

GFS(Google File System)是 Google 公司开发的一款分布式文件系统。
在 2003 年,Google 发表一篇论文详细描述了 GFS 的架构。GFS,MapReduce,Bigt able 并称为 Google 的三架⻢ ⻋,推动了 Google 的高速发展。其他互联公司和开源领域纷纷模仿,构建自己的系统。可以 这么说,GFS,MapReduce,Bigt able 引领了互联网公司的分布式技术的发展。但 GFS 架构设 计并不是一个完美的架构设计,它有诸多方面的问题,一致性的欠缺就是其中的一个问题。
本文探讨一下 GFS 架构设计、分析其在一致性方面的设计不足,并且看一下一致性对分布式系统 的重要性。

我们从 GFS 的接口设计说起。
接口
GFS 采用了人们非常熟悉的接口,但是被没有实现如 POSIX 的标准接口。通常的一些操作包 括:create, delete, open, close, read, write, record append 等。create,delete,open,close 和 POSIX 的接口类似,这里就不强调说了。这里详细讲述一下 write, record append 提供的语意。
write 操作可以将任意⻓度 len 的数据写入到任意指定文件的位置 off set
record append 操作可以原子的将 len<=16MB 的数据写入到指定文件的末尾
之所以 GFS 设计这个接口,是因为 record append 不是简单的 offset 等于文件末尾的 write 操作。 record append 是具有原子特性的操作,本文后面会详细解释这个原子特性。
write 和 record append 操作都允许多个客户端并发操作。
架构
GFS 架构如下图。(摘自 GFS 的论文)
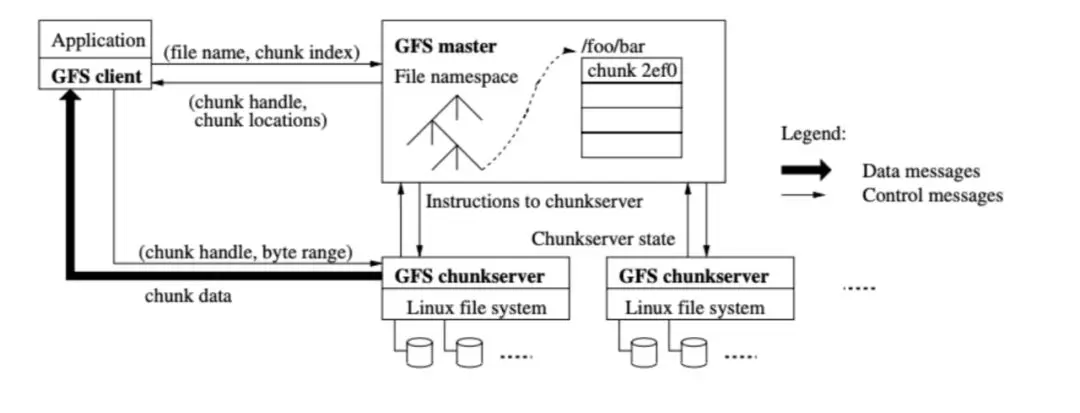
主要的架构部件有 GFS client, GFS master, GFS chunkserver。一个 GFS 集群包括:一个 master,多个 chunkserver,集群可以被多个 GFS client 访问。
GFS 客户端(GFS client)是运行在应用(Application)进程里的代码,通常以 SDK 形式 存在。
GFS 中的文件被分割成固定大小的块(chunk),每个块的⻓度是固定 64MB。GFS chunkserver 把这些 chunk 存储在本地的 Linux 文件系统中,也就是本地磁盘中。通常每个 chunck 会被保存 3 个副本(replica)。一个 chunkserver 会保存多个块,每个块都会有一个 标识叫做块柄(chunk handle)
GFS 主(mast er)维护文件系统的元数据(met adat a),包括名字空间(namespace, 也就是常规文件系统的中的文件树),访问控制信息,每个文件有哪些 chunk 构成,chunk 存储在哪个 chunkserver 上,也就是位置(locat ion)。

