
引言
日常开发工作离不开对数据库的增删改查操作,现代 Web 应用开发一般采用 ORM(Object Relation Mapping, ORM)框架作为连接代码与数据库的桥梁。ORM 框架实现了数据库表与类的映射转化关系,基于开发所使用的语言和数据库结构可以生成相应数据访问层代码,用于日常开发工作。
本文主要讲述了在微服务开发架构下,如何实现数据访问层代码生成的自动化,并解决自动化过程中新数据库表的领域归属问题。为了解决问题,团队引入了深度学习的方法,基于业务现存数据,对新表归属的领域微服务进行预测,辅助整个自动化流程进行,使开发流程变得更加简洁与高效。
背景
FreeWheel 微服务开发的现状
FreeWheel 核心业务系统采用领域微服务架构,并使用 Go 语言作为微服务的开发语言。该架构对于不同的领域服务定义了明确的边界和不同的职责。服务内部共享资源,服务间采用 gRPC 调用来实现数据连接。FreeWheel 后端开发对数据库的使用主要通过由外部开源的 ORM 库来进行,该工具基于数据库 schema 来生成后端可直接使用的数据访问层代码。
数据访问方式
FreeWheel 业务数据存储以 MySQL 关系型数据库为主。由于业务的复杂与多样性,每个微服务下都有很多数据库表,对于不同数据表中数据的增删改查也是按照不同的微服务进行隔离,每个表都只属于一个微服务,都有特定服务的负责人。数据访问层代码是基于具体的微服务来生成的,属于一个微服务的表的增删改查接口会被封装在同一个模型中,通过 go module 的形式发布到内部的 Artifactory 平台上,供微服务进行引用和调用。
每当数据库表有 DDL 更新的时候,都需要重新生成该微服务的数据访问层代码,来更新数据接口,保持数据接口代码和数据库表的一致性。
数据库更新背景
目前核心开发团队的数据库 schema 改动都存储在一个 GitHub 仓库中,并基于此构建 Docker 镜像用于日常业务开发。仓库里包含 DML 和 DDL 两种文件,根据上线周期分别存储在不同的文件夹路径下。日常开发使用的数据库镜像(Regression db 和 Regression db:schema)会每天根据这个仓库下当前开发周期位置的改动文件进行更新。Regression db 镜像主要用于每天的自动化测试,需要使用最新的 schema 数据才能够保证回归测试代码按预期运行。
