

导读:富媒体时代,广告的样式需要千人千面,广告产品形态呈现多样式、多物料组合形态,对 CTR 预估提出了巨大的挑战;针对这个问题,我们提出了一种动态样式组合优选加 DSA 模型,并结合分位置拍卖技术,较完美地解决了组合样式优选的问题。
另外,传统的 CTR 预估较少能挖掘特征之间的交互信息,我们提出一种 MCP 模型,通过辅助的网络结构来学习更好的特征表达,同时在线上 inference 时不会产生额外的计算消耗。
综上,本次分享的内容主要包括:
动态样式 CTR 预估建模
特征表达辅助学习
01 业务背景及 CTR 介绍
1. 智能营销平台业务背景
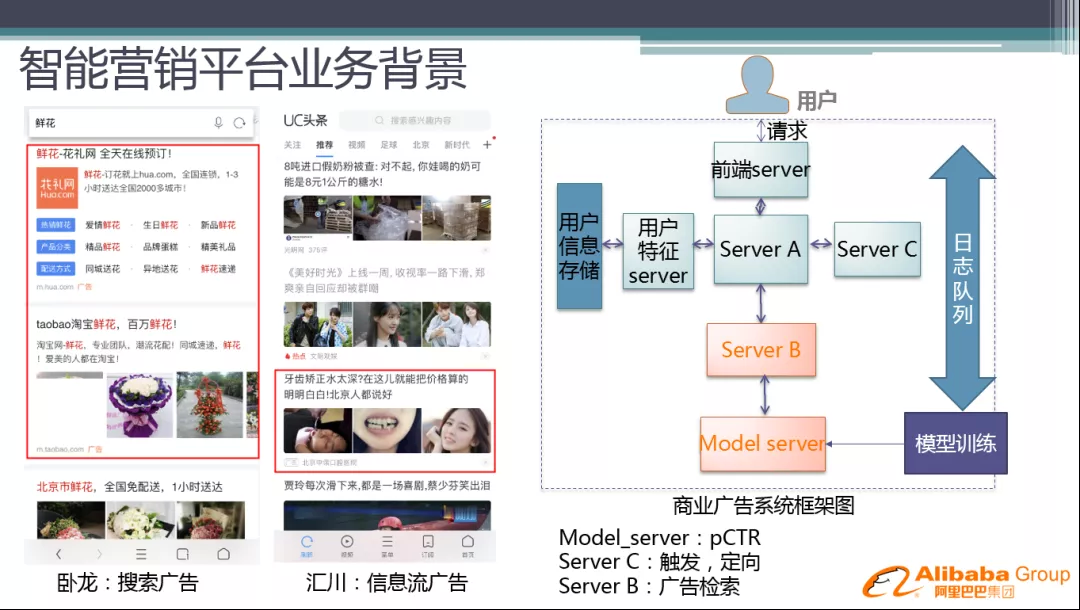
我们的主要业务是搜索广告和信息流广告。搜索广告主要通过搜索 query 触发,信息流广告是在没有 query 的情况下展示广告。
一个通用的商业广告系统,如右图所示:
前端 server:包括媒体接入、广告样式封装等
Server A:策略的中心 Server,实现各个下游 server 之间的连接,以及排序和过滤等策略
Server C:Server A 会先让 Server C 计算出一些候选的拍卖词或者广告集合 ( 在搜索广告中称为触发,在信息流广告中称为定向 )
Server B:广告检索,检索出广告的具体信息,并请求 model server 进行 Q 值计算
Model server:进行各种 Q 值计算的 server
我们可能还会用到用户维度的实时信息,所以我们还有用户特征 server 和用户信息存储等基础架构。
整个商业广告系统是由做工程架构的同学来维护架构,策略同学进行策略的迭代优化。接下来会讲下商业系统中非常重要的部分,也就是 CTR 预估。
2. Click-Through Rate ( CTR ) 预估

CTR 预估的重要性:
Ad selecting:用 CTR 预估做广告漏斗的选择,也就是从检索出来的广告中选出一部分广告进行精排。
Ad ranking:CTR×bid 排序,CTR 估的越准,排序效率越高。
Ad charging:广告计费,根据 CTR 进行广告计费计算。
在线广告的点击率 ( CTR ) 预估问题是构建一个预测模型,来估计给定用户给定广告的点击概率。如图中表格所示:
给定用户 ID、用户属性 ( 如:年龄,性别,兴趣等 ),给定广告 Title,通过用户的行为反馈,可以收集到这个广告用户点击/未点击,作为训练样本就可以训练出一个模型 ( 一个非常复杂的非线性函数表达形式 ),然后推送到在线的 model server 进行实时的 CTR 预估。
CTR 预估的问题看似简单,但确实是业界重点研究的方向,主要从如下几个方向展开:特征优化,模型算法研究,模型应用的创新。
3. CTR 相关工作

回顾下业界常用的模型结构:
逻辑回归模型 ( LR ):模型简单,容易实现,早些年非常流行。
因子分解机 ( FM ):FM 模型增加了二阶项,可以做一些特征两两交互的学习工作。
深度神经网络 ( DNN ):最早以 Google 的 DNN 模型为代表,从结构上对特征做 Embedding,再接几层全连接神经网络,由于我们是分类问题,所以最后用 Sigmoid 计算 CTR 预估值。
Wide&Deep:DNN 在泛化和推理上效果比较好,但是在广告系统中,更希望有一些记忆的特性 ( 如果一个用户对广告有频繁的点击行为,我们希望记住他 ),于是引入了 LR 的组件,来实现记忆的特性。
DeepFM:华为基于 Wide & Deep 模型,又提出了 DeepFM,将 LR 升级为 FM,同时在 DNN Embedding 学习时,联合 FM 进行学习。
后面还有 DCN,以及阿里的深度兴趣网络 DIN 等等。
我们团队的模型现状:
大规模离散 DNN 模型作为基本的模型框架
支持 Wide&Deep,DeepFM 模型结构
自研了时空 DNN,深度记忆网络结构,可以更好的处理用户历史行为,在 CTR 预估中起作用
在特征 Embedding 学习方面,自研了 MCP 网络
02 动态样式 CTR 预估建模
——CTR 预估如何赋能广告样式升级?
