

概述
究竟什么是中台, 业界并没有一个标准答案, 各个厂商都有自己的定义. 笔者比较认可的一个定义是 ThoughtWorks 提出的"企业级能力复用平台". 各个领域涌现出很多中台产品, 如业务中台, 搜索中台, 数据中台等. 其中数据中台这个词汇越来越多的出现在视野中, 从百度指数中可以看到这一趋势.
本文, 介绍有赞的数据中台产生的背景和建设思路. 简单来说, 有赞的数据中台解决的是"有赞的数据资产的加工和复用", 这里提到了数据中台的两个重要功能: 数据加工和数据复用, 分别由数据技术中台和数据资产中台解决. 数据技术中台主要解决数据的加工问题, 在众多大数据组件中,帮助数据开发者简化开发过程,提高开发效率. 数据资产中台主要是解决数据复用的问题, 要做到数据复用, 数据口径的统一是重中之重. 双管齐下, 提高对前台业务的支撑效率.
二. 数据团队面临的挑战
数据团队面临的挑战主要有两方面:
业务挑战
技术挑战
2.1 业务挑战
有赞是一家服务商家的 SaaS 公司, 服务数百万各行各业的商家, 提供电商解决方案. 有赞数据团队的服务对象主要是各个前台业务线, 所以一切故事的开始来源于业务团队. 因为业务特点决定, 目前有赞的数据需求有以下特点:
垂直业务线众多: 有赞微商城, 有赞零售, 有赞美业, 有赞教育等
业务域众多: 商品, 店铺, 会员, 交易, 支付等
数据需求多样: 商家后台数据报表需求, 运营侧数据分析需求, 大促看板需求, 实时报表需求等
业务需求迅速迭代: 业务模型的迭代演进, SaaS 领域对已有功能比较高的兼容要求等
…
2.2 技术挑战
业务线各种各样的数据需求, 给数据团队提出了很多挑战, 主要体现在两方面:
组件多, 维护成本高
开发门槛高
组件多, 维护成本高
软件行业"没有银弹"在大数据领域显现的淋漓尽致. 在有赞的大数据技术栈中, 针对不同的场景, 分别维护着众多的大数据组件. 如数据基础组件的 HDFS, YARN 组件;离线计算元数据组件 HIVE META, 离线计算引擎 HIVE, Spark SQL, Presto;实时计算框架 Storm, Spark Streaming, Flink 等. 这些还只是组件本身并不包括组件配套的鉴权, 安全, 脱敏, 质量相关的服务.
开发门槛高
比如,针对最普通的实时计算场景,任务的开发者通常考虑以下几个方面问题:
数据 Source 流在哪儿, 如何接入
数据处理后的 Sink 是流还是其他存储,如果是其他存储系统,可用性是怎样的,单机房可用还是多机房,扩展性怎么样, 写入是否有热点,是否可以配合实时链路的并行度调整做水平扩展
实时任务本身的高可用部署,监控及报警
消息的一致性语义是什么(at least once, exactly once 还是 at most once), 每种语义对上下游服务的要求是怎么样的
实时计算任务的计算资源如何配置, 水位如何,大促期间如何扩容
公司内部各种各样非大数据的技术组件,如何做适配
…
对于没有相关经验的同学, 需要查阅多种组件的文档, 势必会有开发成本高的困扰.
