

Longhorn 是 Kubernetes 的云原生分布式块存储,易于部署和升级,100%开源且持久,由业界采用最为广泛的 Kubernetes 管理平台创建者 Rancher Labs 推出,并于去年10月捐献给CNCF。Longhorn 的内置增量快照和备份功能可确保 volume 数据的安全,而其直观的 UI 可以方便地管理持久卷的计划备份。使用 Longhorn,你可以获得最细的管理粒度和最大的控制程度,并且可以轻松地在另一个 Kubernetes 中创建一个灾备恢复的 volume,并在发生紧急情况时进行故障转移。
云原生基础设施堆栈:计算、部署、管理、存储和数据库
YugabyteDB 是一个云原生分布式 SQL 数据库,它可以运行在 Kubernetes 环境中,所以它可以与 Longhorn 和许多其他 CNCF 项目互操作。YugabyteDB 是一个开源的高性能分布式 SQL 数据库,该数据库基于 Google Spanner 的可扩展性和容错设计而构建。Yugabyte 的 SQL API(YSQL)与 PostgreSQL 兼容。
如果你正在寻找一种方法来轻松地在 100%的云原生基础架构之上开始应用程序开发,那么这篇文章正是为你准备的。我们将一步一步告诉你如何部署一个完整的云原生基础架构堆栈,该堆栈由 Google Kubernetes Engine、Rancher 企业级 Kubernetes 管理平台、Longhorn 分布式块存储以及 YugabyteDB 分布式 SQL 数据库组成。
为什么要使用 Longhorn 和 YugabyteDB?
YugabyteDB 作为 StatefulSet 部署在 Kubernetes 上,并且需要持久存储。Longhorn 可用于备份 YugabyteDB 本地磁盘,从而允许配置大规模持久卷。将 Longhorn 和 YugabyteDB 结合使用,有以下好处:
不必管理本地磁盘——它们由 Longhorn 进行管理
Longhorn 和 YugabyteDB 可以配置大规模的持久卷
Longhorn 和 YugabyteDB 都支持多云部署,可以帮助企业避免云厂商锁定
此外,Longhorn 可以在一个地理区域内进行同步复制。如果 YugabyteDB 跨区域进行部署并且其中任意一个区域中的节点发生故障,那么 YugabyteDB 只能使用来自另一区域的数据重建该节点,这会产生跨区域流量。而这会导致成本更改,并且会降低所恢复的性能。而将 Longhorn 与 YugabyteDB 结合使用,你可以无缝地重建该节点,因为 Longhorn 会在该区域内进行本地复制。这意味着 YugabyteDB 最终不必从另一个区域复制数据,进而降低了成本并提升了性能。在此部署设置中,如果整个区域发生故障,YugabyteDB 仅需执行一个跨区域节点重建。
前期准备
我们将在已经使用了 Longhorn 的 Google Kubernetes 集群上运行 YugabyteDB 集群:
YugabyteDB(使用 Helm Chart)-版本 2.1.2
Rancher(使用 Docker Run)-版本 2.4
Longhorn(使用 Rancher UI)-版本 0.8.0
一个 Google Cloud Platform 账号
在谷歌云平台上设置一个 K8S 集群和 Rancher
Rancher 是一个开源的企业级 Kubernetes 管理平台。它使得 Run Kubernetes Everywhere 更为轻松和简单,满足 IT 人员的需求并增强 DevOps 团队的能力。
