

一、背景
我们为什么选择 Kubernetes?因为 Kubernetes 几乎支持所有的容器业务类型,包括无状态应用、有状态应用、任务型和 Daemonset,Kubernetes 也逐渐成为容器编排领域不争的事实标准。同时,从资源利用率,开发测试运维和 DevOps 三方面出发,会极大的提升人和机器的效率。
二、方案
整体架构
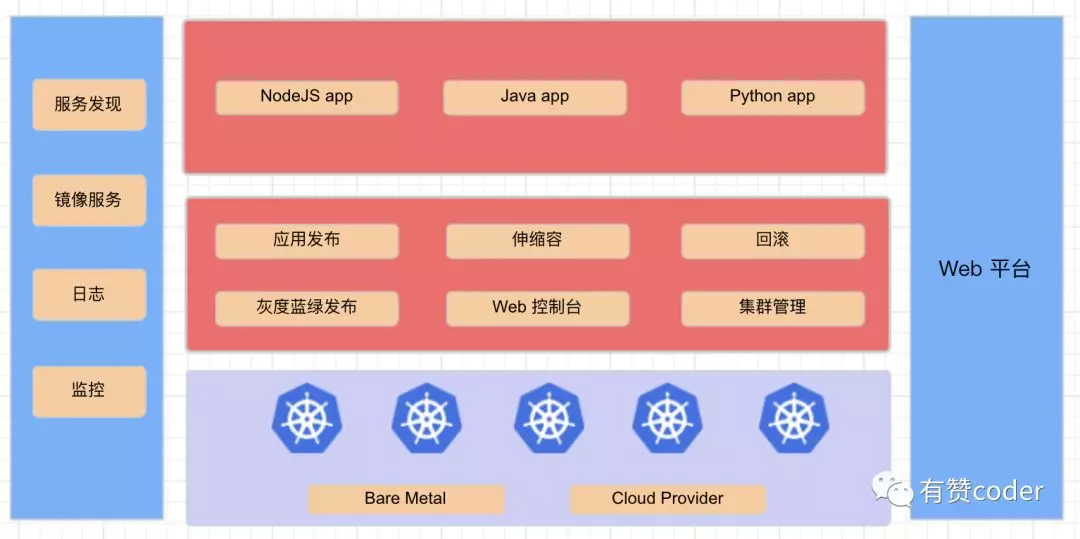
Kubernetes 在整个系统中处于偏底层,负责容器的编排。我们开发了一套 Web 的运维平台,能够完成开发者绝大部分的日常开发操作功能,其中包括了应用发布、伸缩容、回滚、灰度蓝绿发布、CI/CD 流水线、日志和监控的查看等。
集群部署
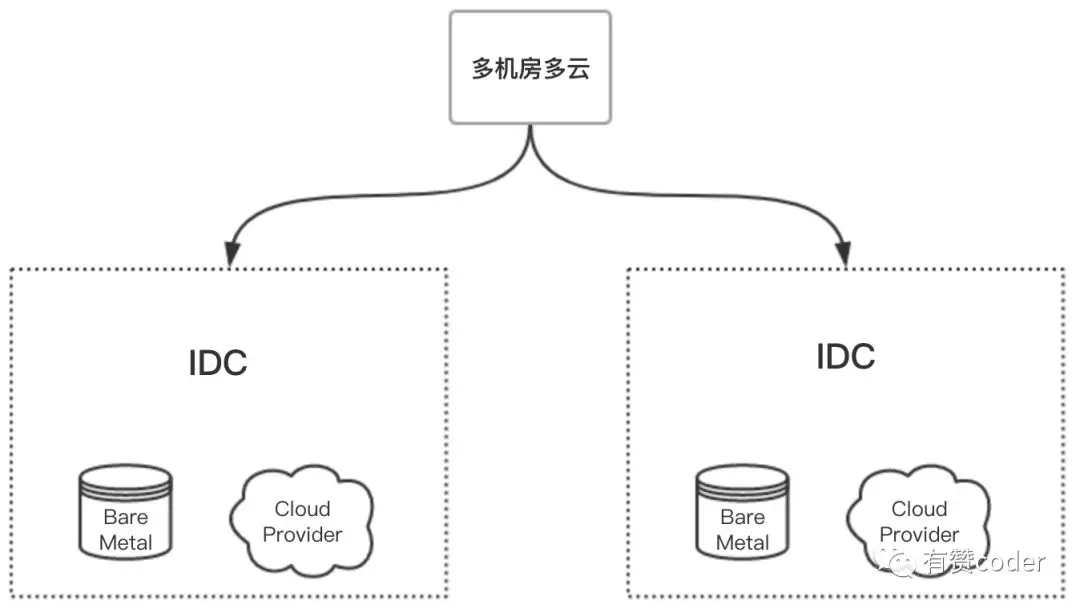
为了实现集群的高可用,平台提供多个 IDC 部署,应用可以同时部署到不同 IDC 的 Kubernetes 集群,同时我们在一个 IDC 同时部署了两个集群,应用可以部署到同机房的两个集群,这样可以解决跨机房调用问题,也可以防止 Kubernetes 集群过大导致的调度性能问题。同时在同一个 IDC 内,集群可以选择自建和云提供商的集群,在双十一这种情况下,可以利用云的弹性,快速扩容集群来满足资源的需求。在同个 IDC 部署多个集群的出发点是,我们没有使用 Kubernetes 的 Ingress,自研了 k8s-sync 组件会在发布时自动将容器的 IP 同步到我们的统一接入中,为了避免 k8s-sync 出错,如果在一个集群中 IP 同步不一致会快速失败,而不会影响其他的集群和现有的服务。
Master 高可用
Master 节点是 Kubernetes 中最重要的部分,生产中必须要保障它的高可用。
etcd 是 Kubernetes 当中唯一带状态的服务,集群中所有的数据都保存在 etcd 中。Kubernetes 选用 etcd 作为它的后端数据存储仓库正是看重了其使用分布式架构,没有单点故障的特性。一是使用独立的 etcd 集群,使用 3 台或者 5 台服务器只运行 etcd,独立维护和升级。甚至可以使用 CoreOS 的 update-engine 和 locksmith,让服务器完全自主地完成升级。这个 etcd 集群将作为基石用于构建整个集群。 采用这项策略的主要动机是 etcd 集群的节点增减都需要显式的通知集群,保证 etcd 集群节点稳定可以更方便地用程序完成集群滚动升级,减轻维护负担
