

SOFARegistry 是蚂蚁金服开源的具有承载海量服务注册和订阅能力的、高可用的服务注册中心,最早源自于淘宝的初版 ConfigServer,在支付宝/蚂蚁金服的业务发展驱动下,近十年间已经演进至第五代。
本文为《剖析 | SOFARegistry 框架》最后一篇,本篇作者 404P(花名:岩途)。《剖析 | SOFARegistry 框架》系列由 SOFA 团队和源码爱好者们出品,项目代号:<SOFARegistry:Lab/>,文末包含往期系列文章。
GitHub 地址:
https://github.com/sofastack/sofa-registry
1 前言
在微服务架构体系下,服务注册中心致力于解决微服务之间服务发现的问题。在服务数量不多的情况下,服务注册中心集群中每台机器都保存着全量的服务数据,但随着蚂蚁金服海量服务的出现,单机已无法存储所有的服务数据,数据分片成为了必然的选择。数据分片之后,每台机器只保存一部分服务数据,节点上下线就容易造成数据波动,很容易影响应用的正常运行。本文通过介绍 SOFARegistry 的分片算法和相关的核心源码来展示蚂蚁金服是如何解决上述问题的。
2 服务注册中心简介
在微服务架构下,一个互联网应用的服务端背后往往存在大量服务间的相互调用。例如服务 A 在链路上依赖于服务 B,那么在业务发生时,服务 A 需要知道服务 B 的地址,才能完成服务调用。而分布式架构下,每个服务往往都是集群部署的,集群中的机器也是经常变化的,所以服务 B 的地址不是固定不变的。如果要保证业务的可靠性,服务调用者则需要感知被调用服务的地址变化。
图 1 微服务架构下的服务寻址
既然成千上万的服务调用者都要感知这样的变化,那这种感知能力便下沉成为微服务中一种固定的架构模式:服务注册中心。
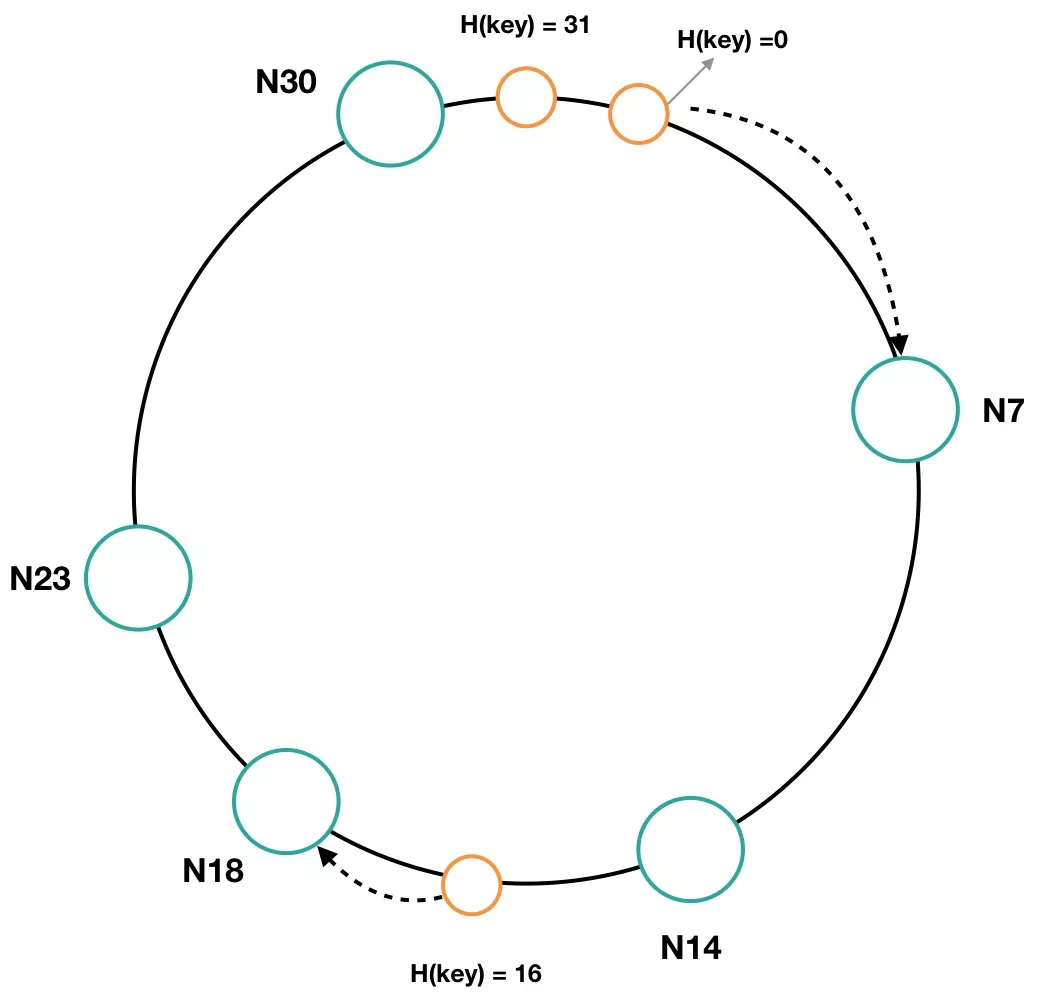
图 2 服务注册中心
服务注册中心里,有服务提供者和服务消费者两种重要的角色,服务调用方是消费者,服务被调方是提供者。对于同一台机器,往往兼具两者角色,既被其它服务调用,也调用其它服务。服务提供者将自身提供的服务信息发布到服务注册中心,服务消费者通过订阅的方式感知所依赖服务的信息是否发生变化。
3 SOFARegistry 总体架构
SOFARegistry 的架构中包括 4 种角色:Client、Session、Data、Meta,如图 3 所示:
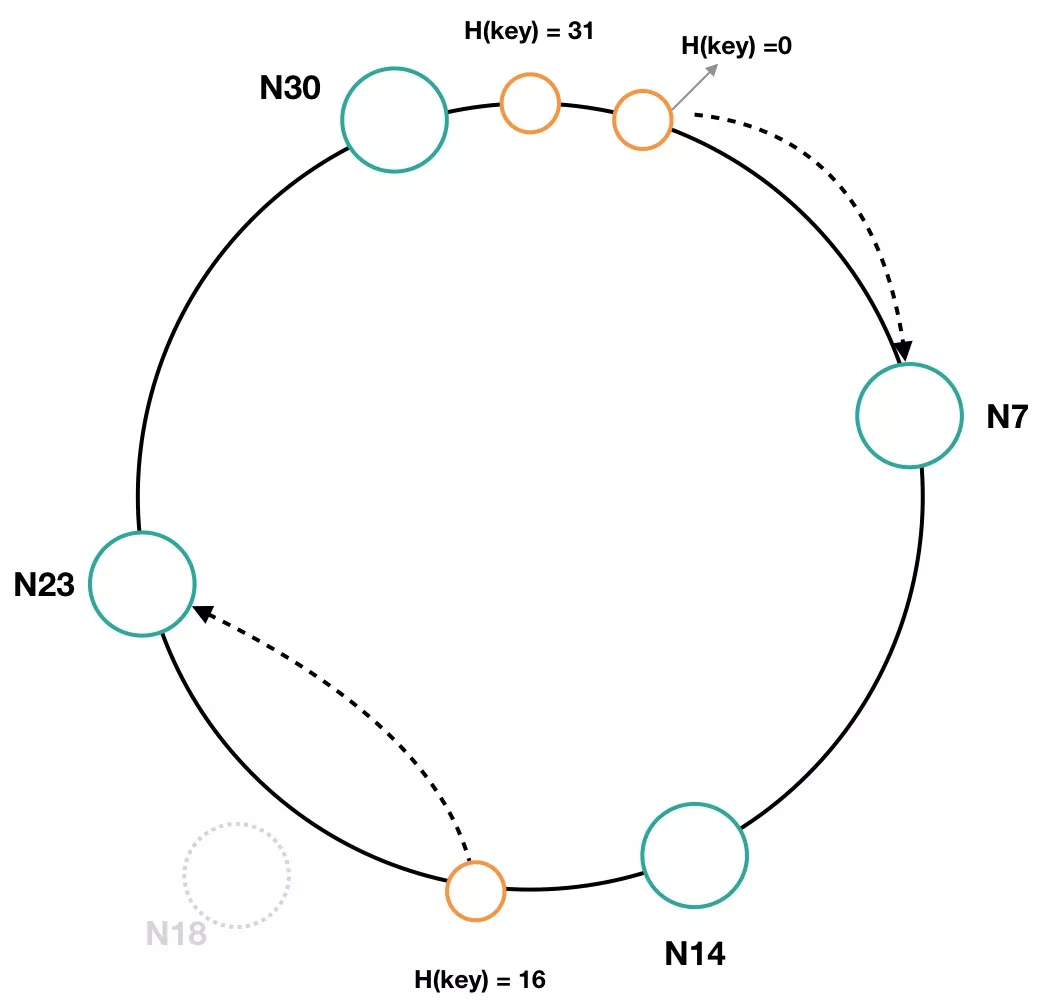
图 3 SOFARegistry 总体架构
Client 层
应用服务器集群。Client 层是应用层,每个应用系统通过依赖注册中心相关的客户端 jar 包,通过编程方式来使用服务注册中心的服务发布和服务订阅能力。
Session 层
Session 服务器集群。顾名思义,Session 层是会话层,通过长连接和 Client 层的应用服务器保持通讯,负责接收 Client 的服务发布和服务订阅请求。该层只在内存中保存各个服务的发布订阅关系,对于具体的服务信息,只在 Client 层和 Data 层之间透传转发。Session 层是无状态的,可以随着 Client 层应用规模的增长而扩容。
Data 层
数据服务器集群。Data 层通过分片存储的方式保存着所用应用的服务注册数据。数据按照 dataInfoId(每一份服务数据的唯一标识)进行一致性 Hash 分片,多副本备份,保证数据的高可用。下文的重点也在于随着数据规模的增长,Data 层如何在不影响业务的前提下实现平滑的扩缩容。
Meta 层
元数据服务器集群。这个集群管辖的范围是 Session 服务器集群和 Data 服务器集群的服务器信息,其角色就相当于 SOFARegistry 架构内部的服务注册中心,只不过 SOFARegistry 作为服务注册中心是服务于广大应用服务层,而 Meta 集群是服务于 SOFARegistry 内部的 Session 集群和 Data 集群,Meta 层能够感知到 Session 节点和 Data 节点的变化,并通知集群的其它节点。
4 SOFARegistry 如何突破单机存储瓶颈
在蚂蚁金服的业务规模下,单台服务器已经无法存储所有的服务注册数据,SOFARegistry 采用了数据分片的方案,每台机器只保存一部分数据,同时每台机器有多副本备份,这样理论上可以无限扩容。根据不同的数据路由方式,常见的数据分片主要分为两大类:范围分片和 Hash(哈希)分片。
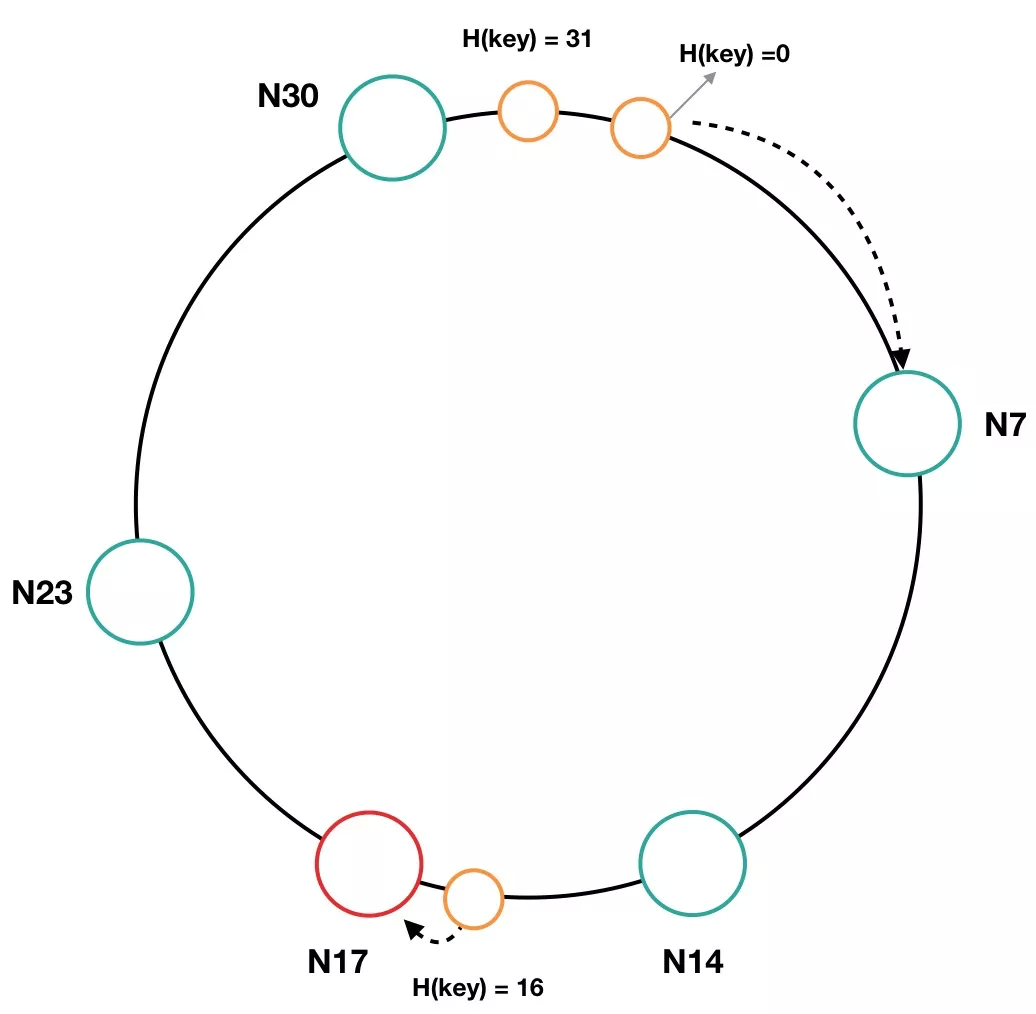
图 4 数据分片
范围分片
每一个数据分片负责存储某一键值区间范围的值。例如按照时间段进行分区,每个小时的 Key 放在对应的节点上。区间范围分片的优势在于数据分片具有连续性,可以实现区间范围查询,但是缺点在于没有对数据进行随机打散,容易存在热点数据问题。
