

谷歌研究院与丰田技术学院联合发布了一篇最新论文,正式公布取代 BERT 的下一代方案——即体积更小、智能度更高的 ALBERT。(ALBERT:用于语言表示自监督学习的精简版 BERT,ALBERT: A Lite BERT for Self-supervised Learning of Language Representations)
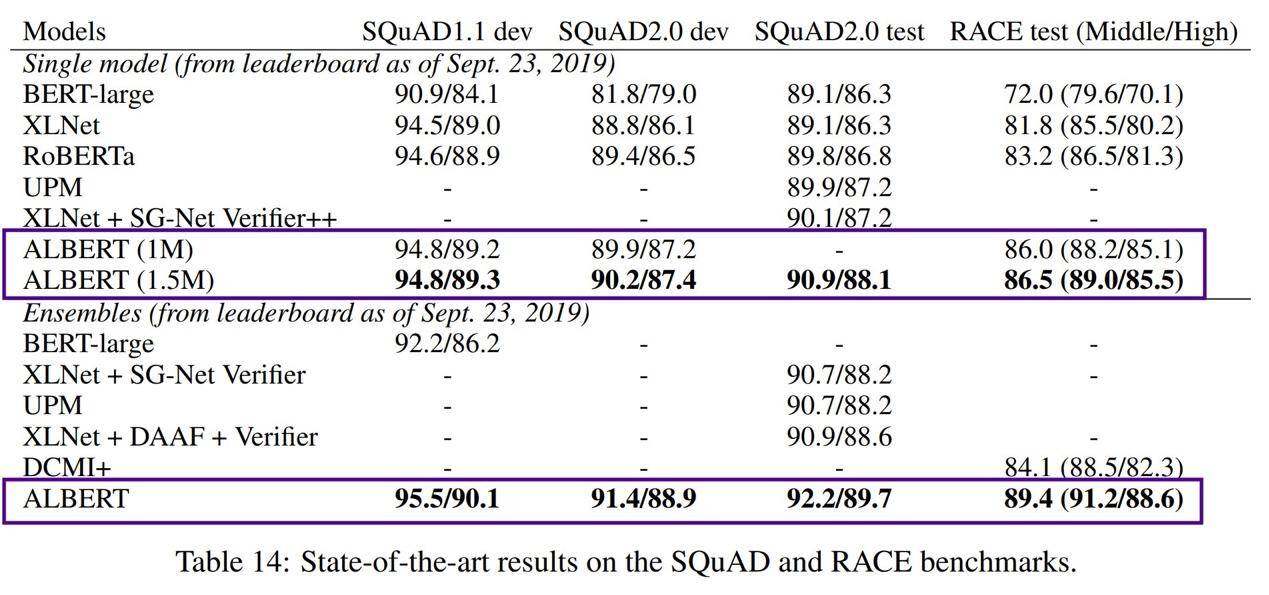
ALBERT 在 SQuAD 与 RACE 测试中刷新了 SOTA,并在 RACE 测试当中以 14.5%的优势击败 BERT……但先别急,后文将具体比较双方的成绩(表中的 1M 与 1.5M 代表训练步数)。
从最终结果来看,ALBERT 的表现确实令人惊艳(刷新了 GLUE、RACE 以及 SQuAD 的分数纪录)。但是……更让人印象深刻的,是 ALBERT 在模型/参数大小方面的瘦身效果。
两大关键架构变更与训练调整,使得 ALBERT 同时获得了出色的测试成绩与良好的瘦身效果。先来看 ALBERT 及其前辈 BERT 的参数差异——BERT x-large 拥有 12.7 亿个参数,而 ALBERT x-large 仅拥有 5900 万个参数!
