

背景
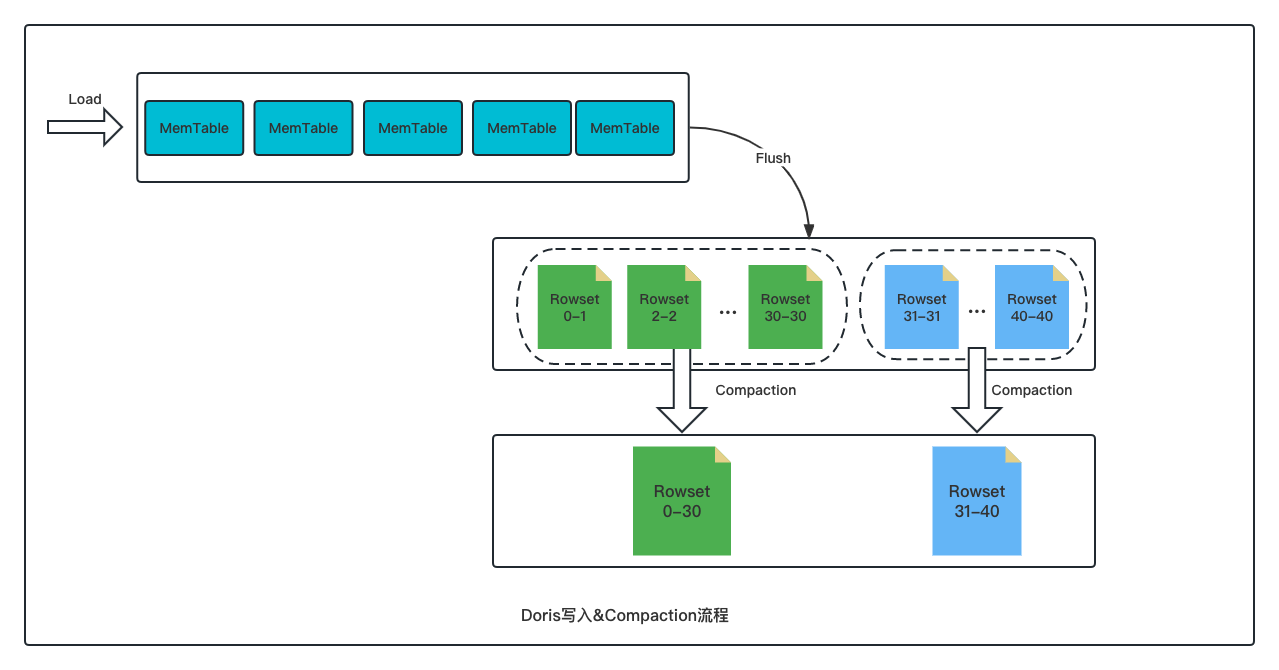
LSM-Tree( Log Structured-Merge Tree)是数据库中最为常见的存储结构之一,其核心思想在于充分发挥磁盘连续读写的性能优势、以短时间的内存与 IO 的开销换取最大的写入性能,数据以 Append-only 的方式写入 Memtable、达到阈值后冻结 Memtable 并 Flush 为磁盘文件、再结合 Compaction 机制将多个小文件进行多路归并排序形成新的文件,最终实现数据的高效写入。
Apache Doris 的存储模型也是采用类似的 LSM-Tree 数据模型。用户不同批次导入的数据会先写入内存结构,随后在磁盘上形成一个个的 Rowset 文件,每个 Rowset 文件对应一次数据导入版本。而 Doris 的 Compaction 则是负责将这些 Rowset 文件进行合并,将多个 Rowset 小文件合并成一个 Rowset 大文件。
在此过程中 Compaction 发挥着以下作用:
每个 Rowset 内的数据是按主键有序的,但 Rowset 与 Rowset 之间数据是无序的,Compaction 会将多个 Rowset 的数据从无序变为有序,提升数据在读取时的效率;
数据以 Append-only 的方式进行写入,因此 Delete、Update 等操作都是标记写入,Compaction 会将标记的数据进行真正删除或更新,避免数据在读取时进行额外的扫描及过滤;
在 Aggregate 模型上,Compaction 还可以将不同 Rowset 中相同 Key 的数据进行预聚合,减少数据读取时的聚合计算,进一步提升读取效率。
问题与思考
尽管 Compaction 在写入和查询性能方面发挥着十分关键的作用,但 Compaction 任务执行期间的写放大问题以及随之而来的磁盘 I/O 和 CPU 资源开销,也为系统稳定性和性能的充分发挥带来了新的挑战。
在用户真实场景中,往往面临着各式各样的数据写入需求,并行写入任务的多少、单次提交数据量的大小、提交频次的高低等,各种场景可能需要搭配不同的 Compaction 策略。而不合理的 Compaction 策略则会带来一系列问题:
Compaction 任务调度不及时导致大量版本堆积、Compaction Score 过高,最终导致写入失败(-235/-238);
Compaction 任务执行速度慢,CPU 消耗高;
Compaction 任务内存占用高,影响查询性能甚至导致 BE OOM;
与此同时,尽管 Apache Doris 提供了多个参数供用户进行调整,但相关参数众多且语义复杂,用户理解成本过高,也为人工调优增加了难度。
基于以上问题,从 Apache Doris 1.1.0 版本开始,我们增加了主动触发式 QuickCompaction、引入了 Cumulative Compaction 任务的隔离调度并增加了小文件合并的梯度合并策略,对高并发写入和数据实时可见等场景都进行了针对性优化。
而在 Apache Doris 最新的 1.2.2 版本和即将发布的 2.0.0 版本中,我们对系统 Compaction 能力进行了全方位增强,在触发策略、执行 方式 、 工程实现 以及参数配置上都进行了大幅优化, 在实时性、易用性与稳定性得到提升的同时更是彻底解决了查询效率问题。
Compaction 优化与实现
在设计和评估 Compaction 策略之时,我们需要综合权衡 Compaction 的任务模型和用户真实使用场景,核心优化思路包含以下几点:
实时性和高效性。Compaction 任务触发策略的实时性和任务执行方式的高效性直接影响到了查询执行的速度,版本堆积将导致 Compaction Score 过高且触发自我保护机制,导致后续数据写入失败。
稳定性。Compaction 任务对系统资源的消耗可控,不会因 Compaction 任务带来过多的内存与 CPU 开销造成系统不稳定。
易用性。由于 Compaction 任务涉及调度、策略、执行多个逻辑单元,部分特殊场景需要对 Compaction 进行调优,因此需要 Compaction 涉及的参数能够精简明了,指导用户快速进行场景化的调优。
具体在实现过程中,包含了触发策略、执行方式、工程实现以及参数配置这四个方面的优化。
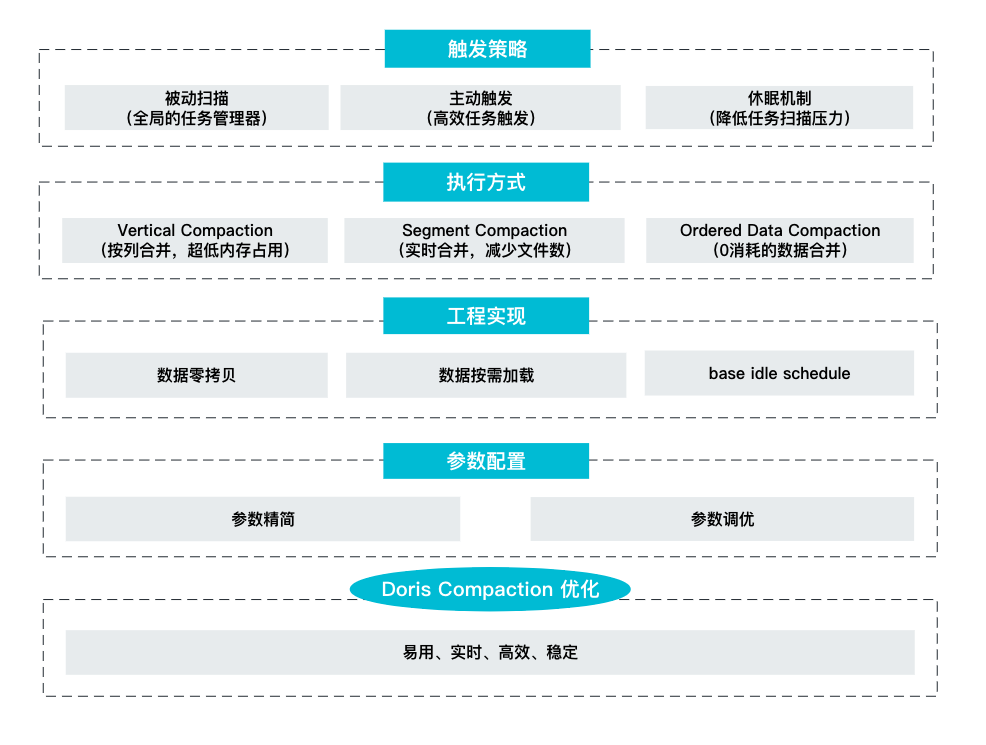