Hash (哈希)分片
Hash 分片则是通过特定的 Hash 函数将数据随机均匀地分散在各个节点中,不支持范围查询,只支持点查询,即根据某个数据的 Key 获取数据的内容。业界大多 KV(Key-Value)存储系统都支持这种方式,包括 cassandra、dynamo、membase 等。业界常见的 Hash 分片算法有哈希取模法、一致性哈希法和虚拟桶法。
哈希取模
哈希取模的 Hash 函数如下:
这是一个 key-machine 的函数。key 是数据主键,K 是物理机数量,通过数据的 key 能够直接路由到物理机器。当 K 发生变化时,会影响全体数据分布。所有节点上的数据会被重新分布,这个过程是难以在系统无感知的情况下平滑完成的。
图 5 哈希取模
一致性哈希
分布式哈希表(DHT)是 P2P 网络和分布式存储中一项常见的技术,是哈希表的分布式扩展,即在每台机器存储部分数据的前提下,如何通过哈希的方式来对数据进行读写路由。其核心在于每个节点不仅只保存一部分数据,而且也只维护一部分路由,从而实现 P2P 网络节点去中心化的分布式寻址和分布式存储。DHT 是一个技术概念,其中业界最常见的一种实现方式就是一致性哈希的 Chord 算法实现。
哈希空间
一致性哈希中的哈希空间是一个数据和节点共用的一个逻辑环形空间,数据和机器通过各自的 Hash 算法得出各自在哈希空间的位置。
图 6 数据项和数据节点共用哈希空间
图 7 是一个二进制长度为 5 的哈希空间,该空间可以表达的数值范围是 0~31(2^5),是一个首尾相接的环状序列。环上的大圈表示不同的机器节点(一般是虚拟节点),用 Ni 来表示,i 代表着节点在哈希空间的位置。例如,某个节点根据 IP 地址和端口号进行哈希计算后得出的值是 7,那么 N7 则代表则该节点在哈希空间中的位置。由于每个物理机的配置不一样,通常配置高的物理节点会虚拟成环上的多个节点。
图 7 长度为 5 的哈希空间
环上的节点把哈希空间分成多个区间,每个节点负责存储其中一个区间的数据。例如 N14 节点负责存储 Hash 值为 8~14 范围内的数据,N7 节点负责存储 Hash 值为 31、0~7 区间的数据。环上的小圈表示实际要存储的一项数据,当一项数据通过 Hash 计算出其在哈希环中的位置后,会在环中顺时针找到离其最近的节点,该项数据将会保存在该节点上。例如,一项数据通过 Hash 计算出值为 16,那么应该存在 N18 节点上。通过上述方式,就可以将数据分布式存储在集群的不同节点,实现数据分片的功能。