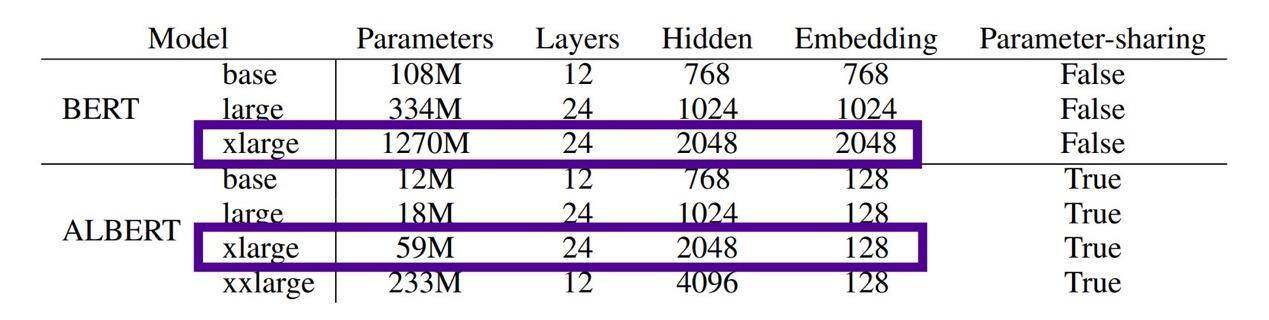
在同等网络规模(隐藏层)下,BERT 拥有 12.7 亿个参数,ALBERT 仅拥有 5900 万个参数……缩小约 21.5 倍。
这无疑是个值得认真探讨的大问题,我们将在本文中慢慢推进。
NLP 模型不是越大越好
我们先从 NLP 的一大重要方面入手——今年以来,NLP 技术取得了一系列辉煌成就,特别是 transformer 类模型的扩展使我们只需要简单扩大预训练模型的规模,就能够快速提高其最终准确性。在 BERT 论文当中,作者们曾提出并在一定程度上论证了 hidden size 越多、隐藏层越多、attention head 越多,模型的实际表现就越好。
目前规模最大的 NLP 模型为英伟达公司最近公布的 Megatron,这是一套包含 80 亿个参数的庞大模型,体积达 BERT 的 24 倍、OpenAI GPT-2 的 6 倍。Megatron 在 512 块 GPU 上经过 9 天才训练完成。
然而,其中无疑存在一个临界点或者说饱和点,导致模型体积并不是越大越好。ALBERT 的作者们证明,拥有 2048 个 hidden size 与 4 倍于原始 BERT 体积的 BERT X-Large 模型反而表现不佳——其准确率得分下降了近 20%。

越大并不一定就越好——将 hidden size 加倍(相当于将参数量提升至 4 倍),反而会导致 BERT 在 RACE 数据集上出现性能下降。
这类似于计算机视觉领域的层深峰值效应。提升计算机视觉模型中的层深会推动性能水平不断提升,但到某个临界点后则开始下降。例如,ResNet-1000 虽然拥有 6.5 倍于 ResNet152 的层数,但成绩仍然不及后者。换句话说,模型训练存在一个饱和点,一旦训练复杂性越过该饱和点,那么任何额外网络元素的加入都只会拉低增益。
考虑到这一点,ALBERT 的开发者们开始着手改进架构与训练方法,希望在构建“更大的 BERT”之外找到新的性能突破之道。
ALBERT 是何方神圣?
ALBERT 的核心架构与 BERT 非常相似,其中同样使用到 transformer 编码器架构以及 GELU 激活机制。在论文中,研究人员们还使用了与原始 BERT 相同的、包含 3 万个单词的语料库。(V=30000。)但最重要的是,ALBERT 做出以下三项重要且实质性的调整:
改进架构以提高参数使用效率:
1 分解式嵌入参数化
ALBERT 的作者们注意到,对于 BERT、XLNet 以及 RoBERTa 而言,WordPiece 嵌入的大小(E)与隐藏层大小(H)直接相关。
但是,ALBERT 的作者们指出,WordPiece 嵌入学习到的实际是与上下文无关的表示形式。而隐藏层嵌入则用于学习与上下文相关的表示形式。
