

在人工智能技术不断深入发展的今天,我们对于计算的性能要求越来越高。传统的计算处理多数是基于云侧的,把所有图像、音频等数据通过网络传输到云中心进行处理后将结果反馈。
但是随着数据的指数式增长,依靠云侧的计算已经显现了诸多不足,例如数据处理的实时性、网络条件制约、数据安全等,因此端侧的推理则愈发重要。在这样的背景下,网易有道 AI 团队自主设计研发了高性能端侧机器学习计算库——EMLL(Edge ML Library),并已在近日开源。
开源地址:https://github.com/netease-youdao/EMLL
EMLL 为加速端侧 AI 推理而设计,提供基于端侧处理器的高性能机器学习计算库,支持 fp32、fp16、int8 等数据类型,已在网易有道词典笔、翻译王和超级词典等智能硬件产品的 NMT、ASR、OCR 引擎中应用,大幅提高计算性能,提升用户体验。
端侧 AI
端侧 AI 具有以下优势:
低延时
保证数据隐私
不依赖网络
端侧 AI 挑战:
处理器算力有限,远低于云端计算能力,如何满足日益复杂的端侧 AI 性能的需求至关重要
内存大小和带宽有限,对性能影响至关重要
ARM 处理器在智能设备中占主导地位,是端侧 AI 落地的主流平台。NPU、DSP、GPU 可以提供更高的计算能力,在端侧 AI 上有一定的应用场景,但生态环境较差,距离成熟还需要时间。
端侧 AI 最耗时的计算为全连接(FC)和卷积计算,底层核心计算为矩阵乘,底层计算库的性能对端侧 AI 能否落地起决定性作用。
ARM 第三方 BLAS 库
Eigen
线性代数运算的 C++ 模板库,矩阵的运算可直接用符号做。
OpenBLAS
由中科院计算所维护的一个开源的高性能 BLAS 库,基于 Kazushige Goto 的 GotoBLAS,支持 Fortran BLAS 和 CBLAS 接口调用。
ARM Compute Library
ARM 官方推出的计算库,支持 AI 的常见运算,其中矩阵乘法运算以模型推理层的形式封装,需要先初始化后才能调用。
表 1 各 ARM blas 库矩阵乘法特点
常规矩阵规模上的矩阵乘法进行了较好的优化,性能表现较好,然后在扁平矩阵上性能表现较差。端侧 AI 底层计算主要为扁平矩阵的乘法,第三方计算库性能表现较差,没有充分发挥硬件的性能,不利于 AI 应用在端侧平台上落地。
表 2 ARM cortex-A53 四核第三方库 GEMM 计算效率
注:C(M, N) = A(M, K) * B(K, N),以上值取全行主序和全列主序的最好值,测试在相同的矩阵上重复 128 次,计算效率由 GEMM 计算 FLOPS 值除以硬件理论 FLOPS 值得到。
EMLL 特点
高性能
EMLL 实现的矩阵乘法函数,为端侧人工智能中常见的扁平矩阵的计算做了专门的优化,为各常见 ARM 处理器做了特定的优化。对于 cortex-A7/A35/A53/A55/A76 处理器,本库根据它们的流水线特点,使用了汇编级别的优化。