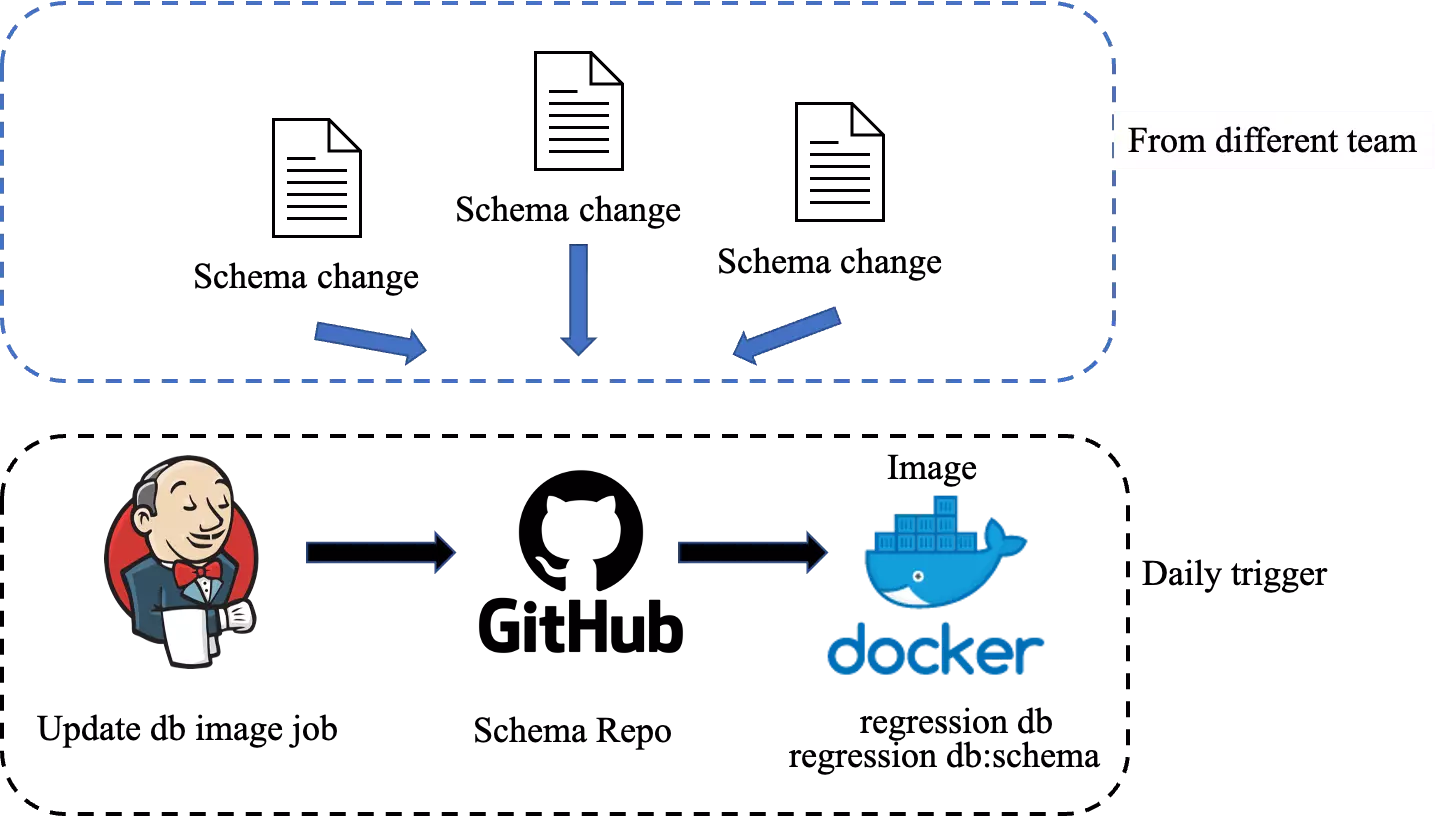
数据库 schema 的改动可能来自于各个团队的成员,每天会触发一次更新 regression 镜像的任务。生成最新的数据库镜像供日常开发使用。上图为日常数据库镜像更新流程。
因为数据库镜像是每天都按照 schema 的仓库更新一遍,会把需要在当前开发周期更新的数据库操作都执行。可以认为是当前开发周期里,最新的数据库 schema。对未来开发周期位置的文件则不会更新到每天的 Regression db 中。等到属于它的开发周期,再更新到数据库中。对于日常开发来说,如果对 schema 有改动,需要基于当天的 regression db 执行自己的改动,然后再通过工具手动生成最新的数据访问层代码,保证生成出来的数据访问层代码能够符合本地更新后的数据库,实现幂等。
第一阶段:现状——本地手动更新
目前更新数据访问层代码是在开发人员本地进行的。首先需要从 Artifactory 拉取最新的 regression db:schema 镜像,然后执行自己需要进行 schema 改动,针对改动完成的数据库镜像生成最新的数据访问层代码。然后提交 Pull request 到代码仓库中,具体流程如下图所示。
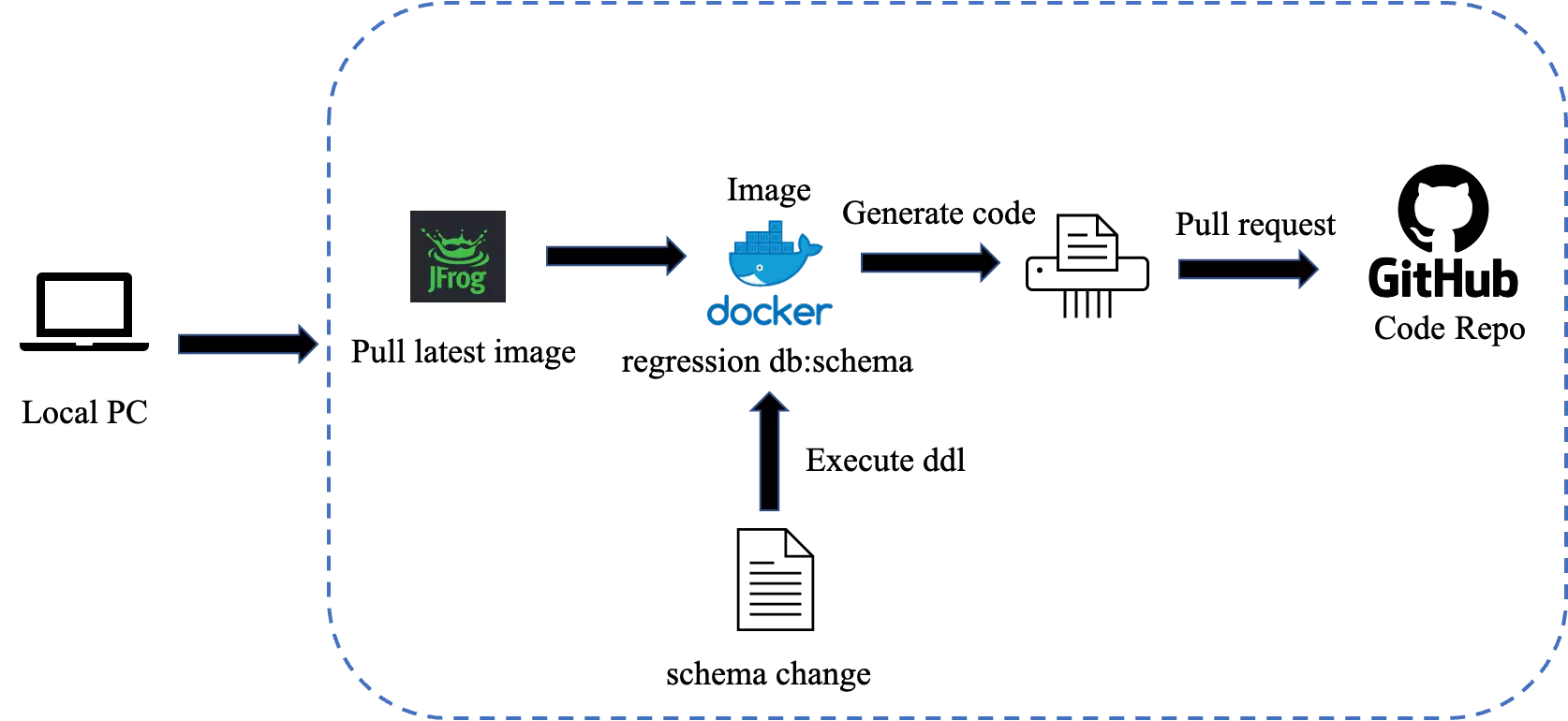
自动化更新数据访问层代码的需要
数据访问层代码与数据库表之间需要保证一致性,如果没有及时更新数据访问层代码,会导致数据库表和数据接口代码之间出现断层。目前业务团队的开发方式是,当数据库表有 DDL 改动的时候,该微服务的团队成员负责更新数据访问层代码,在本地手动生成。
多人协作开发产生冲突
一个微服务包含多张表,开发团队有多人,数据访问层代码基于数据库的 schema 来进行相应数据接口的生成。在开发过程中,不可避免的会有多人同时更新一个微服务的不同表,大家在本地生成数据访问层代码时,使用原 schema 加上自己的 DDL 改动,然后生成最新数据访问层代码。不会执行他人在开发过程中的其他 ddl 改动。日常开发数据库(regression db)的更新,对于在当前开发周期的 DDL 改动,是每天更新一次,如果是未来开发周期的 ddl 改动,将不会更新在其中。如果多人同时对一个微服务下的表进行改动,并且其他人的改动还没有在 regression db 中执行,各自本地生成的数据访问层可能会产生冲突。
