

背景
在 2018 年底,vivo AI 研究院为了解决统一的高性能训练环境、大规模的分布式训练、计算资源的高效利用调度等痛点,着手建设 AI 计算平台。白驹过隙,将近两年时间过去了,平台的建设和落地取得了很大的进展,成为了 vivo AI 领域的核心基础平台。平台现在已经有超过 500 多个用户,来自人工智能、影像、互联网等多个部门。平台的容器集群有 1000 多台服务器,拥有 50000 多 CPU 核,1000 多张 GPU 卡,GPU 算力将近 100 PFLOPS。每天运行 1000 多个的算法训练任务,部署了 100 多个的模型推理服务和 AI 应用。这些训练任务和应用都是以容器的方式运行。平台从当初服务深度学习训练为主,到现在演进成包含 VTraining、VServing、VContainer 三大模块,对外提供模型训练、模型推理和容器化的能力。
计算平台的底座是 VContainer,是基于 Kubernetes 构建的容器平台,对上提供了容器运行、资源调度等能力。Kubernetes 是平台最基础最重要的组件,其稳定性对平台至关重要。本文是 vivo AI 计算平台技术演进系列文章之一,着重分享了平台在 Kubernetes 上遇到的疑难杂症和解决方法。
疑难杂症一:kmem accounting 问题
平台的 GPU 机器在运行算法训练的时候,经常会出现机器 Crash 重启或者卡死的现象。CPU 机器也会偶现此问题。通过排查,发现是臭名昭著的 kmem accounting 问题。这个问题在网上有很多资料,比如腾讯云的文章《Cgroup泄漏–潜藏在你的集群中》和 PingCap 的文章《诊断修复 TiDB Operator 在 K8s 测试中遇到的 Linux 内核问题》。这些资料提供了现象、根因的说明以及具体的修复方法,对我们修复问题提供很大的帮助,但现存的资料有以下问题:
某些细节的信息有误。比如 PingCap 文章提到 docker 18.09.1 版本的 runc 已经将问题修复,但实际并没有。
缺乏严谨的验证修复是否成功的方法。比如如何验证某个版本的 runc 修复了该问题。
缺乏针对 GPU 机器的修复说明。
该问题还会导致容器的内存指标虚高的问题。
本文针对上面的问题进行补充,希望给大家解决此问题带来帮助。
kubelet 的编译选项
有些资料提到 kubelet 版本是 v1.14 及以上的,可以用编译选项 BUILDTAGS=“nokmem"来关闭 kmem accounting 的特性。实际验证这个编译选项是无效的,正确的编译选项是 GOFLAGS=”-tags=nokmem"。完整的编译命令是在 k8s 项目的根路径下执行:
验证修复的方法
首先,可以用命令 docker run -d --name test --kernel-memory 100M nginx:1.14.2 验证 runc 是否关闭了 kmem accounting。如果该命令执行成功,容器成功创建,说明 kmem accounting 特性还是开启的。如果命令失败,出现以下错误消息:
则说明 kmem accounting 特性已经被关闭了。
确认 runc 的 kmem accounting 关闭后,下一步是确认 kubelet 的 kmem accounting 是否关闭。重启机器后执行命令:
如果 mem.txt 的内容是空,说明 kubelet 的 kmem accounting 也成功关闭。该机器的 kmem 问题已修复。
GPU 机器的特殊处理
我们将重新编译的 kubelet 和 runc 部署到 CPU 机器,通过上述验证方法,证明 kmem 问题已经修复了。但是同样部署到 GPU 机器后,却发现 kmem 问题还存在。经过排查后,我们找到了原因。GPU 机器上,docker 的 runtime 会设置为 nvidia-container-runtime:
即 docker 会调用 nvidia-container-runtime,而不是 runc。我们使用了 nvidia-container-runtime v2.0.0.3,该版本是基于 runc 改动,添加了一个 pre-start hook,用于容器启动前在容器内挂载 GPU 驱动、nvidia 库和 GPU 设备,其原理如下图所示:
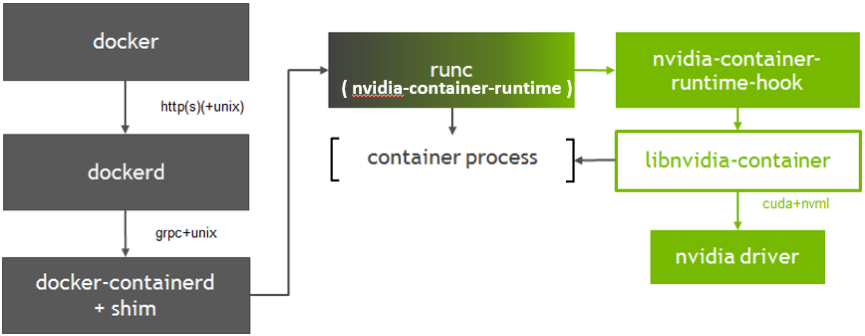
注意 nvidia-container-runtime 本身充当了 runc,机器上的 runc 二进制不会被调用。因此为了修复 GPU 机器上的 kmem 问题,我们需要关闭 nvidia-container-runtime 的 kmem accounting 特性。
