AWS ParallelCluster 可简化 HPC 集群的创建和部署。Amazon API Gateway 一种完全托管的服务,可让开发人员更轻松地创建、发布、维护、监控任何规模的 API 并保护其安全。
在此博文中,我们结合 AWS ParallelCluster 和 AWS API Gateway 来允许 HTTP 与计划程序交互。您可以使用 API 提交、监控和终止作业,而不是通过 SSH 连接到主节点。这样便可以通过编程方式将 ParallelCluster 集成到本地或 AWS 上运行的其他应用程序。
API 使用 AWS Lambda 和 AWS Systems Manager 执行用户命令,无需授予对节点的直接 SSH 访问权,从而增强整个集群的安全性。
VPC 配置
用于此配置的 VPC 可以使用 VPC 向导创建。您也可以使用符合 AWS ParallelCluster 网络要求的现有 VPC。
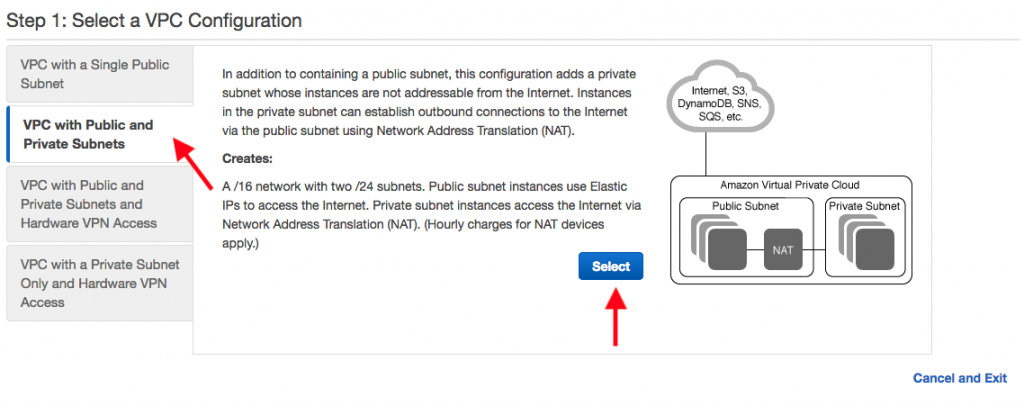
在选择 VPC 配置中,选择具有公共和私有子网的 VPC,然后点击选择。
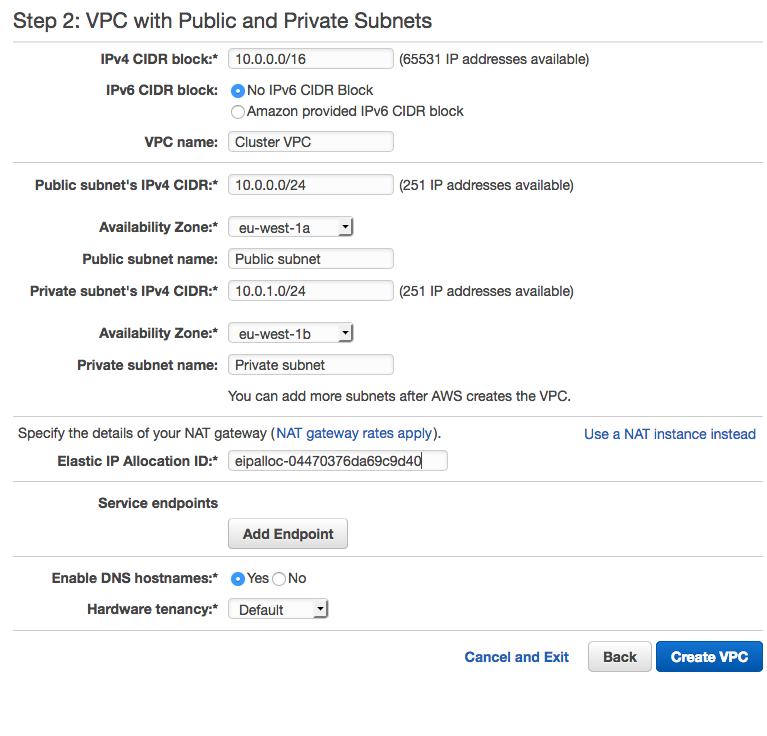
在开始 VPC 向导之前,分配一个弹性 IP 地址。该地址将被用于为私有子网配置 NAT 网关。在 AWS ParallelCluster 私有子网中启用计算节点以下载所需软件包和访问 AWS 服务公共终端节点时,需要 NAT 网关。请参见 AWS ParallelCluster 网络要求。
您可以在具有公共和私有子网 (NAT) 的 VPC 中了解有关 VPC 创建和配置选项的更多详细信息。
下面的示例使用以下配置:
IPv4 CIDR 块:10.0.0.0/16
VPC 名称:集群 VPC
公共子网的 IPv4 CIDR:10.0.0.0/24
可用区:eu-west-1a
公共子网名称:Public subnet
私有子网的 IPv4 CIDR:1 0.0.1.0/24
可用区:eu-west-1b
私有子网名称:Private subnet
弹性 IP 分配 ID:启用 DNS 主机名:yes
AWS ParallelCluster 配置
AWS ParallelCluster 是一种开源集群管理工具,可用于在 AWS 云中部署和管理 HPC 集群;要开始使用,请参阅安装 AWS ParallelCluster。
在配置好 AWS ParallelCluster 命令行之后,在 .parallelcluster/config 中创建下面的集群模板文件。master_subnet_id 包含已创建公共子网的 ID,compute_subnet_id 包含私有 ID。ec2_iam_role 是将用于集群所有实例的角色。创建此角色的步骤将在下面说明。
[aws]aws_region_name = eu-west-1
[cluster slurm]scheduler = slurmcompute_instance_type = c5.largeinitial_queue_size = 2max_queue_size = 10maintain_initial_size = falsebase_os = alinuxkey_name = AWS_Irelandvpc_settings = publicec2_iam_role = parallelcluster-custom-role
[vpc public]master_subnet_id = subnet-01fc20e143543f8afcompute_subnet_id = subnet-0b1ae2790497d83ecvpc_id = vpc-0cdee679c5a6163bd
[global]update_check = truesanity_check = truecluster_template = slurm
[aliases]ssh = ssh {CFN_USER}@{MASTER_IP} {ARGS}
复制代码
SSM 终端节点的 IAM 自定义角色
要允许 ParallelCluster 节点调用 Lambda 和 SSM 终端节点,需要配置自定义 IAM 角色。
请参阅 AWS ParallelCluster 中的 AWS Identity and Access Management 角色了解默认 AWS ParallelCluster 策略的详细信息。
从 AWS 控制台中:
{ "Version": "2012-10-17", "Statement": [ { "Resource": [ "*" ], "Action": [ "ec2:DescribeVolumes", "ec2:AttachVolume", "ec2:DescribeInstanceAttribute", "ec2:DescribeInstanceStatus", "ec2:DescribeInstances", "ec2:DescribeRegions" ], "Sid": "EC2", "Effect": "Allow" }, { "Resource": [ "*" ], "Action": [ "dynamodb:ListTables" ], "Sid": "DynamoDBList", "Effect": "Allow" }, { "Resource": [ "arn:aws:sqs:<REGION>:<AWS ACCOUNT ID>:parallelcluster-*" ], "Action": [ "sqs:SendMessage", "sqs:ReceiveMessage", "sqs:ChangeMessageVisibility", "sqs:DeleteMessage", "sqs:GetQueueUrl" ], "Sid": "SQSQueue", "Effect": "Allow" }, { "Resource": [ "*" ], "Action": [ "autoscaling:DescribeAutoScalingGroups", "autoscaling:TerminateInstanceInAutoScalingGroup", "autoscaling:SetDesiredCapacity", "autoscaling:DescribeTags", "autoScaling:UpdateAutoScalingGroup", "autoscaling:SetInstanceHealth" ], "Sid": "Autoscaling", "Effect": "Allow" }, { "Resource": [ "arn:aws:dynamodb:<REGION>:<AWS ACCOUNT ID>:table/parallelcluster-*" ], "Action": [ "dynamodb:PutItem", "dynamodb:Query", "dynamodb:GetItem", "dynamodb:DeleteItem", "dynamodb:DescribeTable" ], "Sid": "DynamoDBTable", "Effect": "Allow" }, { "Resource": [ "arn:aws:s3:::<REGION>-aws-parallelcluster/*" ], "Action": [ "s3:GetObject" ], "Sid": "S3GetObj", "Effect": "Allow" }, { "Resource": [ "arn:aws:cloudformation:<REGION>:<AWS ACCOUNT ID>:stack/parallelcluster-*" ], "Action": [ "cloudformation:DescribeStacks" ], "Sid": "CloudFormationDescribe", "Effect": "Allow" }, { "Resource": [ "*" ], "Action": [ "sqs:ListQueues" ], "Sid": "SQSList", "Effect": "Allow" }, { "Effect": "Allow", "Action": [ "ssm:DescribeAssociation", "ssm:GetDeployablePatchSnapshotForInstance", "ssm:GetDocument", "ssm:DescribeDocument", "ssm:GetManifest", "ssm:GetParameter", "ssm:GetParameters", "ssm:ListAssociations", "ssm:ListInstanceAssociations", "ssm:PutInventory", "ssm:PutComplianceItems", "ssm:PutConfigurePackageResult", "ssm:UpdateAssociationStatus", "ssm:UpdateInstanceAssociationStatus", "ssm:UpdateInstanceInformation" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ssmmessages:CreateControlChannel", "ssmmessages:CreateDataChannel", "ssmmessages:OpenControlChannel", "ssmmessages:OpenDataChannel" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ec2messages:AcknowledgeMessage", "ec2messages:DeleteMessage", "ec2messages:FailMessage", "ec2messages:GetEndpoint", "ec2messages:GetMessages", "ec2messages:SendReply" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:*" ], "Resource": [ "arn:aws:s3:::pcluster-data/*" ] } ]}
复制代码
选择查看策略,然后在下一部分中输入 parallelcluster-custom-policy 字符串并选择创建策略。
现在,您可以创建角色。在左侧菜单中选择角色,然后选择创建角色。
选择 AWS 服务作为受信任实体的类型,并选择 EC2 作为将使用此角色的服务,如下所示:
创建角色
选择下一步权限以继续。
在策略选择中,选择您刚创建的 parallelcluster-custom-policy。
依次选择下一步:标签和下一步:查看。
在真实名称框中,输入 parallelcluster-custom-role 并通过选择创建角色进行确认。
使用 AWS Lambda 进行 Slurm 命令执行
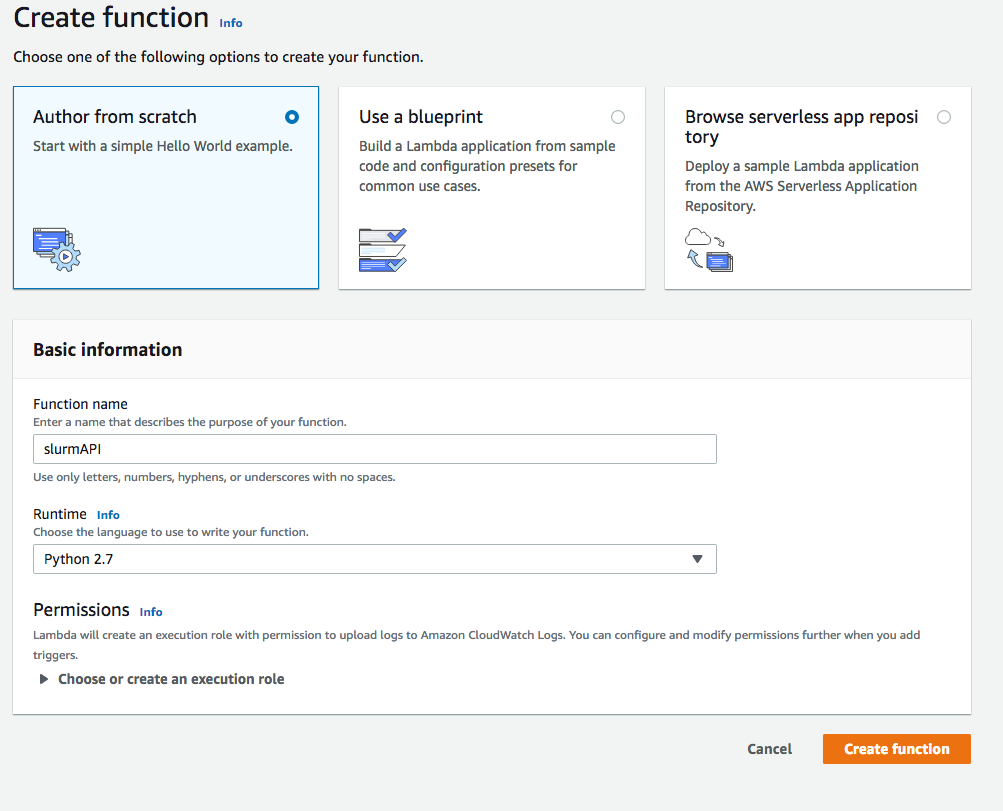
AWS Lambda 允许您在无预置或管理服务器的情况下运行代码。在此解决方案中,Lambda 用于在主节点中执行 Slurm 命令。可以按使用控制台文档创建 Lambda 函数中的说明从 AWS 控制台中创建 AWS Lambda 函数。
对于函数名称,输入 slurmAPI。
对于运行时,请输入 Python 2.7。
选择创建函数以创建函数。
下面的代码应粘贴到函数代码部分中,您可以通过进一步向下滚动页面来查看该代码。Lambda 函数使用 AWS Systems Manager 执行计划程序命令,从而防止 SSH 访问节点。请适当修改 并将 S3 存储桶名称从 pcluster-data 更新为您之前选择的名称。
import boto3import timeimport jsonimport randomimport string
def lambda_handler(event, context): instance_id = event["queryStringParameters"]["instanceid"] selected_function = event["queryStringParameters"]["function"] if selected_function == 'list_jobs': command='squeue' elif selected_function == 'list_nodes': command='scontrol show nodes' elif selected_function == 'list_partitions': command='scontrol show partitions' elif selected_function == 'job_details': jobid = event["queryStringParameters"]["jobid"] command='scontrol show jobs %s'%jobid elif selected_function == 'submit_job': script_name = ''.join([random.choice(string.ascii_letters + string.digits) for n in xrange(10)]) jobscript_location = event["queryStringParameters"]["jobscript_location"] command = 'aws s3 cp s3://%s %s.sh; chmod +x %s.sh'%(jobscript_location,script_name,script_name) s3_tmp_out = execute_command(command,instance_id) submitopts = '' try: submitopts = event["headers"]["submitopts"] except Exception as e: submitopts = '' command = 'sbatch %s %s.sh'%(submitopts,script_name) body = execute_command(command,instance_id) return { 'statusCode': 200, 'body': body } def execute_command(command,instance_id): bucket_name = 'pcluster-data' ssm_client = boto3.client('ssm', region_name="<REGION>") s3 = boto3.resource('s3') bucket = s3.Bucket(bucket_name) username='ec2-user' response = ssm_client.send_command( InstanceIds=[ "%s"%instance_id ], DocumentName="AWS-RunShellScript", OutputS3BucketName=bucket_name, OutputS3KeyPrefix="ssm", Parameters={ 'commands':[ 'sudo su - %s -c "%s"'%(username,command) ] }, ) command_id = response['Command']['CommandId'] time.sleep(1) output = ssm_client.get_command_invocation( CommandId=command_id, InstanceId=instance_id, ) while output['Status'] != 'Success': time.sleep(1) output = ssm_client.get_command_invocation(CommandId=command_id,InstanceId=instance_id) if (output['Status'] == 'Failed') or (output['Status'] =='Cancelled') or (output['Status'] == 'TimedOut'): break body = '' files = list(bucket.objects.filter(Prefix='ssm/%s/%s/awsrunShellScript/0.awsrunShellScript'%(command_id,instance_id))) for obj in files: key = obj.key body += obj.get()['Body'].read() return body
复制代码
在基本设置部分中,将 10 秒设置为超时。
点击右上角的保存以保存函数。
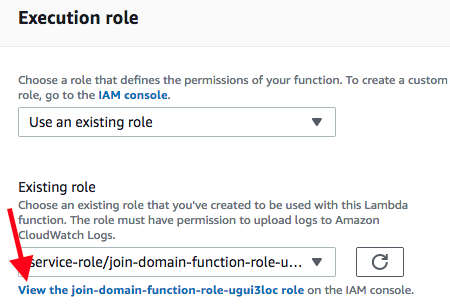
在执行角色部分中,选择在 IAM 控制台上查看 join-domain-finction-role 角色(用下图中的红色箭头表示)。
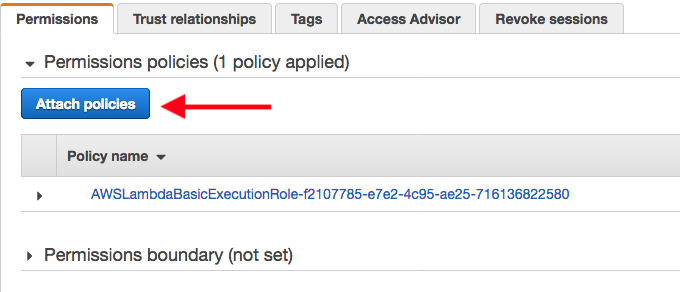
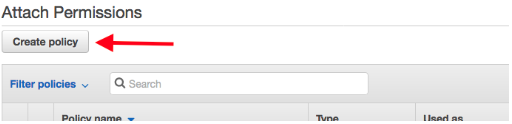
在新打开的选项卡中,依次选择附加策略和创建策略。
最后一个操作将在浏览器中打开一个新选项卡。从这个新选项卡中,选择创建策略,然后选择 Json。
适当修改 、,同时将 S3 存储桶名称从 pcluster-data 更新为您之前选择的名称。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ssm:SendCommand" ], "Resource": [ "arn:aws:ec2:<REGION>:<AWS ACCOUNT ID>:instance/*", "arn:aws:ssm:<REGION>::document/AWS-RunShellScript", "arn:aws:s3:::pcluster-data/ssm" ] }, { "Effect": "Allow", "Action": [ "ssm:GetCommandInvocation" ], "Resource": [ "arn:aws:ssm:<REGION>:<AWS ACCOUNT ID>:*" ] }, { "Effect": "Allow", "Action": [ "s3:*" ], "Resource": [ "arn:aws:s3:::pcluster-data", "arn:aws:s3:::pcluster-data/*" ] } ]}
复制代码
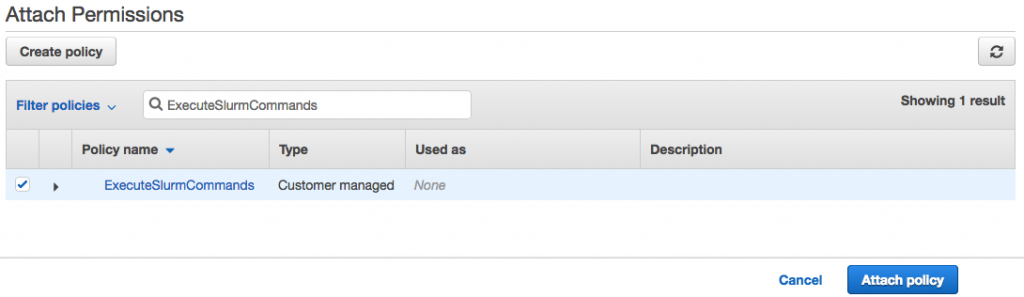
在下面的部分中,输入 ExecuteSlurmCommands 字符串的名称,然后选择创建策略。
关闭当前选项卡并移动到上一个选项卡。
刷新列表,依次选择 ExecuteSlurmCommands 策略和附加策略,如下所示:
使用 AWS API Gateway 执行 AWS Lambda 函数
The AWS API Gateway 可用于创建用作应用程序“前门”的 REST 和 WebSocket API,以从 AWS Lambda 等后端服务中访问数据、业务逻辑或功能。
登录 API Gateway 控制台。
如果这是您第一次使用 API
Gateway,您将看到向您介绍服务功能的页面。选择开始使用。在出现创建示例 API 弹出窗口时,选择确定。
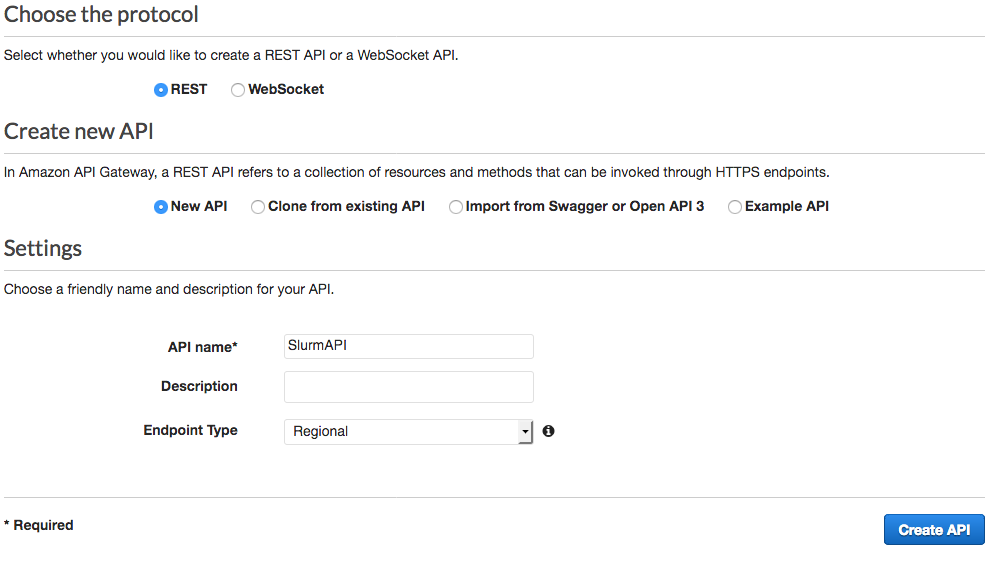
如果这不是您第一次使用 API Gateway,请选择创建 API。
如下所示创建空 API,然后选择创建 API:
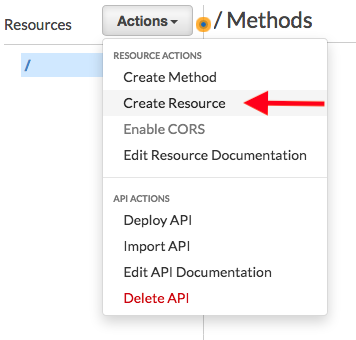
现在,您可以通过在资源树中选择根资源 (/) 并从下面所示的“操作”下拉菜单中选择创建资源来创建 slurm 资源:
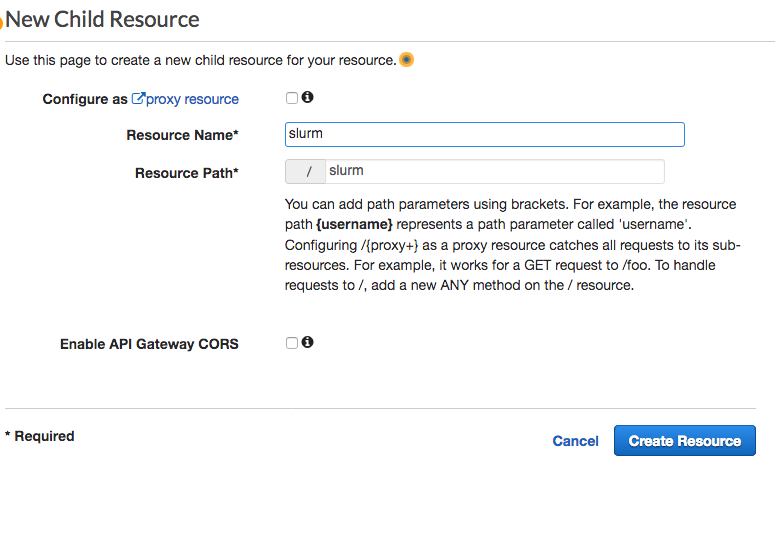
新资源可以配置如下:
配置为代理资源:未选中
资源名称:slurm
资源路径:/slurm
启用 API Gateway CORS:未选中
要确认配置,请选择创建资源。
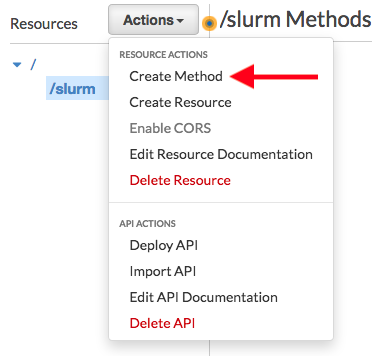
在“资源”列表中,选择 /slurm,然后如下所示选择操作和创建方法:
从下拉菜单中选择 ANY,然后选择对号图标。
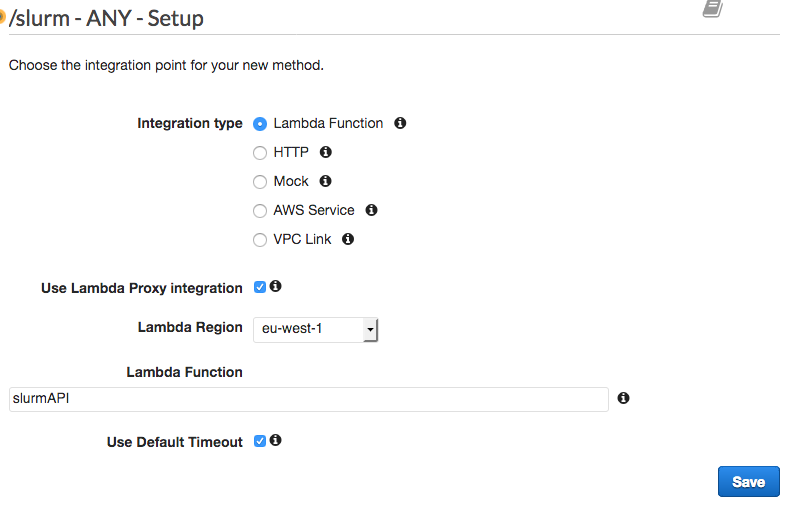
在“/slurm – ANY – 设置”部分中,使用下面的值:
集成类型:Lambda 函数
使用 Lambda 代理集成:已选中
Lambda 区域:eu-west-1
Lambda 函数:slurmAPI
使用默认超时:已选中
然后选择保存。
slurm - ANY - 设置
当系统提示添加权限到 Lambda 函数时,选择 确定。
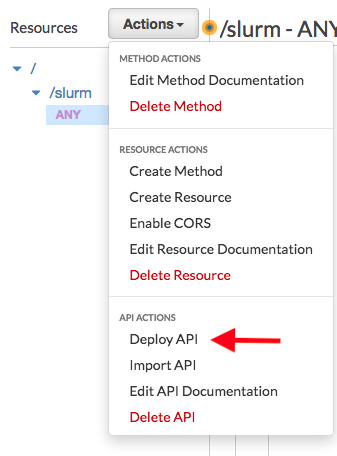
现在,您可以通过从下面所示的“操作”下拉菜单中选择部署 API 来部署 API:
对于部署阶段,选择 [新阶段],对于阶段名称,输入 slurm,然后选择部署:
部署 API
记下 API 的调用 URL – API 交互将需要此 URL。
部署集群
现在,可以使用以下命令行创建集群:
pcluster create -t slurm slurmcluster
-t slurm 指示要使用集群模板的哪个部分。
slurmcluster 是将创建的集群名称。
如需了解详情,请参阅 AWS ParallelCluster 文档。pcluster 命令行参数的具体说明可参见 AWS ParallelCluster CLI 命令。
如何与 slurm API 互动
前述步骤中创建的 slurm API 需要一些参数:
instanceid– 主节点的实例 ID。
function– 要执行的 API 函数。可接受的值包括 list_jobs、list_nodes、list_partitions、job_details 和 submit_job。
jobscript_location– 作业脚本的 s3 位置(仅当 function=submit_job 时才需要)。
submitopts– 传递给计划程序的提交参数(可选,可在 function=submit_job 时使用)。
下面是与 API 进行互动的示例:
#提交作业$ curl -s POST "https://966p4hvg04.execute-api.eu-west-1.amazonaws.com/slurm/slurm?instanceid=i-062155b00c02a6c8e&function=submit_job&jobscript_location=pcluster-data/job_script.sh" -H 'submitopts: --job-name=TestJob --partition=compute'已提交的批量作业 11
#作业列表$ curl -s POST "https://966p4hvg04.execute-api.eu-west-1.amazonaws.com/slurm/slurm?instanceid=i-062155b00c02a6c8e&function=list_jobs" JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 11 compute TestJob ec2-user R 0:14 1 ip-10-0-3-209 #作业详细信息 $ curl -s POST "https://966p4hvg04.execute-api.eu-west-1.amazonaws.com/slurm/slurm?instanceid=i-062155b00c02a6c8e&function=job_details&jobid=11" JobId=11 JobName=TestJob UserId=ec2-user(500) GroupId=ec2-user(500) MCS_label=N/A