另一方面,本地开发使用的数据库不一定是最新的 Regression db,由此基于此生成的数据访问层代码可能存在断层。
跨团队合作不明确流程
因为项目性质,经常会有跨团队的合作。其他团队对于改动数据库 schema 之后,需要按照其所属微服务来更新数据访问层代码的流程并不熟悉。没有把 schema 的改动告知微服务的负责人,导致未及时更新数据访问层代码,从而造成数据接口和数据库之间的断层的情况。另一方面,对于新入职的同学,需要一定的学习成本来熟悉这套流程,并且不知道修改的表是属于哪个微服务来负责的。
为了解决上述问题,我们认为根据数据库 schema 的改动,自动化生成数据访问层代码的流程是有必要的。自动化该流程能够带来以下好处:
避免多人协作开发时更新数据访问层代码的冲突问题
避免数据接口与实际数据存在断层
节约沟通和学习成本
使大家日常开发的数据访问层代码基准一致
第二阶段:部分自动化——Pipeline 搭建
更新数据访问层代码的方案计划与设计
流程设计
我们对于数据库的改动包含 DML 和 DDL 两种,都存在一个 Github 仓库中,每个文件都按照内部开发的 CLI 工具进行提交,从而保证了提交文件命名的规范,可以通过命名上区分 DDL、DML、rollback 文件(但具体执行的时候还是会根据 SQL 解析再判断一次 DML 还是 DDL)。通过提交的文件路径来区分是当前文件需要在哪个开发周期执行。
整个自动化流程设计图如下:
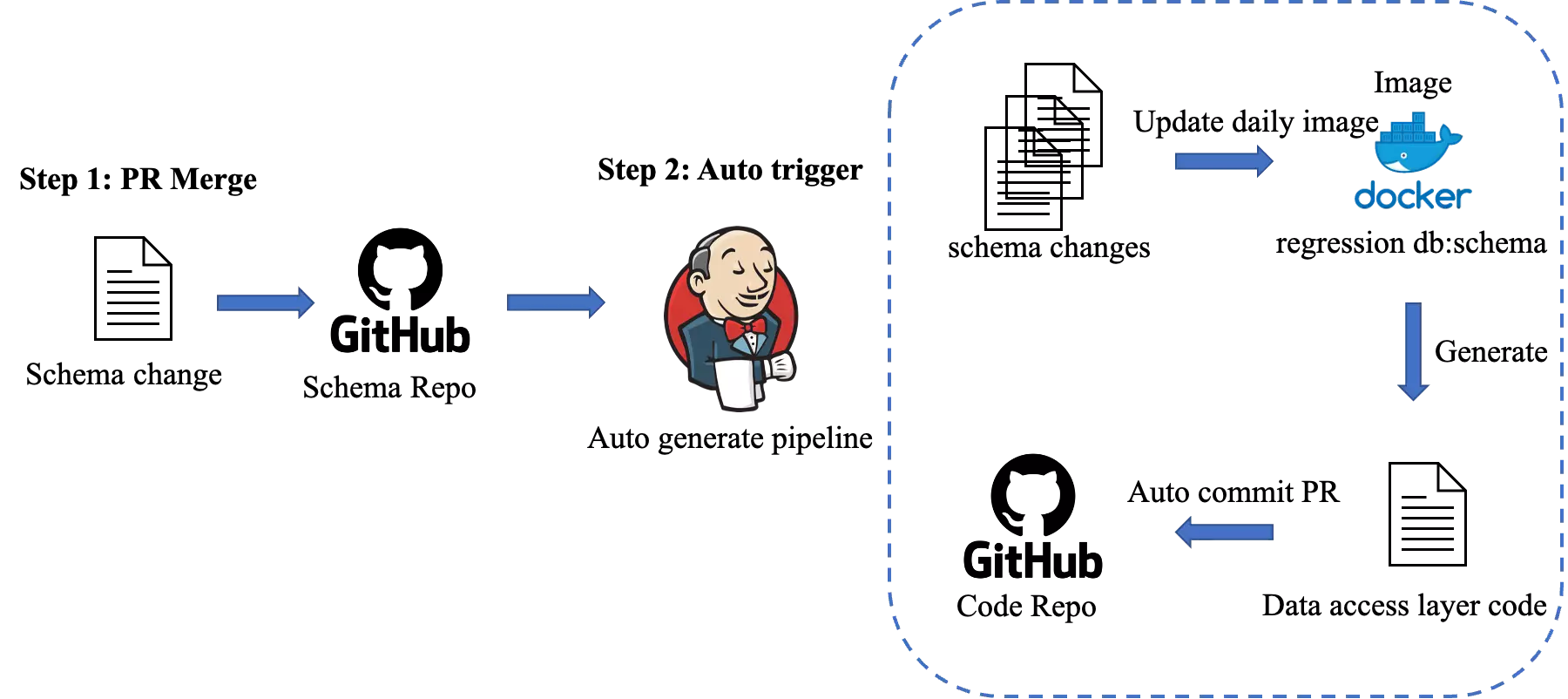
这样,我们只需要对数据库仓库进行监控,当有新的 Pull Request 合并了,就触发一个 Jenkins 的任务,我们生成相应数据访问层代码的过程就集中在这个 Jenkins 任务里。每一个 schema 的 Pull Request 都会触发下游的数据访问层代码生成,避免了没有及时更新数据访问层代码而造成数据接口与实际数据存在间隙的问题。