Rancher 需要 64 位的 Ubuntu16.04 或 18.04 和至少 4GB 内存的 Linux 主机。在此示例中,我们将使用安装在 GCP VM 实例上的 Rancher UI 设置 Google Kubernetes Engine(GKE)集群。
使用 Rancher 在 GCP 上设置 Kubernetes 集群所需的步骤包括:
在 GCP 中创建一个具有所需 IAM 角色的 Service Account
创建一个运行 Ubuntu 18.04 的 VM 实例
在 VM 实例上安装 Rancher
生成一个 Service Account 密钥
通过 Rancher UI 设置 GKE 集群
创建一个 Service Account 和 VM 实例
首先,我们需要创建一个附加到 GCP 项目的 Service Account。要完成此操作,访问路径是:【IAM & admin > Service accounts】
选择【Create New Service Account】,给其命名并点击【Create】。
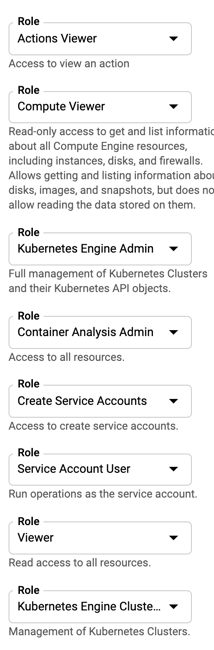
接下来,我们需要添加所需的角色到 Service Account 以便能够使用 Rancher 设置 Kubernetes 集群。添加下面显示的角色并创建 Service Account。
角色添加完成之后,点击【Continue and Done】。
现在我们需要创建一个 Ubuntu VM 实例,它将会被托管在 GCP 上。执行路径为:【Compute Engine > VM Instances > Create New Instance】
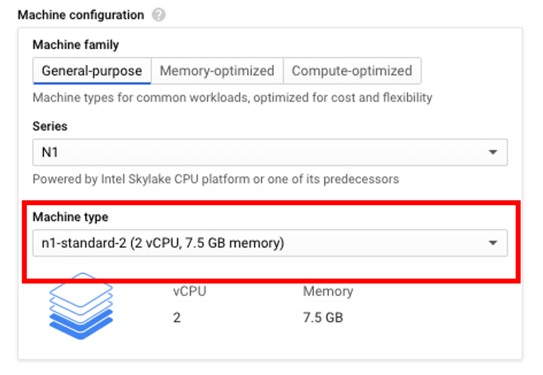
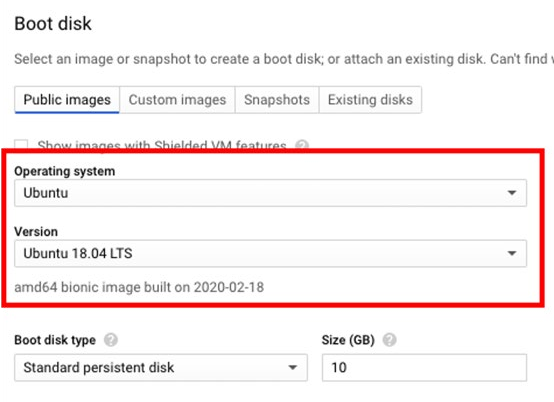