1. 广告产品样式升级
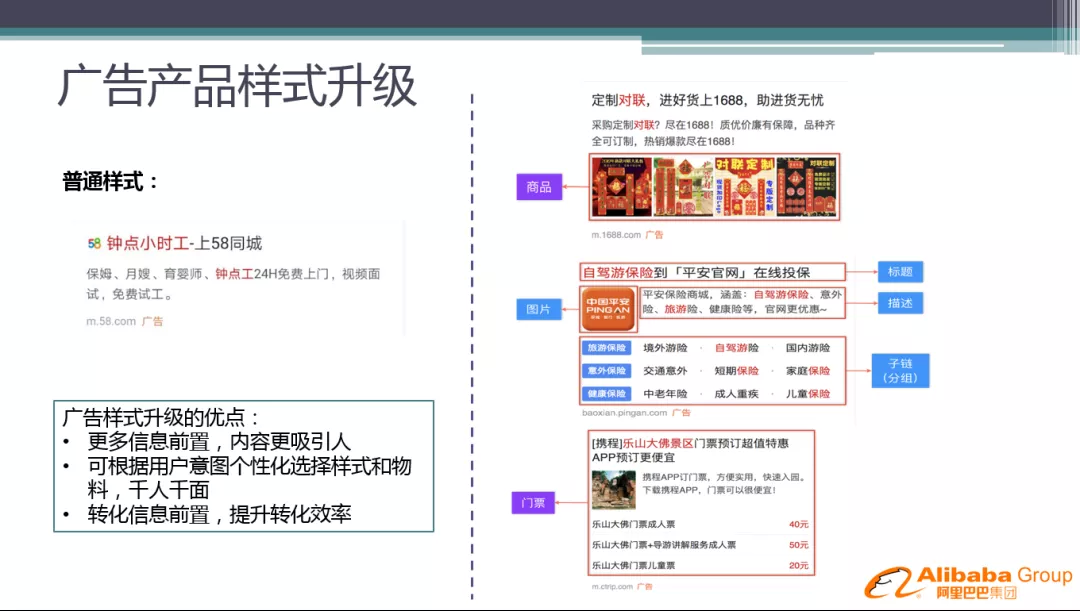
在前几年,广告样式主要是普通的样式:标题+描述,信息量非常少,用户真正感兴趣的内容,需要在落地页中呈现。
近期针对样式方面,我们做了很多的产品升级,如右图所示,增加了商品列表、图文混排、子链 ( 分组 ) 等样式。这样做的优点:
更多信息前置,内容更吸引人,带来点击率的大量提升
可根据用户意图个性化选择样式和物料,千人千面
转化信息前置,提升转化效率
2. 动态创意的组件化
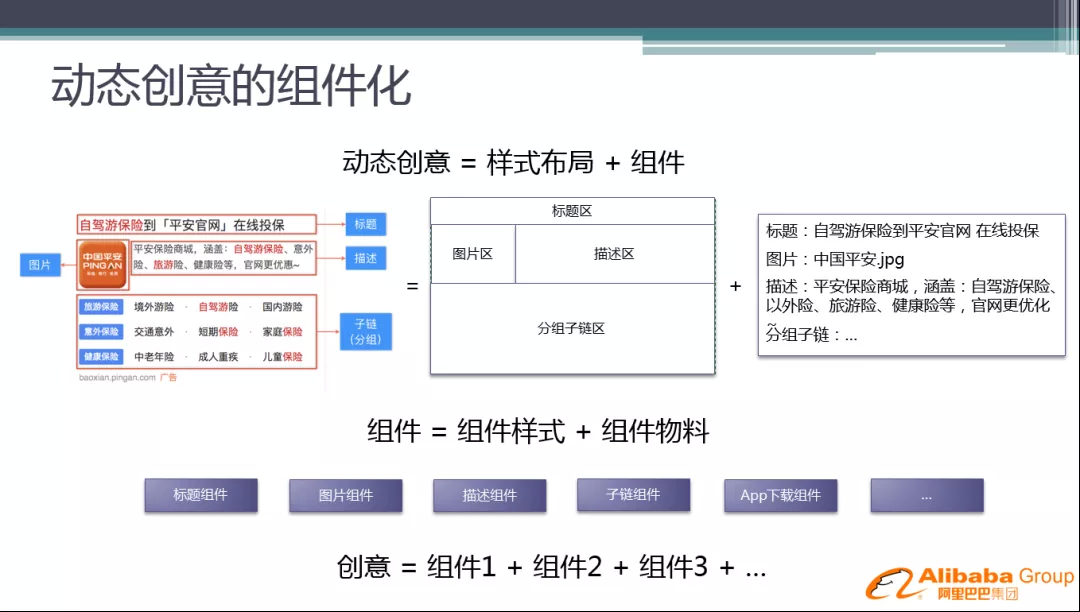
广告产品样式升级主要是通过动态创意来实现的,动态创意包含 样式布局 和 组件 两个要素。如左侧的广告,我们将它拆成元素,有标题、图片、描述和分组等各种子链区,我们将它定义成样式布局。有了样式布局之后,我们需要做的就是填充,比如从广告库中找到标题,填充进去,同时把图片、描述等等也一一找出填充进去。这样的方案对广告主来说是很省时省力的,因为广告主主要关注的是内容的提供。对于内容的提供,我们也提出了策略的解决方案,广告主只需要提供一些基础的内容,我们可以用算法生成一些相近的物料。对于组件的样式不需要广告主定制,我们有专业的样式产品团队进行样式设计,然后由策略团队做样式的策略优选,来确定哪种样式是最好的。
动态创意从产品逻辑上来看很简单,但是从策略上来讲是巨大的难点,首先要确定哪种样式加物料的组合效果最优,而且针对不同用户和广告主最优;其次还要考虑同屏展现下的最优组合。所以我们提出了整体的解决方案:先通过样式+物料组合优选,确定每个广告的动态创意组合,然后通过 DSA 模型建模分位置拍卖过程。
3. 样式+物料组合优选
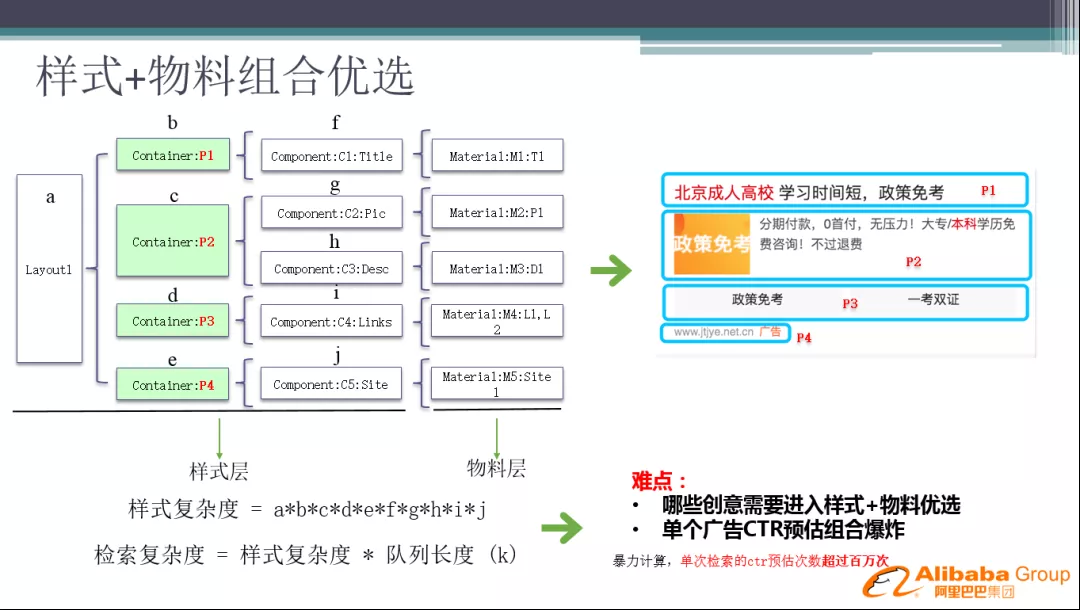
首先介绍一个最基本的解法:
一个广告要展示的时候,我们第一层要选 Layout,确定样式的布局;选定 Layout 之后,要选定每个容器中放哪个物料,从图片到描述,到标题等等,整个计算就是一个多连乘的公式,在线上如果要实现这一套计算,特别是每种实际展现的样式我们在计算 CTR 时,单次检索的 CTR 预估次数会超过百万次,致使单个广告 CTR 预估组合爆炸。并且不只是单个广告,我们检索可能会检索出上千条广告,哪些创意要进入样式+物料优选,也是非常难的问题。因此简单的样式优选难以实现,对性能挑战非常大。