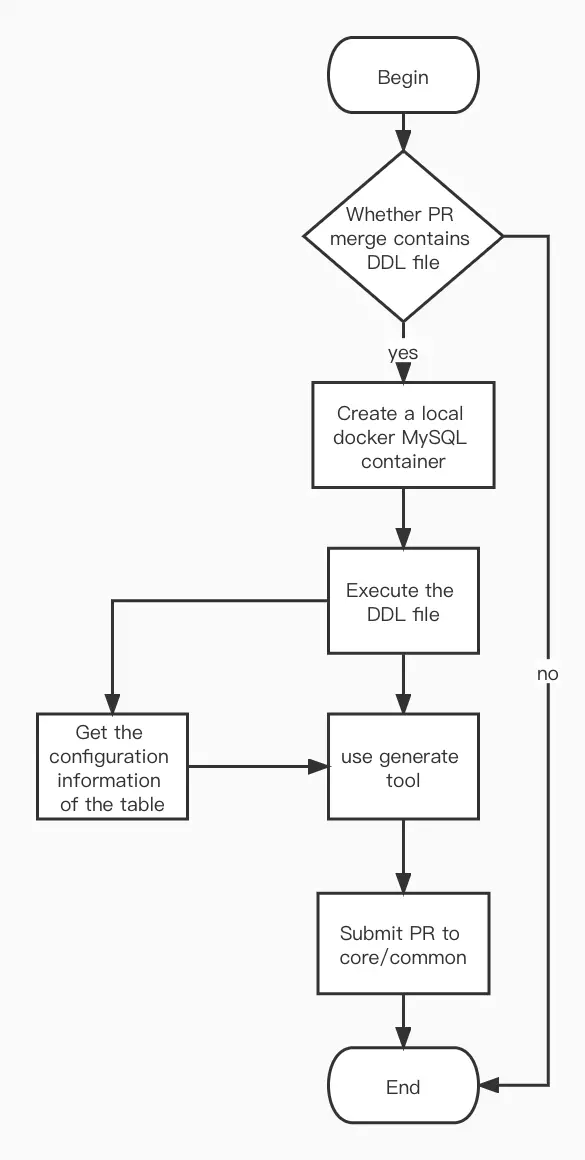
Jenkins 任务的执行过程如上图所示:
上游为数据仓库的 Pull Request 合并进入主分支,会把当前 Pull Request 包含的改动文件传给 Jenkins。
首先判断当前改动文件是否存在 DDL 的改动,只有 DDL 改动才需要更新数据访问层代码;如果仅为 DML 文件改动,则无需生成新的数据访问层代码,任务提前结束。否则进入下一步。
启动一个 docker MySQL 容器,使用日常开发数据库的 schema 镜像(regression db-schema-only 镜像),在日常开发数据库的基础上,执行 DDL 文件。
在使用数据访问层代码生成脚本的时候,需要把当前更新的微服务名字作为参数传入。数据访问层代码在生成各个微服务的模型时,维护了一个配置文件,以微服务为单位。包含属于这个微服务的所有数据库表以及这些表的外键关系。我们可以从这些配置文件中获得当前 DDL 文件里所做变更的表所隶属的微服务。
基于更新后的数据库,和根据配置文件找到的微服务,调用数据访问层代码生成脚本,进行代码生成。
更新了数据访问层代码后,自动提交 Pull Request 到代码库中,使用Github/Cli工具,能够直接通过 cmd 命令的形式,提交 Pull Request 到指定的 repo,并且还能同时设置 Label、reviewer、assignee 等。这里我们在提交 Pull Request 之后,自动设置 label 标明是由工具自动生成的 Pull Request,且把 reviewer 设置为对应的微服务的负责人。
最后,发送任务执行完成的通知到群组中,包含上游数据库触发该任务的 Pull Request 信息,自动提交的数据访问层代码更新的 Pull Request 信息,以及对应微服务的负责人,至此,Jenkins 任务完成。
整个 Jenkins 任务的平均时间为 10 分钟,大大减轻人工手动在本地更新数据访问层代码的时间成本。同时因为每一条 DDL 改动均会触发 Jenkins 任务,保证了每一个改动都生成了相应的数据访问层代码,避免了遗漏的情况。
Jenkins 自动化生成任务的局限性