出于本次 demo 的目的,我选择了 n1-standard-2 机器类型。选择 Ubuntu 镜像,需要点击【Boot Disk > Change】并且在操作系统的选项中选择 Ubuntu,版本选择 Ubuntu 18.04 LTS。
需要检查一下是否允许 HTTPS 流量,检查路径为【Firewall > Allow HTTPS traffic】

使用以上设置创建 VM 实例仅需几分钟。创建完成后,使用 SSH 连接到 VM。在将 terminal 连接到 VM 的情况下,下一步是通过执行以下命令来安装 Rancher:
注意:如果没有找到 Docker,请按照以下说明在 Ubuntu VM 上安装它:
https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-18-04
创建 GKE 集群
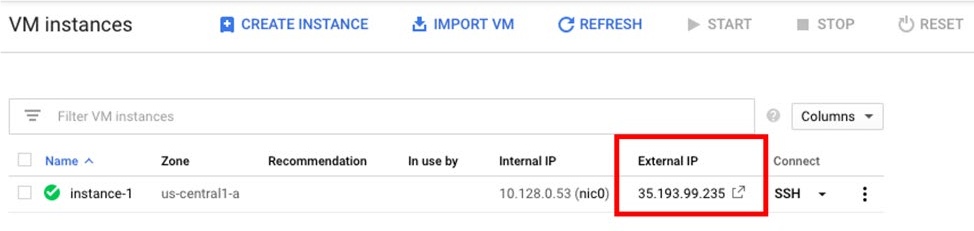
要访问 Rancher server UI 并创建登录名,请打开浏览器并转到安装它的 IP 地址。
例如:https://<external-ip>/login
注意:如果你在尝试访问 Rancher UI 时遇到任何问题,请尝试使用 Chrome Incognito 模式加载页面或禁用浏览器缓存。
按照提示创建一个新帐户。
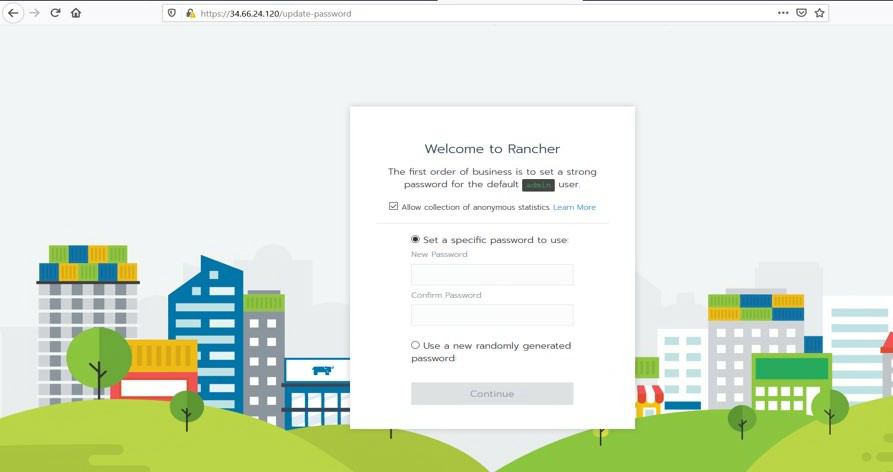
创建帐户后,请转到 https://<external-ip>/g/clusters。然后单击【Add Cluster】以创建 GKE 集群。
选择 GKE 并给集群命名。
现在我们需要从之前创建的 GCP Service Account 中添加私钥。可以在【IAM & admin > Service Accounts > Create Key】下找到。
