

1. 导读
还原真实世界是每个地图技术人的追求,愿意为此付出不懈努力。随着地图静态路网的完善,道路上动态发生的事件,对用户出行的影响逐渐突显出来,尤其是道路上发生的封闭事件。
为了挖掘道路上的封闭事件,高德技术团队设计了一套半监督的深度学习方案。下面通过业务背景、解决方案、建模方法以及业务落地四个方面展开说明。
2. 业务背景
动态事件是道路通行能力的变化进而影响用户出行的事件。通过动态事件的描述,可以了解动态事件包含两个要素,第一个是通行能力的变化,第二个是影响用户出行。
动态事件基本类型是封闭、施工、事故,如图 1 所示。其中封闭是道路通行能力极弱,正常车辆不能通行,特殊车辆才可能通行;封闭影响用户出行,需要用户掉头并绕路才能到达目的地,严重影响用户的出行。
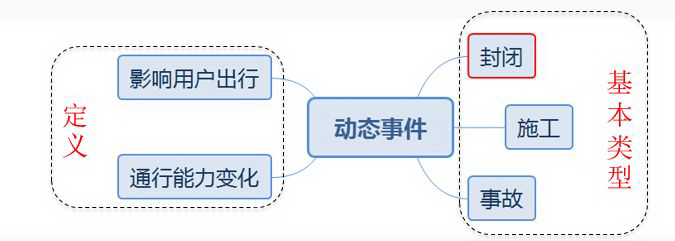
图 1 动态事件定义及基本类型
为了对动态事件有形象的理解,图 2 展示了动态事件的常见情况。第一张图展示了天气类的封路,雨雪雾等均可能引起道路封闭。第二张图展示了管制类封路,如道路要进行马拉松比赛,所以管制性封路。第三张图像展示了施工类封路,第四张图展示了施工但未封闭的情况。

图 2 动态事件示例
高德有多种发现封路事件的方法,本文主要介绍基于用户轨迹数据的动态事件挖掘算法。
图 3 中第一张图片展示了道路封闭发生后,流量从 100 左右跌到了 0;第二张图片展示了车辆的轨迹不能正常通过某一段道路,需要掉头并绕路通过;第三张展示了一条道路不能通行,道路上没有车辆的 GPS 点。热力用来描述 GPS 点的密度,GPS 点密度越高,热力越明显,颜色越深。
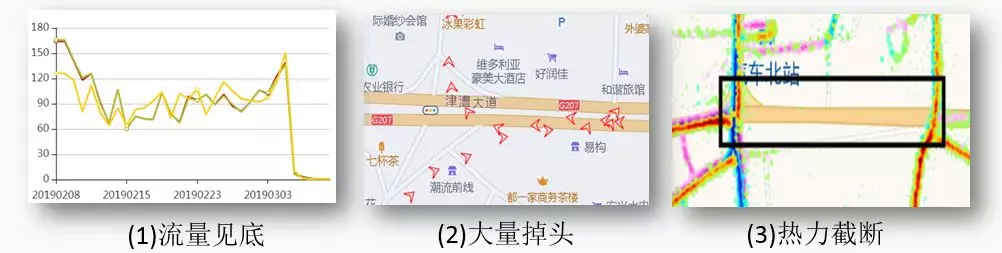
图 3 封闭事件的大数据线索
封路问题主要拆分为新增和消散两部分工作来展开的。新增和消散对应封闭事件的上线和下线。封闭问题之所以分为新增和消散,主要原因是新增和消散在业务分布上有着很大的差异。
新增问题是面向全路网的数据,封闭事件是小概率事件,发现封闭事件前会进行导航规划。消散面向的是线上事件,绝大部分为封闭事件,不进行导航规划。本文主要介绍封路新增问题。下面开始介绍封路挖掘的解决方案。
3. 解决方案
高德在处理动态事件时,基本逻辑是利用已知数据,找出疑似封闭事件,之后再进行提纯,产出封闭事件并进行上线。按照此逻辑,产线处理过程分为三个层次:
数据层
发现层
验证层
大数据的解决方案也是基于此三层架构来设计的。经过系统化设计最终确定了分层化、半监督的深度学习方案,该方案可用于离线挖掘,也可以用于实时挖掘。整体方案如图 4 所示:
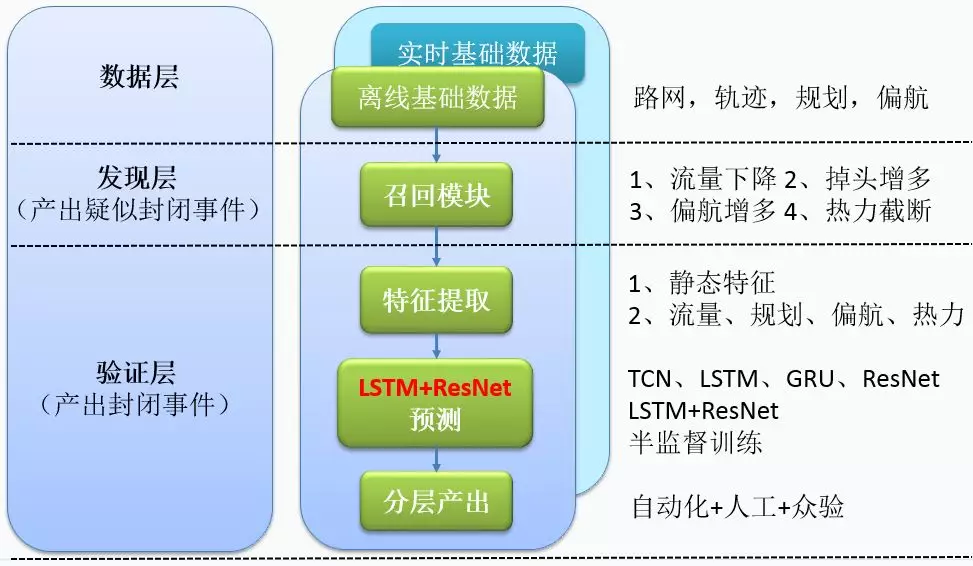
图 4 整体解决方案
本方案主要包括如下 5 个部分:
基础数据:基础数据主要用到了静态数据及动态数据,静态数据主要包括路网及其属性,动态数据主要是用户的轨迹、规划、偏航等;
召回模块:为了发现疑似封闭事件,设计了召回模块。召回模块在搜索、广告等任务中均会使用。流量下降、掉头增多、偏航增多、热力截断是典型的召回策略;
特征提取:业务建模过程中会将流量、规划、偏航、热力的数据在拓扑结构及时序上进行建模,产出相应的特征;
LSTM+ResNet 预测:模型部分围绕时序模型及卷积模型进行了探索,如 TCN、LSTM、GRU 等。最终设计了 LSTMResNet 组合模型用于线上业务;
分层产出:模型置信度越高,封闭准确率越高。不同的置信度可以分层化产出,高置信的产出自动化上线的同时,中低置信度的产出人工协助上线,低置信度的产出能够赋能产线,大数据协同其他事件源一起挖掘封闭事件。
4. 建模方法
4.1 路网建模
路网是一张有向图,每一条边,也就是路网中的一条路,被称为一条 link。路网建模分为空间建模、业务数据建模、时序建模三个步骤,如图 5 所示。将路网三步建模展开描述,分别是:
空间建模:路网按拓扑结构拆分,分为上游 links、当前 link、下游 links;
业务数据在道路空间上的建模:基于拆分后的拓扑结构,对当前 link 及上下游 links 在规划、流量、偏航、热力几方面进行建模,形成一个 39 维的特征向量;
时序建模:我们的业务是典型的时序问题。以流量下降为例说明,道路封闭前,流量在 100 左右波动;道路封闭过程中,流量是逐渐下降的过程;道路封闭后,流量在 0 附近波动,基本无车辆通行。道路从非封闭到封闭的过程,是流量在时序上逐渐下降到 0 附近的过程。我们选取了四周的时间序列,每一天的数据是上一步提取的对应日期的 39 维特征向量。
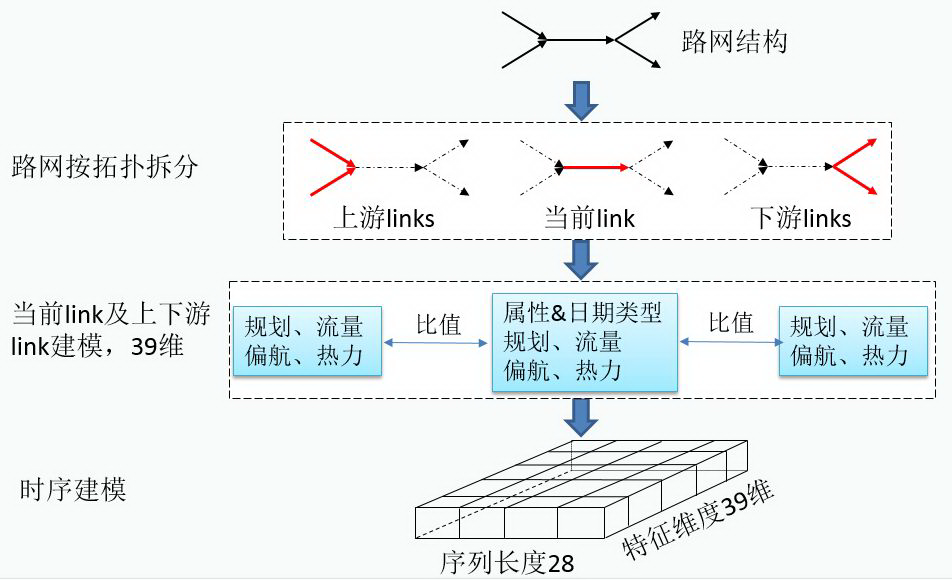
图 5 路网建模方法
4.2 算法建模