对于新表创建(Create Table )的场景,之前开发同事在本地生成数据访问层代码时,因为明确该新表所隶属的微服务,所以会先修改对应微服务的配置文件,再根据修改后的配置文件信息和执行 schema 改动后的数据库生成数据访问层代码,最后提交到主代码库中。但在我们将整个数据访问层代码生成阶段做成自动化的任务之后,Jenkins 并没法判断新表属于哪个微服务,因此我们需要对新表创建的场景进行特殊处理。
也许有人好奇为何不能在 DDL 改动的时候把对应的归属在 Pull Request 里写清楚,这是因为在我们实际的业务开发过程中,时常会有一些新表的创建来自于其他兄弟团队正在进行的产品原型验证。只有当产品原型验证通过并且有对外暴露增删改查接口的需求时,才有必要生成数据访问层代码。因此修改 schema 的权限不仅限于各个微服务的负责团队,无法固定要求由微服务负责人保证同步更新 Schema 和配置文件。因此我们有必要考察新的思路来解决这一问题,保证整个任务的自动化。
第三阶段:全自动化——微服务归属预测
引入深度学习到工程实践中
我们统计了一下最近几个开发上线周期Create Table 的数据信息。
根据统计数据,平均每个开发上线周期有 6 个新表创建的情况,虽然单个周期数量不大,但这是一个持续性的问题,随着业务的拓展,会不断有新的微服务、新表的增加。同时考虑到对于新同学或者是不太熟悉微服务归属的同学来说,也不可避免引入额外的沟通学习的成本。
重新审视这个问题,我们把所有表和微服务归属进行了列举,发现大多数表的命名规则和微服务领域名称有着很高的相似度,这启发我们考虑通过深度学习的方法,来对新建的数据库表所属的微服务进行预测,从而解决这一问题。
下表统计了当前所有领域微服务和已有表的数据信息:
从上表可以看出,不同微服务之间所拥有的数据库表数量有很大差异,且平均表数不超过 100,属于典型的小样本的预测学习。考虑到领域微服务的数量相对稳定,即便将来会引入新的服务,改动需求也不会太频繁。因此,可以归纳为小样本文本的分类问题。根据表名来对数据库表属于哪个微服务进行分类。
目前现有表的命名形式为xxxx_xxxxxx_xxxxxx_xxxx 按照下划线进行分词,将每个表的表名划分为一个词组,作为模型的输入,最长表名词组为 7 个单词,最短词组为 3 个单词。所有微服务领域名称作为模型训练的 Label,建模进行分类预测。
