

Kelemetry 是字节跳动开发的用于 Kubernetes 控制平面的追踪系统,它从全局视角串联起多个 Kubernetes 组件的行为,追踪单个 Kubernetes 对象的完整生命周期以及不同对象之间的相互影响。
通过可视化 K8s 系统内的事件链路,它使得 Kubernetes 系统更容易观测、更容易理解、更容易 Debug。
背景
在传统的分布式追踪中,“追踪”通常对应于用户请求期间的内部调用。特别是当用户请求到达时,追踪会从根跨度开始,然后每个内部 RPC 用会启动一个新的子跨度。由于父跨度的持续时间通常是其子跨度的超集,追踪可以直观地以树形或火焰图的形式观察,其中层次结构表示组件之间的依赖关系。
与传统的 RPC 系统相反,Kubernetes API 是异步和声明式的。为了执行操作,组件会更新 apiserver 上对象的规范(期望状态),然后其他组件会不断尝试自我纠正以达到期望的状态。
例如,当我们将 ReplicaSet 从 3 个副本扩展到 5 个副本时,我们会将 spec.replicas 字段更新为 5,rs controller 会观察到此更改,并不断创建新的 pod 对象,直到总数达到 5 个。当 kubelet 观察到其管理的节点创建了一个 pod 时,它会在其节点上生成与 pod 中的规范匹配的容器。
在此过程中,我们从未直接调用过 rs controller,rs controller 也从未直接调用过 kubelet。这意味着我们无法观察到组件之间的直接因果关系。如果在过程中删除了原始的 3 个 pod 中的一个,副本集控制器将与两个新的 pod 一起创建一个不同的 pod,我们无法将此创建与 ReplicaSet 的扩展或 pod 的删除关联起来。
因此,由于“追踪”或“跨度”的定义模糊不清,传统的基于跨度的分布式追踪模型在 Kubernetes 中几乎不适用。
过去,各个组件一直在实现自己的内部追踪,通常每个“reconcile”对应一个追踪(例如,kubelet 追踪只追踪处理单个 pod 创建/更新的同步操作)。然而,没有单一的追踪能够解释整个流程,这导致了可观察性的孤立岛,因为只有观察多个 reconcile 才能理解许多面向用户的行为;例如,扩展 ReplicaSet 的过程只能通过观察副本集控制器处理 ReplicaSet 更新或 pod 就绪更新的多个 reconcile 来推断。
为解决可观察性数据孤岛的问题,Kelemetry 以组件无关、非侵入性的方式,收集并连接来自不同组件的信号,并以追踪的形式展示相关数据。
设计
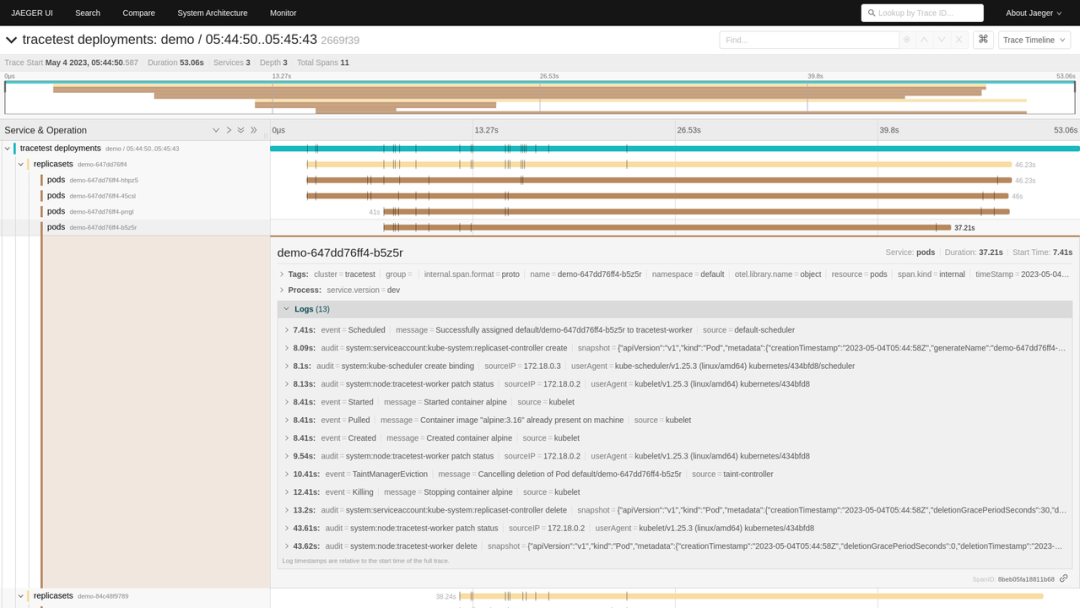
1.将对象作为跨度