BERT 的强大,主要取决于通过隐藏层学习到的、与上下文相关的表示形式。如果将 H 与 E 绑定在一起,则 NLP 必然需要极大的 V(词汇量),因此实际上只需要 V * E 的嵌入矩阵就必须要按照 H(隐藏层)进行规模设计。这就导致最终得到的模型往往拥有数十亿个参数,且其中大部分参数在实际训练中极少更新。
换言之,硬要把不同目标下的两种要素捆绑在一起,自然会导致参数使用效率低下。
反过来看,将二者彼此独立开来,则意味着参数使用效率将得到提高,并保证 H(与上下文相关)始终大于 E(与上下文无关)。
为了实现这个目标,ALBERT 将嵌入参数拆分成两个较小的矩阵。相较于以往将一个热矢量直接投向至 H 中,现在新模型会将热矢量投射至一个较小的低维矩阵 E 中,而后再将 E 投射至 H 隐藏空间中。
如此一来,参数则从 VH,瘦身成 VE + E*H 的形式。
2 跨层参数共享
ALBERT 还在所有层之间共享参数,从而进一步提高参数效率。具体来讲,前馈网络参数与注意力参数都实现了全面共享。
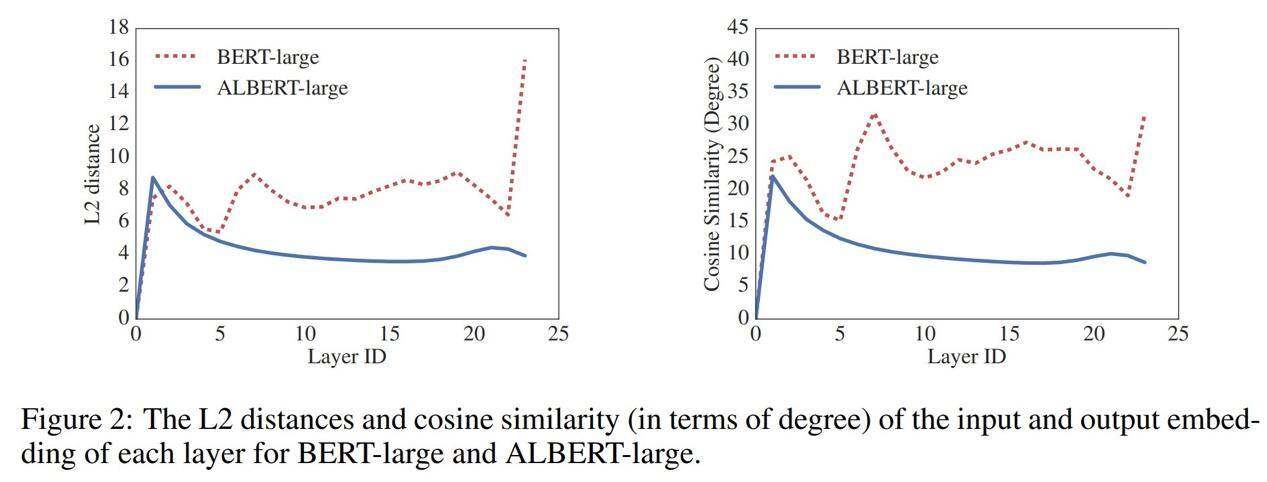
如此一来,与 BERT 相比,ALBERT 从一层到另一层的过渡变得更加顺滑。研究人员们还注意到,这种权重分配有助于稳定网络参数。
训练的革命——句子顺序预测,简称 SOP:
与 BERT 一样,ALBERT 也采用 MLM(屏蔽语言建模),且最多使用 3 个屏蔽字(n-gram 最大值为 3)。
然而,BERT 同时也使用到下一句预测(NSP)来配合 MLM……相比之下,ALBERT 拿出了自己的独家绝技——SOP 训练方法。
为什么不使用 NSP?这里需要强调一点,RoBERTa 的作者们已经证明,初始 BERT 当中使用的下一句预测(NSP)损失函数的训练效果并不好。以此为基础,ALBERT 的发明者们进一步从理论上解释了 NSP 为什么无法带来良好收效,并据此开发出 SOP——句子顺序预测。
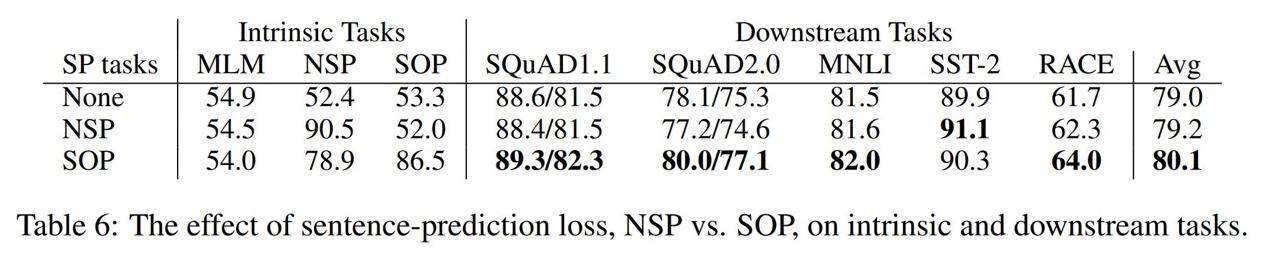
SOP (ALBERT)、NSP (BERT) 以及不使用(XLNet, RoBERTa)结果对比。
ALBERT 作者们认为,NSP(下一句预测)在理论上会尝试将主题预测与相干预测相结合。作为参考,NSP 会使用两个句子——若第二句来自同一文档,则代表匹配成功;若第二句来自不同文档,则代表匹配失败。
相比之下,ALBERT 作者们认为句子之间的一致性(而非主题预测)才是最重要的指标。因此,SOP 采用了如下执行方式:
使用来自同一份文档的两个句子,如果句子的顺序排列正确则视为匹配成功,如果句子顺序排列错误则代表匹配失败。
这就避免了主题预测的问题,同时帮助 ALBERT 逐步掌握了更细腻的话语或句子间衔接方式。
测试结果当然也证明了这一思路的正确性。
如果进行规模扩展,ALBERT 的表现如何?