从时序建模开始,到最终选定时序和卷积的组合模型,LSTMResNet 模型,我们经历了一系列的探索:
鉴于我们的业务是典型的时序问题,所以从经典的时序模型 LSTM、GRU 进行实验;
有了经典的模型,就希望在“state of the art”的时序模型上实验,所以调研了 TCN 并进行实验。最终 TCN 实验表现优于 LSTM、GRU;
本着“他山之石可以攻玉”的想法,我们也实验了 CNN 经典模型 ResNet,ResNet 表现虽不如 TCN,但与 GRU 相当,优于 LSTM。重要的是 TCN 表现优秀的原因之一就是内部运用了 ResNet Block;
鉴于 ResNet 表现优秀,所以有了时序+ResNet 的想法。于是我们试验了 LSTM+ResNet 的模型,称为 LSTMResNet 模型。
快、准、稳是我们选取模型的主要考虑因素。“快”指的是挖掘周期短,LSTM 比 TCN 需要的序列更短;“准”指的是挖掘的准确率高,LSTMResNet 模型的准确率最高;“稳”指的是模型潜在的恶劣 badcase 更少,越是经典常用的模型,一般认为模型潜在问题更少。
基于快、准、稳的考虑,我们选取了 LSTMResNet,并进行后续的业务迭代、落地。
LSTMResNet 网络结构如图 6 所示,输入特征向量经过 LSTM 网络层,LSTM 的输出作为 ResNet 的输入,ResNet 的输出连接全连接层,最后全连接层与只有两个节点的网络层连接,这两个节点就是二分类的置信度。输入向量是长度为 28,表示 28 天,每天特征是 39 维的特征向量;LSTM 输出向量是长度为 28,有 5 个隐层的网络层。
ResNet 是由 7 个 ResNet Block 组成。每个 ResNet Block 内部都会进行卷积、归一化、ReLU 运算,ResNet Block 运算结果与 ResNet Block 的输入向量进行相加。
LSTMResNet 模型参数整体较少,LSTM 只有 5 个隐层;ResNet 只有七个 Block,包含 14 个网络层。这是因为模型复杂的情况下,非常容易过拟合,所以模型参数配置时没有使用更多的神经元。
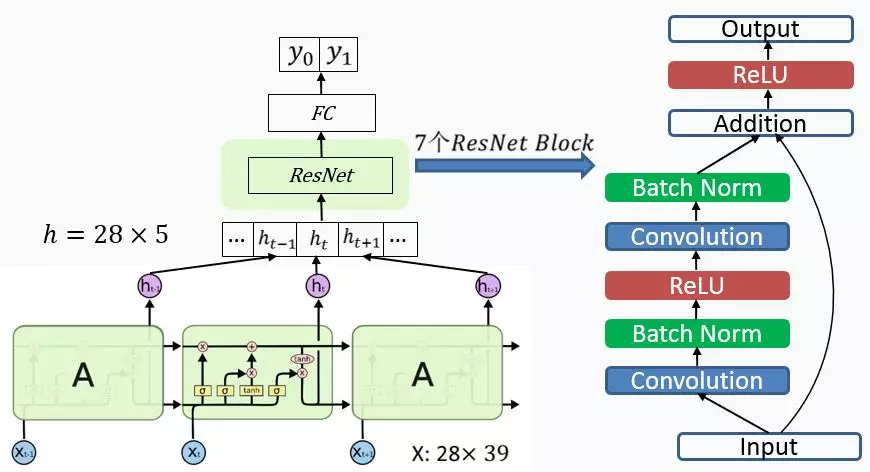
图 6 LSTMResNet 网络结构
