
人类藉由从各渠道感知及融合信息,来理解这个世界,具体方式包括:用双眼观察图像,用双耳聆听声音,以及其他的感知输入方式。人工智能的核心愿景之一,便是开发一种赋予计算机类似功能的算法,通过有效地从多模态数据(比如视觉语言)来学习,从而了解我们周围的世界。例如:视觉语言(即 VL)系统允许我们在相关的图像中搜索文本,并使用自然语言来描述图像的内容,反之亦然。
如图一所示,典型的视觉语言系统会借助由两个模块组成的模块化架构,来获得视觉语言方面的认知:
模块一:图像编码模块,也称为视觉特征提取器。具体实现:通过卷积神经网络(CNN)模型,生成输入图像的特征图谱。在此之前,最为常见的做法,是使用视觉基因数据集( Visual Genome, VG),来训练基于卷积神经网络的对象检测模型。
模块二:视觉语言融合模块。具体实现:将编码后的图像与文本映射到同一语义空间中的向量上,从而可以通过其向量的余弦距离,来计算它们的语义相似度。该模块通常使用基于 Transformer 的模型,比如说 OSCAR 来实现。
近来,通过大规模运用一一对应的图像与文本语料库,视觉语言预训练(VLP)在改善视觉语言融合模块方面取得了极大进展。最有代表性的方法,是以自监督的方式,使用海量的图像与文本配对数据,来训练基于 Transformer 的大型模型。比如:基于其上下文,预测相应遮蔽的元素。我们可以对预训练的视觉语言融合模型进行微调,以适应各式各样的下游视觉语言任务。不过,尽管在改善图像编码和物体检测方面的研究已经获得了巨大进步,但自从 2017 年经典的自下而上式局部特征推理机制出现以来,现有的视觉语言预训练方法都是将图像编码模块作为黑盒子来对待的,而不去涉及视觉特征的改善。
本文中,我们将会介绍近来微软在改善图像编码模块方面的进展。针对图像编码,微软的研究员开发了一种新的对象属性检测模型,这种模型也被称为 VinVL,翻译过来就是视觉语言中的视觉特征。我们在全面验证后确认,在视觉语言模型中,视觉特征的关系十分重大。微软的视觉语言系统将 VinVL 与最先进的视觉语言融合模块(如 OSCAR 及 VIVO)相结合,表现非常优秀,不仅在七个主要的视觉语言基准上都达到了最先进的技术水平,在最具竞争力的视觉语言榜单上——包括视觉问答(VQA),微软 COCO 图像字幕和 NOCAPS(新型对象字幕)竞赛中均名列前茅。最出彩的是,就常用语图像字幕生成(CIDEr)而言,微软的视觉语言系统在 NOCAPS 榜单上的表现远胜人类(分别获得 92.5 和 85.3 分)。
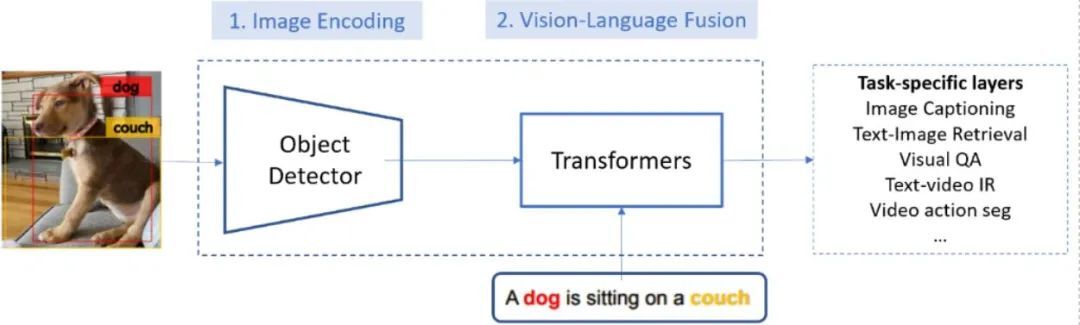
图一:用于视觉语言任务的最新模块化架构图,包括两个模块、图像编码模块以及视觉语言融合模块。通常来说,各个模块分别用视觉基因数据集(Visual Genome)和概念字幕数据集(Conceptual Captions)训练。