三. 数据中台
按照产生顺序, 数据中台主要包括:
数据技术中台
数据资产中台
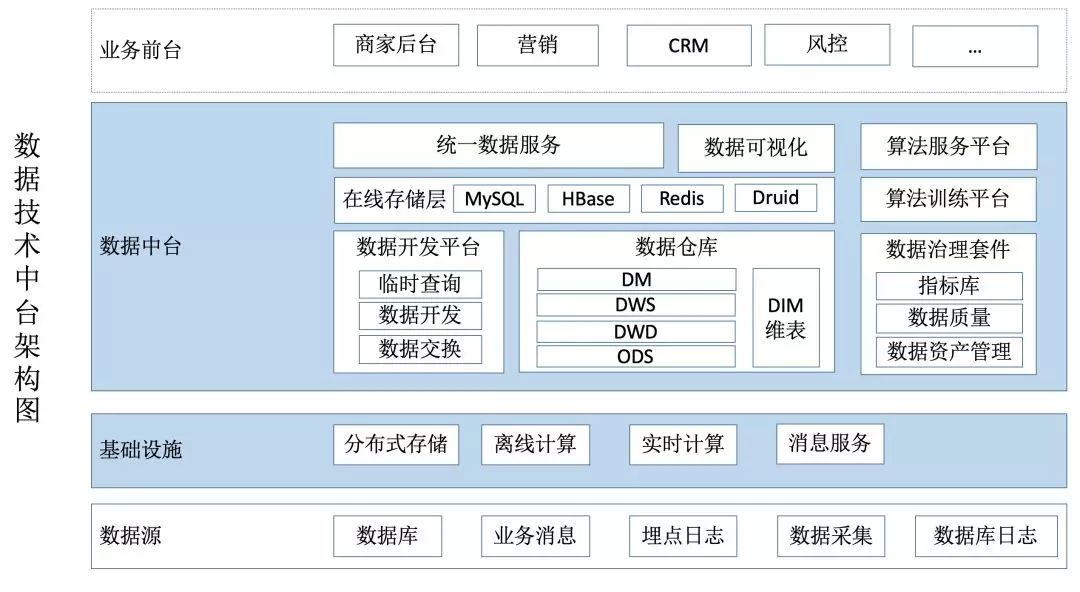
3.1 数据技术中台构建
所以, 技术上的复杂性, 带来了开发成本高的问题. 所以易用性的本质是为了提效, 数据技术中台由一些列工具型平台构成, 最主要的几部分如下:
基础组件运维管控
数据开发平台
数据资产管理平台
数据指标管理
统一数据服务
基础组件运维管控
上文也有提到, 大数据基础组件种类繁多, 概括下来可以分为三类:
离线计算组件 (HDFS,YARN, HIVE, Spark)
分布式在线存储组件(HBase, Kafka, Druid)
实时计算组件(Storm, Spark Streaming, Flink)
每类组件的管控需求都不尽相同, 比如在线存储组件对 rt, 可用性要求较高; 实时计算组件对延迟, 积压问题比较在意; 离线计算组件对数据吞吐能力要求较高, 但是因为是分布式计算,所以对慢盘, 慢任务需要有特别关注, 否则很容易一个节点拖慢整个集群.
运维管理好大数据组件, 做好动物管理员, 本身就是一件类似数据运营的工作, 找到系统的北极星指标, 关注它, 使用它来帮助做系统的优化.
总结下来, 做好数据组件的管理需要解决以下问题:
确定核心指标. 需要 case by case 的确认每个子系统的最核心的指标, 比如对 HDFS 系统来说, 文件数目, 文件操作 tps, 文件操作的 rt, 99% rt, 是否有丢块等,就是核心指标, 需要特别关注.
监控. 采集核心指标, 展现到监控上, 便于观察趋势, 帮助问题排查和扩容等操作的判断依据.
报警. 根据核心指标, 确定安全水位, 配置报警, 缩短故障发现时间.
具备一定的定制开发能力. 对使用组件不要求有核心 feature 的开发改造能力(这不符合 ROI), 但是在权限/安全方面, 社区版本很难满足定制需求, 这就需要对基础组件做一定的改造; 另外需要关注社区,对于重大隐患的 bug, 需要打回的公司的版本.
软件发布/配置发布规范. 多人协作, 多组件协作, 需要一个完整的开发/测试/发布流程, 不止对软件, 对配置的发布也一定要规范. 这方面曾经踩过不少的坑.
故障演练, 要定期的主动对技术组件做故障演练, 有些组件虽然支持某类功能,但是随着数据量, 负载的不同, 这类功能实际效果具体是怎样的需要通过实践来确认. 比如 HBase 支持单机宕机自动恢复, 但是宕机恢复时间究竟是多少, 跟集群负载, 各方面的配置都是相关的, 需要通过故障演练来组件优化系统.