接下来我们又遇到一个问题,在官方仓库中找不到 v2.0.0.3 的对应分支或者 tags。经过一番研究,我们发现 nvidia-container-runtime 对 runc 的改动是 PR Add patch updated for v1.0.0-rc8 的内容。我们自己从 runc 的 1.0.0-rc8 tag 拉出分支,做了一样的改动后,通过命令 make BUILDTAGS="seccomp nokmem"编译出关闭了 kmem 的 nvidia-container-runtime。将新的二进制部署到 GPU 机器,可以通过上述的验证。
如果大家使用的是 nvidia-container-runtime v3.0 以上版本,则不会遇到这个问题。因为 3.0 做了重构,nvidia-container-runtime 不再基于 runc,是一个独立的实现,会调用 runc。因此只需要 runc 关闭 kmem 即可。
容器内存指标虚高的问题
我们注意到平台的 calico 容器使用了很多的内存,下面所示的一个 calico-node 的 Pod 使用了 4.8G 内存。
一开始我们怀疑 calico 有内存泄露的问题,社区上也有相关的 issue: Large RAM consumption。但接着发现内存泄露问题在我们使用的 v3.6.5 版本已经修复,calico 相关的进程实际使用的内存也不多。进一步排查后发现是 kmem 导致了这个问题。
k8s 或者监控组件 cadvisor,会使用容器内/sys/fs/cgroup/memory/memory.usage_in_bytes 文件的值,作为容器的内存使用值。这个值是包含了/sys/fs/cgroup/memory/memory.kmem.usage_in_bytes 的值。
存在 kmem 问题的节点上,memory.kmem.usage_in_bytes 的值很大,从而导致 memory.usage_in_bytes 的值特别大:
在正常的节点上,memory.kmem.usage_in_bytes 的值为 0,memory.usage_in_bytes 的值是正常的:
由此可见,kmem 的问题除了会影响机器的稳定性,还会影响容器的内存指标。如果 Pod 配置了 limit 会导致 Pod 频繁被 OOM Kill。
疑难杂症二:CPU Manager 导致容器的 GPU 设备缺失
CPU Manager 是 k8s 的一个特性,可以在 kubelet 上开启。开启后满足需求的 Pod(QoS 为 Guaranteed, 且 cpu request 为正整数)会跑在固定的 CPU 核上并且独占 CPU 核,这能有效提升容器内应用的性能。这个特性在官方文章 Feature Highlight: CPU Manager 有详细说明。我们在 GPU 机器启动了该特性后,发现 GPU 容器无法访问 GPU 设备,执行 nvidia-smi 命令会有错误消息“Failed to initialize NVML: Unknown Error”。社区中有相关 issue:Updating cpu-manager-policy=static causes NVML unknown error。
根因分析
CPU Manager 特性是在 kubelet 的 CPU Manager 模块实现的。该模块通过 docker 的–cpuset-cpus 参数,可以限制容器使用指定的 CPU 核。它会维护一个数据结构,记录哪些 Pod 独占用了哪些 CPU 核。非独占核的 Pod 会共享没被独占的 CPU 核,如下图所示:
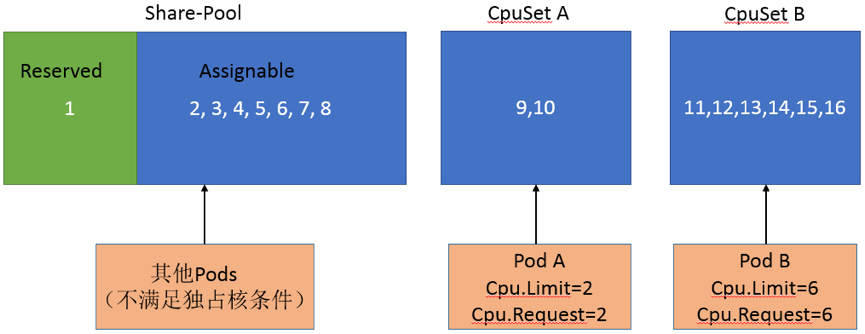
当新的 Pod 创建时,如果不满足独占核需求,cpuset-cpus 将设置为 Share-Pool 里的 CPU 核。如果满足独占核需求,则会从 Share-Pool 的 Assignable 里面分出 CPU 核给新的 Pod,Share-Pool 发生变化后也要更新非独占核 Pod 的 cpuset-cpus。CPU Manager 模块会定时刷新 Pod 的 cpuset-cpus 参数。
文章上一节提到,GPU 容器是通过 nvidia 设置 pre-start hook,在容器创建后启动前将 GPU 设备挂载到容器内,但这个设备信息没有同步给 docker。因此 CPU Manager 调用 docker API 更新容器 cpuset-cpus 参数时,GPU 设备的挂载会失效,导致了上述的问题。
修复方法
修复该问题需要修改 kubelet 的 CPU Manager 模块的代码。对于独占核的 Pod,不再定时去更新 Pod 的 cpuset-cpus 参数。这样规避了更新导致设备失效的问题。这个修复要求使用 GPU 的 Pod 必须独占核。具体的代码改动可以参见社区此说明。
疑难杂症三:容器内僵尸进程
按照容器的最佳实践,容器里应该只运行一个应用进程。有些业务场景由于特殊需求会在容器内启动多个子进程,比如一机多卡的算法训练。当子进程出现异常时,父进程没正确处理和回收,导致子进程变成僵尸进程。如下面的情况:
这会导致删除 Pod 后,Pod 在 k8s 中一直处于 Terminating 状态,主机上也无法通过 docker 命令删除对应的容器。我们可以通过 kubectl delete pod {containerID} 命令将容器的 shim 进程强制杀掉。但是僵尸进程会一直存在于系统中,最后只有重启系统才能解决。在 Linux 中 1 号进程有处理和回收僵尸进程的职责。在容器内一般的应用进程作为 1 号进程并没有这个功能。为了解决这个问题,我们需要在容器内有一个正确发挥作用的 1 号进程。
社区的 tini 项目是专门为容器设计的 init 进程,可以通过将 tini 设置为 entrypoint 让它成为 1 号进程。这需要在镜像内安装 tini 和设置 entrypoint。平台上用户可以使用自己打包的镜像,这涉及太多镜像的改造。我们发现了一种改造成本更小的方案。k8s 启动的 Pod 在主机上除了业务容器还会有 pause 容器。pause 容器中的 pause 进程实际上也有回收僵尸进程的功能。因此通过给 Pod 设置 shareProcessNamespace: true,pause 容器和业务容器共享 PID 命名空间后,容器内的一号进程就是 pause 进程,这就解决了僵尸进程的问题。关于 pause 容器和进程的更多信息,可以参见 The Almighty Pause Container。
疑难杂症四:CIDRNotAvailable 问题
在 k8s 集群规模变大后,我们发现 Controller Manager 的日志有很多 CIDRNotAvailable 相关的错误,k8s 的 event 里也有很多相关事件:
我们对此进行了排查和验证,最终确定该错误只会影响使用了 host-local 模式来分配容器 IP 的集群。平台的集群网络使用了 calico-ipam 模式,不受影响。
当容器 IP 分配使用 host local 模式,容器网络会划分成多个子网,每个节点分配一个子网,调度到节点上的容器的 IP 从这个子网分配。通过 Controller Manager 的参数 node-cidr-mask-size 可以指定子网的大小。Controller Manager 会根据这个参数分配子网给节点。node 的 spec.podCIDR 字段就是节点分配到的子网的信息:
node-cidr-mask-size 参数默认值是 24, 即主机上的子网是 24 位,比如 10.42.0.0/24。整个容器网络是 16 位的子网,如 10.42.0.0/16,这个网络可以划分成 256 个 24 位的子网,集群中有 256 个节点可以分配到子网。超过了 256 个后,新的节点划分不到子网,就会出现这个错误。使用 host local 模式的集群,调度到新节点的容器因为分配不到 IP,状态会一直处于 ContainerCreating。平台使用 calico-ipam 模式,不依赖 podCIDR 字段,因此不受影响。
疑难杂症五:cadvisor CPU 利用率过高
平台通过使用 cadvisor 来采集容器指标。我们发现有时候某些节点上的容器指标缺失。经过排查,发现是节点的 cadvisor 卡住了,这时 cadvisor 的 CPU 利用率很高。社区有相关 issue:High CPU usage with low number of containers。Github 的文章Debugging network stalls on Kubernetes详细剖析了根因,此文问题排查的技巧和思路绝佳,强烈推荐大家阅读。Github 遇到服务出现偶现的网络延迟,和我们的现象不一样。但是导致问题的根因是一样的。
直接原因是 cadvisor 在读取/sys/fs/cgroup/memory/memory.stat 文件时,耗费了较多时间。这是因为当容器退出时,应用的内存已经释放了,但是内核用于缓存如 inode 等数据的内存还未释放。如果每次主动释放这些内存,会有较大的性能开销,因此内核采用了延迟释放的策略,只有当内存不够的时候,才释放这些内存,然后才会删除对应的 cgroup。这种策略导致系统中存在很多僵尸 cgroup,这些 cgroup 的进程已退出但是因为内核使用内存未释放,所以一直未被清理,还会包含在 memory.stat 中。当这些内存被回收和 cgroup 被清理时,读取 memory.stat 的耗时就会变长。这个问题在 4.19 以上的内核已经优化了。
相关文章:
作者介绍:
吴梓洋,曾就职于 Oracle, Rancher 等公司,目前是 vivo AI 研究院计算平台组的资深工程师,也是 kube-batch, tf-operator 等项目的 contributor,关注 K8s、容器等云原生技术。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论