Compaction 触发策略
调度策略决定着 Compaction 任务的实时性。在 Apache Doris 2.0.0 版本中,我们在主动触发和被动扫描这两种方式的基础之上引入了 Tablet 休眠机制,力求在各类场景均能以最低的消耗保障最高的实时性。
主动触发
主动触发是一种最为实时的方式,在数据导入的阶段就检查 Tablet 是否有待触发的 Compaction 任务,这样的方式保证了 Compaction 任务与数据导入任务同步进行,在新版本产生的同时就能够立即触发数据合并,能够让 Tablet 版本数维持在一个非常稳定的状态。主动触发主要针对增量数据的 Compaction (Cumulative Compaction),存量数据则依赖被动扫描完成。
被动扫描
与主动触发不同,被动扫描主要负责触发大数据量的 Base Compaction 任务。Doris 通过启动一个后台线程,对该节点上所有的 Tablet 元数据进行扫描,根据 Tablet Compaction 任务的紧迫程度进行打分,选择得分最高的 Tablet 触发 Compaction 任务。这样的全局扫描模式能够选出最紧急的 Tablet 进行 Compaction,但一般其执行周期较长,所以需要配合主动触发策略实施。
休眠机制
频繁的元信息扫描会导致大量的 CPU 资源浪费。因此在 Doris 2.0.0 版本中我们引入了 Tablet 休眠机制,来降低元数据扫描带来的 CPU 开销。通过对长时间没有 Compaction 任务的 Tablet 设置休眠时间,一段时间内不再对该 Tablet 进行扫描,能够大幅降低任务扫描的压力。同时如果休眠的 Tablet 有突发的导入,通过主动触发的方式也能顾唤醒 Compaction 任务,不会对任务的实时性有任何影响。
通过上述的主动扫描+被动触发+休眠机制,使用最小的资源消耗,保证了 Compaction 任务触发的实时性。
Compaction 执行方式
在 Doris 1.2.2 版本中中,我们引入了两种全新的 Compaction 执行方式:
Vertical Compaction,用以彻底解决 Compaction 的内存问题以及大宽表场景下的数据合并;