kube-apiserver 高可用
apiserver 本身是一个无状态服务,要实现其高可用相对要容易一些,前端部署了负载均衡,其他组件都通过这个负载均衡去访问 apiserver。
kube-controller-manager 与 kube-scheduler 高可用
这两项服务是 Master 节点的一部分,他们的高可用相对容易,仅需要运行多份实例即可。这些实例会通过向 apiserver 中的 Endpoint 加锁的方式来进行 leader election, 当目前拿到 leader 的实例无法正常工作时,别的实例会拿到锁,变为新的 leader。
日志
针对日志采集,在有赞主要分为两类,对于输出到 stdout 和 stderr 的日志,会使用 filebeat 进行采集,写入到 kafaka 中做后续的存储和处理。对于 Java 类应用,在虚拟机时代,就已经自研了一套日志处理方案,在容器中我们沿袭了这套方案,通过 agent 采集走。
集群监控
对于集群的监控主要分为两种,对于节点的监控,还是沿袭了虚拟机时代的方案,继续使用 open-falcon;使用 Kubernetes 后,我们使用了 cadvisor 和 kube-state-metrics,用于采集容器和 Kubernetes 中一些资源对象的数据;同时,对于 Kubernetes 中的组件,kubelet、kube-apiserver、kube-controller-manager 和 kube-scheduler,各自都暴露了 metrics 接口,吐出了自身的运行时的监控数据。这些数据都被集群的 prometheus 全部拉取,然后
展示在 Grafana 和运维平台上。
应用监控
在运维平台中,对于应用开发者来说最关心的是应用层面的监控数据。目前,我们结合 cadvisor 和 kube-state-metrics 提供了 CPU、内存、磁盘 IO、网络 IO 这四个监控项。同时,我们针对容器重启,销毁,拉取镜像失败,孤儿 Pod 等事件做了监控和报警。