训练集和测试集划分
考虑到不同微服务的现有表数据分布情况,按照每个微服务隶属表的 80%与 20%的比例进行划分,而不是随机划分。
RNN 模型
RNN 模型具备短时间的记忆功能,适合处理自然语言等问题。因此我们首先考虑使用经典 RNN 模型来建模,如下图所示。

输入数据首先经过嵌入层(embedding)处理,把每个表名当作一个字符串,去除连接符,进行词向量化,作为模型的输入数据。输出结果为每个类别的概率值,有几个微服务就有几个类别,结果为该表分别属于这些微服务的概率。我们把概率最大的微服务认为是当前表的所属微服务。
最终分类效果并不理想,把表名看作一个字符串进行嵌入层处理时,会丢失掉很多信息,每个表名里含有多个单词,没有运用到表名里多个单词之间的信息量。
TextCNN 模型
基于上述结果我们考虑尝试使用 TextCNN。它是一种卷积神经网络,卷积核的操作也能够结合上下文的关系,进行模型训练,同样适合在自然语言处理的任务上使用。TextCNN 模型的结构如下图所示。
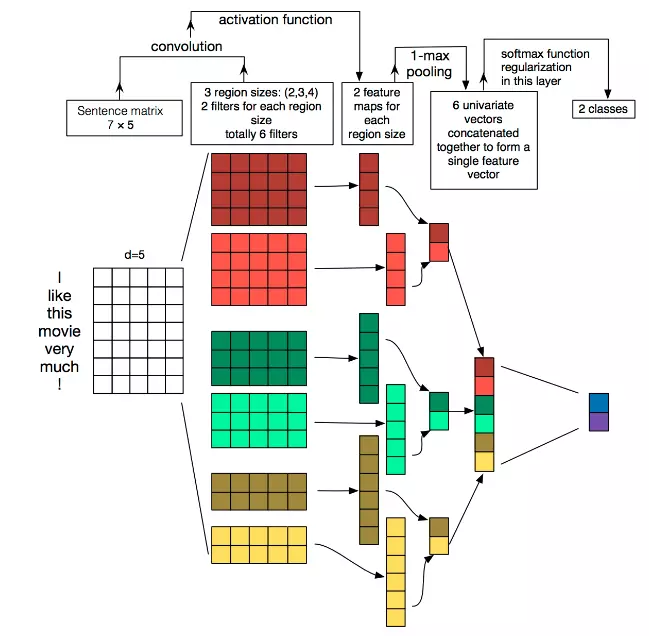
首先也是对数据进行数值化,我们先将表名进行分词。鉴于每个表名所含的单词数量长短不一,我们设置了一个统一的词量,少于标准的就进行重点词汇填充,超过的就进行截断。然后对每个词进行编码,这样每条训练数据就是长度固定的词向量。
多分类模型的精确率和召回率
针对模型的预测分类结果,我们使用多分类精确率、召回率和 F-score 值来衡量。
True Positive (TP): 把正样本成功预测为正。
True Negative (TN):把负样本成功预测为负。
False Positive (FP):把负样本错误地预测为正。
False Negative (FN):把正样本错误的预测为负。
分别计算每个微服务的 TP、FP、FN,并计算起精确率和召回率。
其中,
$Precision(精确率)=\frac{TP}{TP+FP}$
$Recall(召回率)=\frac{TP}{TP+FN}$
这样每个微服务的类别都会得到精确率和召回率的结果,因为不同类别之间的现有表数量分布差异较大,我们期望对于表多的微服务(说明业务需求更多更活跃)分类更精准,因此采用 Weighted-average 方法将其结果聚合。