4. 一种简单的算法升级

针对上面的问题,先看一种简化的解决思路:
广告检索,基于原来的检索逻辑,先检索出来创意 ID
CTR 预估,筛选广告,不计算样式和物料内容,只计算基本的 CTR 预估值
广告精排,确定展现队列,排序之后,在搜索广告系统中,可能只剩下了少数条广告
样式和物料选择计算,确定最终的创意样式
这样做的优点:
样式+物料计算的候选广告大大减少。
同时,缺点也非常明显:
CTR 预估没有体现样式和物料带来的加成,使策略最优的效果没有体现出来
样式之间的相互影响没有体现出来,一个强样式排在前面时,会使后面的广告 CTR 预估受影响。业界有很多论文在做这块内容的研究,大家可以了解下
5. 样式+物料选择建模
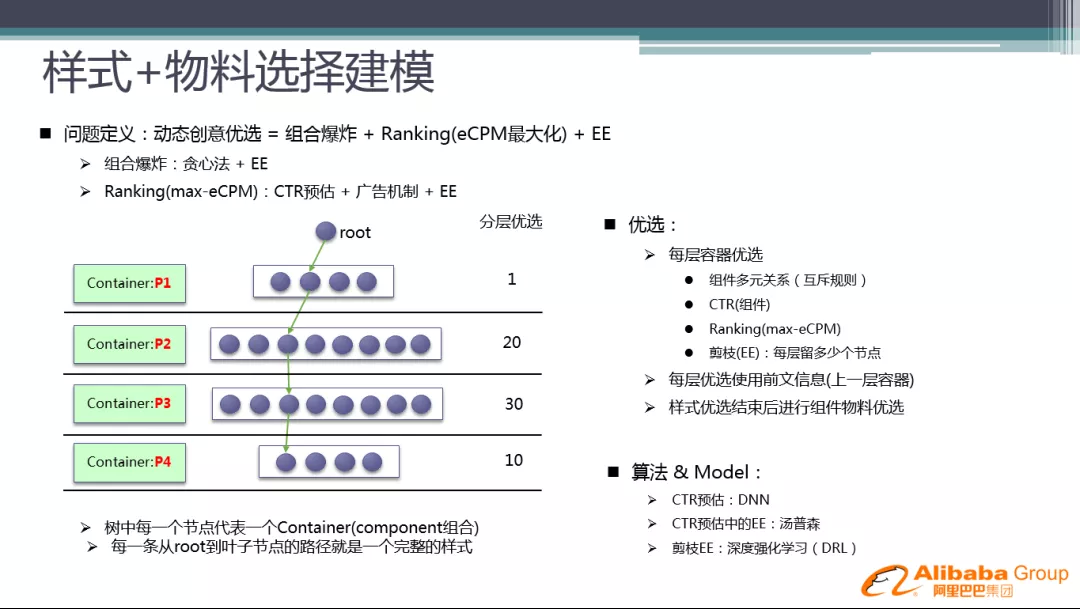
因此,我们将问题进行定义:动态创意优选 = 组合爆炸 + Ranking ( eCPM 最大化 ) + EE
针对组合爆炸的解法是运用贪心算法+EE。这里的贪心策略是将物料组装的形式分层次来做,比如先选定标题,再放图片,进而放入描述,放入子链,…,而不是整个展开来计算。如左图所示,树中每一个节点代表一个容器,每一条从 root 到叶子节点的路径就是一个完整的样式。
针对 Ranking ( max-eCPM ) 的解法是:CTR 预估+广告 EE 机制
优选策略:
① 每层容器优选
组件多元关系 ( 互斥规则 )
CTR ( 组件 )
Ranking ( max-eCPM )
剪枝 ( EE ):每层留多少个节点
② 每层优选使用前文信息 ( 上一层容器 )
③ 样式优选结束后进行组件物料优选
这里用到的算法和 Model:
CTR 预估:DNN
CTR 预估中的 EE:汤普森采样
剪枝 EE:目前这部分还没有做,未来我们准备用深度强化学习 ( DRL ) 来做剪枝,来决策哪些内容可以提前去掉,不用参与计算
6. 一种改进的算法流程
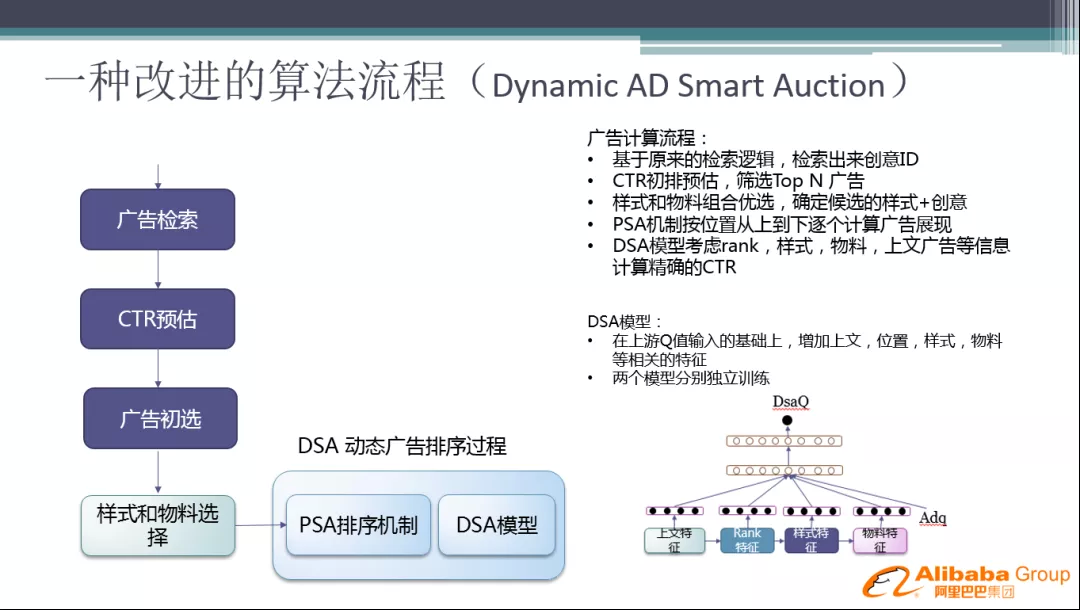
前面的算法,已经解决了大部分的问题,当然还有一部分问题没有解决掉,进而我们又引入了 DSA 动态广告排序过程。