为了连接不同组件的可观察性数据,Kelemetry 采用了一种不同的方法,受 kspan 项目的启发,与将单个操作作为根跨度的尝试不同,这里为对象本身创建一个跨度,而每个在对象上发生的事件都是一个子跨度。此外,各个对象通过它们的拥有关系连接在一起,使得子对象的跨度成为父对象的子跨度。
基于此,我们得到了两个维度:树形层次结构表示对象层次结构和事件范围,而时间线表示事件顺序,通常与因果关系一致。
例如,当我们创建一个单 pod 部署时,deployment controller、rs controller 和 kubelet 之间的交互可以使用审计日志和事件的数据在单个追踪中显示:

追踪通常用于追踪持续几秒钟的短暂请求,所以追踪存储实现可能不支持具有长生命周期或包含太多跨度的追踪;包含过多跨度的追踪可能导致某些存储后端的性能问题。因此,我们通过将每个事件分到其所属的半小时时间段中,将每个追踪的持续时间限制为 30 分钟。例如,发生在 12:56 的事件将被分组到 12:30-13:00 的对象跨度中。
我们使用分布式 KV 存储来存储(集群、资源类型、命名空间、名称、字段、半小时时间戳)到相应对象创建的追踪/跨度 ID 的映射,以确保每个对象只创建一个追踪。
2.审计日志收集
Kelemetry 的主要数据源之一是 apiserver 的审计日志。审计日志提供了关于每个控制器操作的丰富信息,包括发起操作的客户端、涉及的对象、从接收请求到完成的准确持续时间等。在 Kubernetes 架构中,每个对象的更改会触发其相关的控制器进行协调,并导致后续对象的更改,因此观察与对象更改相关的审计日志有助于理解一系列事件中控制器之间的交互。
Kubernetes apiserver 的审计日志以两种不同的方式暴露:日志文件和 webhook。一些云提供商实现了自己的审计日志收集方式,而在社区中配置审计日志收集的与厂商无关的方法进展甚微。为了简化自助提供的集群的部署过程,Kelemetry 提供了一个审计 webhook,用于接收原生的审计信息,也暴露了插件 API 以实现从特定厂商的消息队列中消费审计日志。
3.Event 收集
当 Kubernetes 控制器处理对象时,它们会发出与对象关联的“event”。当用户运行 kubectl describe 命令时,这些 event 会显示出来,通常提供了控制器处理过程的更友好的描述。例如,当调度器无法调度一个 pod 时,它会发出一个 FailToSchedulePod 事件,其中包含详细的消息:
0/4022 nodes are available to run pod xxxxx: 1072 Insufficient memory, 1819 Insufficient cpu, 1930 node(s) didn't match node selector, 71 node(s) had taint {xxxxx}, that the pod didn't tolerate.