$$Weighted-Precision=P_{D1}\times W_{D1}+P_{D2}\times W_{D2}+P_{D3}\times W_{D3}$$
$$Weighted-Recall=R_{D1}\times W_{D1}+R_{D2}\times W_{D2}+R_{D3}\times W_{D3}$$
$$Weighted-F-Score=(1+\beta^{2})\times \frac{Weighted-Precision\times Weighted-Recall}{\beta^{2}\times(Weighted-Precision+ Weighted-Recall)}$$
最终通过$Weighted-Precision$、$Weighted-Recall$和$Weighted-F-Score$来衡量多分类情况下的模型表现。
从上图结果可以看出 TextCNN 的结果有了很大提升,但依然难以满足实际需要。这是因为在小样本训练模型中,只用 top-1 的结果很难满足大部分情况。因为样本数量有限,分类结果准确度受限。
Top-k 结果优化
因为小样本训练的模型结果情况并不理想,考虑到每个开发周期真正存在Create Table 的情况并不多,我们期望尽可能满足所有的上游 schema 的改动,都能更新对应微服务的数据访问层代码。我们取模型结果的 Top-k 进行分析。k 取 1 到 3,只要 Top-k 的分类结果是正确的,就认为当前模型分类正确。
Top-3 的结果能够达到 90%,已经可以考虑用于实际任务新表,于是我们将新表创建的实现设计成如下模式:
预测属于的三个微服务分别更新 schema
生成对应数据访问层代码
至多提交三个 Pull Request,(分别属于三个微服务)
因为是 Pull Request,如果微服务的负责人 review 到当前 Pull Request 时,发现该表实际上不属于当前微服务,可以直接关闭,不会影响主分支的代码环境。
同时对于预测准确的微服务,在 Pull Request 里也会更新该微服务的配置文件信息。自动化地实现对数据库表和微服务的管理。引入模型对新建数据库表的预测后,能够有效的节约人员的沟通和学习成本,使本项目更接近于无人工干预的纯自动化方案。