在这样的架构下,文件的读写基本过程简化、抽象成如下的过程:
写流程
1.client 向 mast er 发送 creat e 请求,请求包含文件路径和文件名。mast er 根据文件路径和文件 名,在名字空间里创建一个对象代表这个文件。
2.client 向 3 个 chunkserver 发送要写入到文件中的数据,每个 chunkserver 收到数据后,将数据 写入到本地的文件系统中,写入成功后,发请求给 mast er 告知 mast er 一个 chunk 写入成功, 与此同时告知 client 写入成功。
3.mast er 收到 chunkserver 写入成功后,记录这个 chunk 与机器之间的对应关系,也就是 chunk 的位置。
4.client 确认 3 个 chunkserver 都写成功后,本次写入成功。
这个写流程是一个高度简化抽象的流程,实际的写流程是一个非常复杂的流程,要考虑到写入 类型(即,是随机写还是尾部追加),还要考虑并发写入,后面我们继续详细的描述写流程, 解释 GFS 是如何处理不同的写入类型和并发写入的。

读流程
1.应用发起读操作,指定文件路径,偏移量(off set )
2.client 根据固定的 chunk 大小(也即 64MB),计算出数据在第几个 chunk 上,也就是 chunk 索 引号(index)
3.client 向 mast er 发送一个请求,包括文件名和索引号,mast er 返回 3 个副本在哪 3 台机器上, 也就是副本位置(location of replica)。
4.client 向其中一个副本的机器发送请求,请求包换块柄和字节的读取范围。
5.chunkserver 根据块柄和读取范围从本地的文件系统读取数据返回给 client
这个读流程未做太多的简化和抽象,但实际的读流程还会做一些优化,这些优化和本文主题关 系不大就不展开了。

写流程详述
我们详细的讲一下写入流程的几个细节。
1.名字空间管理(namespace management)和锁保护(locking)
写入流程需要向主发送 creat e 这样请求,来操作保存在主上的名字空间。 如果有多个客户端同时进行写入操作,那么这些客户端也会同时操作向主发送 creat e 请求。主 在同一时间收到多个请求,通过加锁的方式,防止多个客户端同时修改同一个文件的元数据。
2.租约(Lease)
client 需要向 3 个副本写入数据,在并发的情况下会有多个 client 同时向 3 个副本写入数据。GFS 需要一个规则来管理这些数据的写入。 这个规则简单来讲,每个 chunk 都只有一个副本来管理多个 client 的并发写入。也就是说,对 于一个 chunk,mast er 会授予其中一个副本一个租约(lease),具有租约的副本来管理所有要写 入到这个 chunk 的数据写入,这个具有租约的副本称之为首要副本(primary)。其他的副本称之 为二级副本(secondary)
3.变更次序(Mutation Order)
将对文件的写入(不管是在任意位置的写入,还是在末尾追加)称之为变更(Mut at ion)。 Primary 管理所有 client 的并发请求,让所有的请求按照一定顺序(Order)应用到 chunk 上。