由于 event 针对用于 kubectl describe 命令优化,它们并不保留每个原始事件,而是存储了最后一次记录事件的时间戳和次数。另一方面,Kelemetry 使用 Kubernetes 中的对象列表观察 API 检索事件,而该 API 仅公开 event 对象的最新版本。为了避免重复事件,Kelemetry 使用了几种启发式方法来“猜测”是否应将 event 报告为一个跨度:
持久化处理的最后一个 event 的时间戳,并在重启后忽略该时间戳之前的事件。虽然事件的接收顺序不一定有保证(由于客户端时钟偏差、控制器 — apiserver — etcd 往返的不一致延迟等原因),但这种延迟相对较小,可以消除由于控制器重启导致的大多数重复。
验证 event 的 resourceVersion 是否发生了变化,避免由于重列导致的重复 event。
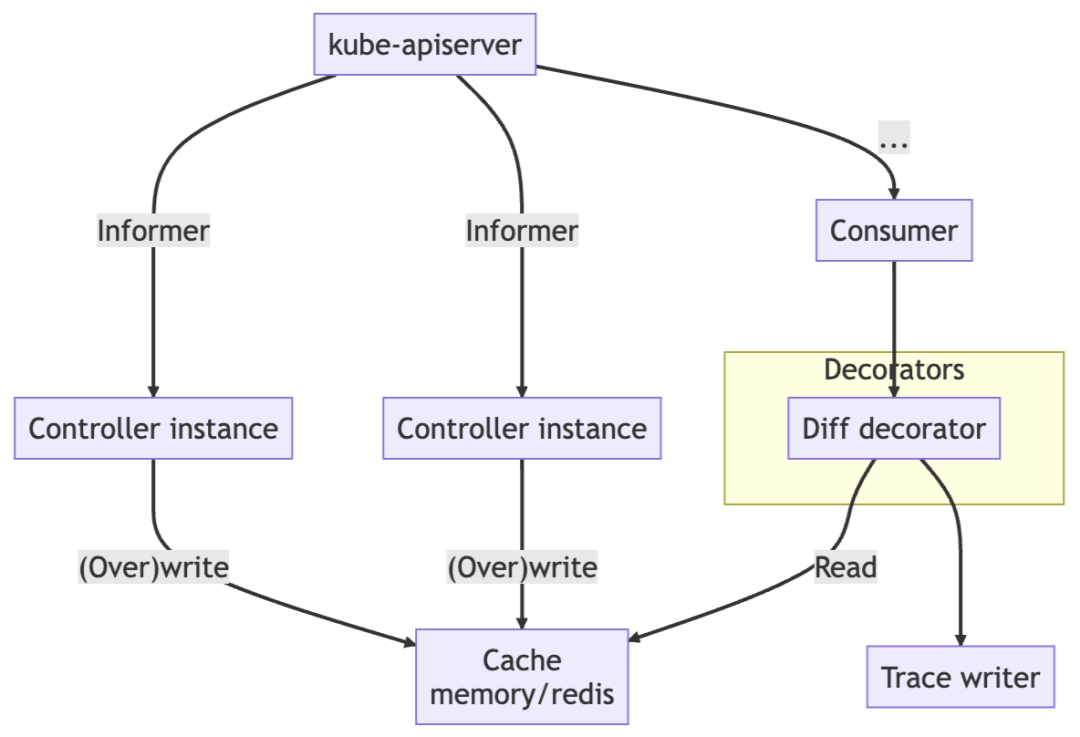
4.将对象状态与审计日志关联
在研究审计日志进行故障排除时,我们最想知道的是“此请求改变了什么”,而不是“谁发起了此请求”,尤其是当各个组件的语义不清楚时。Kelemetry 运行一个控制器来监视对象的创建、更新和删除事件,并在接收到审计事件时将其与审计跨度关联起来。当 Kubernetes 对象被更新时,它的 resourceVersion 字段会更新为一个新的唯一值。这个值可以用来关联更新对应的审计日志。Kelemetry 把对象每个 resourceVersion 的 diff 和快照缓存在分布式 KV 存储中,以便稍后从审计消费者中链接,从而使每个审计日志跨度包含控制器更改的字段。
追踪 resourceVersion 还有助于识别控制器之间的 409 冲突。当客户端传递 UPDATE 请求的 resourceVersion 过旧,且其他请求是将 resourceVersion 更改时,就会发生冲突请求。Kelemetry 能够将具有相同旧资源版本的多个审计日志组合在一起,以显示与其后续冲突相关的审计请求作为相关的子跨度。
为了确保无缝可用性,该控制器使用多主选举机制,允许控制器的多个副本同时监视同一集群,以确保在控制器重新启动时不会丢失任何事件。
5.前端追踪转换