VinVL:通用的对象属性检测模型
与传统的计算机视觉任务(如对象检测)相反,视觉语言任务需要计算机对于各种各样的视觉概念有更广泛的理解,从而能够将其与文本中的相应概念相匹配。一方面来说,最常见的对象检测基准(如 COCO、Open Images 和 Objects365)包含的对象类注释多达 600 个,其主要关注的是形状明确的对象,比如汽车或人;但缺少无固定形状的可视对象,比如草丛和天空——而后者对于描述图像是非常有用的。受限和有所偏好的对象类使得这些对象检测数据集,在训练实际应用中非常有用的视觉语言理解模型时捉襟见肘。另一方面,尽管 VG 数据集对于更为多样化和不具偏好的对象及属性类有注释,也只是个包含了 11 万张图像的数据集,从统计学上来说,想要借以训练可靠的图像编码模型还是太小了。
针对视觉语言任务,为了训练对象属性检测模型,我们将四个大型的公共对象检测数据集,包括 COCO,Open Images,Objects365 和 VG 合并起来,构造了一个包含 2.49M 图像的大型对象检测数据集,其中有 1848 个对象类和 524 个属性类。鉴于大多数数据集并没有属性注释,我们采用了预训练和微调的策略,来构建我们的对象属性检测模型。起初,我们通过这个合并后的数据集,来预训练对象检测模型,然后在 VG 数据集的额外属性分支上对模型进行微调,使得它能够检测对象及属性。最终的对象属性检测模型是个具有 152 个卷积层和 133M 参数的 Faster-RCNN 模型,也是 VL 任务中最大的图像编码模型了。
我们的图像属性检测模型可以检测 1594 个对象类以及 524 个视觉属性。最终,根据我们的实验,针对输入图像上几乎所有语义上有意义的区域,该模型能够检测并进行相应编码。如图二所示,与传统的对象检测模型(左侧)相比,我们的模型(右侧)能够检测到图像中更多的视觉对象及属性,并以更为丰富的视觉特征进行编码,对于大部分的 VL 任务来说,这是至关重要的。

图二:通过 Open Images 数据集训练的传统对象检测模型(左侧),以及通过四个公共对象检测数据集训练的对象属性检测模型(右侧)。我们的模型包含了更丰富的语义,比如更丰富的视觉概念以及属性信息,同时所检测到的边界框几乎涵盖了所有具有语义的区域。
视觉语言任务方面的最新进展
由于图像编码模块是图像语言系统的基础,如图一所示,我们的新图像编码可以结合许多现有的 VL 融合模块一起使用,以提升 VL 任务上的表现。如表一所示,只将常见自下而上的模型所生成的视觉特征替换为我们的新模型所生成的那些,完整保留像 OSCAR 和 VIVO 这样的视觉语言融合模块,我们发现:现有已建立的七个 VL 任务上,新的结合体表现要明显优于之前的 SoTA 模型。