Segment Compaction,用以彻底解决上传过程中的 Segment 文件过多问题;
而在即将发布的 Doris 2.0.0 版本,我们引入了 Ordered Data Compaction 以提升时序数据场景的数据合并能力。
Vertical Compaction
在之前的版本中,Compaction 通常采用行的方式进行,每次合并的基本单元为整行数据。由于存储引擎采用列式存储,行 Compaction 的方式对数据读取极其不友好,每次 Compaction 都需要加载所有列的数据,内存消耗极大,而这样的方式在宽表场景下也将带来内存的极大消耗。
针对上述问题,我们在 Doris 1.2.2 版本中实现了对列式存储更加友好的 Vertical Compaction,具体执行流程如下图:
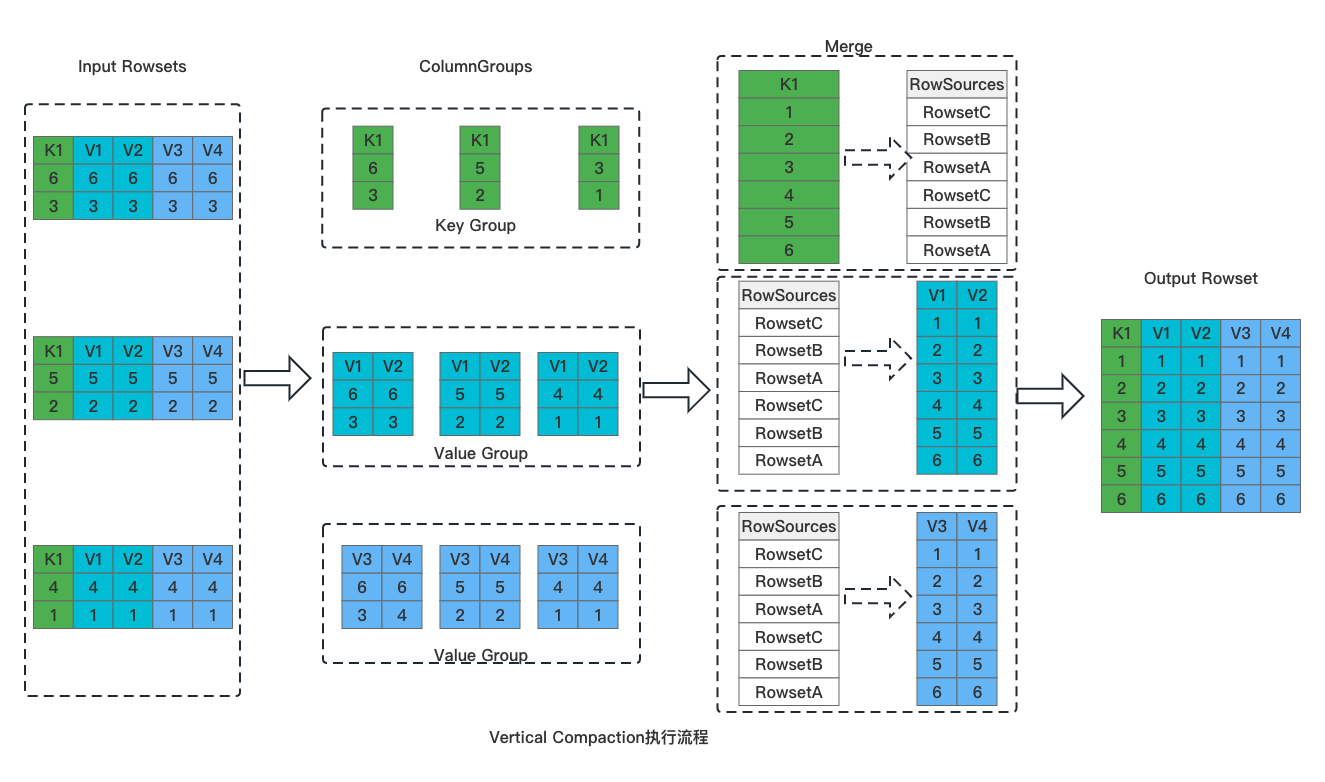
整体分为如下几个步骤:
切分列组。将输入 Rowset 按照列进行切分,所有的 Key 列一组、Value 列按 N 个一组,切分成多个 Column Group;
Key 列合并。Key 列的顺序就是最终数据的顺序,多个 Rowset 的 Key 列采用堆排序进行合并,产生最终有序的 Key 列数据。在产生 Key 列数据的同时,会同时产生用于标记全局序 RowSources。
Value 列的合并。逐一合并 Column Group 中的 Value 列,以 Key 列合并时产生的 RowSources 为依据对数据进行排序。
数据写入。数据按列写入,形成最终的 Rowset 文件。
由于采用了按列组的方式进行数据合并,Vertical Compaction 天然与列式存储更加贴合,使用列组的方式进行数据合并,单次合并只需要加载部分列的数据,因此能够极大减少合并过程中的内存占用。在实际测试中,Vertical C ompaction 使用内存仅为原有 Compaction 算法的 1/10,同时 Compaction 速率提升 15%。
Vertical Compaction 在 1.2.2 版本中默认关闭状态,需要在 BE 配置项中设置 enable_vertical_compaction=true 开启该功能。