在传统的追踪中,跨度总是在同一个进程(通常是同一个函数)中开始和结束。因此,OTLP 等追踪协议不支持在跨度完成后对其进行修改。不幸的是,Kelemetry 不是这种情况,因为对象不是运行中的函数,并且没有专门用于启动或停止其跨度的进程。相反,Kelemetry 在创建后立即确定对象跨度,并将其他数据写入子跨度, 是以每个审计日志和事件都是一个子跨度而不是对象跨度上的日志。
然而,由于审计日志的结束时间/持续时间通常没有什么价值,因此追踪视图非常丑陋且空间效率低下:

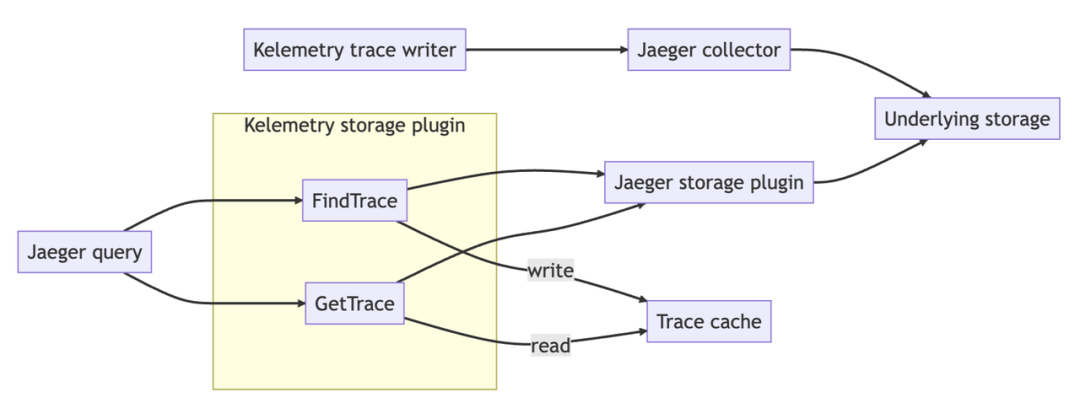
为了提高用户体验,Kelemetry 拦截在 Jaeger 查询前端和存储后端之间,将存储后端结果返回给查询前端之前,对存储后端结果执行自定义转换流水线。
Kelemetry 目前支持 4 种转换流水线:
tree:服务名/操作名等字段名简化后的原始 trace 树
timeline:修剪所有嵌套的伪跨度,将所有事件跨度放在根跨度下,有效地提供审计日志
tracing:非对象跨度被展平为相关对象的跨度日志

分组:在追踪管道输出之上,为每个数据源(审计/事件)创建一个新的伪跨度。当多个组件将它们的跨度发送到 Kelemetry 时,组件所有者可以专注于自己组件的日志并轻松地交叉检查其他组件的日志。
用户可以在追踪搜索时通过设置“service name“来选择转换流水线。中间存储插件为每个追踪搜索结果生成一个新的“CacheID”,并将其与实际 TraceID 和转换管道一起存储到缓存 KV 中。当用户查看时,他们传递 CacheID,CacheID 由中间存储插件转换为实际 TraceID,并执行与 CacheID 关联的转换管道。
6.突破时长限制
如上所述,追踪不能无限增长,因为它可能会导致某些存储后端出现问题。相反,我们每 30 分钟开始一个新的追踪。这会导致用户体验混乱,因为在 12:28 开始滚动的部署追踪会在 12:30 突然终止,用户必须在 12:30 手动跳转到下一个追踪才能继续查看追踪。
为了避免这种认知开销,Kelemetry 存储插件在搜索追踪时识别具有相同对象标签的跨度,并将它们与相同的缓存 ID 以及用户指定的搜索时间范围一起存储。在渲染 span 时,所有相关的轨迹都合并在一起,具有相同对象标签的对象 span 被删除重复,它们的子对象被合并。轨迹搜索时间范围成为轨迹的剪切范围,将对象组的完整故事显示为单个轨迹。
