图数据库已经越来越被人们熟知,同时也在许多企业中得到了应用,但是由于市面上没有统一的图查询语言标准,所以有部分开发者对于不同图数据库的用法存在着疑问。因此本文作者对市面上主流的几款图数据库进行了一番分析,并以查询操作为例进行深入介绍。
文章的开头我们先来看下什么是图数据库,根据维基百科的定义:图数据库是使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。
虽然和关系型数据库存储的结构不同(关系型数据库为表结构,图数据库为图结构),但不计各自的性能问题,关系型数据库可以通过递归查询或者组合其他 SQL 语句(Join)完成图查询语言查询节点关系操作。得益于 1987 年 SQL 成为国际标准化组织(ISO)标准,关系型数据库行业得到了很好的发展。同 60、70 年代的关系型数据库类似,图数据库这个领域的查询语言目前也没有统一标准,虽然 19 年 9 月经过国际 SQL 标准委员会投票表决,决定将图查询语言(Graph Query Language)纳为一种新的数据库查询语言,但 GQL 的制定仍需要一段时间。
鉴于市面上没有统一的图查询语言标准,在本文中我们选取市面上主流的几款图查询语言来分析一波用法,由于篇幅原因本文旨在简单介绍图查询语言和常规用法,更详细的内容将在进阶篇中讲述。
图查询语言·介绍
图查询语言 Gremlin
Gremlin 是 Apache ThinkerPop 框架下的图遍历语言。Gremlin 可以是声明性的也可以是命令性的。虽然 Gremlin 是基于 Groovy 的,但具有许多语言变体,允许开发人员以 Java、JavaScript、Python、Scala、Clojure 和 Groovy 等许多现代编程语言原生编写 Gremlin 查询。
支持图数据库:Janus Graph、InfiniteGraph、Cosmos DB、DataStax Enterprise(5.0+) 、Amazon Neptune
图查询语言 Cypher
Cypher 是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询,和 SQL 很相似,Cypher 语言的关键字不区分大小写,但是属性值,标签,关系类型和变量是区分大小写的。
支持图数据库: Neo4j、RedisGraph、AgensGraph
图查询语言 nGQL
nGQL 是一种类 SQL 的声明型的文本查询语言,nGQL 同样是关键词大小写不敏感的查询语言,目前支持模式匹配、聚合运算、图计算,可无嵌入组合语句。
支持图数据库:Nebula Graph
图查询语言·术语篇
在比较这 3 个图查询语言之前,我们先来看看他们各自的术语,如果你翻阅他们的文档会经常见到下面这些“关键字”,在这里我们不讲用法,只看这些图数据库常用概念在这 3 个图数据库文档中的叫法。
| 术语 | Gremlin | Cypher | nGQL |
|---|
| 点 | Vertex | Node | Vertex |
| 边 | Edge | Relationship | Edge |
| 点类型 | Label | Label | Tag |
| 边类型 | label | RelationshipType | edge type |
| 点 ID | vid | id(n) | vid |
| 边 ID | eid | id® | 无 |
| 插入 | add | create | insert |
| 删除 | drop | delete | delete / drop |
| 更新属性 | setProperty | set | update |
我们可以看到大体上对点和边的叫法类似,只不过 Cypher 中直接使用了 Relationship 关系一词代表边。其他的术语基本都非常直观。
图查询语言·实操篇
上面说了一通术语之类的“干货”之后,是时候展示真正的技术了——来个具体一点的例子,在具体的例子中我们将会分析 Gremlin、Cypher、nGQL 的用法不同。
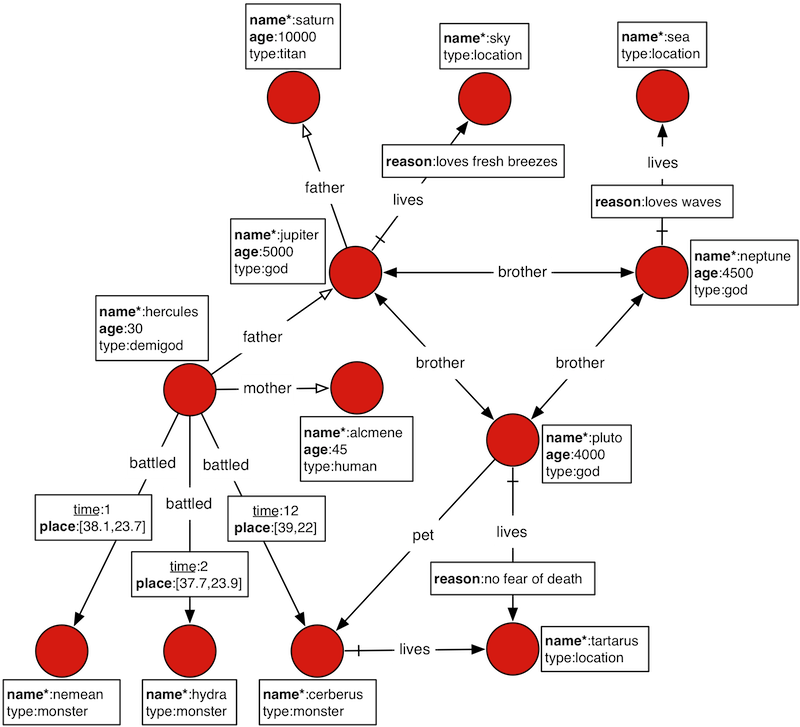
示例图:The Graphs of Gods
实操示例使用了 Janus Graph 的示例图 The Graphs of Gods。该图结构如下图所示,描述了罗马万神话中诸神关系。
插入数据
# 插入点## nGQLnebula> INSERT VERTEX character(name, age, type) VALUES hash("saturn"):("saturn", 10000, "titan"), hash("jupiter"):("jupiter", 5000, "god");## Gremlingremlin> saturn = g.addV("character").property(T.id, 1).property('name', 'saturn').property('age', 10000).property('type', 'titan').next();==>v[1]gremlin> jupiter = g.addV("character").property(T.id, 2).property('name', 'jupiter').property('age', 