节点下线
如图 8 所示,节点 N18 出现故障被移除了,那么之前 N18 节点负责的 Hash 环区间,则被顺时针移到 N23 节点,N23 节点存储的区间由 19~23 扩展为 15~23。N18 节点下线后,Hash 值为 16 的数据项将会保存在 N23 节点上。
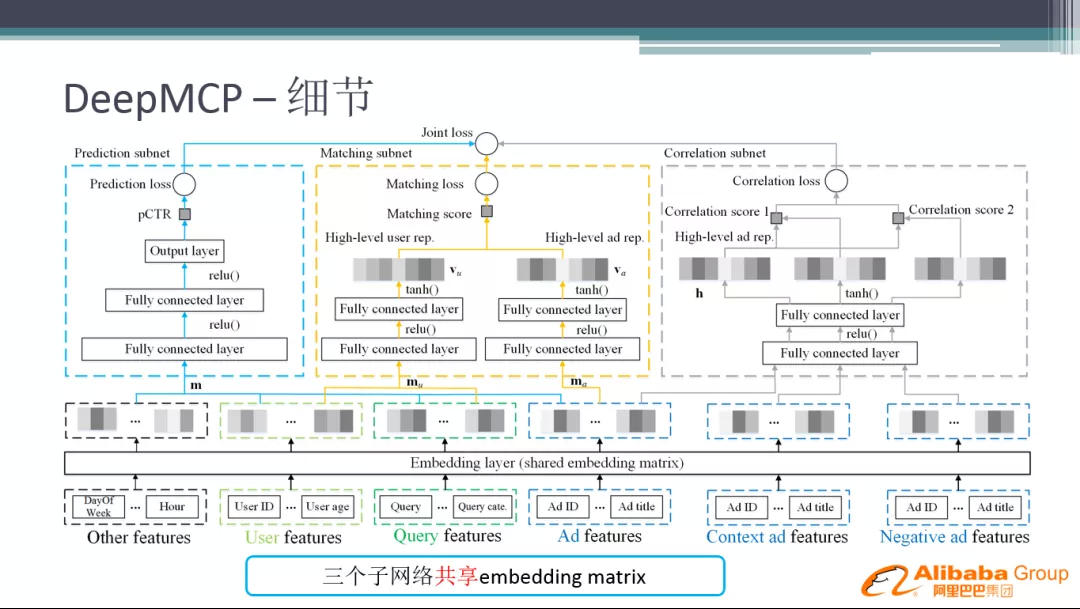
图 8 一致性哈希环中节点下线
节点上线
如图 9 所示,如果集群中上线一个新节点,其 IP 和端口进行 Hash 后的值为 17,那么其节点名为 N17。那么 N17 节点所负责的哈希环区间为 15~17,N23 节点负责的哈希区间缩小为 18~23。N17 节点上线后,Hash 值为 16 的数据项将会保存在 N17 节点上。
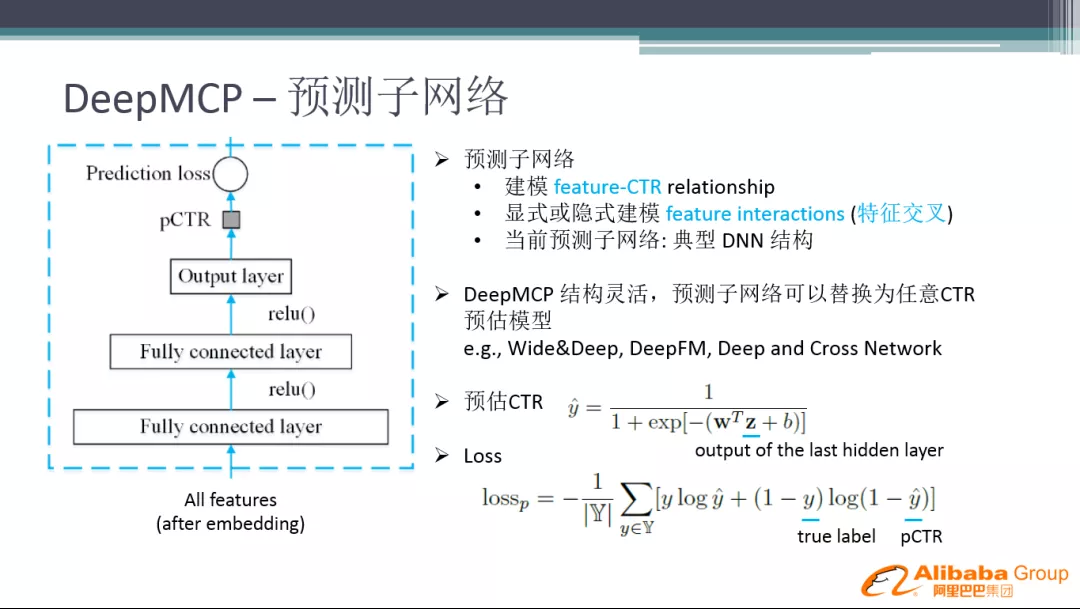
图 9 一致性哈希环中节点上线
当节点动态变化时,一致性哈希仍能够保持数据的均衡性,同时也避免了全局数据的重新哈希和数据同步。但是,发生变化的两个相邻节点所负责的数据分布范围依旧是会发生变化的,这对数据同步带来了不便。数据同步一般是通过操作日志来实现的,而一致性哈希算法的操作日志往往和数据分布相关联,在数据分布范围不稳定的情况下,操作日志的位置也会随着机器动态上下线而发生变化,在这种场景下难以实现数据的精准同步。例如,上图中 Hash 环有 0~31 个取值,假如日志文件按照这种哈希值来命名的话,那么 data-16.log 这个文件日志最初是在 N18 节点,N18 节点下线后,N23 节点也有 data-16.log 了,N17 节点上线后,N17 节点也有 data-16.log 了。所以,需要有一种机制能够保证操作日志的位置不会因为节点动态变化而受到影响。
虚拟桶预分片
虚拟桶则是将 key-node 映射进行了分解,在数据项和节点之间引入了虚拟桶这一层。如图所示,数据路由分为两步,先通过 key 做 Hash 运算计算出数据项应所对应的 slot,然后再通过 slot 和节点之间的映射关系得出该数据项应该存在哪个节点上。其中 slot 数量是固定的,key - slot 之间的哈希映射关系不会因为节点的动态变化而发生改变,数据的操作日志也和 slot 相对应,从而保证了数据同步的可行性。