7.多集群支持
可以部署 Kelemetry 来监视来自多个集群的事件。在字节跳动,Kelemetry 每天创建 80 亿个跨度(不包括伪跨度;使用多 raft 缓存后端而不是 etcd)。对象可以链接到来自不同集群的父对象,以启用对跨集群组件的追踪。
未来增强
1.采用自定义追踪源
为了真正连接 K8s 生态系统中的所有观测点,审计和事件并不足够全面。Kelemetry 将从现有组件收集追踪,并将其集成到 Kelemetry 追踪系统中,以提供对整个系统的统一和专业化视图。
2.批量分析
通过 Kelemetry 的聚合追踪,回答诸如“从部署升级到首次拉取镜像的进展需要多长时间”等问题变得更加容易,但我们仍然缺乏在大规模上聚合这些指标以提供整体性能洞察的能力。通过每隔半小时分析 Kelemetry 的追踪输出,我们可以识别一系列跨度中的模式,并将其关联为不同的场景。
使用案例
1. replicaset controller 异常
用户报告,一个 deployment 不断创建新的 Pod。我们可以通过 deployment 名称快速查找其 Kelemetry 追踪,分析 replicaset 与其创建的 Pod 之间的关系。
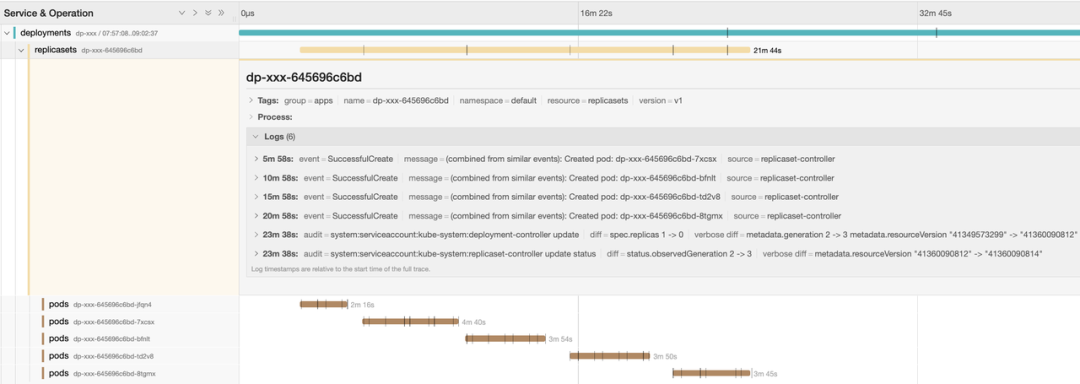
从追踪可见几个关键点:
Replicaset-controller 发出
SuccessfulCreate事件,表示 Pod 创建请求成功返回,并在 replicaset reconcile 中得到了 replicaset controller 的确认。没有 replicaset 状态更新事件,这意味着 replicaset controller 中的 Pod reconcile 未能更新 replicaset 状态或未观察到这些 Pod。
此外,查看其中一个 Pod 的追踪:

Replicaset controller 在 Pod 创建后再也没有与该 Pod 进行交互,甚至没有失败的更新请求。
因此,我们可以得出结论,replicaset controller 中的 Pod 缓存很可能与 apiserver 上的实际 Pod 存储不一致,我们应该考虑 pod informer 的性能或一致性问题。如果没有 Kelemetry,定位此问题将涉及查看多个 apiserver 实例的各个 Pod 的审计日志。