整个广告计算流程:
基于原来的检索逻辑,检索出来创意 ID
CTR 粗排预估,进行广告初选,筛选 Top N 广告
针对 Top N 广告进行样式和物料组合优选,确定候选广告的样式+创意
PSA 机制按位置从上到下逐个计算广告展现
DSA 模型考虑 rank,样式,物料,上文广告等信息计算精确的 CTR
这里的改进是增加了新模型 DSA,可以在上游 Q 值输入的基础上,增加上文,位置,样式,物料等相关特征。另外,我们对 CTR 模型和 DSA 模型是分别独立进行训练的,这里会存在一些问题。
7. CTR 粗选模型 + DSA 模型联合训练
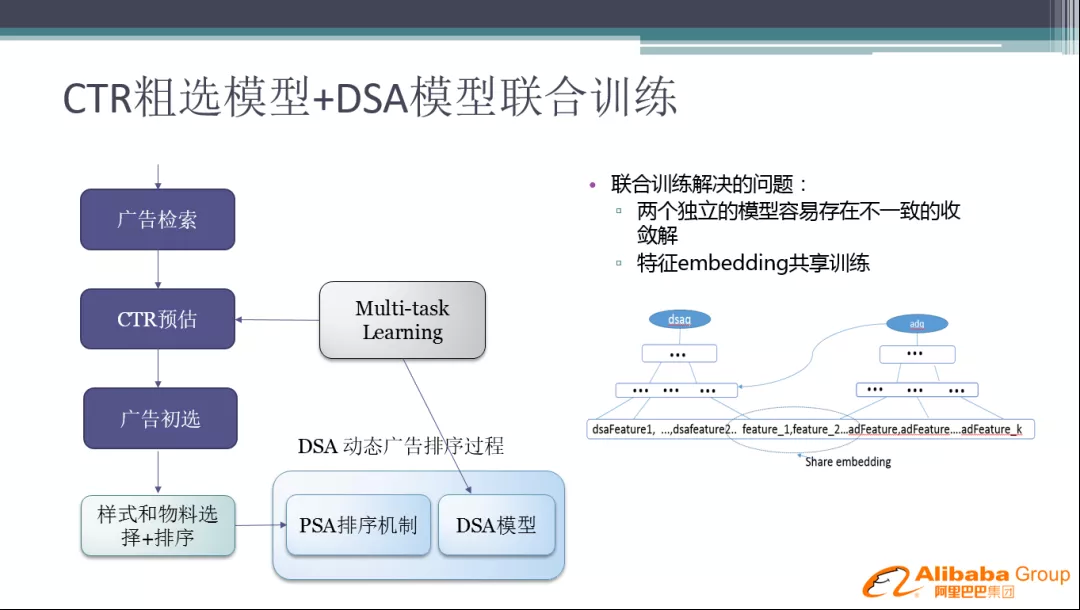
独立训练存在的问题:由于是独立训练,两个模型都存在幸存者偏差,那么 CTR 预估模型中的选出的最好的广告,并不代表在 DSA 模型中就是排的最好的,这两个模型解的不一致性就会带来策略的损失。
近年来,Multi-task Learning ( 多目标学习 ) 领域比较火,也是用来解决这个问题的,所以我们引入了 Multi-task Learning 算法。针对前一版的改进是两个模型联合一起训练,在特征层面可以 share embedding,在网络结构上是两个共生网络进行联合训练。
这里一个小的 trick 是:有些特征在 DSA 阶段,不需要重复计算,所以我们会把上一阶段的 Q 作为下一阶段的输入去使用。
8. 小结
本节内容小结:
在动态样式产品升级的情况下,CTR 预估会面临 组合爆炸 的难题
为减少计算量,可以先计算出广告展现队列 ( 减少样式物料优选的计算量 ),然后再进行 样式和物料选择
即使单个广告的样式和物料优选也会面临计算量非常大的问题,所以引入了 贪心 + EE 的策略,逐层筛选最优结果
先计算广告队列再进行样式和物料优选时,样式和物料的效果 不能影响排序,不是最优结果,收益不能达到最大化
因此,引入 PSA 机制和 DSA 模型,将样式优选和排序过程融合起来,能大幅提升效果
DSA 模型可以和上游模型进行联合建模,进一步提升模型效果
03 特征表达辅助学习
——CTR 模型的 Embedding 能否学习得更好?
1. 深度匹配、关联与预测网络 ( DeepMCP ) idea
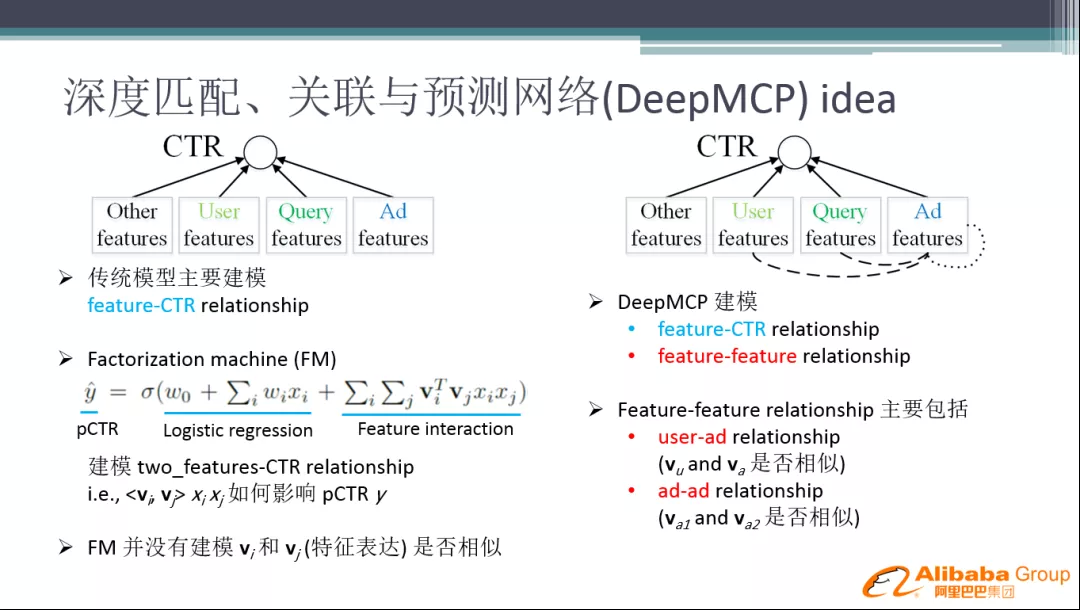
常用的 CTR 模型结构,如左图,模型就是在学一个映射的网络,来实现特征输入到 CTR 的映射形式。传统的模型是解 Feature 到 CTR 目标值的关系,即使后面的 FM 模型,也是在解两两特征如何影响 CTR,并没有建模特征表达是否相似。因此是否可以建立特征表达之间的约束学习,使模型具有更好的泛化性?
我们的解决办法是在 CTR 网络结构中引入辅助的网络结构 ( DeepMCP ),对特征和 CTR 之间的关系,以及特征和特征之间的关系进行建模。其中特征和特征之间的关系,主要包括:用户和广告 之间的关系以及 广告和广告 之间的关系。
2. DeepMCP 概览
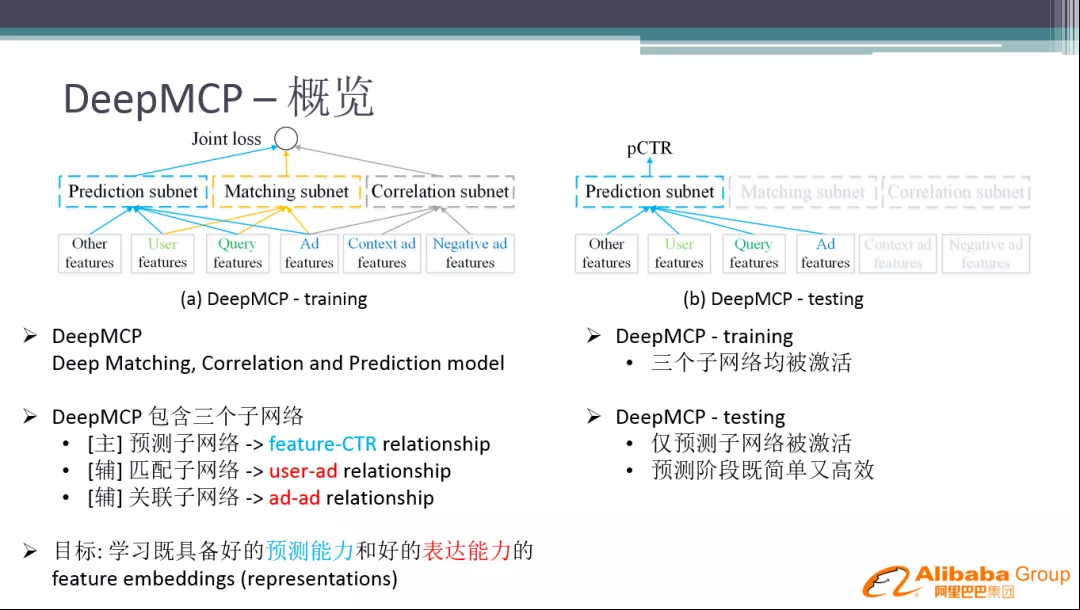
具体的解决方案是在原来预测网络的基础上,加入匹配子网络和关联子网络。目标是学习具备好的预测能力和表达能力的 Embedding 模型。
DeepMCP 的优点:
训练时,三个子网络均被激活
线上做预估时,只有预测子网络被激活,不需用到两个辅助子网络,不会消耗额外的线上计算性能
3. Motivating Example
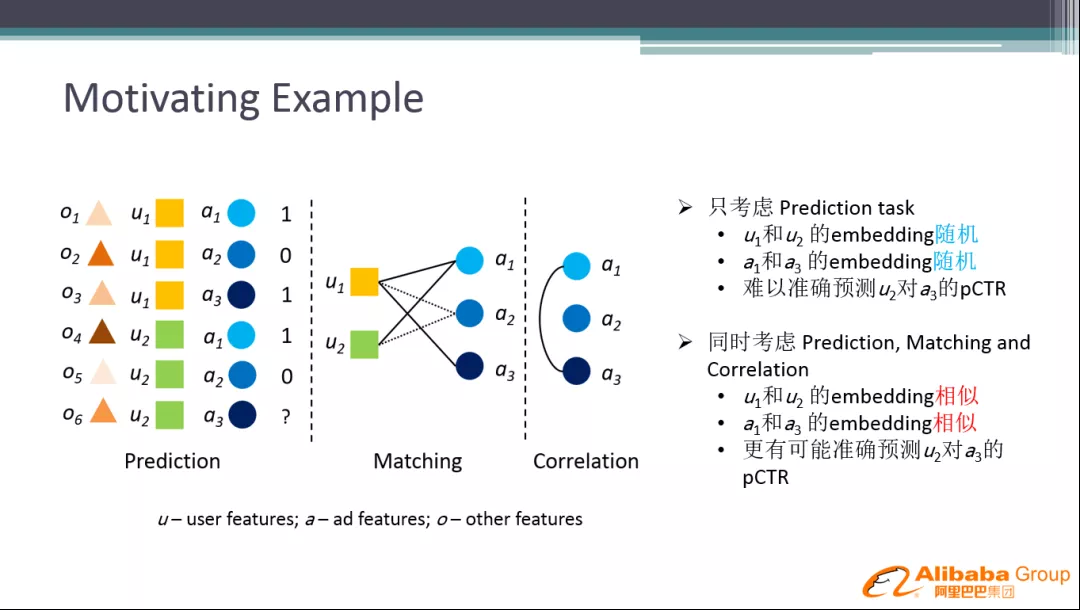
背景动机:
如上图,u 代表用户特征,a 代表广告特征。用户 u1点击了广告 a1和 a3,用户 u2点击了广告 a1,实际场景中,我们可能会需要预测用户 u2对 a3的点击率,在之前的网络中,用户 u2和 a3在 Embedding 表达上没有任何的关系,所以很难预测 u2对 a3的 pCTR。有了辅助网络之后,由于 u1和 a1的 Embedding 与 u2和 a2的 Embedding 比较像,可以推导出 a1和 a3的 Embedding 相似,最终更有可能准确预测出 u1对 a3的 pCTR。
4. 细节
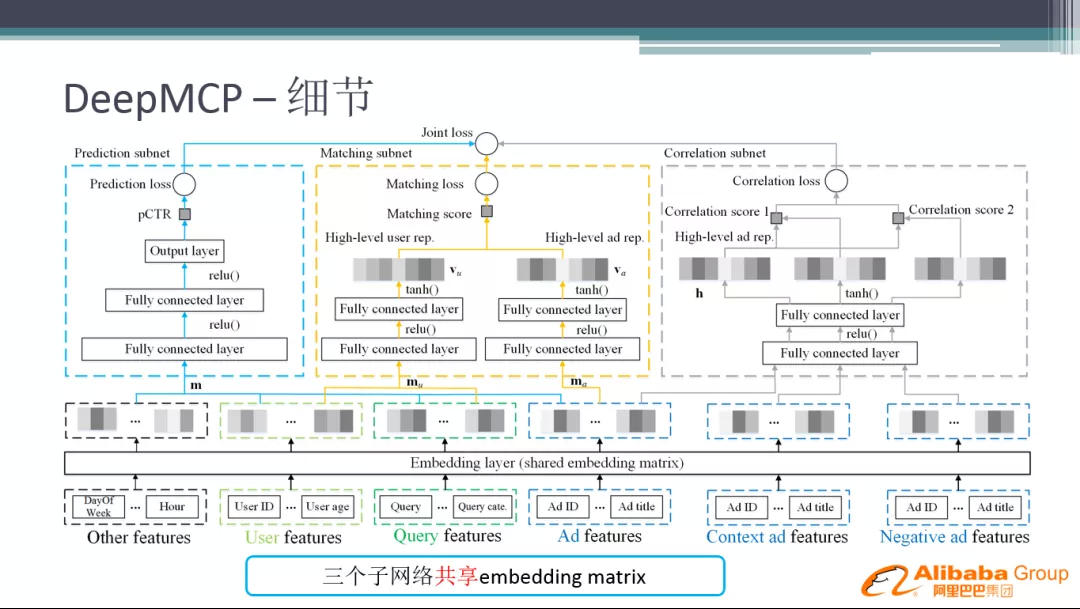
上图为 DeepMCP 的网络结构图,三个子网络共享 Embedding matrix。下面将整个网络拆开分别进行介绍:
① 预测子网络
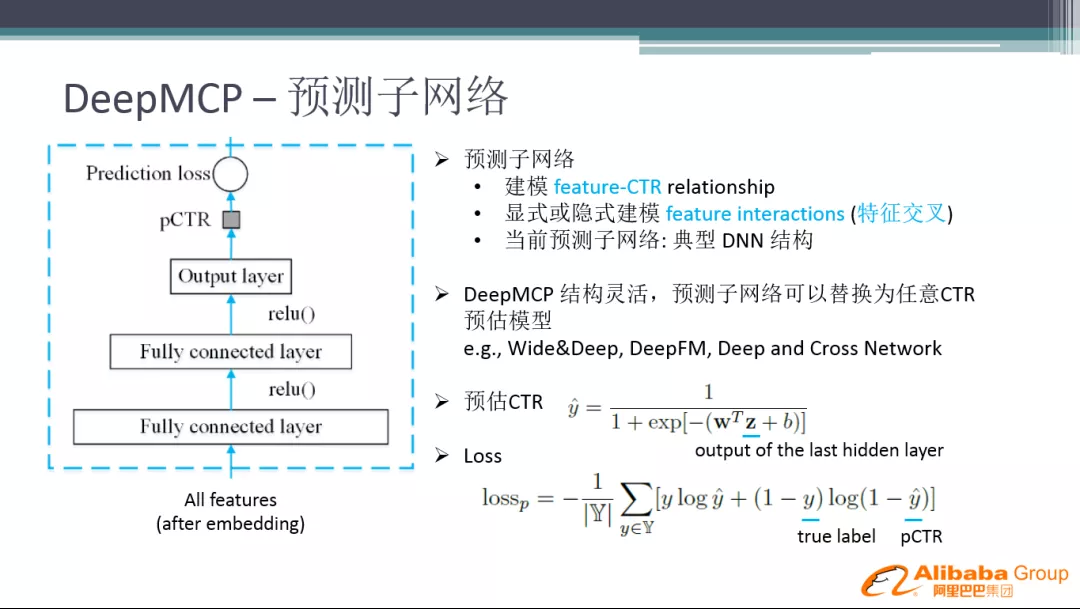
预测子网络就是传统的网络,给定一些特征,然后接几层全连接层,再通过 Sigmoid 生成 CTR 值,最后得到 Prediction loss。这里的预测子网络可以替换为任意 CTR 预估模型,比如 Wide&Deep、DeepFM、Deep and Cross Network 等等。
② 匹配子网络
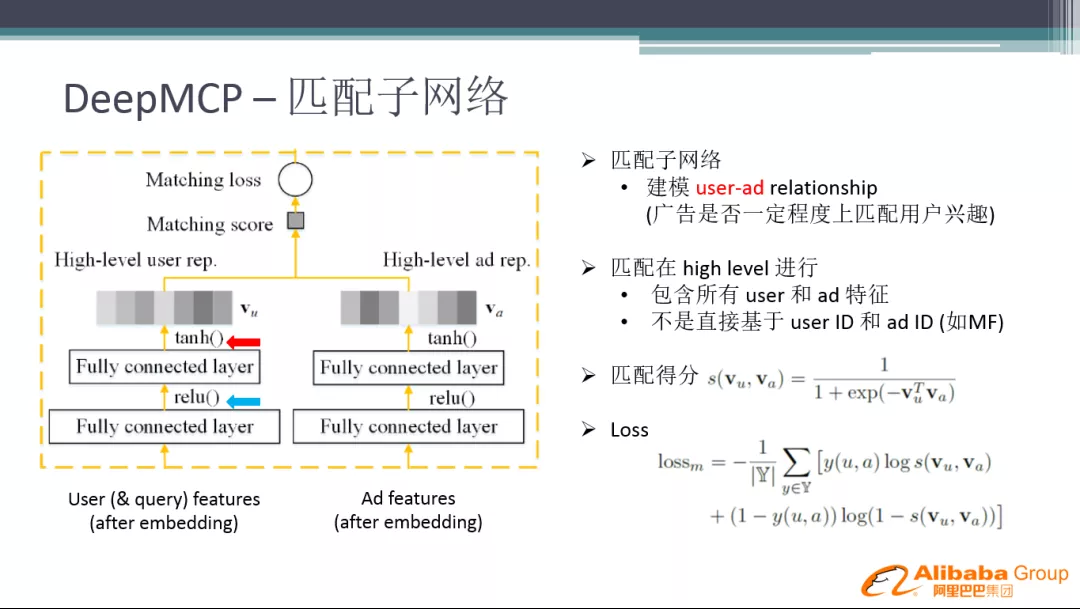
匹配子网络主要是建立用户和广告之间的关系,广告是否一定程度上匹配用户兴趣。我们把用户特征和广告特征分别经过几层神经网络,映射到两个相等维度的 Embedding,再通过 tanh 激活,计算相关性得到 Matching score,最后得到 Matching Loss。这里用到的不只是用户 ID 和广告 ID,而是用户和广告相关的所有特征,因为我们是要辅助的学习特征的表达,而不是推荐系统中只对 ID 进行学习。
③ 关联子网络

关联子网络是建模广告和广告之间的关系。我们首先要构建广告和广告之间的关系,这里借鉴了图网络的思路,但是我们用到的是用户在 context window 一段时间内的点击序列,跟点击序列不相关的广告用随机负采样的方法 ( skip-gram model with neg sampling ) 做负样本,这种方法跟 word2vec 算法的核心思想比较类似。收集完序列之后,把当前广告作为 target ad features,用户点击的广告作为 context ad features,随机负采样的作为 Neg ad features,输入到网络中。网络的目标是当前广告跟历史点击的广告学到的 Embedding 表达尽量接近,随机负采样的表达不接近。将得到的正负样本的 loss 加起来就是 Correlation loss。
④ DeepMCP

对于整个网络,所有 loss 加一起的时候会有调制,我们加入了 α ( 对应 Matching Loss ) 和 β ( 对应 Correlation Loss ) 两个参数。调制参数的调整是在 validation 数据集上监测 AUC,最佳参数在最高 validation AUC 处获得。在线上时,只使用预测子网络。
5. 实验
① 预估效果
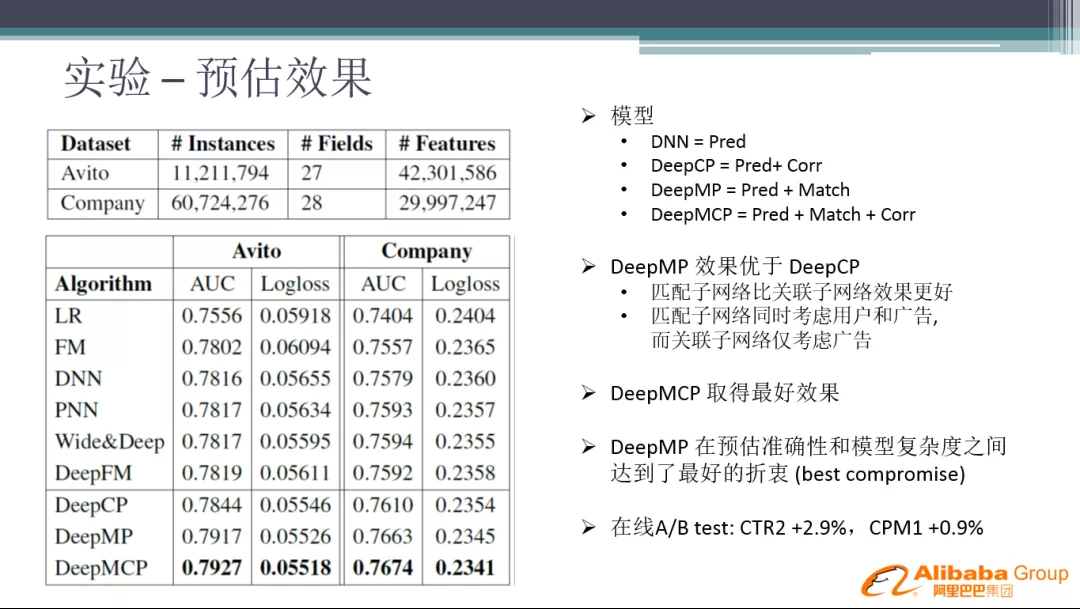
我们分别在公开比赛数据集 Avito 和公司业务数据集,通过对比基础模型 ( LR、FM、DNN、PNN、Wide&Deep、DeepFM ),并对我们的网络进行拆解,DeepCP 代表只加入了一个 Correlation 网络,DeepMP 代表只加入了一个 Matching 网络。可以看到 DeepMP 效果优于 DeepCP,整体上 DeepMCP 效果最好。最终上线的时候,我们采用的是 DeepMP,在预估准确性和模型复杂度之间达到了最好的折衷 ( best compromise )。在线 A/B test 时,CTR2 + 2.9%,CPM1 + 0.9%。
② 调权参数的影响
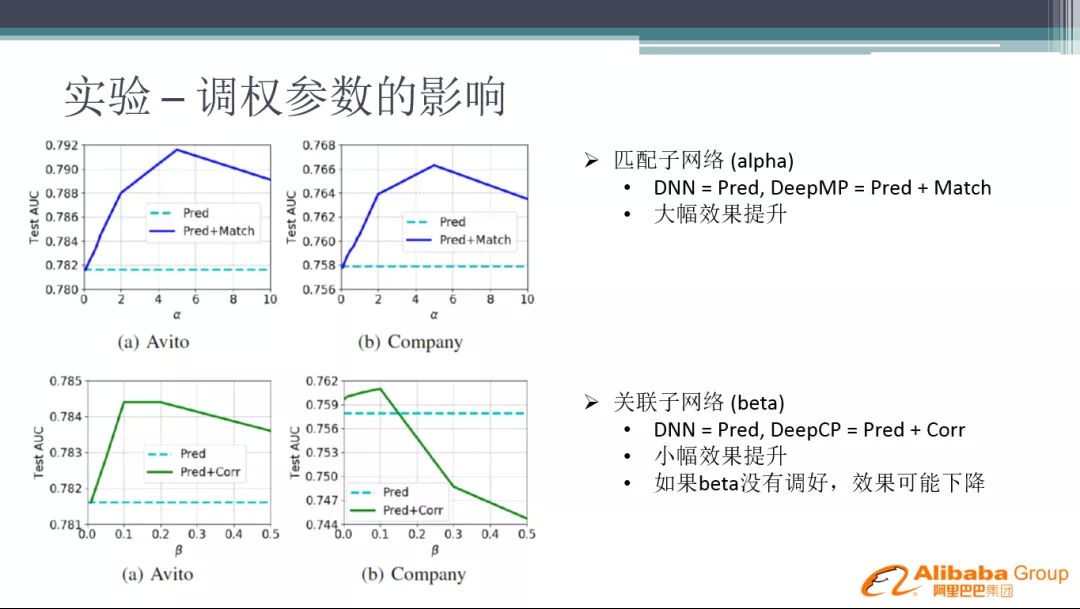
经过测试,我们发现 Matching 部分的权重要大于 Correlation。
③ 网络参数的影响
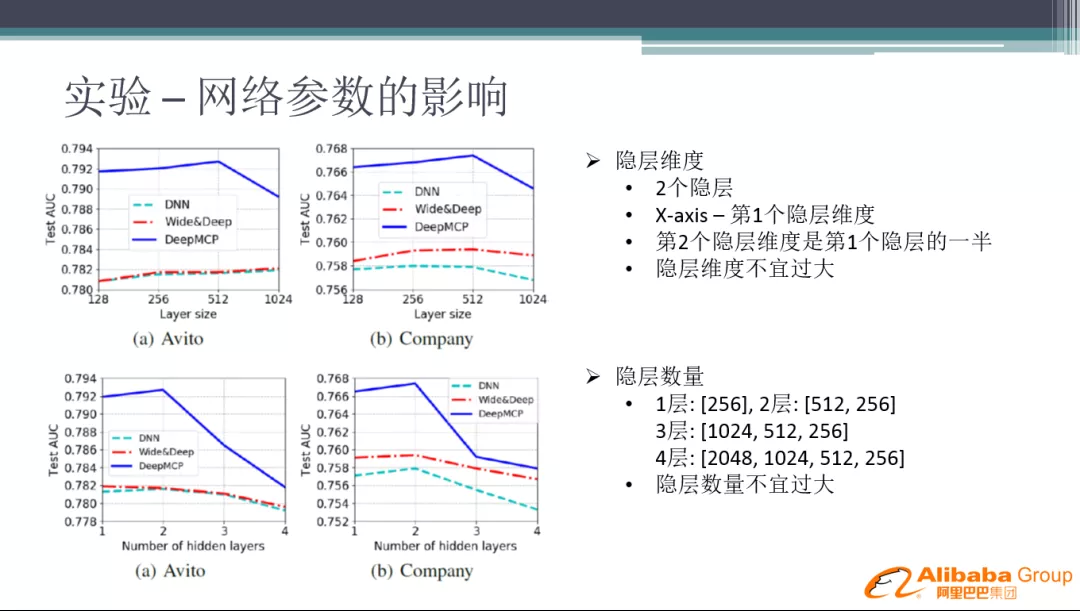
这里主要是指 MCP 辅助网络的层数,主网络的层数根据业务来定。
6. 小结
本节内容小结:
传统 CTR 预估模型主要是建模 feature-CTR relationship
DeepMCP 额外建模 feature-feature relationship ( i.e., user-ad 和 ad-ad relationships )
DeepMCP 是一种多目标学习 ( multi-task learning ) 框架
DeepMCP 包含预测、匹配、关联三个子网络
当三个子网络在 target labels 的监督下联合优化时,学到的 feature embeddings ( representations ) 既具有好的 预测能力,又具有好的 表达能力
实验结果表明匹配子网络比关联子网络带来更大的效果提升
最终我们选择了 DeepMP ( pred+match ),在预估准确性和模型复杂度之间达到了 最好的折衷( best compromise )
本次的分享就到这里,谢谢大家。
作者介绍:
秀武,阿里巴巴高级算法专家。
本文来自 DataFunTalk
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论