为了克服过拟合问题,我们在 ResNet 中使用 Batch Normalization 的同时,还使用了 dropout,图 7 是 dropout 取值不同时的表现(数据来自中间实验过程):

图 7 dropout 调参
5. 业务落地
业务建模之后进行业务落地的工作,主要考虑两个方面:
模型落地方式:当前业务的主要需求是高置信的产出能够达到人工标注的准确率,这部分产出将自动化上线,要模型产出准确率不比人工标注准确率差,这是非常高的一个标准。基于高置信产出必须高准确率的要求,我们采用半监督的方法提升了高置信产出的准确率;
业务风险预防:为了防止模型上线后出现一些影响面较大、明显背离业务常识的 badcase,我们对模型进行了可解释性分析,分析模型的产出是否符合业务常识。
5.1 半监督助力业务落地
半监督方法是一种介于监督和非监督的方法,本文半监督实现的主要思路是:首先,用数量较少的高精样本数据学习模型,其次,用该模型对线上差分样本预测,最后,将预测的高置信部分样本作为带标签数据,重新训练模型,得到最终的模型。实验过程如图 8 所示:

图 8 半监督实验流程
为了评测半监督训练的模型的高置信部分的准确率,分别评测模型 V1 和模型 V2 在业务数据上产出的 topN 准确率,模型 V2 比模型 V1 准确率高 10 个百分点,由此可见,半监督方法非常明显的提升了高置信样本的准确率。
5.2 业务数据验证
业务数据验证,主要是通过分析流量、规划、偏航、热力这四类主要特征是否符合业务常识,来解释模型对封闭事件的刻画是否符合业务预期。模型在流量、规划、偏航、热力上符合业务预期,则模型产出恶劣 badcase 的可能较小。
实验方法是,首先提取北京市某天的业务数据,其次使用模型进行预测,最后按置信度统计分析。业务数据验证结论如下:
模型置信度在流量、规划、偏航、热力截断这四方面均符合业务常识;
置信度能够刻画事件有无;
置信度越高封闭可能性越大
6. 小结
本文介绍了动态事件和封闭事件的概念。为了挖掘封闭事件,我们设计了一套半监督的深度学习方案,较为详细的介绍了路网建模、TCN 及 LSTM 等深度学习建模。为了防止模型产出背离业务常识,进行了业务数据验证,实验表明模型挖出的封闭事件符合业务常识。封闭事件的挖掘能够更好帮助用户合理的规划路线、提高用户体验。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论