性能摸底. 需要对组件做标准的 Benchmark, 一来掌握系统极限,二来在业务接入时能够提供准确的性能指标, 帮助业务方做选型判断.
…
数据开发平台
数据开发平台关注的是数据的加工, 是数据开发用户(数据产品开发同学, 数仓开发同学, 业务线数据开发同学)最频繁接触到的产品, 数据开发平台主要包括两个平台型产品, 分别解决离线和实时场景的数据加工需求.
离线开发平台, 主要负责离线数据的加工, 任务调度, 数据 ETL, 临时查询, 监控报警等
实时计算平台, 主要负责实时计算任务的管理, 监控报警等
关于这两个平台, 有更具体的文章介绍(见参考文章),这里不在赘述.
数据资产管理平台
数据资产管理平台主要解决数据资源的管理, 数据资产遍布在各个大数据组件中, 有 hive 的表, 有 hbase 的表, 有 druid 的 datasource, 有 kafka 中的流, 各个组件的管控系统很难互相打通, 所以需要一个统一的数据资产管理服务, 来统筹大数据资源的管理.
总体说来, 数据资产管理平台关注的是数据的静态状态, 比如 Hive 的库表/字段, HBase 的表, Kafka 的 Topic. 提供以下几方面的工具:
数据地图(方便用户查找,定位已有的数据自产并复用)
数据质量(对数据资源,根据预设的规则做质量检查,提前发现潜在问题,比如每日数据量,是否有字段缺失等,并且在数据不合格的状况下能够及时通知出来)
成本核算(统计各个团队,组件的成本占用,利于做成本降低之类的优化,当数据体量达到一定规模的时候, 成本问题会变的越来越重要)
数据血缘管理(管理所有的数据资源的依赖关系, 主要用在两个场景: a. 数据问题评估, 当上游数据变更或者质量问题的时候, 能够快速确定影响面和修复方案. b. 数据生命周期管理, 当下游应用下线,不再使用某个数据的时候,能够找到不被引用的数据, 及时下线,避免不必要的计算)
…
数据指标管理
如果说数据平台关注的是数据的加工/转换,既数据任务的管理; 数据资产管理平台关注的是具体的数据表和字段的质量和血缘; 那么指标库管理的就是数据指标的口径统一和复用. 在有赞, 我们通过指标库系统来管理数据指标的口径.
概括来说,数据指标被分为原子指标和派生指标. 原子指标为不可再分割的基础指标, 由数仓团队统一开发和管理, 原子指标数据一般落在数仓的 DW 层. 但是往往业务方需要的指标, 原子指标并不能满足, 所以业务方需要在原子指标的基础上再次加工成派生指标. 比如 交易数据中 gmv 是原子指标, 微商城业务最近 30 天的 gmv 指标就是派生指标 wsc30dgmv.关于指标库, 后面会有单独的文章介绍.
统一数据服务
数据开发平台,资产治理平台,指标库只是解决了数据的加工和口径的统一的问题. 产出的数据并不是真正对外可用的. 绝大多数场景, 都需要数据开发的同学, 将加工后的数据, 通过数据交换组件, 导出到线存储服务中, 然后再开发数据接口, 供前台业务同学调用. 这里在线存储服务到接口这一层, 传统的业务支撑方式中存在大量的重复开发. 针对这个问题, 我们设计统一数据服务, 用户通过配置模板的方式, 生成数据 API 服务, 简化开发流程. 有赞的统一数据服务目前刚刚上线, 已经支持 10+业务场景, 后面会有单独的文章介绍.
3.2 数据资产中台构建
3.1 节中介绍了偏技术视角的中台, 涵盖了大数据的技术架构. 但是数据中台远不止技术设施,更主要的是数据资产的建设和组织, 因为对业务方而言,业务方更关注的是有哪儿些数据自产可以使用,而不是通过什么底层技术实现.