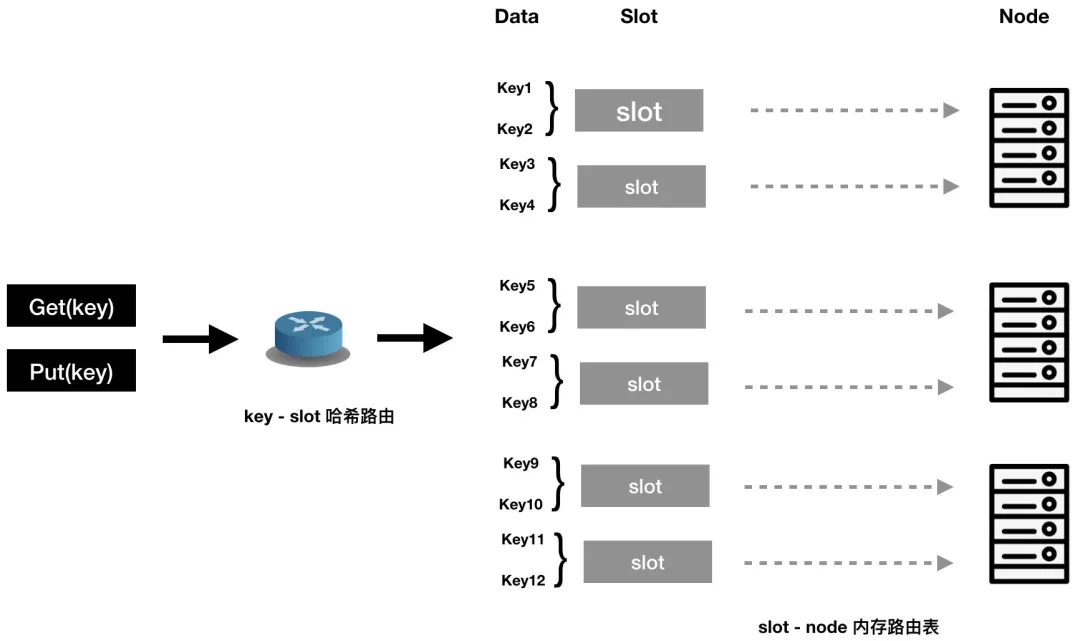
图 10 虚拟桶预分片机制
路由表中存储着所有节点和所有 slot 之间的映射关系,并尽量确保 slot 和节点之间的映射是均衡的。这样,在节点动态变化的时候,只需要修改路由表中 slot 和动态节点之间的关系即可,既保证了弹性扩缩容,也降低了数据同步的难度。
SOFARegistry 的分片选择
通过上述一致性哈希分片和虚拟桶分片的对比,我们可以总结一下它们之间的差异性:一致性哈希比较适合分布式缓存类的场景,这种场景重在解决数据均衡分布、避免数据热点和缓存加速的问题,不保证数据的高可靠,例如 Memcached;而虚拟桶则比较适合通过数据多副本来保证数据高可靠的场景,例如 Tair、Cassandra。
显然,SOFARegistry 比较适合采用虚拟桶的方式,因为服务注册中心对于数据具有高可靠性要求。但由于历史原因,SOFARegistry 最早选择了一致性哈希分片,所以同样遇到了数据分布不固定带来的数据同步难题。我们如何解决的呢?我们通过在 DataServer 内存中以 dataInfoId 的粒度记录操作日志,并且在 DataServer 之间也是以 dataInfoId 的粒度去做数据同步(一个服务就由一个 dataInfoId 唯标识)。其实这种日志记录的思想和虚拟桶是一致的,只是每个 datainfoId 就相当于一个 slot 了,这是一种因历史原因而采取的妥协方案。在服务注册中心的场景下,datainfoId 往往对应着一个发布的服务,所以总量还是比较有限的,以蚂蚁金服目前的规模,每台 DataServer 中承载的 dataInfoId 数量也仅在数万的级别,勉强实现了 dataInfoId 作为 slot 的数据多副本同步方案。
5 DataServer 扩缩容相关源码
注:本次源码解读基于 registry-server-data 的5.3.0版本。
DataServer 的核心启动类是 DataServerBootstrap,该类主要包含了三类组件:节点间的 bolt 通信组件、JVM 内部的事件通信组件、定时器组件。
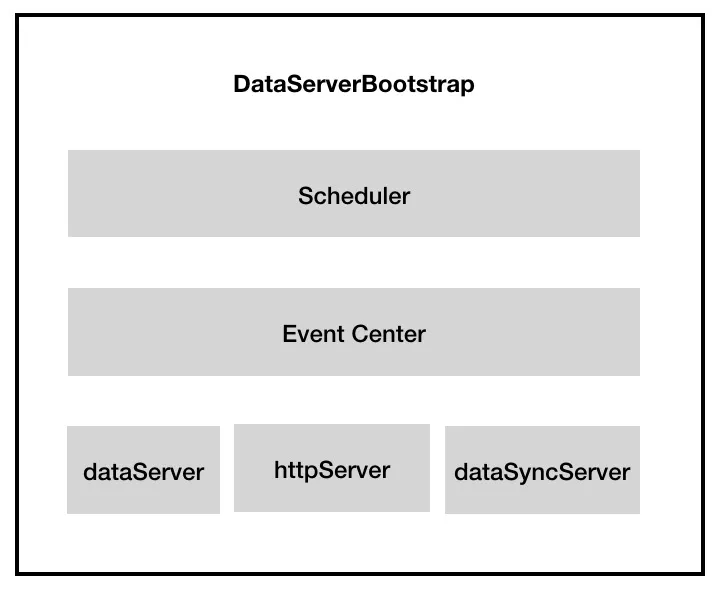
图 11 DataServerBootstrap 的核心组件
外部节点通信组件:在该类中有3个 Server 通信对象,用于和其它外部节点进行通信。其中 httpServer 主要提供一系列 http 接口,用于 dashboard 管理、数据查询等;dataSyncServer 主要是处理一些数据同步相关的服务;dataServer 则负责数据相关服务;从其注册的 handler 来看,dataSyncServer 和 dataSever 的职责有部分重叠;
JVM 内部通信组件:DataServer 内部逻辑主要是通过事件驱动机制来实现的,图12列举了部分事件在事件中心的交互流程,从图中可以看到,一个事件往往会有多个投递源,非常适合用 EventCenter 来解耦事件投递和事件处理之间的逻辑;
定时器组件:例如定时检测节点信息、定时检测数据版本信息;
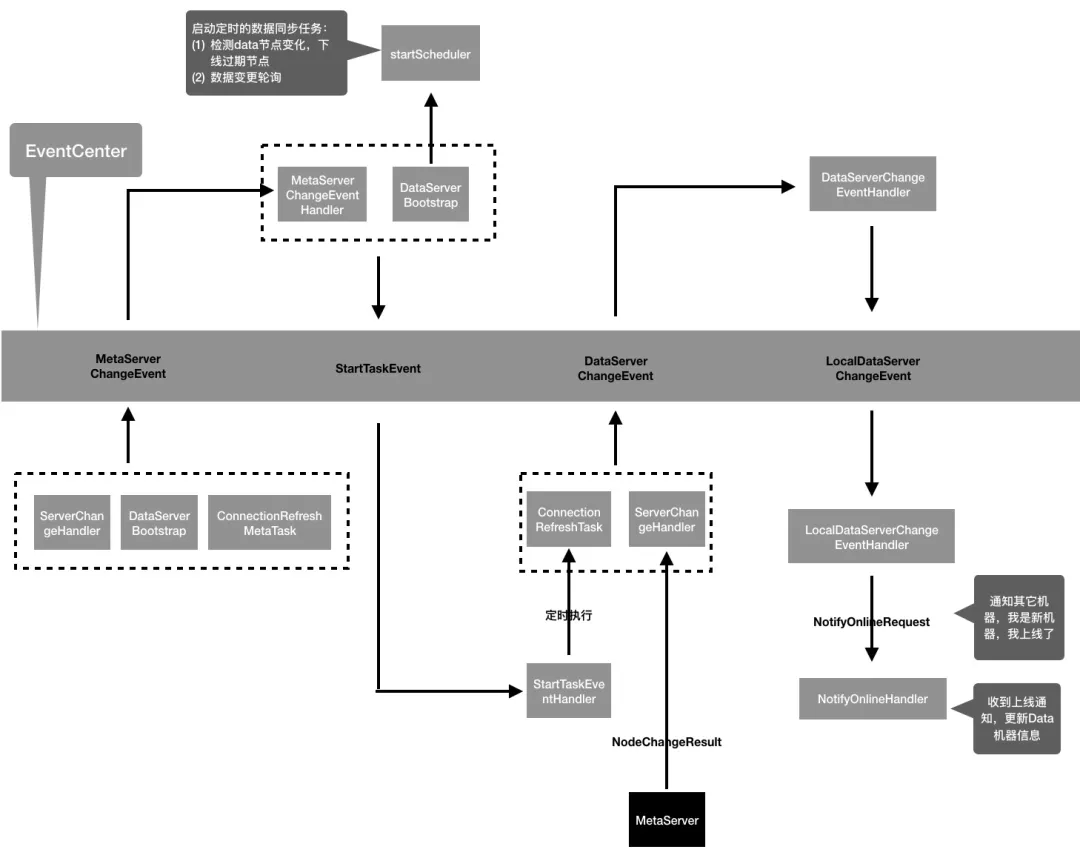
图 12 DataServer 中的核心事件流转
DataServer 节点扩容
假设随着业务规模的增长,Data 集群需要扩容新的 Data 节点。如图 13,Data4 是新增的 Data 节点,当新节点 Data4 启动时,Data4 处于初始化状态,在该状态下,对于 Data4 的数据写操作被禁止,数据读操作会转发到其它节点,同时,存量节点中属于新节点的数据将会被新节点和其副本节点拉取过来。
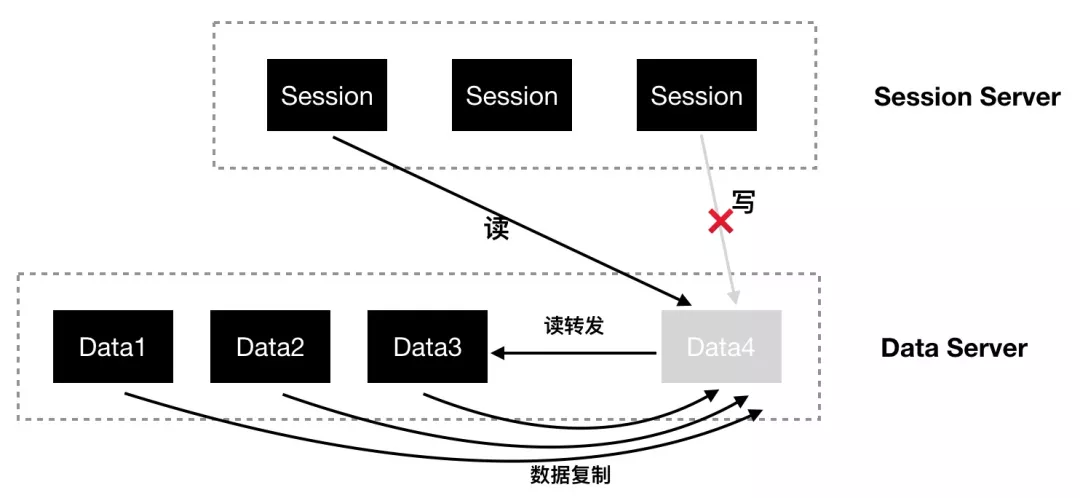
图 13 DataServer 节点扩容场景
转发读操作
在数据未同步完成之前,所有对新节点的读数据操作,将转发到拥有该数据分片的数据节点。
查询服务数据处理器 GetDataHandler:
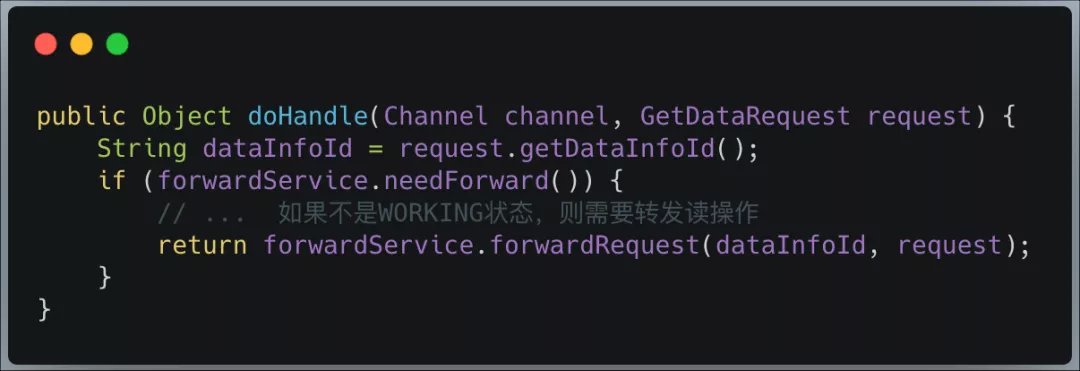
转发服务 ForwardServiceImpl:
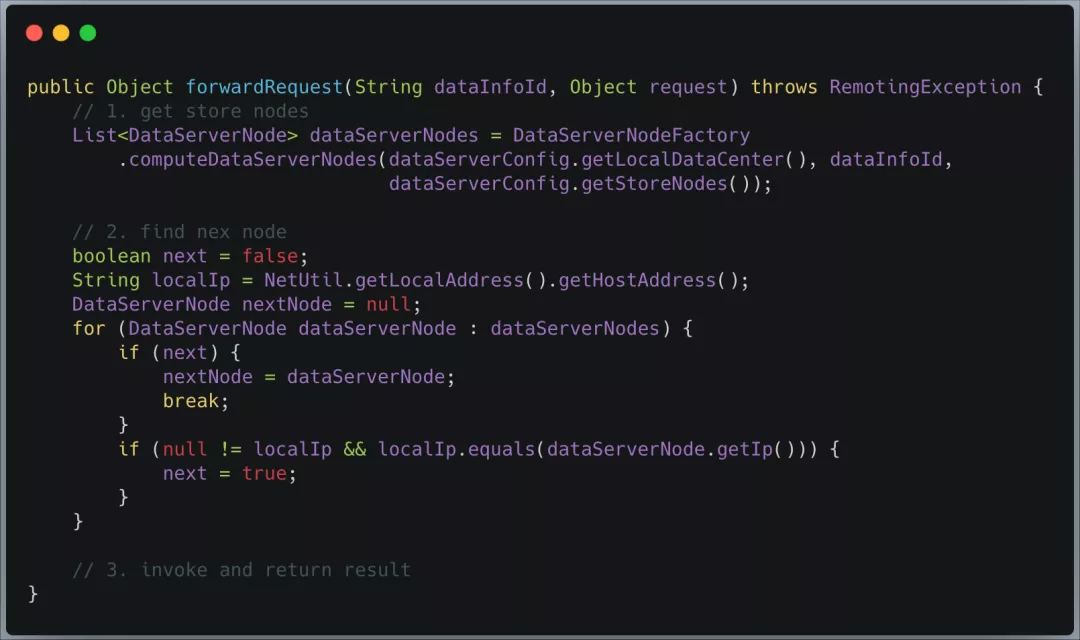
转发读操作时,分为 3 个步骤:首先,根据当前机器所在的数据中心(每个数据中心都有一个哈希空间)、 dataInfoId 和数据备份数量(默认是 3)来计算要读取的数据项所在的节点列表;其次,从这些节点列表中找出一个 IP 和本机不一致的节点作为转发目标节点;最后,将读请求转发至目标节点,并将读取的数据项返回给 session 节点。