5000).property('type', 'god').next();==>v[2]gremlin> prometheus = g.addV("character").property(T.id, 31).property('name', 'prometheus').property('age', 1000).property('type', 'god').next();==>v[31]gremlin> jesus = g.addV("character").property(T.id, 32).property('name', 'jesus').property('age', 5000).property('type', 'god').next();==>v[32]## Cyphercypher> CREATE (src:character {name:"saturn", age: 10000, type:"titan"})cypher> CREATE (dst:character {name:"jupiter", age: 5000, type:"god"})# 插入边## nGQLnebula> INSERT EDGE father() VALUES hash("jupiter")->hash("saturn"):();## Gremlingremlin> g.addE("father").from(jupiter).to(saturn).property(T.id, 13);==>e[13][2-father->1]## Cyphercypher> CREATE (src)-[rel:father]->(dst)
复制代码
在数据插入这块,我们可以看到 nGQL 使用 INSERT VERTEX 插入点,而 Gremlin 直接使用类函数的 g.addV() 来插入点,Cypher 使用 CREATE 这个 SQL 常见关键词来创建插入的点。
在点对应的属性值方面,nGQL 通过 VALUES 关键词来赋值,Gremlin 则通过操作 .property() 进行对应属性的赋值,Cypher 更直观直接在对应的属性值后面跟上想对应的值。
在边插入方面,可以看到和点的使用语法类似,只不过在 Cypher 和 nGQL 中分别使用 -[]-> 和 **-> 来表示关系,而 Gremlin 则用 to() **关键词来标识指向关系,在使用这 3 种图查询语言的图数据库中的边均为有向边,下图左边为有向边,右边为无向边。
删除数据
# nGQLnebula> DELETE VERTEX hash("prometheus");# Gremlingremlin> g.V(prometheus).drop();# Cyphercypher> MATCH (n:character {name:"prometheus"}) DETACH DELETE n
复制代码
这里,我们可以看到大家的删除关键词都是类似的:Delete 和 Drop,不过这里需要注意的是上面术语篇中提过 nGQL 中删除操作对应单词有 Delete 和 Drop ,在 nGQL 中 Delete 一般用于点边,Drop 用于 Schema 删除,这点和 SQL 的设计思路是一样的。
更新数据
# nGQLnebula> UPDATE VERTEX hash("jesus") SET character.type = 'titan';# Gremlingremlin> g.V(jesus).property('age', 6000);==>v[32]# Cyphercypher> MATCH (n:character {name:"jesus"}) SET n.type = 'titan';
复制代码
可以看到 Cypher 和 nGQL 都使用 SET 关键词来设置点对应的类型值,只不过 nGQL 中多了 UPDATE 关键词来标识操作,Gremlin 的操作和查看点操作类似,只不过增加了变更 property 值操作,这里我们注意到的是,Cypher 中常见的一个关键词便是 MATCH,顾名思义,它是一个查询关键词,它会去选择匹配对应条件下的点边,再进行下一步操作。
查看数据
# nGQLnebula> FETCH PROP ON character hash("saturn");===================================================| character.name | character.age | character.type |===================================================| saturn | 10000 | titan |---------------------------------------------------# Gremlingremlin> g.V(saturn).valueMap();==>[name:[saturn],type:[titan],age:[10000]]# Cyphercypher> MATCH (n:character {name:"saturn"}) RETURN properties(n) ╒════════════════════════════════════════════╕ │"properties(n)" │ ╞════════════════════════════════════════════╡ │{"name":"saturn","type":"titan","age":10000}│ └────────────────────────────────────────────┘
复制代码