备注:我们仍然对 VL 融合模块执行训练,但使用了同样的模型架构、训练数据和训练方法。

表一:在将视觉特征从常见的自下而上特征换成我们的之后,七个 VL 任务上都有提升,NOCAPS 基准来自 VIVO,其他任务的基准来自 OSCAR。
考虑到参数效率,我们在表二中,针对不同大小的模型进行了对比。在大多数任务中,我们的基础模型都优于之前的大型模型,这表明使用更好的图像编码,VL 融合模块的参数效率更佳。

表二:Oscar+,使用我们的对象属性检测模型生成视觉特征,并在已建立的七个 VL 任务中获得了更好的表现。标记为 S、B、L 的 SoTA 模型,表示小型、基础型和大型模型(BERT 提供规模评测)分别可获得的最佳性能。本文中的所有表格,蓝色都表示任务的最佳结果,灰色背景表示 Oscar 所生成的结果。之前 SoTA 的结果是从 ERNIE-VIL 模型、神经状态机(NSM)、VIVO、VILLA 和 OSCAR 收集来的。
我们的新视觉语言模型包含两个模块,一是作为图像编码模型的新对象属性检测模型,二是作为视觉语言融合模块的 OSCAR,这个新模型截止 2020 年 12 月 31 日一直轻松居于多个 AI 基准的顶端,包括视觉问答(VQA)、微软的 COCO 图像字幕和 Nocaps。最出彩的是,就常用语图像字幕生成(CIDEr)而言,我们的 VL 系统在 Nocaps 榜单上的表现远胜人类(分别获得 92.5 和 85.3 分)。以 GQA 基准而言,我们的模型也是第一个能胜过 NSM 的 VL 模型,并包含一些专为特定任务设计的复杂推理组件。
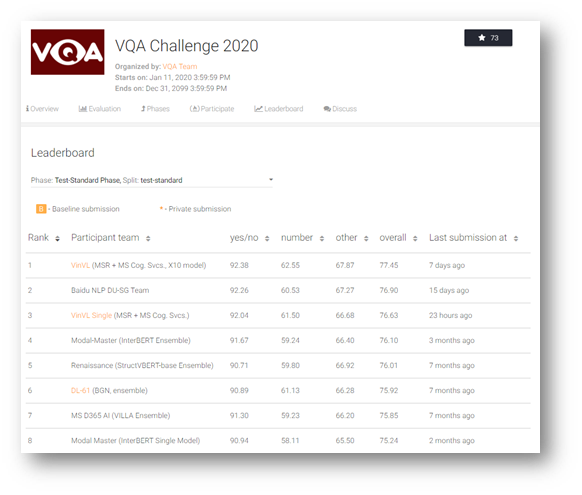
Visual Question Answering (VQA)
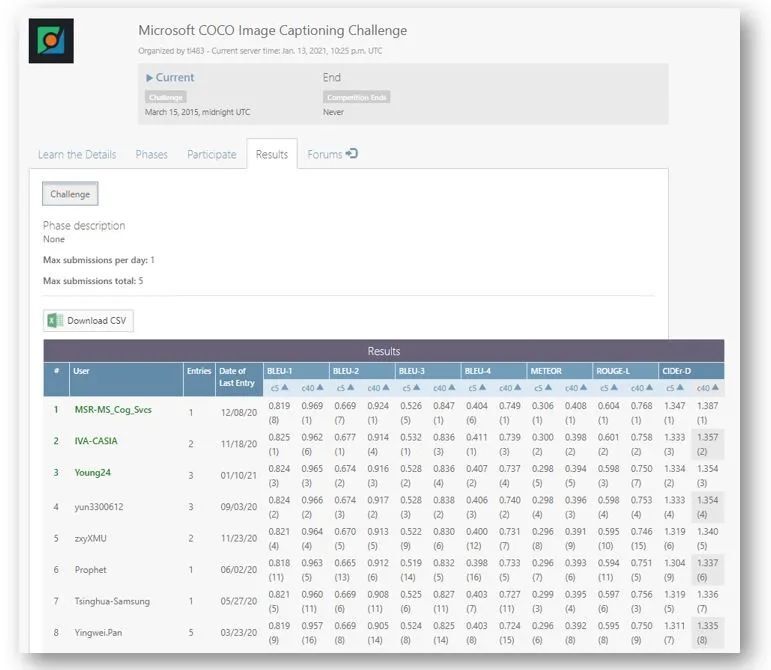
Microsoft COCO Image Captioning
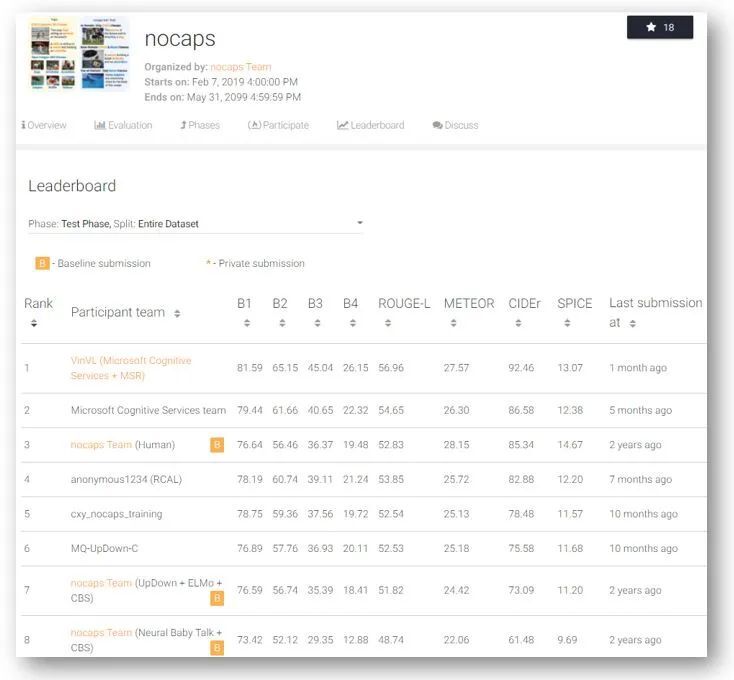
Novel Object Captioning (nocaps)
展望未来
VinVL 在改善图像编码以提升 VL 理解方面展现出了巨大的潜力。如本文中的图片所示,我们新开发的图像编码模型在诸多 VL 任务中表现优秀。不过,尽管结果很令人振奋,比如在图像字幕基准上胜过了人类的表现,但我们的模型还绝未达到人类的 VL 理解级别。未来有趣的开发方向包括:1)利用海量图像分类或加了标签的数据,进一步扩大对象 - 属性检测的预训练;2)扩展跨模型的视觉语言表征学习方法,从而建立基于感知的语言模型,令计算机可以像人类一样,通过自然语言表达视觉概念,也可以反过来通过视觉概念来形象化自然语言。
原文链接:




