

万亿架构设计
在百度监控系统 TSDB 的常态工作负载下,单机每秒处理 20 多万数据点,集群每秒处理数万次查询,每天有几万亿的数据点在 TSDB 中穿梭,这样强悍的性能除了得益于 HBase 本身的性能优势外,架构层面的针对性设计同样功不可没。
面对已是万亿级别却仍持续增长的数据规模,我们设计了读/写分离且无状态的“弹性”架构;为了在高负载下仍保证低延迟的写入和查询,我们将数据进行分层,分别存入 Redis、HBase 和 Hadoop;为了不间断地为业务提供可靠的服务,我们设计了具备分钟级自愈能力的异地冗余架构;为了节约存储成本,我们引入并改进了 Facebook 的时序数据压缩算法。
TSDB 的整体架构如图 1 所示。
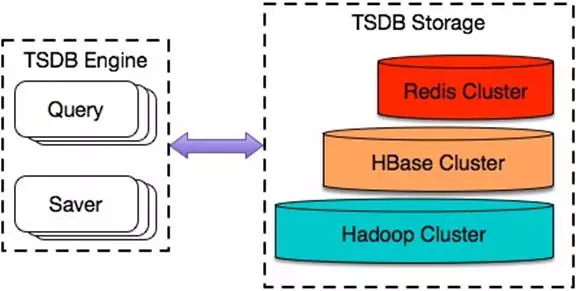
图 1 TSDB 整体架构
可扩展
我们希望通过简单地增加节点就使系统的处理能力线性提升,如果节点之间完全对等、互不影响,那么对整个集群而言,增加节点没有额外的资源消耗,就可以使处理能力随着节点数线性增长。
根据时序数据写多读少的特点,我们将读、写操作分离,设计了无状态的查询模块 Query-engine 和写模块 Saver,使得 Query-engine 或 Saver 的每个实例完全对等,并在上游应用轮询或者一致性哈希进行负载均衡。
实例的部署是基于百度内部的容器方案 Matrix,一则可以合理地分配资源,二则由于写入和查询隔离开来、互不干扰,其各自的性能均得到充分发挥。基于 Matrix 的虚拟化方案也使 TSDB 能够在分钟级完成任意数量的实例扩容。
高性能
在上一篇文章中介绍的“水平分表”的策略(图 2)中,存在 HBase 里的数据被按时间划分到了不同的 Slice,老的 Slice 访问压力相对较小,减轻了系统处理这部分数据的负载,然而最新的一个 Slice 仍然会保持很高的热度,相对集中的负载仍然给 HBase 集群带来不小的压力。因此,我们利用内存缓存了部分热点数据(查询量相对更多的数据),以空间换取更低的查询响应时间,同时分流 HBase 的查询压力。
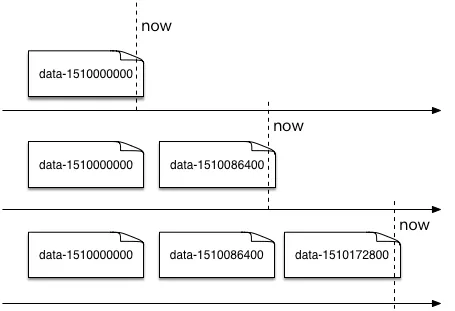
图 2 按时间水平分表
缓存能力由百度运维部 DBA 团队的 BDRP 平台提供。但由于数据量太大,缓存一小时的数据需要较多的内存资源,我们在性能和成本之间做了权衡,选择只将核心指标数据写入缓存。
在大批量查询历史数据的场景中,查询的频率不高,对数据时效性的要求也较低,其目标数据通常是冷数据,因此我们把这部分数据从 Saver 的流量中复制出来,定期地灌入独立的 Hadoop 集群,将此类查询压力从 HBase 分流出去。
经过 Hadoop 和 Redis 的查询分流,HBase 仍然存储全量的数据,但其只承接常规的趋势图查询请求以及从缓存穿透的请求。
低成本
为了降低数据的存储成本,我们引入了 Facebook 在论文《Gorilla: A Fast, Scalable, In-Memory Time Series Database》中介绍的一种时序数据压缩算法(见图 3),它能够达到 10 倍的压缩比,我们将其进行改造后应用到了缓存中。
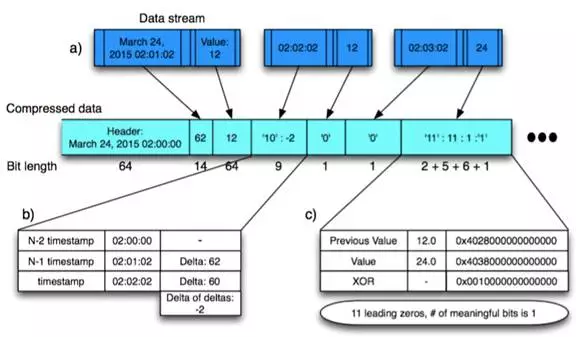
图 3 Facebook Gorilla 中的压缩算法示意图
Gorilla 中的压缩算法较容易理解,其核心思想是增量压缩,不仅针对数据点取值进行压缩,且对时间戳应用了一种 Delta-of-Delta 压缩方法。经过压缩的数据点,其存储空间占用可以“bit”计,算法对于周期稳定、取值变化幅度较小的数据的压缩效果尤其好。
然而,这种增量压缩的算法中,后一个数据点的压缩结果依赖前一个数据点的压缩结果,这要求在集群中为每个时间序列维护压缩的状态,论文未对其分布式实现做详细的介绍,我们将数据压缩成 Byte 流,以 Key-Value 的方式存储在 Redis 中。此外,论文中的算法仅支持浮点型数值,而我们改造后的算法还支持整数型和统计型数值(即上文提到的 StatisticsValue,每一个具有 max、min、sum、count 四个统计值)。
数据压缩的整体方案在实际使用中为我们节省了 80% 的存储空间,额外的 CPU 消耗不超过 10%。
高可用
冗余是高可用的一大法宝,我们使用了简单有效的异地互备的方案,即冗余出一整套集群和数据来实现高可用。写入时,客户端将数据双写到两个集群,查询时通过动态路由表或百度名字服务(Baidu Naming Service, BNS)访问到其中一个集群(图 4),在此基础上我们具备故障自愈机制,可以实现分钟级的单机房故障自愈。
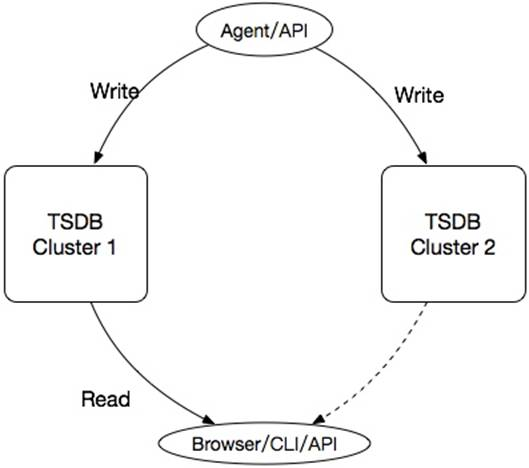
图 4 异地互备
总结
近年来,TSDB 在智慧城市、物联网和车联网等等领域都有着十分广泛的应用,更是成为监控场景的标配基础服务。在《百度大规模时序数据存储》系列的四篇文章中,我们为读者介绍了大规模 TSDB 从模型到功能再到架构的设计实践,但从实际的需求出发,我们认为 TSDB 的架构设计思路和功能侧重点并不局限于文中所述。
技术上,在大规模的时序数据存储系统中,我们选择了 HBase 作为底层存储,但并不代表 HBase 在任何场景下都是最合适的选择。在应用上,TSDB 也会与分布式计算、数据挖掘、异常检测甚至 AI 技术进行深度结合,将会面临更加复杂和富有挑战的场景。
我们设想将 TSDB 抽象成各种功能组件,能够根据不同场景的特点,灵活地搭配各个功能组件,以满足不同的需求。例如在数据量级较小的时候可以基于 MySQL 进行单机存储;或者作为缓存层直接基于内存存储;或者利用 Elasticsearch 的强大检索能力做多维度聚合分析等等。
目前我们已经进行了一些组件化的工作,并在这些工作的基础上实现了对 Cassandra 的支持,后续还将丰富框架和组件,引入新的功能,并逐步实现对 Elasticsearch、MySQL 等存储系统的支持。
作者介绍:
运小尧,百度高级研发工程师,负责百度运维大数据存储平台的设计和研发,致力于追求大规模存储系统的高性能和高可用。
本文转载自公众号 AIOps 智能运维(ID:AI_Ops)。
原文链接:
https://mp.weixin.qq.com/s/VM6tH06e-sA55DWQjeKEOA

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论