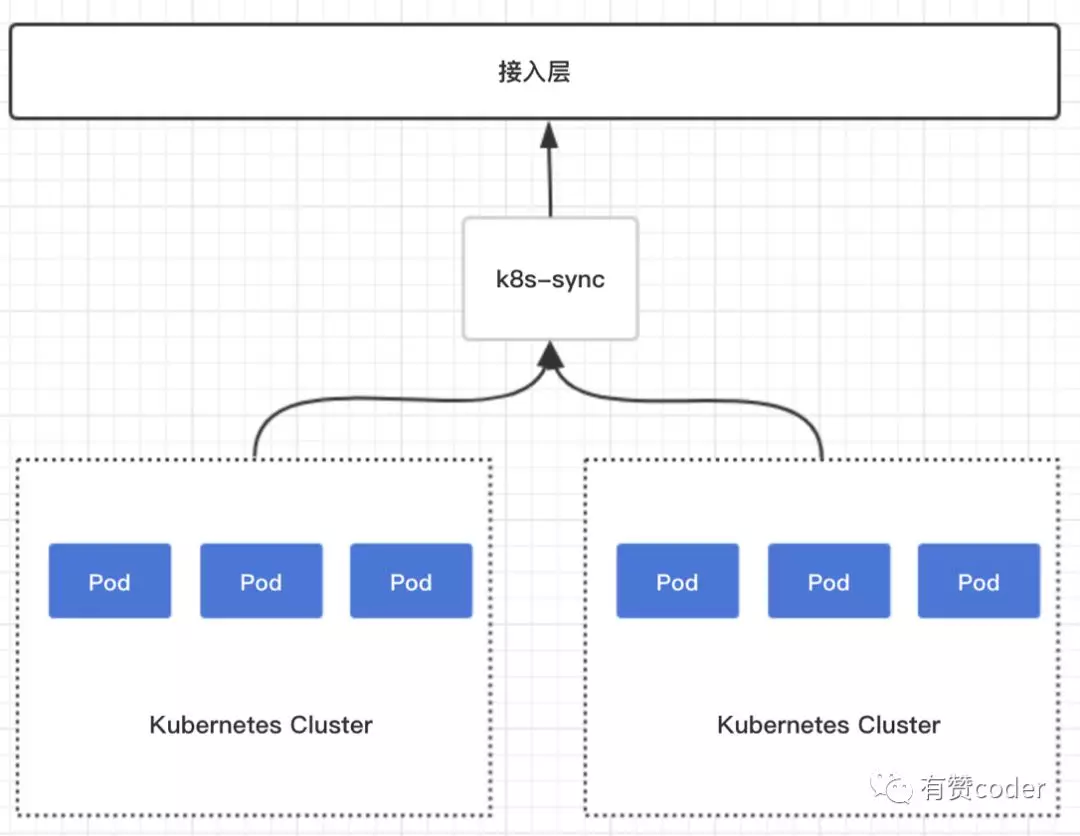
服务暴露
Kubernetes 中服务的暴露是一个比较重要的问题,同时也有很多开源的方案。刚开始,我们调研了 traefik ,但是很多地方满足不了我们的需求,所以沿用了内部的接入层 yz7,为了适配 Kubernetes,自研了 k8s-syc。k8s-sync 会 watch 集群中的 endpoints,然后将 IP 同步到 yz7 中。对于 RPC 服务,由于我们内部采用了 macvlan ,这种调用和虚拟机时代保持了一致。
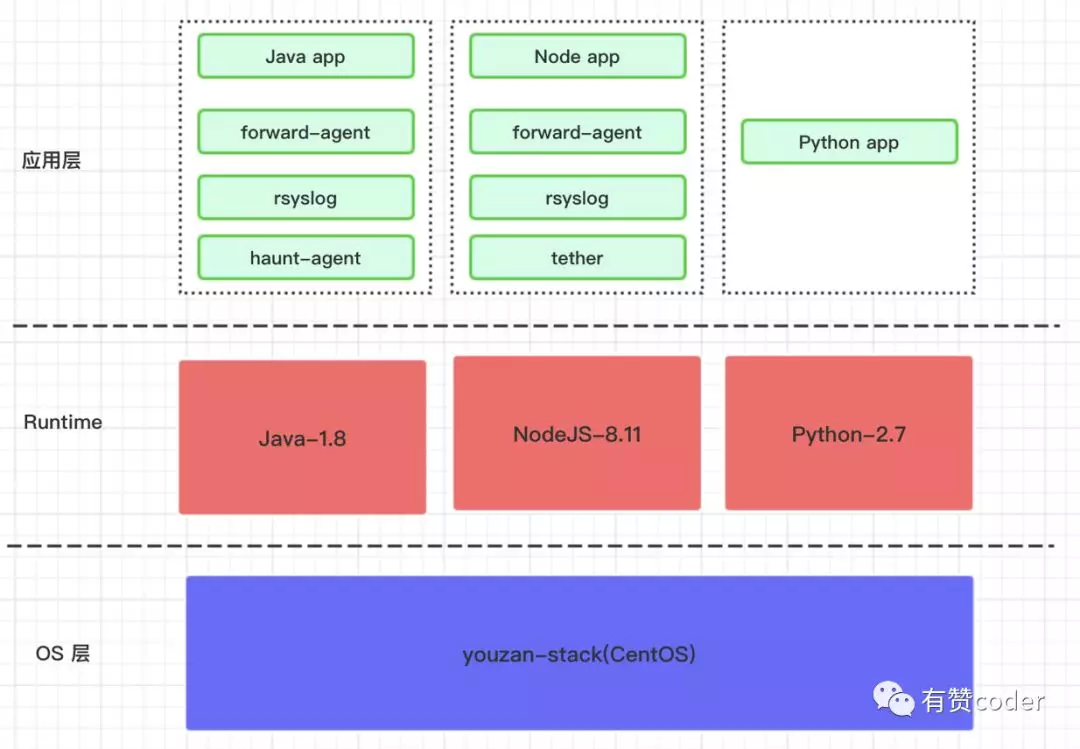
镜像
镜像的构建主要分 3 层,OS 层、Runtime 层和业务应用层。有赞内部每种应用类型会有严格的端口规范,每种应用类型接入容器发布时要符合端口规范。对于 Python 和 NodeJS 应用接入容器发布时比较简单,只需要在应用 repo 的根路径下添加 app.yaml 文件,这个文件定义了应用的镜像的构成,包括 OS、runtime 和 entrypoint。例如,下面是一个 Python 应用的 app.yaml 示例文件。
标签
为了便于运维管理和亲和性的需求,我们给 Pod 打上了很多标签,例如:应用名称、集群名称、环境、机房、灰度蓝绿等。目前,我们还没有使用亲和性来实现更复杂的高可用,后续会基于这些标签来规划应用的亲和性和反亲和性。
Lifecycle Hooks
我们使用了 Kubernetes 的 poststart 和 prestop 的钩子。
容器启动时,会调用定义的 preload 和 online 脚本,该脚本会对应用程序进行健康检查,健康检查通过后再执行 online 脚本对应用进行上线动作。
容器销毁时,会调用 offline 和 stop 脚本,和启动时相反,容器销毁时会先进行下线动作然后再执行 stop 脚本。
持续交付
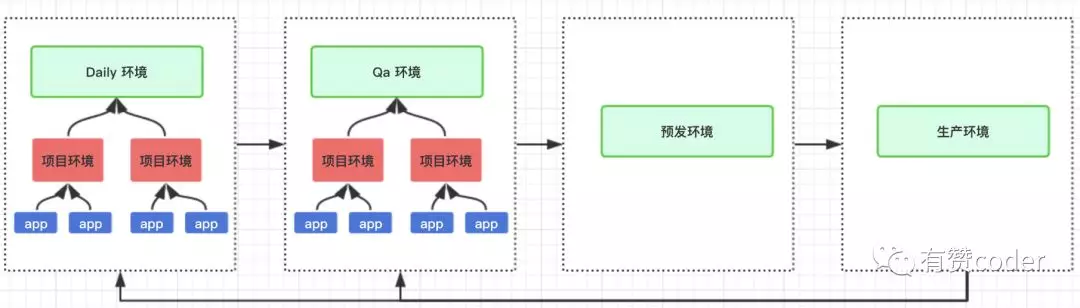