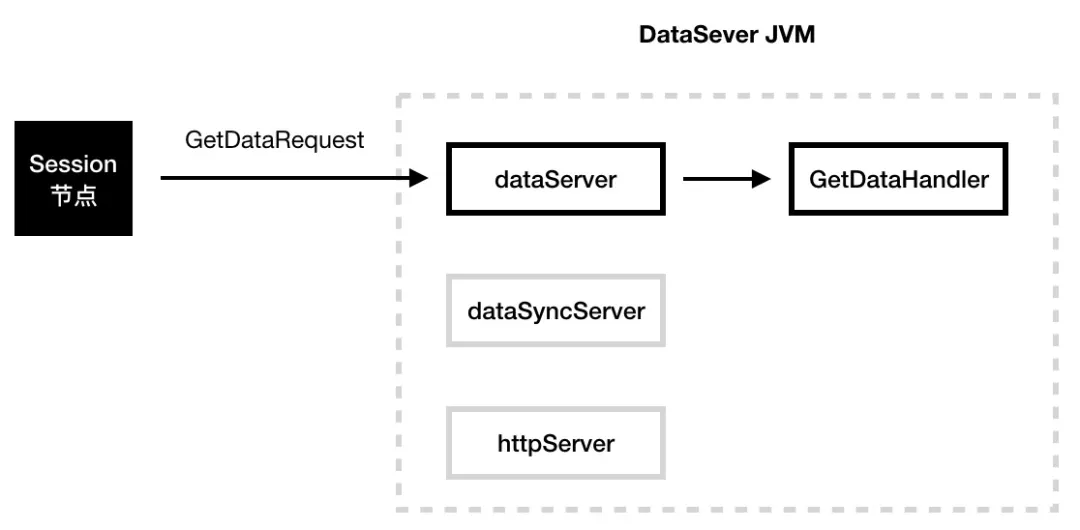
图 14 DataServer 节点扩容时的读请求
禁止写操作
在数据未同步完成之前,禁止对新节点的写数据操作,防止在数据同步过程中出现新的数据不一致情况。
发布服务处理器 PublishDataHandler:
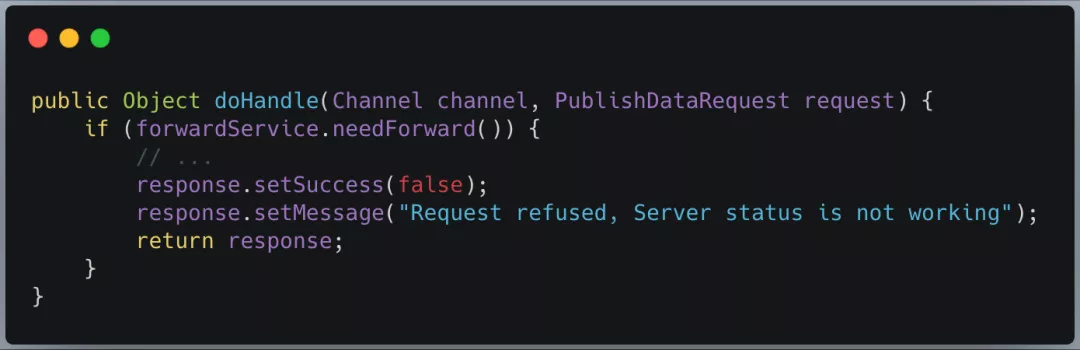
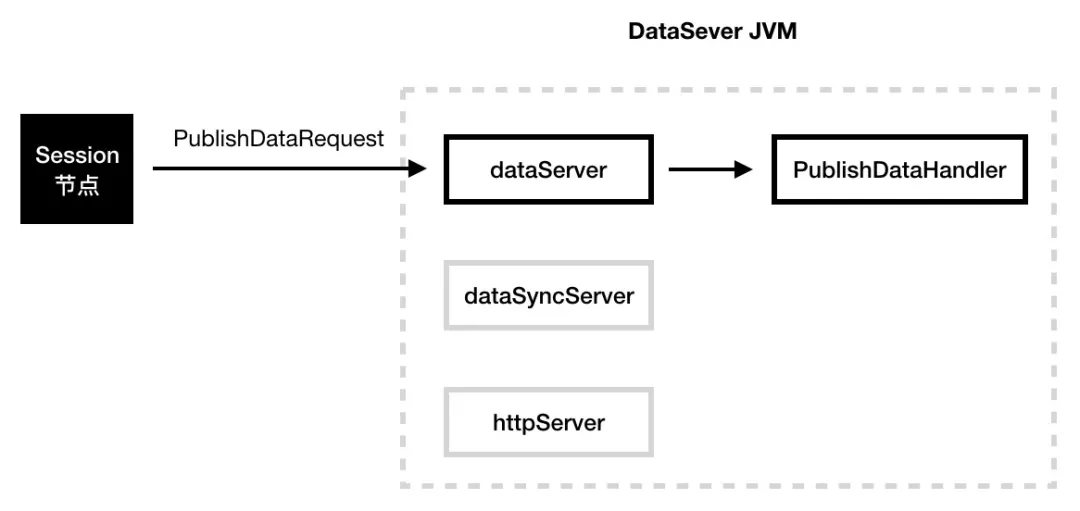
图 15 DataServer 节点扩容时的写请求
DataServer 节点缩容
以图 16 为例,数据项 Key 12 的读写请求均落在 N14 节点上,当 N14 节点接收到写请求后,会同时将数据同步给后继的节点 N17、N23(假设此时的副本数是 3)。当 N14 节点下线,MetaServer 感知到与 N14 的连接失效后,会剔除 N14 节点,同时向各节点推送 NodeChangeResult 请求,各数据节点收到该请求后,会更新本地的节点信息,并重新计算环空间。在哈希空间重新刷新之后,数据项 Key 12 的读取请求均落在 N17 节点上,由于 N17 节点上有 N14 节点上的所有数据,所以此时的切换是平滑稳定的。
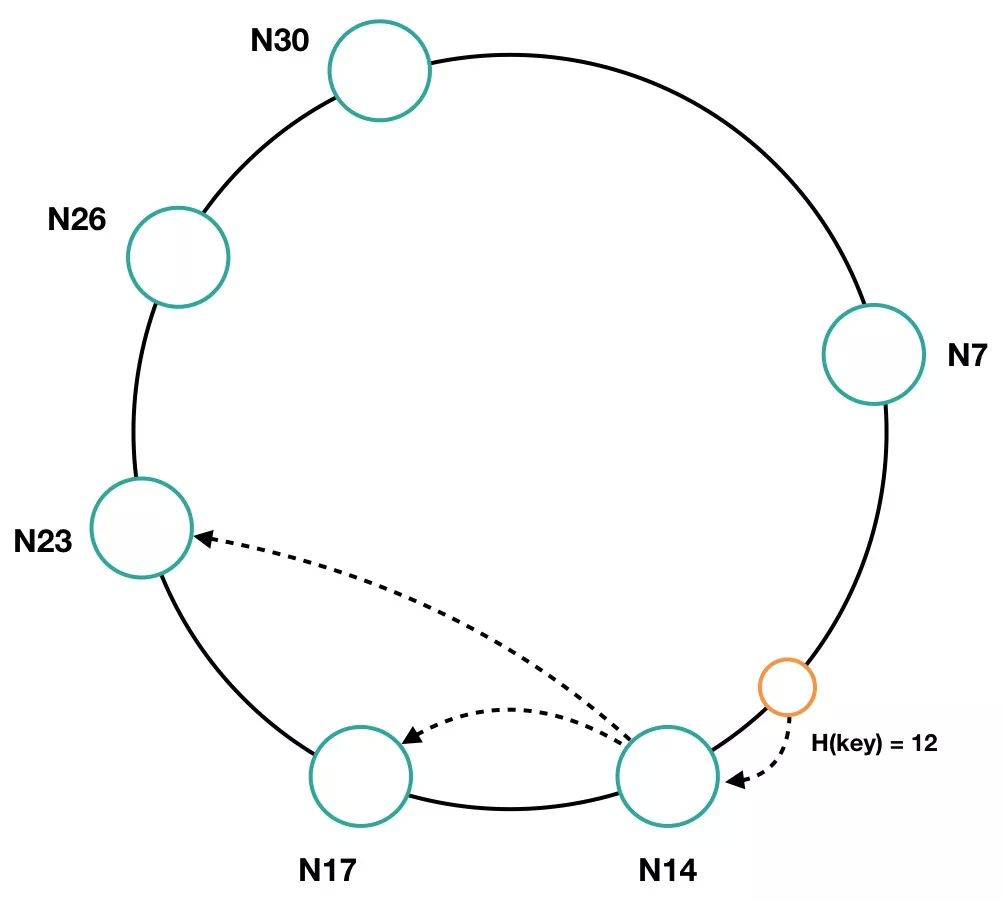
图 16 DataServer 节点缩容时的平滑切换
节点变更时的数据同步
MetaServer 会通过网络连接感知到新节点上线或者下线,所有的 DataServer 中运行着一个定时刷新连接的任务 ConnectionRefreshTask,该任务定时去轮询 MetaServer,获取数据节点的信息。需要注意的是,除了 DataServer 主动去 MetaServer 拉取节点信息外,MetaServer 也会主动发送 NodeChangeResult 请求到各个节点,通知节点信息发生变化,推拉获取信息的最终效果是一致的。
