

在全球,Netflix 拥有超过 1.5 亿的用户,因此,创新和速度是我们优先考虑的。这样才能为用户带来最佳体验。

这意味着我们的微服务不断发展和变化,但不变的是我们的责任。我们有责任提供高可用性服务,这些服务每天向订阅用户提供 1 亿小时以上的流媒体内容。
为实现这种级别的可用性,我们利用了 N+1 的体系结构。在这种结构中,我们将 Amazon Web Services (AWS:亚马逊的云服务)上的区域视为很多的故障域,这种策略允许我们承受单个区域的故障。
在单个独立的区域发生故障时,我们首先在健康区域对微服务进行规模预扩展,之后我们就可以将流量从那个故障区域转移出去。
这种预先规模扩展是必要的,因为我们使用了自动规模扩展的方式,这通常意味着我们提供的区域服务规模正好能够处理它们区域当前的需求,在区域流量转移过来之后,它们的流量会增加,原有的服务规模也就可能不够用了。
虽然我们现在已经有了这种流量疏散能力,但这种弹性并非 API 一开始就有的。2013 年,我们首次开发了多区域可用性策略(multi-regional availability strategy,以防止当年的故障再次发生,并加速了我们重新构建服务运营的进程。在过去 6 年,Netflix 和我们的客户群一起不断地成长和发展,推翻了我们预先扩展微服务能力的核心假设。这两个假设是:
所有微服务的区域需求(即请求、消息和连接等需求)都可以通过我们的关键性能指标(每秒流启动:stream starts per second,缩写为 SPS)提取出来。
在流量疏散过程中,可以统一地扩展健康区域内的微服务。
这些假设简化了预扩展机制,让我们用统一的方式对待微服务,而忽略了需求的独特性和区域性。在 2013 年,由于当时的服务以及客户群也相当统一,这种方法运行得很好,但随着 Netflix 的发展,这种方法变得不那么有效了。
无效的假设
区域性的微服务需求
我们的大多数微服务都在某种程度上与服务的数据流相关,因此 SPS 似乎是简化区域性的微服务需求的合理方式。对于大型单体服务尤其如此。例如,播放器日志记录、授权、许可协议和书签最初由一个单体服务处理,该服务的需求与 SPS 高度相关。
然而,为了提高开发人员的速度、可操作性和可靠性,我们把这个单体服务分解为更小的、具有不同功能特定需求的服务,这些服务都是为了某个目标专门构建的。
我们的边缘网关(zuul)也通过功能分片取得了类似的成绩。下图说明了每个分片的需求、综合需求和 SPS。从综合需求和 SPS 线来看,SPS 大致相当于一天中大部分时间的综合需求。但从单个分片来看,使用 SPS 作为需求指标而引入的错误,其数量差异很大。
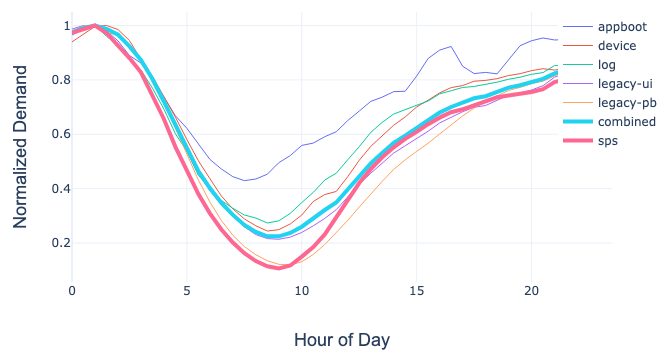
Zuul 分片在一天中的标准化需求示意图
统一的疏散扩展方式
由于我们使用 SPS 作为需求指标,因此若假定我们可以在健康区域统一地预扩展所有微服务,这个假定看起来似乎也是合理的。为了说明这种方法的缺点,让我们看看回放许可(playback licensing:DRM)和授权的情况。
DRM 与设备类型密切相关,比如消费电子(CE)、Android 和 iOS 均使用不同的 DRM 平台。此外,CE 与移动流媒体的比例在区域上存在差异;例如移动端在南美更受欢迎。因此,如果我们把南美的流量转移到北美,对 CE 和 Android DRM 的需求将不会同步增长。
另一方面,回放授权是所有设备在请求许可之前使用的功能。虽然它确实有一些特定的设备行为,但更主要的是,疏散期间的需求是区域性的需求总体变化的函数。
缩小差距
为了解决前述方法中的问题, 我们需要更好地描述特定微服务的需求,搞清楚当我们疏散流量时这些需求是如何变化的。前者要求我们捕捉区域对微服务的需求,而不是依赖于 SPS。后者需要更好地理解按设备类型划分的微服务需求,以及疏散过程中跨区域设备需求的变化。