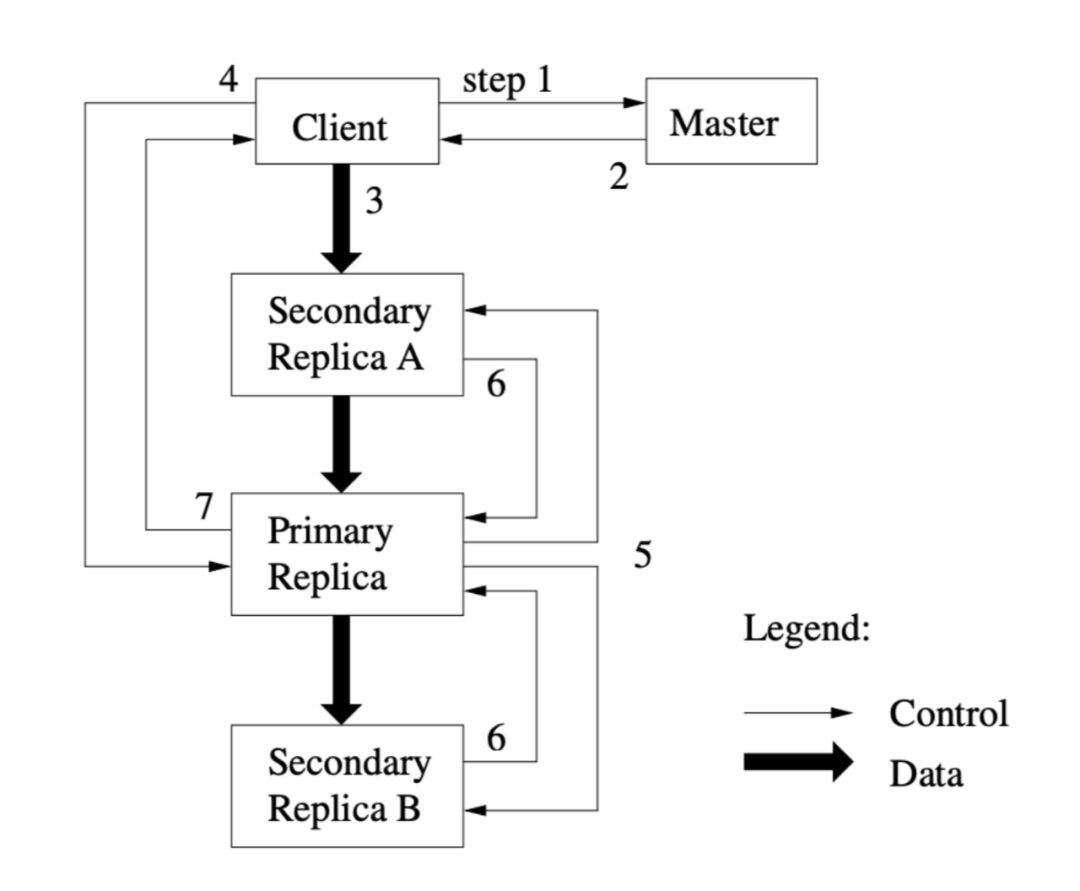
4.基本变更流程
1).client 询问 mast er 哪个 chunkserver 持有这个 chunk 的 lease,以及其他的副本的位置。如果 没有副本持有 lease,mast er 挑选一个副本,通知这副本它持有 lease。
2).mast er 回复 client ,告述客户端首要副本的位置,和二级副本的位置。客户端联系首要副 本,如果首要副本无响应或者回复客户端它不是首要副本,则客户端重新联系主。
3).客户端向所有的副本推送数据。客户端可以以任意的顺序推送。每个 chunkserver 会缓存这 些数据在缓冲区中。
4).当所有的副本都回复说已经收到数据后,客户端发送一个写入请求(write request)给首 要副本,这个请求里标识着之前写入的数据。首要副本收到请求后,会给写入分配一个连续的 编号,首要副本会按照这个编号的顺序,将数据写入到本地磁盘。
5).首要副本将这个带有编号写入请求转发给其他二级副本,二级副本也会按照编号的顺序, 将数据写入本地,并且回复首要副本数据写入成功。
6).当首要副本收到所有二级副本的回复时,说明这次写入操作成功。
7).首要副本回复客户端写入成功。在任意一个副本上遇到的任意错误,都会报告给客户端失败。
前面讲的 writ e 接口就是按照这个基本流程进行的。 下图描述了这个基本过程。(摘自 GFS 的论文)
5.跨边界变更
如果一次写入的数据量跨过了一个块的边界,那么客户端会把这次写入分解成向多个 chunk 的 多个写入。

6.原子记录追加(Atomic Record Appends)
Record Appends 在论文中被称之为原子记录追加(Atomic Record Appends),这个接口也 遵循基本的变更流程,有一些附加的逻辑:客户端把数据推送给所有的副本后,客户端发请求 给首要副本,首要副本收到写入请求后,会检查如果把这个 record 附加在尾部,会不会超出块 的边界,如果超过了边界,它把块中剩余的空间填充满(这里填充什么并不重要,后面我们会 解释这块),并且让其他的二级副本做相同的事,再告述客户端这次写入应该在下一块重试。 如果记录适合块剩余的空间,则首要副本把记录追加尾部,并且告述其他二级副本写入数据在 同样的位置,最后通知客户端操作成功。