Priority=4294901759 Nice=0 Account=(null) QOS=(null) JobState=RUNNING Reason=None Dependency=(null) Requeue=1 Restarts=0 BatchFlag=1 Reboot=0 ExitCode=0:0 RunTime=00:00:06 TimeLimit=UNLIMITED TimeMin=N/A SubmitTime=2019-06-26T14:42:09 EligibleTime=2019-06-26T14:42:09 AccrueTime=Unknown StartTime=2019-06-26T14:49:18 EndTime=Unknown Deadline=N/A PreemptTime=None SuspendTime=None SecsPreSuspend=0 LastSchedEval=2019-06-26T14:49:18 Partition=compute AllocNode:Sid=ip-10-0-1-181:28284 ReqNodeList=(null) ExcNodeList=(null) NodeList=ip-10-0-3-209 BatchHost=ip-10-0-3-209 NumNodes=1 NumCPUs=1 NumTasks=1 CPUs/Task=1 ReqB:S:C:T=0:0:*:* TRES=cpu=1,node=1,billing=1 Socks/Node=* NtasksPerN:B:S:C=0:0:*:* CoreSpec=* MinCPUsNode=1 MinMemoryNode=0 MinTmpDiskNode=0 Features=(null) DelayBoot=00:00:00 OverSubscribe=OK Contiguous=0 Licenses=(null) Network=(null) Command=/home/ec2-user/C7XMOG2hPo.sh WorkDir=/home/ec2-user StdErr=/home/ec2-user/slurm-11.out StdIn=/dev/null StdOut=/home/ec2-user/slurm-11.out Power=
复制代码
API 的身份验证可以按照 API Gateway 文档中 REST API 访问权的控制和管理进行管理。
清除
当您完成计算时,可以使用以下命令销毁集群:
pcluster delete slurmcluster
其他已创建的资源可以按照官方 AWS 文档销毁:
删除 API Gateway 中的 API
删除 VPC 和子网
删除 Lambda 函数
小结
此博文已向您展示如何使用 AWS ParallelCluster 部署 Slurm 集群并将其与 AWS API Gateway 集成。
此解决方案使用 AWS API Gateway、AWS Lambda 和 AWS Systems Manager 来简化与集群的互动,无需授权访问主节点的命令行,从而可提高总体安全性。您可以通过添加其他计划程序或互动工作流程来扩展 API,并且可以与外部应用程序集成。
本文转载自 AWS 博客。
原文链接:
https://amazonaws-china.com/cn/blogs/china/aws-api-gateway-hpc-job-submission/

















评论