正如之前提到,规模扩展会先增加收益、后降低收益,ALBERT 的作者们也进行了自己的规模测试,并发现了其中的层深与层宽(即 hidden 大小)峰值。因此,作者推荐在 ALBERT 当中采用 12 层参数交叉共享模型。
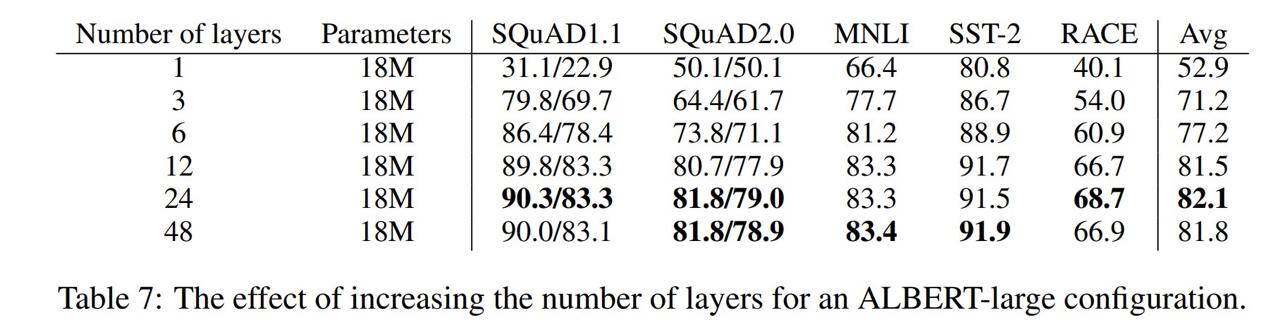

ALBERT 发现,删除随机失活(dropout)并添加数据能够提升性能:
ALBERT 的作者们在报告中指出,与计算机视觉技术领域发现的结论一致,删除随机失活并训练更多数据能够实现性能提升。
总结
ALBERT 在多个基准测试当中获得了目前最强的 NLP 性能水平,亦把参数效率提升到新的高度。这是一项了不起的突破,继承了一年之前 BERT 的出色表现,并从多个方面推动 NLP 技术的整体进步。令人耳目一新的是,AI 的未来并不单纯依赖于更多 GPU 以及直接构建规模更大的已训练模型,同时还取决于架构自身的改进以及参数效率的提升。在打破现有技术纪录的同时,参数的大量缩减(或者说参数效率的显著增长)也将让实用 AI 的可用性更上一层楼。
作者们指出,ALBERT 未来的工作可能是通过稀疏或者阻塞注意力来提高计算效率。期待这位后起之秀能为我们带来更多惊喜!
ALBERT 的 Github 以及官方/非官方消息源在哪里?
遗憾的是,我找不到任何正式发布至 GitHub 或者以其他方式进行开源的 ALBERT 代码,论文当中也没有提及。希望情况能够尽快得到改观。
非官方 PyTorch 版本:感谢 Tyler Kalbach 的帮助,我们找到了 ALBERT 的一套非官方 PyTorch 版本,GitHub 地址如下:
https://github.com/graykode/ALBERT-Pytorch
非官方 TensorFlow 版本:感谢 Engbert Tienkamp 的协助,我们找到了 ALBERT 的一套非官方 TensorFlow 版本,GitHub 地址如下:
https://github.com/brightmart/albert_zh
论文链接:
https://arxiv.org/abs/1909.11942v1
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论