2.浮动的 minReadySeconds
用户发现 deployment 的滚动更新非常缓慢,从 14:00 到 18:00 花费了几个小时。如果不使用 Kelemetry,通过使用 kubectl 查找对象,发现 minReadySeconds 字段设置为 10,所以长时间的滚动更新时间是不符合预期的。kube-controller-manager 的日志显示,在一个小时后 Pod 才变为 Ready 状态

进一步查看 kube-controller-manager 的日志后发现,在某个时刻 minReadySeconds 的值为 3600。

如果使用 Kelemetry 进行调试,我们可以直接通过 deployment 名称查找追踪,并发现 federation 组件增加了 minReadySeconds 的值。
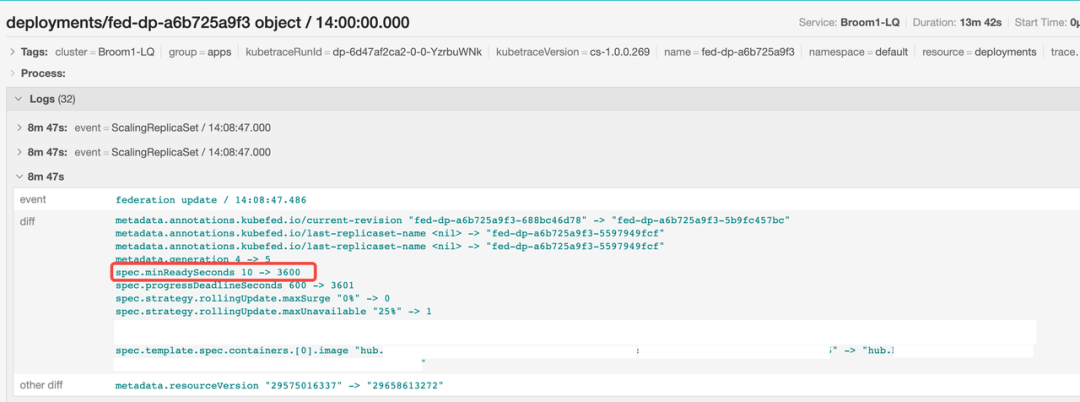
后来,deployment controller 将该值恢复为 10。
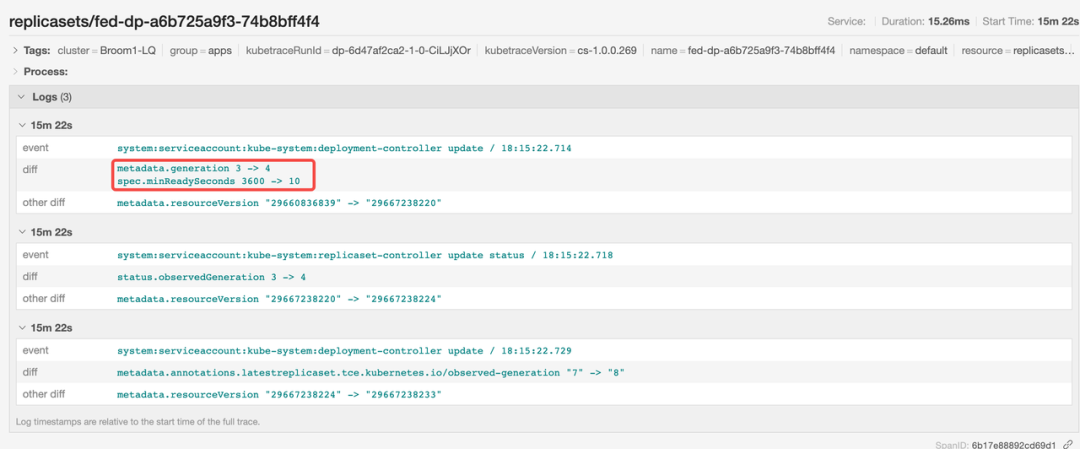
因此,我们可以得出结论,问题是由用户在滚动更新过程中临时注入的较大 minReadySeconds 值引起的。通过检视对象 diff ,可以轻松识别由非预期中间状态引起的问题。
尝试 Kelemetry
目前,Kelemetry 已在 GitHub 上开源:github.com/kubewharf/kelemetry
感兴趣的开发者可以按照 docs/QUICK_START.md 快速入门指南,亲自体验 Kelemetry 如何与组件进行交互。如果你不想设置一个集群,也可以查看从 GitHub CI 流水线构建的在线预览:kubewharf.io/kelemetry/trace-deployment/。
我们期待有更多朋友关注与加入社区,如果大家在试用过程中发现了一些问题,也欢迎大家提出 issue 给我们反馈!

扫描二维码,添加小助手

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论