EMLL 多数情况下相对 Eigen、ARM compute Library 第三方库性能提升明显,尤其在端侧 AI 常用的扁平矩阵乘法中获得数倍的性能提升。下图展示了端侧 AI 中部分典型矩阵尺寸情况下得单精度矩阵乘法的性能结果。
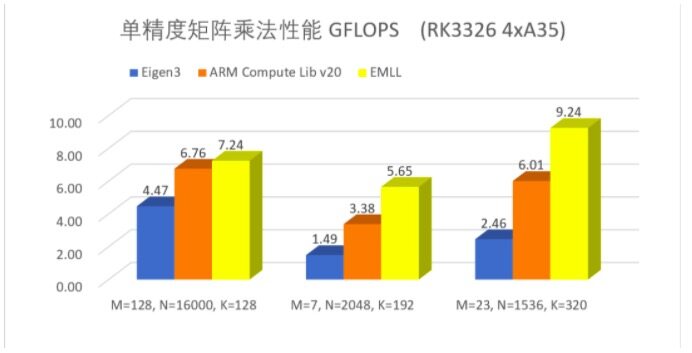
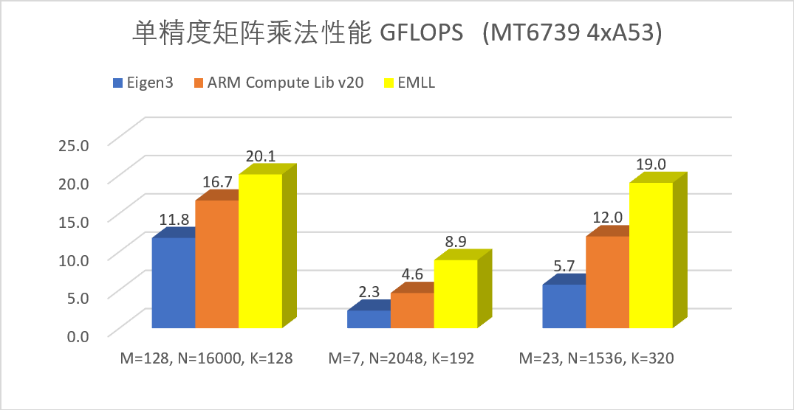
图 1 EMLL 矩阵乘法性能
易用性
EMLL 使用的函数接口在参数设计上力求简洁直接,矩阵乘法去掉了不常用的 LD*参数,矩阵和向量的传递通过指针和整数维度分别传递。本库不依赖第三方计算库。
扩展性
对于矩阵乘法和量化函数,EMLL 库提取了它们和架构无关的代码作为通用的宏,这些宏可以在支持新的 CPU 架构时大大节省所需的代码量。
EMLL 性能优化方法
在端侧设备上优化计算库的性能,需要从访存效率和计算效率两个角度考虑,下面以(稠密)矩阵乘法为例,介绍 EMLL 采用的优化方法。
分块
矩阵乘法的计算过程中需要频繁地访存。当矩阵规模较大时,CPU 缓存容量不足以装下其全部内容,访存时就会频繁出现缓存缺失,降低程序效率。此时,EMLL 会对矩阵乘法问题进行必要的拆解,把较大的矩阵切分成小块的矩阵,这就是分块的手段。经过切分,每个子任务只计算一小块矩阵对结果的贡献,只会密集访问这个小块矩阵的区域,大大提高了缓存命中率。对于两个较大矩阵之间的乘法,EMLL 参照已有的优化工作[1],通过多级的分块,充分利用 CPU 多级缓存,主要采用如下两种切分方式:
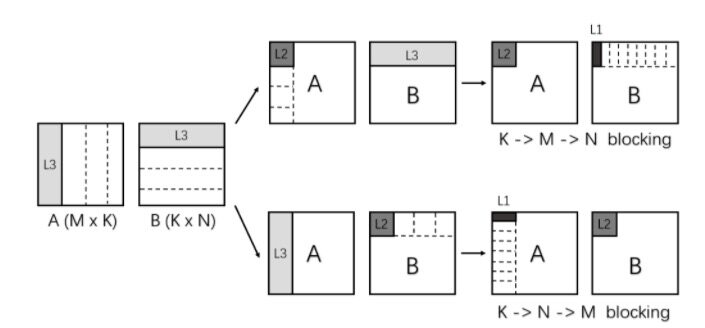
图 2 分块方法
L1 - L3 代表不同矩阵块所利用的 CPU 缓存
CPU 的寄存器可以看成“速度最快的缓存”。为了充分利用寄存器,在上述分块的基础上,EMLL 进行了进一步拆分,左边的小矩阵拆成 m×k 的最小矩阵 a1,右边的小矩阵拆成 k×n 的最小矩阵 b1。计算这一对最小矩阵的乘法,如果直接用三重循环的方式,需要 2×m×n×k 次元素访问,如果不利用寄存器,则都为访存操作;利用了寄存器,则只需要在乘法开始前把两个小矩阵放到寄存器中,后续的乘法就不再访存,使访存减少到 (m + n) ×k 次。
综上,大尺度的分块可以提高 CPU 各级缓存的利用率,小尺度的分块可以利用 CPU 寄存器以减少访存次数,两者对性能均有明显帮助。
重排
上文提到,为了充分利用寄存器,子矩阵块的读取被划分为更小的小块 m×k 或 k×n (1 < m, n, k < 20),计算中逐个读取这些小块。而通常情况下,矩阵在内存中的存储方式为行主序或列主序。无论哪种存储方式,按小块读取会存在很多跳跃访问的情况。跳跃访问对性能不利,这里列举三点:
消耗额外的缓存带宽:L2/L3 缓存与 L1 的数据交互以缓存行的形式进行。跳跃访问 L2/L3 缓存的数据时,缓存行数据的利用率低,浪费传输带宽。
无法充分利用向量化的加载单元:很多支持 SIMD 的 CPU 上配备了向量化的加载单元,支持一条指令加载若干个地址连续的元素,若是跳跃访问则没法利用此特性。
增加页表查询的开销:访存操作常涉及虚拟地址向物理地址的转换,需要查询页表。一个页表的覆盖地址范围有限。如果跳跃的步长过大,则需频繁查询新的页表。
在两个子矩阵块的乘法中,每个子矩阵块通常会被读取多次,每次读取的顺序可以相同。B 的子矩阵块在与它相乘的 A 块的行数多于 m 时会被读多次;A 的子矩阵块在与它相乘的 B 块的列数多于 n 时会被读多次。EMLL 参照已有的优化工作 1,在计算开始前,将两个子矩阵块先按计算时的读取顺序(即上一段所述按更小的小块读取)重新排列元素,这样计算时对两个子矩阵块的访问全部变成了顺序访问,此即重排的优化方法。虽然计算前重新排列元素会有额外的开销,但计算过程中对矩阵块的多次访问被顺序化后的收益更大,因此带来总体的性能提升。
对于特殊尺寸的矩阵,重排的开销可能大于收益,需要选择性地重排或不重排[2]。当源矩阵 A 的行数 M 很少而源矩阵 B 较大时,B 的子块被重复读取的次数大大降低,对 B 的子块重排的收益大大降低,甚至开始低于开销。这种情况在端侧 AI 推理中非常普遍。EMLL 会判断 M 的大小,当 M 小于一个阈值时,对矩阵 B 不再重排,而是调整计算顺序,对 B 的所有元素进行顺序的一次读取。类似地,当源矩阵 B 的列数 N 明显偏小时,EMLL 对矩阵 A 不再重排,调整计算顺序,对 A 的元素一次顺序读完。通过对特殊尺寸矩阵的特别处理,EMLL 在这些尺寸上的性能明显超过了 Eigen 和 OpenBLAS 等开源库。
汇编优化
现今主流的 CPU 为了提高数据计算的效率,支持了“单指令多数据”(SIMD)的处理模式,即一条指令对多个数据进行相同的操作。调用 SIMD 指令集,可以在不增加指令吞吐量的情况下,提高数据计算的吞吐量。ARM 平台提供了 NEON 指令集支持 SIMD 操作。
当 m = n = 4 而 k = 1 时,做最小矩阵小块之间的乘法并累加结果,如果使用标量计算,需要 16 次乘法和 16 次加法。NEON 指令集提供了广播模式的融合乘加操作,只需 4 条指令,即可完成相同的任务,如下图所示。其他 m,n 和 k 的取值,大多也可以用 NEON 指令加速运算。NEON 指令可以通过汇编的方式显式调用,也可通过编译器提供的 intrinsics 函数调用,后者可读性更好但性能指标的不确定性更大。