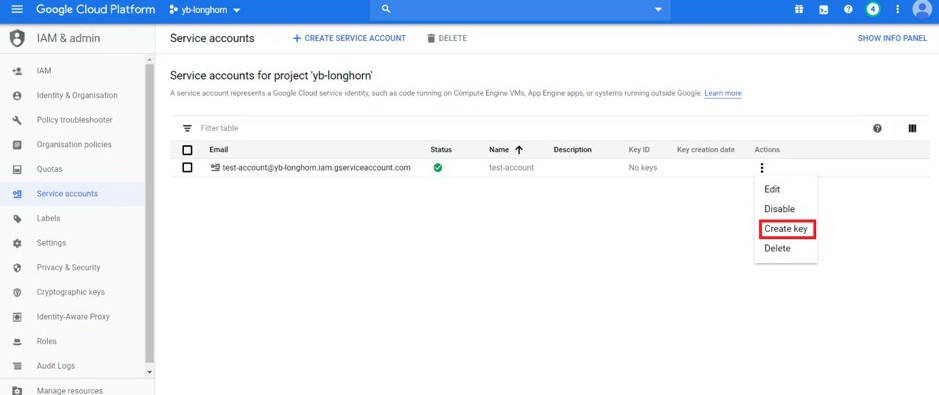
这将生成一个包含私钥详细信息的 JSON 文件。
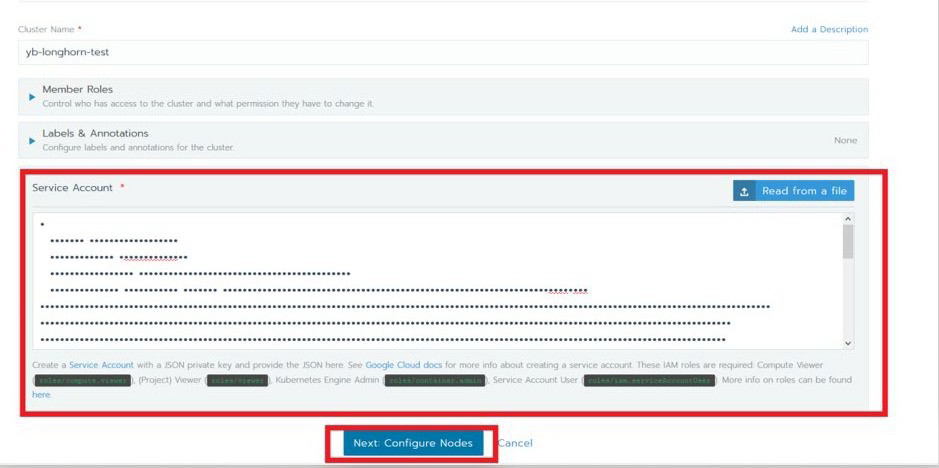
复制 JSON 文件的内容到 Rancher UI 中的 Service Account 部分并单击【Next】。
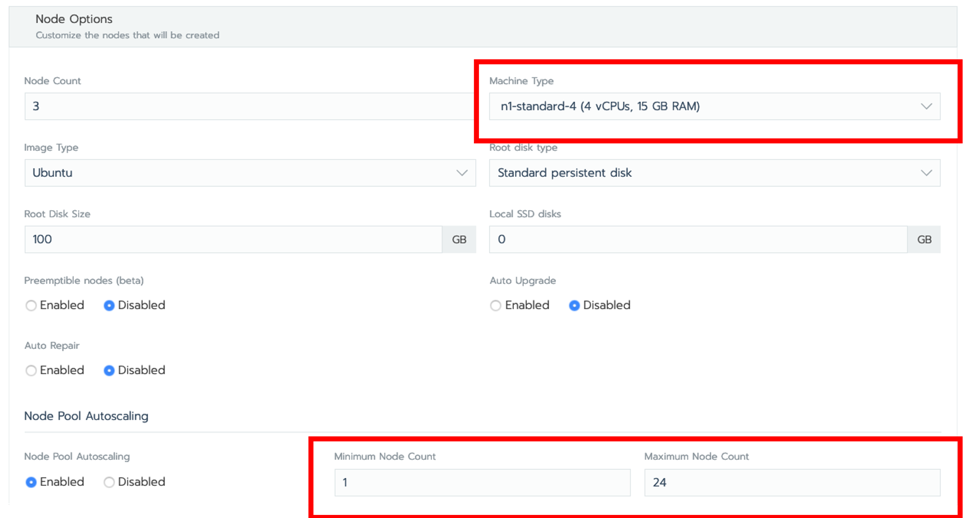
考虑到本教程的目的,我选择了 n1-standard-4 机器类型,打开了【Node Pool Autoscaling】,并将最大节点数设置为 24。单击【Create】。
通过确保将集群的状态设置为 Active 来验证是否已创建集群。请耐心等待,这将需要几分钟的时间。
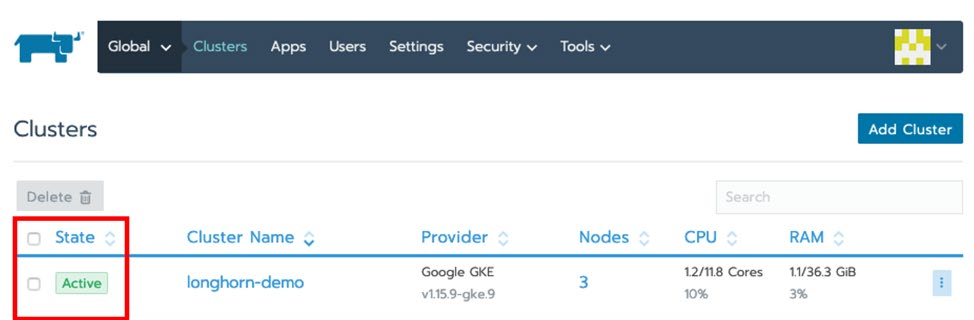
还可以通过转到【Kubernetes Engine>Clusters】从 GCP 项目访问该集群。
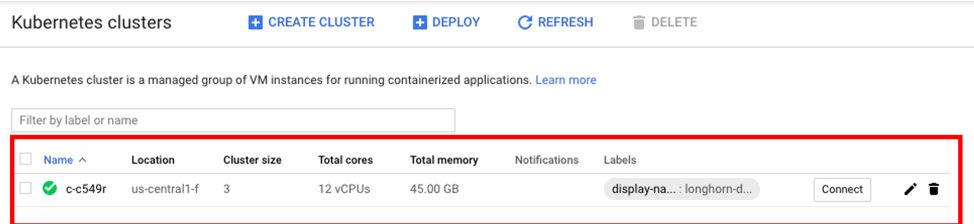
在 GKE 上安装 Longhorn
Rancher 安装完成后,我们可以使用其 UI 来在 GKE 集群上安装和设置 Longhorn。
单击该集群,在本例中为 longhorn-demo,然后选择【System】。
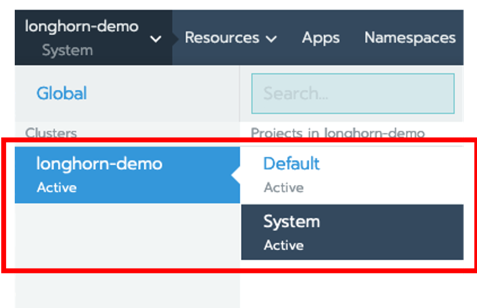
接下来点击【Apps>Launch】,搜索 Longhorn,并点击该卡片。
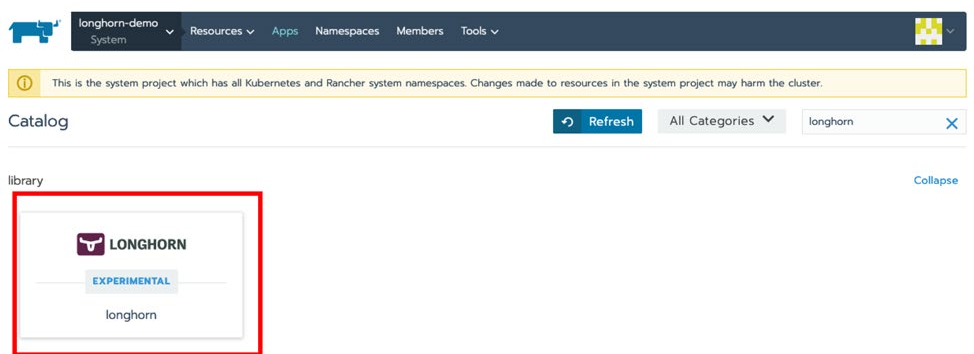
给 deployment 命名,也可以使用默认名称,然后点击【Launch】。安装完成后,你可以通过点击/index.html 链接来访问 Longhorn UI。

验证是否已安装 Longhorn,并且 GKE 群集节点是否可见。