在有赞,CI/CD 的实现是通过项目环境来实现的。每个标准环境的部署,是部署在不同的 Kubernetes 集群中的,每个集群中通过不同的 namespace 来区分各自的环境。
多集群管理
目前我们的生产环境的集群包括了自建集群和公有云集群,其他环境也有很多套集群。为了便于进行集群管理,我们自研了集群管理平台。集群管理员可以在平台上对进行操作,包括创建集群、添加节点、维护节点、给节点打标签和查询集群及节点的水位状态。
遇到的问题
在容器化的过程中,还是碰到了不少的问题,主要有下面这些和大家分享下:
1.CPU 核数不准
我们使用了 lxcfs 进行了一些隔离,但是对于 Java 程序来说获取到的 CPU 核数还是不准的,前期我们使用了 hack 的方案,后续升级了 jdk 避免了这个问题。
2.有问题时的排查
针对发布时,应用程序发布起来出现 CrashLoopbackoff 的情况时,我们提供了调试模式发布,这时,会移除 Pod 的健康检查和 lifecycle hook,保证可以发布起来。针对线上运行时出现了问题,我们提供了隔离的功能,给 Pod 打上特殊的标签让其脱离 Deployment 的控制,同时会执行程序的下线流程,保证不再有流量进来,这样就保留了有问题时的现场,供开发人员进行现场问题排查。
3.Pod 中 Container 的依赖
通常,在 Pod 里除了业务容器还有其他的 sidecar 容器,在我们这里特殊的是,业务容器还依赖了 sidecar 容器,但是 Pod 的启动实际是无序的,所以我们目前使用了富容器,辅助程序和业务程序放在了一起,启动时控制了它们的启动次序。目前,社区里也有相应的讨论,已经在实现中。
三、未来展望
未来,我们期望能开始使用 operator 来优化和改进 Kubernetes 的使用,并使用它去优化一些应用程序的交付;希望可以开始使用 HPA 和 VPA,来实现自动化的伸缩容;实现更精细化的调度,提供集群的利用率。
本文转载自公众号有赞 coder(ID:youzan_coder)。
原文链接:

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...












评论 1 条评论