特定微服务的区域性需求
因为服务是不统一的,我们知道了使用诸如 SPS 这样的代理需求指标是站不住脚的,我们需要针对特定微服务的需求指标。不幸的是,由于服务的多样性,其混合了 Java(带有Ribbon/gRPC 的Governator/Springboot 等)和 Node (NodeQuark),我们无法依赖单个需求指标来覆盖所有的用例。为了解决这个问题,我们构建了一个系统;对每个微服务,该系统都允许我们将其关联到能代表其需求的指标上。
微服务指标是配置驱动的、自服务的,并且允许确定范围,这样的话可以让微服务在不同的分片和区域之间具有不同的配置。然后我们的系统查询Atlas(这是我们的时间序列遥感勘测平台)以收集所需要的历史数据。
按设备类型划分的微服务需求
由于区域性的设备偏好会影响需求,我们需要解析微服务需求,以揭示特定于设备的组成部分。我们采用的方法,是根据聚合的设备类型(CE、Android、PS4 等)划分微服务的区域需求。
不幸的是,现有的指标不能统一地揭示出按设备类型划分的需求,所以我们利用分布式跟踪来揭示所需的详细信息。使用这些采样得到的跟踪数据,我们可以解释微服务的区域设备类型需求如何随时间变化。下图突出显示了某个微服务的相对设备需求在一天中的变化情况。
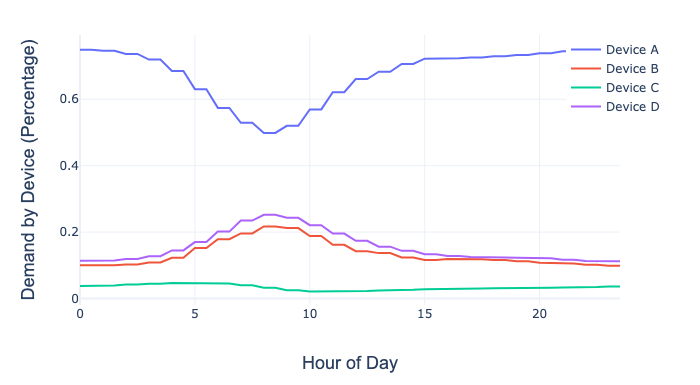
按设备类型划分的区域性微服务需求
设备类型的需求
我们可以使用以前的设备类型流量,来了解如何扩展服务需求的组成部分,这些组件都是特定于设备的。例如,下图显示了当我们疏散 us-west-2 的流量时,us-east-1 中的 CE 流量是如何变化的。
将 nominal traffic 线和 evacuation traffic 线进行标准化,使 1 表示最大(nominal traffic),需求扩展比例表示疏散过程中需求的相对变化(即 evacuation traffic/nominal traffic)。
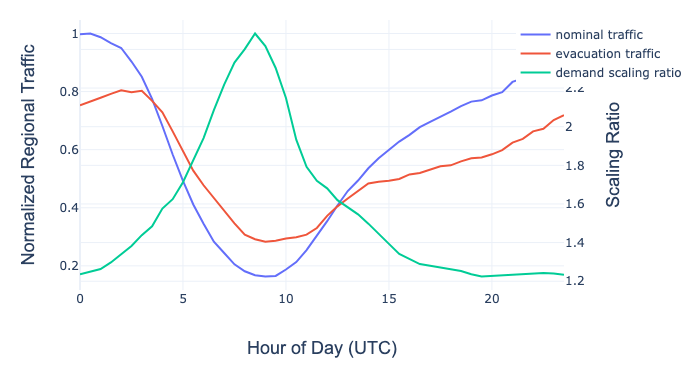
在 US-East-1 区域中,Nominal vs Evacuation CE 流量
特定于微服务的需求扩展比例
我们现在可以将按设备划分的微服务需求,和特定于设备的疏散扩展比例组合起来,从而更好地表示疏散过程中微服务区域需求的变化——即微服务的设备类型加权的需求扩展比例。
为了计算这个比率(一天中的特定时间),我们取服务的设备类型百分比,乘以设备类型疏散扩展比例,生成每种设备类型对服务的扩展比例的贡献。将这些组成部分相加,就得到微服务的设备类型加权疏散扩展比例。为了提供一个具体的示例,下表显示了一个虚构的服务的疏散扩展比例计算。
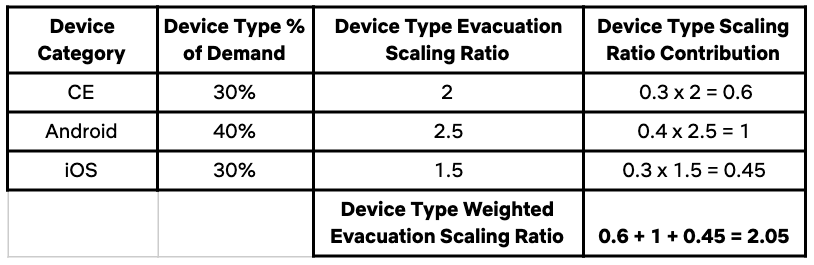
服务疏散扩展比例计算
下图突出显示了,使用特定于微服务的疏散扩展比例,与之前使用的基于 SPS 的简化方法的影响对比。在服务 A 的情况下,旧的方法可以很好地逼近这个比率,但在服务 B 和服务 C 的情况下,旧的方法将分别导致预测需求过高和过低。
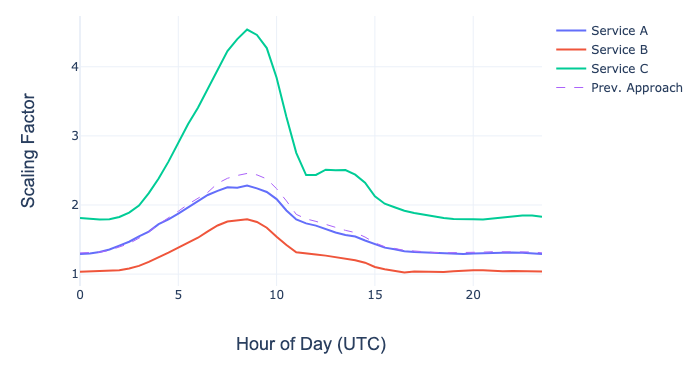
设备类型加权与以前的方法
接下来做什么?
对微服务需求独特性的理解提高了我们的预测质量,并以额外的计算复杂性为代价实现了更安全、更有效的疏散。然而,这种新方法本身就是一种近似,它也带有自己的一组假设。
例如,它假设设备类型的所有类别的流量(例如 Android 日志记录和回放流量)都具有相似的形状。随着 Netflix 的发展,我们的假设将再次受到挑战,我们必须适应,继续为客户提供他们所期望的可用性和可靠性。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论