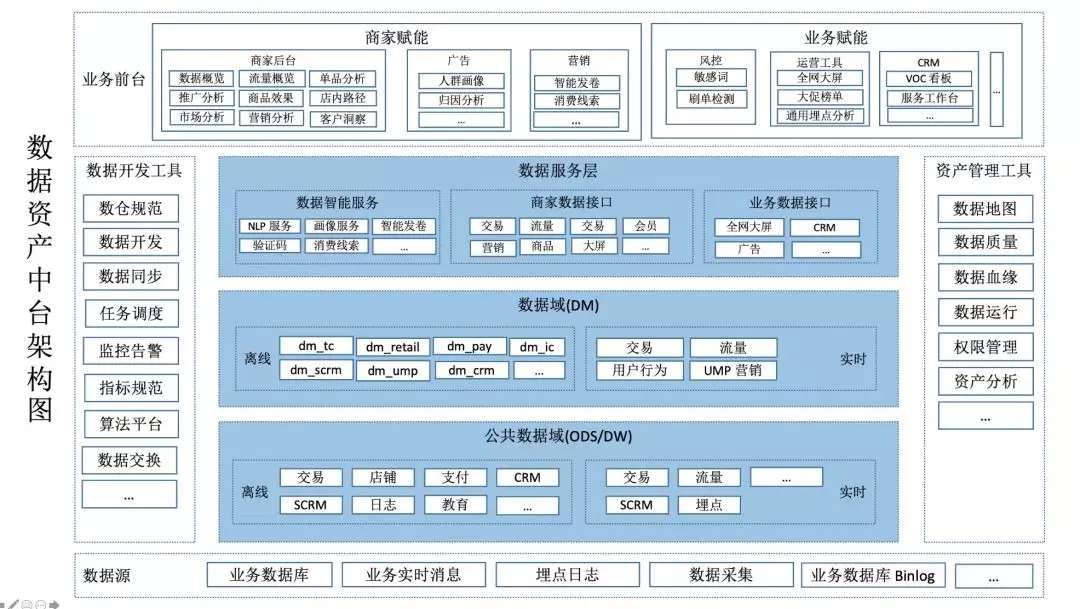
大数据团队提供的数据资产主要有以下几类:
离线数据资产(离线数仓)
数据智能服务
实时数据资产(实时数仓)
在用户数目上, 目前离线数仓承接了大多数的数据需求, 这里仅仅对离线数仓展开介绍. 离线数仓中数据的开发主要发生在数据开发平台上, 包括数据 etl 导入任务, 数据开发任务, 数据 etl 导出任务,任务流的管理和调度. 借助于指标库和数仓开发规范做数据的加工. 整个开发过程中, 数据开发平台,数据质量管理,指标库平台会通过对命名, 指标的查重等手段来强制一些开发规范的执行, 从根本上解决数据指标口径一致和数据复用等问题.
有赞离线数据资产如上图中蓝色部分, 从底向上分为三层:
公共数据层
公共数据层主要承载数仓建模中的 ODS 层和 DW 层, 数据的开发和口径管理由数据仓库团队负责. 数据的开发和口径管理严格按照数仓开发规范和指标管理规范,提供公共的原子指标的开发.
垂直业务域数据层
垂直业务域数据层, 树妖曾在数仓建模中的 DM 层, 数据的开发和口径管理由业务方的数据开发同学负责. 业务方同样根据数仓开发规范和指标管理规范, 完成派生指标的开发.
数据服务层
数据在离线数仓中开发完毕后, 通过数据开发平台的 ETL 导出任务导出到在线存储层, 然后自行封装或者通过统一数据服务,提供在线数据接口.这一分层在实时数仓中同样适用, 本文不展开
三. 总结 &展望
有赞数据中台并不是一蹴而就, 而是面临着业务和技术上的挑战逐渐成长到现在, 当然还有很多待完善的地方, 比如指标库,统一数据服务还处于刚刚起步阶段. 后面有赞数据中台的建设将主要集中在成本,数据资产管理 &复用,实时数仓等方面发力, 帮助我们的商家和业务方挖掘更多数据价值.

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论