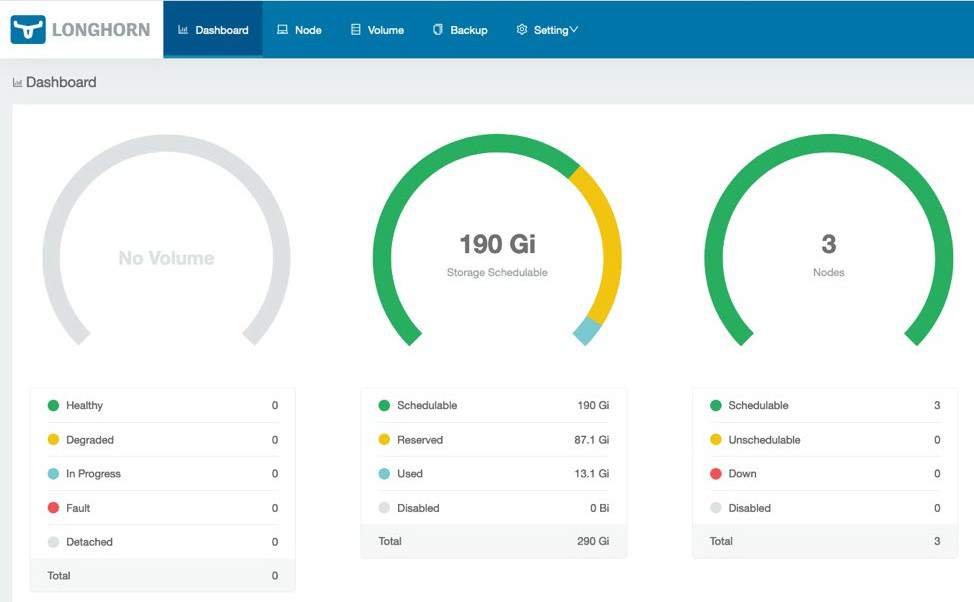
使用 Helm 在 GKE 集群上安装 YugabyteDB
下一步是在 GKE 集群上安装 YugabyteDB。可以通过执行以下链接中的步骤来完成:
https://docs.yugabyte.com/latest/deploy/kubernetes/helm-chart/
以下将概述这些步骤:
验证并升级 Helm
首先,通过使用 Helm 版本命令来检查 Helm 是否已经安装:
如果你遇到与 Tiller 相关的问题,例如上述错误,则可以使用升级选项初始化 Helm:
根据以下文档,你应该能够使用 Helm chart 来安装 YugabyteDB:
https://docs.yugabyte.com/latest/deploy/kubernetes/single-zone/oss/helm-chart/
创建一个 Service account
在创建集群之前,你需要有一个 service account,它应该被授予集群管理员的角色。使用以下命令创建一个 yugabyte-helm service account,并授予 cluster-admin 的集群角色。
初始化 Helm
创建一个命名空间
添加 chart 镜像仓库
从镜像仓库中获取更新
安装 YugabyteDB
我们将使用 Helm chart 来安装 YugabyteDB 并且将使用 Load Balancer 公开 UI 端点和 YSQL、Yugabyte SQL API。此外,我们将在资源不足的环境中使用 Helm 资源选项,并指定 Longhorn 存储类。这将需要一段时间,需要耐心等待。你可以在文档中找到关于 Helm 的详细说明:
https://docs.yugabyte.com/latest/deploy/kubernetes/gke/helm-chart/
执行以下命令以检查 YugabyteDB 集群的状态:
你还可以通过访问 GKE 的“Services & Ingress and Workloads”页面来验证是否已安装所有组件并进行通信。
你也可以通过访问端口 7000 上 yb-master-ui 服务的端点来查看管理 UI 中的 YugabyteDB 安装。
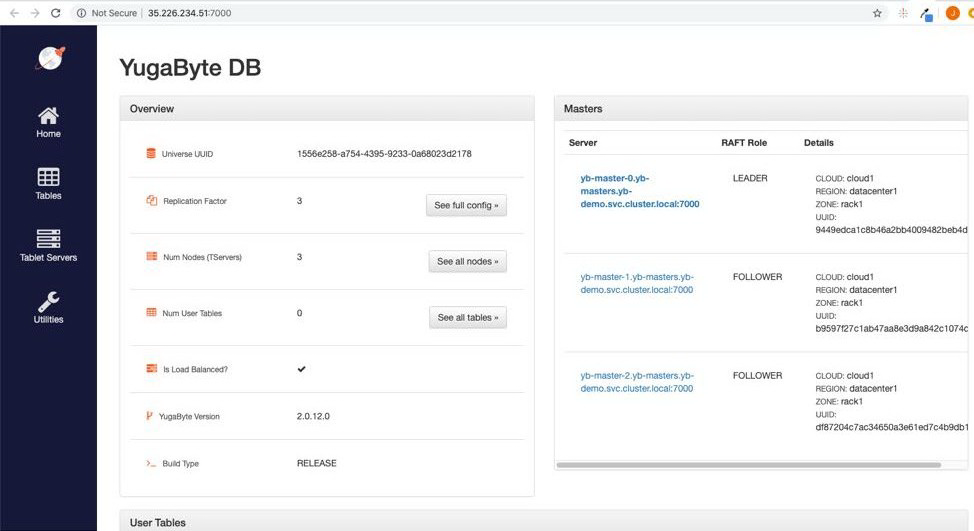
你还可以通过执行以下命令登录到 PostgreSQL 兼容的 shell:
现在,你可以开始创建数据库对象和处理数据了。
使用 Longhorn 管理 YugabyteDB volume
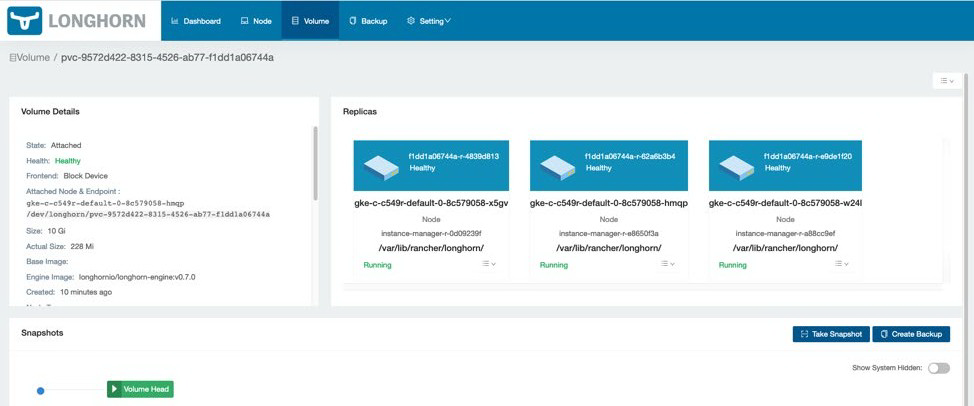
接下来,重新加载 Longhorn dashboard,以验证 YugabyteDB volume 已正确设置。Volume 的数量现在应该处于可见状态:
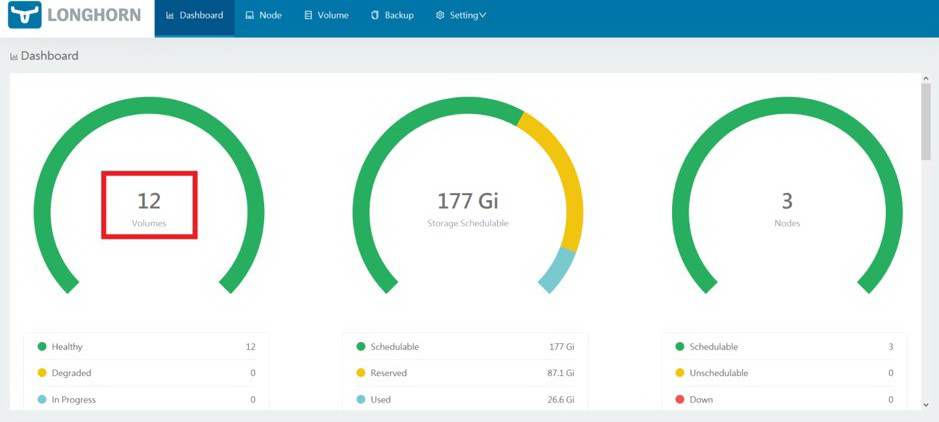
单击【volume】以管理 volume。各个 volume 应该可见。
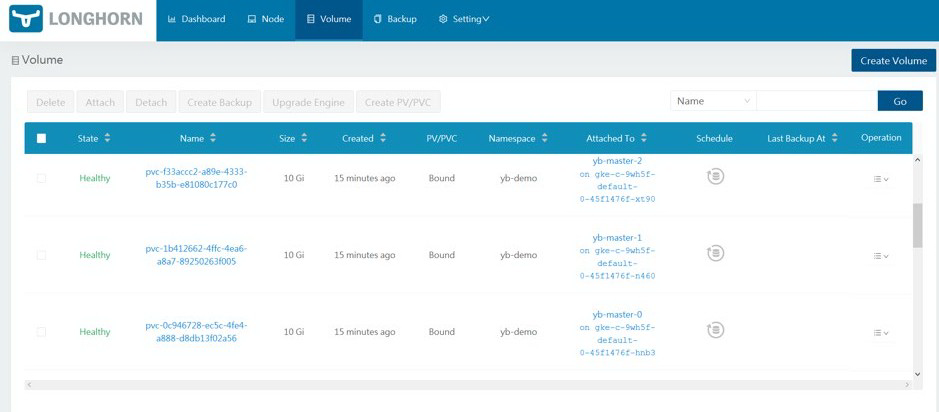
现在可以通过选择它们以及所需的操作来管理 volume。
就是它!现在,你已经可以在有 Longhorn 作为分布式块存储的 GKE 上运行 YugabyteDB 了!
原文链接:
作者简介
Jimmy Guerrero,在开发者关系团队和开源社区拥有 20 多年的经验。他目前领导 YugabyteDB 的社区和市场团队。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论