当中。
Q4 : 请问网络延迟在不同网络模型下有什么区别?
A4 :如果我们直接使用物理机的网络,通常来讲,我们不认为这种方式有延迟,就是主机网络一般情况下我们会忽略掉它的延迟,但是如果你使用的是 overlay 的这种网络模型的话,因为它是覆盖层的网络,所以你在去做发包解包的时候,当然是会有不同的资源的损耗,性能的损耗都是有的。
Q5 : 请问一般建议公司公用一个 Redis 集群,还是各系统独立集群?
A5 :这个问题当然是建议各个系统独立集群了,我们来举一个最简单的例子,比如说你在其中用到了 list,我们都知道 Redis 就有一个 ziplist 的配置项,他其实跟你的存储和你的性能是有关系的。如果你是公司的所有的东西都用同一个集群,那你修改了 Redis 集群的配置的话,很可能会影响到所有的服务。但如果你是每个系统独立用一个 Redis 群的话,彼此之间互不影响,也不会出现某一个应用不小心把集群给打挂了,然后造成连锁反应的情况。
Q6 : 请问 Redis 持久化,在生产中如何考虑呢?
A6 :这部分东西我是这样想的。如果你真的需要去做持久化,一方面 Redis 提供了两种核心,一种是 RDB,另外一种是 AOF,如果说你的数据很多的话,相应你的 RDB 可能会变得很大。如果你是去做持久化,我通常建议就是两个里头去做一次权衡。因为通常来讲,即使你是使用物理机的环境,我也建议你的存储目录可以放到一个独立的盘里头,或者说你可以去挂在一个分布式的存储,但是前提是你需要保证它的性能,因为你不能因为它的写入性能而拖累你的集群,所以更加推荐的就是你可以全都把它们打开,但是如果你数据其实没那么重要,你可以你只开 AOF。
Q7 : 请问生产级别的 ceph 可靠不?
A7 :其实 ceph 的可靠性这个问题,很多人都讨论过,就我个人而言,ceph 的可靠性是有保证的。我这边在用的 ceph 很多,并且存了很多比较核心的数据,所以 ceph 的可靠性是 ok 的。
重点在于说你能不能搞得定他,而且有一家公司其实大家可能有所了解,叫做 SUSE,就是一个 Linux 的一个发行版,这家公司其实提供了一个企业级的存储解决方案,并且它的底层其实还是用的 ceph,其实这也是正常的,只要有专人去搞这个事情,然后把它解决掉,我觉得 ceph 足够稳定的。
顺便提一下,如果你使用的是 k8s 的话,现在有一个项目叫做 rocket,它其实提供了一个 ceph 的 operator,这种方案其实现在已经算是相对来说比较很稳定的了,推荐大家尝试一下。
Q8: 请问申请内存、限制内存、还有本身 Redis 内存怎么配置比较好?
A8:这里需要考虑几个问题,首先我们先说 Redis 本身的内存,其实要看你的实际业务的使用场景,或者说你业务的实际需求,你肯定不可能让你的 Redis 的实例或者 Redis 集群的内存都占满。
如果是占满的话,你就需要开启 lru 去做驱逐之类的事情,这是一方面。另一方面就是申请内存,其实我理解你这个地方要问的问题应该是指,在 k8s 环境下面,在 k8s 下面一个是 request 的,一个是 limit,limit 肯定是你的可用限制的内存,限制内存你一定需要考虑到 Redis 本身还要用到的一些内存。
嘉宾介绍:
张晋涛,云原生技术专家。
负责 DevOps 的实践和落地,推进容器化技术落地和运维自动化等。
参与了众多知名开源项目,对 Docker、Kubernetes 及相关生态有大量生产实践和深入源码的研究。
本文转载自:dbaplus 社群(ID:dbaplus)

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论