最终运行的整体流程和自动生成提交的 Pull Request 情况如下图。

模型后续优化方案
引入其他的量来扩充数据集,比如提交 Pull Request 的人员名、每个表的字段名等,都加入模型分类的训练数据中,希望通过增加训练数据的量和提供额外的信息来增强模型的预测效果。
统计近半年开发上线周期内存在新表创建改动的微服务,对于近期有频繁新建表的服务增大预测的权重。对于现有表较少且稳定的微服务(几乎不再存在新表创建的情况),考虑降低权重或者不再进行该微服务的预测。
模型迭代与更新
使用的模型复杂度不高,且对机器要求不大,可本地进行训练,维护成本较低,易用、可维护。
结合之前对每个开发上线周期的新表数量统计情况,对于小样本的学习,更新模型过于频繁可能不利于模型表现效果。计划以三个开发上线周期作为一个模型迭代周期。每个模型迭代周期更新模型,增加这三个开发周期里新建的表来扩充训练集,随着训练集的逐步扩充,希望能够进一步提高模型准确率。
未来计划与展望
将深度学习模型引入后,观察 Top-k 的分类结果与实际可用情况,及时进行调整与维护。
这是我们首次在日常软件工程开发过程中引入机器学习的解决方案,期待在未来更多的工程项目中,探索并引入该思路。
将模型训练做成自动化 Pipeline,定期训练,更新使用的模型。
参考文献
4 Things You Need to Know about AI: Accuracy, Precision, Recall and F1 scores
Multi-Class Metrics Made Simple, Part I: Precision and Recall
Accuracy, Precision and Recall: Multi-class Performance Metrics for Supervised Learning
Convolutional Neural Networks for Sentence Classification
作者介绍:
许京爽,Freewheel 研发工程师,毕业于北京航空航天大学,曾在 InfoQ 发表《从 JavaScript 迁移到 TypeScript,类型声明文件自动生成与中心化管理的实践》。