端侧的中低端平台配备的处理器,为了节省成本和功耗,在执行核心通常砍掉了乱序执行的能力,而是严格按照指令在指令流中的顺序来执行它们,如 ARM 的 cortex-A7, A35, A53, A55 等。部分型号的处理器可以在顺序执行的前提下同时执行相邻的两条指令。对于这些处理器,指令之间如果存在数据依赖或者执行单元冲突,则指令的顺序会对性能产生明显的影响,若追求极致性能,需要在汇编级别重排相关的指令。对于存在数据依赖的两条指令(比如一个运算指令的输入依赖于另一个加载指令的结果),应尽可能地使它们远离,避免因依赖关系的等待造成流水线空闲。
EMLL 功能
支持的计算函数
表 3 支持的计算函数
支持的架构
armv7a, armv8a
支持的端侧操作系统
Linux, Android
应用案例
网易有道词典笔,是网易有道打磨的一款学习型智能硬件,网易有道词典笔,具有“多行扫描翻译”功能,支持整段翻译的智能学习硬件。
网易有道超级词典打造高效的智能英语学习系统,强化端侧功能,提供了拍照学英语、查词翻译、背单词、听力练习、对话翻译、语音助手等功能。
网易有道翻译王支持 43 种语言互译,畅游全球 191 个国家和地区,支持 21 种语言在线、7 种语言端侧拍照翻译,指示牌、菜单等即拍即译。
网易有道词典笔、超级词典、翻译王均内嵌了网易有道自主研发的神经网络翻译 NMT、光学字符识别 OCR、语音识别 ASR、语音合成 TTS 等业内领先的 AI 技术,并且支持离线功能。
网易有道自研端侧机器学习计算库已在网易有道词典笔、超级词典、翻译王等智能硬件产品中使用,带来以下好处:
端到端性能相对于使用 eigen 库加速 1.3 到 2.43 倍,效果显著,大大降低了端侧推理引擎的延迟。除了在有道智能硬件带来了较好的性能提升,我们在配置骁龙 855 的某款手机上也做了性能测试,端到端性能相对于 eigen 提升了 25%-55%,效果明显。
端侧推理引擎采用 EMLL 之后,可以上线更大的 AI 模型,提高质量,并保证实时性,如端侧 NMT 质量(BLEU)提升 2 个点,端侧 ASR 准确度提升 4.73%。
EMLL 可以保证在更低端芯片上实时性,如在 cortex-A7 上使用 Eigen 库无法达到实时性,使用 EMLL 之后延迟大幅降低,并保证实时性效果。EMLL 可以让智能硬件更多的芯片选择,从而降低成本,提高市场竞争力。
表 4 测试平台
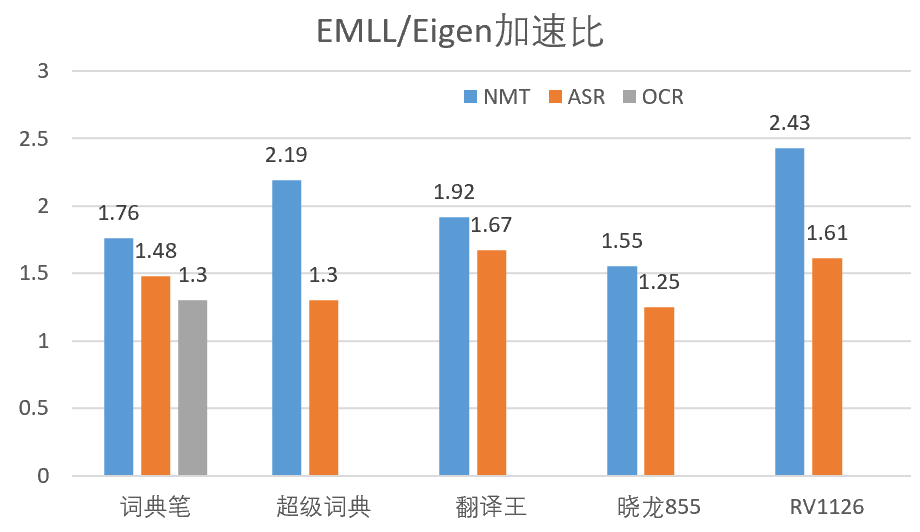
图 3 端侧 NMT、ASR、OCR 在不同平台上使用 EMLL 和 eigen 端到端性能加速比
EMLL 高性能端侧机器学习计算库,已经在网易有道多款智能硬件产品中实际应用并取得显著的效果,大幅提升性能,给用户带来更好的产品体验。
未来,网易有道将持续维护和优化 EMLL,帮助更多企业、科研机构等伙伴提升端侧 AI 计算能力。

InfoQ高级技术编辑

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论 1 条评论