当轮询信息返回数据节点有变化时,会向 EventCenter 投递一个 DataServerChangeEvent 事件,在该事件的处理器中,如果判断出是当前机房节点信息有变化,则会投递新的事件 LocalDataServerChangeEvent,该事件的处理器 LocalDataServerChangeEventHandler 中会判断当前节点是否为新加入的节点,如果是新节点则会向其它节点发送 NotifyOnlineRequest 请求,如图 17 所示:
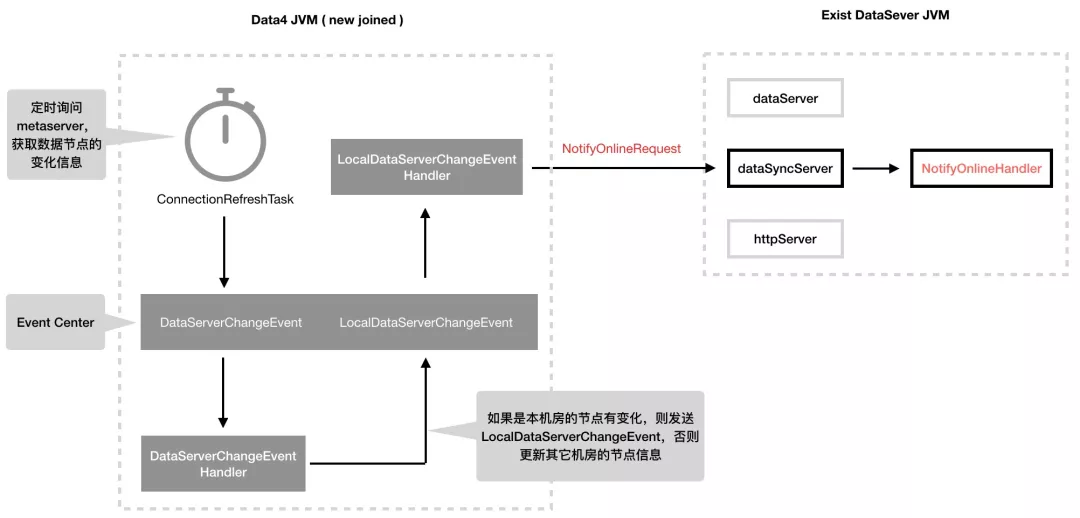
图 17 DataServer 节点上线时新节点的逻辑
同机房数据节点变更事件处理器 LocalDataServerChangeEventHandler:
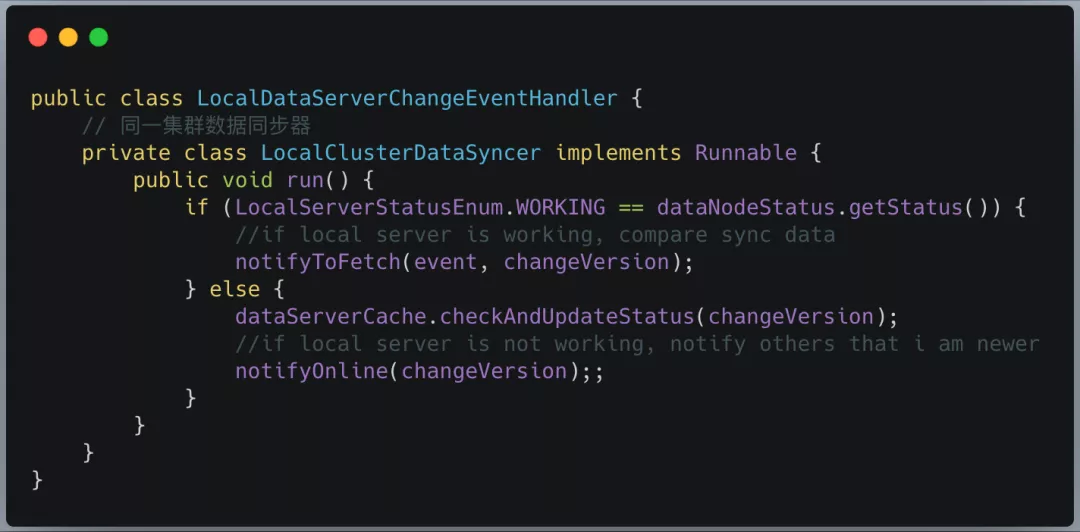
图 17 展示的是新加入节点收到节点变更消息的处理逻辑,如果是线上已经运行的节点收到节点变更的消息,前面的处理流程都相同,不同之处在于 LocalDataServerChangeEventHandler 中会根据 Hash 环计算出变更节点(扩容场景下,变更节点是新节点,缩容场景下,变更节点是下线节点在 Hash 环中的后继节点)所负责的数据分片范围和其备份节点。
当前节点遍历自身内存中的数据项,过滤出属于变更节点的分片范围的数据项,然后向变更节点和其备份节点发送 NotifyFetchDatumRequest 请求, 变更节点和其备份节点收到该请求后,其处理器会向发送者同步数据(NotifyFetchDatumHandler.fetchDatum),如图 18 所示。
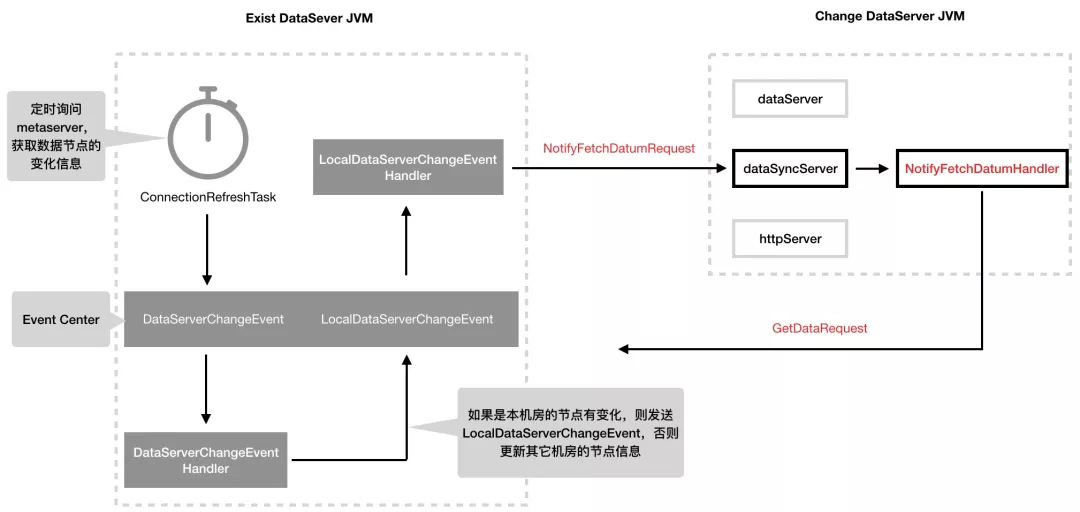
图 18 DataServer 节点变更时已存节点的逻辑
6 总结
SOFARegistry 为了解决海量服务注册和订阅的场景,在 DataServer 集群中采用了一致性 Hash 算法进行数据分片,突破了单机存储的瓶颈,理论上提供了无限扩展的可能性。同时 SOFARegistry 为了实现数据的高可用,在 DataServer 内存中以 dataInfoId 的粒度记录服务数据,并在 DataServer 之间通过 dataInfoId 的纬度进行数据同步,保障了数据一致性的同时也实现了 DataServer 平滑地扩缩容。
本文转载自公众号金融级分布式架构(ID:Antfin_SOFA)。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论