原子性
讲完架构和读写流程,我们开始分析 GFS 的一致性,首先从原子性开始分析。
Write 和 Atomic Record Append 的区别 前面讲过,如果一次写入的数量跨越了块的边界,那么会分解成多个操作,writ e 和 record append 在处理数据跨越边界时的行为是不同的。我们举例 2 个例子来说明一下。
例子 1,文件目前有 2 个 chunk,分别是 chunk1, chunk2。
Client 1 要在 54MB 的位置写入 20MB 数据。这写入跨越了边界,要分解成 2 个操作,第一个操 作写入 chunk1 最后 10 MB,第二个操作写入 chunk2 的开头 10MB。Client 2 也要在 54MB 的位置写入 20MB 的数据。这个写入也跨越边界,也要分解为 2 个操作, 作为第三个操作写入 chunk1 最后 10 MB,作为第四个操作写入 chunk2 的开头 10MB。
2 个客户端并发写入数据,那么第一个操作和第三个操作在 chunk1 上就是并发执行的,第二个 操作和第四个操作在 chunk2 上并发执行,如果 chunk1 的先执行第一操作再执行第三个操作, chunk2 先执行第四个操作再执行第二个操作,那么最后,在 chunk1 上会保留 client 1 的写入的 数据,在 chunk2 上保留了 client 2 的写入的数据。虽然 client 1 和 client 2 的写入都成功了,但最 后既不是 client 1 想要的结果,也不是 client 2 想要的结果。最后的结果是 client 1 和 client 2 写入 的混合。对于 client 1 和 client 2 来说,他们操作都不是原子的。
例子 2,文件目前有 2 个 chunk,分别是 chunk1, chunk2。
Client 要在 54MB 的位置写入 20MB 数据。这写入跨越了边界,要分解成 2 个操作,第一个操作 写入 chunk1 最后 10 MB,第二个操作写入 chunk2 的开头 10MB。chunk1 执行第一个操作成功 了,chunk2 执行第二个操作失败了,也就是写入的这部分数据,一部分是成功的,一部分是 失败的,这也不是原子操作。
接下来看 record append。由于 record append 最多能写入 16MB 的数据,并且当写入的数据量 超过块的剩余空间时,剩余的空间会被填充,这次写入操作会在下个块重试,这 2 点保证了 record append 操作只会在一个块上生效。这样就避免了跨越边界分解成多个操作,从而也就 避免了,写入的数据一部分成功一部分失败,也避免了并发写入数据混合在一起,这 2 种非原子性的行为。

GFS 原子性的含义
所以,GFS 的原子性不是指多副本之间原子性,而是指发生在多 chunk 上的多个操作的的原子性。可以得出这样的推论,如果 Writ e 操作不跨越边界,那么没有跨越边界的 writ e 操作也满足 GFS 所说的原子性。
GFS 多副本不具有原子性
GFS 一个 chunk 的副本之间是不具有原子性的,不具有原子性的副本复制,它的行为是:
一个写入操作,如果成功,他在所有的副本上都成功,如果失败,则有可能是一部分副本 成功,而另外一部分失败。
在这样的行为如下,失败是这样处理的:
如果是 write 失败,那么客户端可以重试,直到 write 成功,达到一致的状态。但是如果在 重试达到成功以前出现宕机,那么就变成了永久的不一致了。
Record Append 在写入失败后,也会重试,但是与 writ e 的重试不同,不是在原有的 off set 上重试,而是接在失败的记录后面重试,这样 Record Append 留下的不一致是永久的不一 致,并且还会有重复问题,如果一条记录在一部分副本上成功,在另外一部分副本上失 败,那么这次 Record Append 就会报告给客户端失败,并且让客户端重试,如果重试后成 功,那么在某些副本上,这条记录就会成功的写入 2 次。
我们可以得出,Record Append 保证是至少一次的原子操作(at least once atomic)。

一致性
GFS 把自己的一致性称为松弛的一致性模型(relaxed consistency model)。这个模型分析元 数据的一致性和文件数据的一致性,松弛主要是指文件数据具有松弛的一致性。
元数据的一致性
元数据的操作都是由单一的 mast er 处理的,并且操作通过锁保护,所以是保证原子的,也保 证正确性的。
文件数据的一致性
在说明松弛一致性模型之前,我们先看看这个模型中的 2 个概念。对于一个文件中的区域:
如果无论从哪个副本读取,所有的客户端都能总是看到相同的数据,那么就叫一致的 (consist ent );
在一次数据变更后,这个文件的区域是一致的,并且客户端可以看到这次数据变更写入的 所有数据,那么就叫界定的(defined)。
1.在没有并发的情况下,写入不会有相互干扰,成功的写入是界定的,那么必然也就是一致的
2.在有并发的情况下,成功的写入是一致的,但不是界定的,也就是我们前面所举的例子 2。
3.如果写入失败,那么副本之间就会出现不一致。
4.Record Append 能够保证是界定的,但是在界定的区域之间夹杂着一些不一致的区域。 Record Append 会填充数据,不管每个副本是否填充相同的数据,这部分区域都会认为是 inconsist ent 的。