在查看数据这块,Gremlin 通过调取 valueMap() 获得对应的属性值,而 Cypher 正如上面更新数据所说,依旧是 MATCH 关键词来进行对应的匹配查询再通过 RETURN 返回对应的数值,而 nGQL 则对 saturn 进行 hash 运算得到对应 VID 之后去获取对应 VID 的属性值。
查询 hercules 的父亲
# nGQLnebula> LOOKUP ON character WHERE character.name == 'hercules' | \ -> GO FROM $-.VertexID OVER father YIELD $$.character.name;=====================| $$.character.name |=====================| jupiter |---------------------# Gremlingremlin> g.V().hasLabel('character').has('name','hercules').out('father').values('name');==>jupiter# Cyphercypher> MATCH (src:character{name:"hercules"})-[:father]->(dst:character) RETURN dst.name ╒══════════╕ │"dst.name"│ ╞══════════╡ │"jupiter" │ └──────────┘
复制代码
查询父亲,其实是一个查询关系/边的操作,这里不做赘述,上面插入边的时候简单介绍了 Gremlin、Cypher、nGQL 这三种图数据库是各自用来标识边的关键词和操作符是什么。
查询 hercules 的祖父
# nGQLnebula> LOOKUP ON character WHERE character.name == 'hercules' | \ -> GO 2 STEPS FROM $-.VertexID OVER father YIELD $$.character.name;=====================| $$.character.name |=====================| saturn |---------------------# Gremlingremlin> g.V().hasLabel('character').has('name','hercules').out('father').out('father').values('name');==>saturn# Cyphercypher> MATCH (src:character{name:"hercules"})-[:father*2]->(dst:character) RETURN dst.name ╒══════════╕ │"dst.name"│ ╞══════════╡ │"saturn" │ └──────────┘
复制代码
查询祖父,其实是一个查询对应点的两跳关系,即:父亲的父亲,我们可以看到 Gremlin 使用了两次 out() 来表示为祖父,而 nGQL 这里使用了 |(Pipe 管道)的概念,用于子查询。在两跳关系处理上,上面说到 Gremlin 是用了 2 次 out(),而 Cypher、nGQL 则引入了 step 数的概念,分别对应到查询语句的 GO 2 STEP 和 [:father *2],相对来说 Cypher、nGQL 这样书写更优雅。
查询年龄大于 100 的人物
# nGQLnebula> LOOKUP ON character WHERE character.age > 100 YIELD character.name, character.age;=========================================================| VertexID | character.name | character.age |=========================================================| 6761447489613431910 | pluto | 4000 |---------------------------------------------------------| -5860788569139907963 | neptune | 4500 |---------------------------------------------------------| 4863977009196259577 | jupiter | 5000 |---------------------------------------------------------| -4316810810681305233 | saturn | 10000 |---------------------------------------------------------# Gremlingremlin> g.V().hasLabel('character').has('age',gt(100)).values('name');==>saturn==>jupiter==>neptune==>pluto# Cyphercypher> MATCH (src:character) WHERE src.age > 100 RETURN src.name ╒═══════════╕ │"src.name" │ ╞═══════════╡ │ "saturn" │ ├───────────┤ │ "jupiter" │ ├───────────┤ │ "neptune" │ │───────────│ │ "pluto" │ └───────────┘
复制代码
这个是一个典型的查询语句,找寻符合特定条件的点并返回结果,在 Cypher 和 nGQL 中用 WHRER 进行条件判断,而 Gremlin 延续了它的“编程风”用 gt(100) 表示年大于龄 100 的这个筛选条件,延伸下 Gremlin 中 eq() 则表示等于这个查询条件。
从一起居住的人物中排除 pluto 本人
# nGQLnebula> GO FROM hash("pluto") OVER lives YIELD lives._dst AS place | GO FROM $-.place OVER lives REVERSELY WHERE \$$.character.name != "pluto" YIELD $$.character.name AS cohabitants;===============| cohabitants |===============| cerberus |---------------# Gremlingremlin> g.V(pluto).out('lives').in('lives').where(is(neq(pluto))).values('name');==>cerberus# Cyphercypher> MATCH (src:character{name:"pluto"})-[:lives]->()<-[:lives]-(dst:character) RETURN dst.name ╒══════════╕ │"dst.name"│ ╞══════════╡ │"cerberus"│ └──────────┘
复制代码
这是一个沿指定点 Pluto 反向查询指定边(居住)的操作,在反向查询中,Gremlin 使用了 in 来表示反向关系,而 Cypher 则更直观的将指向箭头反向变成 <- 来表示反向关系,nGQL 则用关键词 REVERSELY 来标识反向关系。
Pluto 的兄弟们居住在哪
# which brother lives in which place?## nGQLnebula> GO FROM hash("pluto") OVER brother YIELD brother._dst AS god | \GO FROM $-.god OVER lives YIELD $^.character.name AS Brother, $$.location.name AS Habitations;=========================| Brother | Habitations |=========================| jupiter | sky |-------------------------| neptune | sea |-------------------------## Gremlingremlin> g.V(pluto).out('brother').as('god').out('lives').as('place').select('god','place').by('name');==>[god:jupiter, place:sky]==>[god:neptune, place:sea]## Cyphercypher> MATCH (src:Character{name:"pluto"})-[:brother]->(bro:Character)-[:lives]->(dst)RETURN bro.name, dst.name ╒═════════════════════════╕ │"bro.name" │"dst.name"│ ╞═════════════════════════╡ │ "jupiter" │ "sky" │ ├─────────────────────────┤ │ "neptune" │ "sea" │ └─────────────────────────┘
复制代码
这是一个通过查询指定点 Pluto 查询指定边 brother 后再查询指定边 live 的查询,相对来说不是很复杂,这里就不做解释说明了。
最后,本文只是对 Gremlin、Cypher、nGQL 等 3 个图查询语言进行了简单的介绍,更复杂的语法将在本系列的后续文章中继续,欢迎在论坛留言交流。
附 录

















评论