如何适应松弛的一致性模型
这种松弛的一致性模型,实际上是一种不能保证一致性的模型,或者更准确的说是一致性的数 据中间夹杂不一致数据。
这些夹杂其中的不一致数据,对应用来说是不可接受的。在这种一致性下,应该如何使用 GFS 那?GFS 的论文中,给出了这样几条使用 GFS 的建议:依赖追加(append)而不是依赖覆盖 (overwrite),设立检查点(checkpointing),写入自校验(write self-validating),自记录标识 (self-identifying records)。
使用方式 1:只有单个写入的情况下,按从头到尾的方式生成文件。
方法 1.1:先临时写入一个文件,再全部数据写入成功后,将文件改名成一个永久的名 字,文件的读取方只能通过永久的文件名访问到这个文件。
方法 1.2:写入方按一定的周期,写入数据,写入成功后,记录一个写入进度检查点 (checkpoint ),这个检查点包括应用级的校验数(checksum)。读取方只去校验、处理检查点之前的数据。即便写入方出现宕机的情况,重启后的写入方或者新的写入方,会 从检查点开始,继续重新写入数据,这样就修复了不一致的数据。
使用方式 2:多个写入并发向一个文件尾部追加,这个使用方式就像是一个生产消费型的消息 队列,多个生产者向一个文件尾部追加消息,消费者从文件读取消息
方法 2.1:使用 record append 接口,保证数据至少被成功的写入一次。但是应用需要应对 不一致数据,和重复数据。
为了校验不一致数据,给每个记录添加校验数(checksum),读取方通过校验数识别 出不一致的数据,并且丢弃不一致的数据。
如果应用读取数据没有幂等处理,那么应用就需要过滤掉重复数据。写入方写入记录时 额外写入一个唯一的标识(ident ifier),读取方读取数据后通过标识辨别之前是否已经 处理过这个标识的数据。

GFS 的设计哲学
可以看出基于 GFS 的应用需要通过一些特殊的手段来应对 GFS 松弛的一致性模型带来的各种问 题。GFS 的一致性保证对于使用者是非常不友好的,很多人第一次看到这样的一致性保证都是 比较吃惊的。
那么 GFS 为什么要设计这样的一致性模型那?GFS 在架构上选择这样的设计有它自己的设计哲 学。GFS 追求的是简单、够用的原则。GFS 主要要解决的问题是如何使用廉价的服务器存储海 量的数据,并且达到非常高的吞吐量(GFS 非常好的做到了这 2 点,但不是本文的主题,这里 就不展开了),并且文件系统本身的实现要简单,能够快速的实现出来(GFS 的开发者在开发 完 GFS 之后,很快就去开发 BigT able 了)。GFS 很好的完成了完成了这样的目标。但是留下了 一致性问题,给使用者带来的负担。但是在 GFS 应用的前期,一致性不是问题,GFS 的主要使 用者(BigT able)就是 GFS 开发者,他们深知应该如何使用 GFS,这种不一致在 BigT able 中被 很好屏蔽掉(采用上面所说的方法),BigT able 提供了很好的一致性保证。
但是随着 GFS 使用的不断深入,GFS 简单够用的架构开始带来很多问题,一致性问题仅仅是其 中的一个。主导了 GFS 很⻓时间的 Leader Sean Quinlan 在一次采访中,详细说明了在 GFS 度 过了应用的初期之后,这种简单的架构带来的各种问题[1]。
开源分布式文件系统 HDFS,清晰的看到了 GFS 的一致性模型给使用者带来的不方便,坚定地 摒弃了 GFS 的一致性模型,提供了很好的一致性保证。HDFS 达到了怎样的一致性,这里就不 在展开了,另外再做详细的讨论。

总之,保证一直性对于分布式文件系统,甚至所有的分布式系统都是很重要的。
本文转载自技术锁话公众号。
原文链接:https://mp.weixin.qq.com/s/GuJ6VqZJy3ONaVOWvQT9kg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论