相关 PR:https://github.com/apache/doris/pull/14524
Segment Compaction
在数据导入阶段,Doris 会在内存中积攒数据,到达一定大小时 Flush 到磁盘形成一个个的 Segment 文件。大批量数据导入时会形成大量的 Segment 文件进而影响后续查询性能,基于此 Doris 对一次导入的 Segment 文件数量做了限制。当用户导入大量数据时,可能会触发这个限制,此时系统将反馈 -238 (TOO_MANY_SEGMENTS) 同时终止对应的导入任务。Segment compaction 允许我们在导入数据的同时进行数据的实时合并,以有效控制 Segment 文件的数量,增加系统所能承载的导入数据量,同时优化后续查询效率。具体流程如下所示:
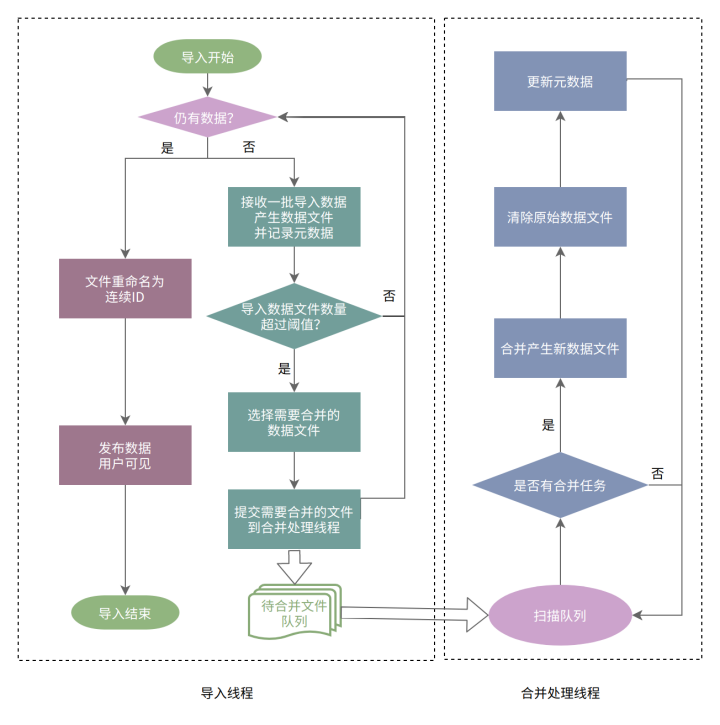
在新增的 Segment 数量超过一定阈值(例如 10)时即触发该任务执行,由专门的合并线程异步执行。通过将每组 10 个 Segment 合并成一个新的 Segment 并删除旧 Segment,导入完成后的实际 Segment 文件数量将下降 10 倍。Segment Compaction 会伴随导入的过程并行执行,在大数据量导入的场景下,能够在不显著增加导入时间的前提下大幅降低文件个数,提升查询效率。
Segment Compaction 在 1.2.2 版本中默认关闭状态,需要在 BE 配置项中设置 enable_segcompaction = true 开启该功能。
相关 PR : https://github.com/apache/doris/pull/12866
Ordered Data Compaction
随着越来越多用户在时序数据分析场景应用 Apache Doris,我们在 Apache Doris 2.0.0 版本实现了全新的 Ordered Data Compaction。
时序数据分析场景一般具备如下特点:数据整体有序、写入速率恒定、单次导入文件大小相对平均。针对如上特点,Ordered Data Compaction 无需遍历数据,跳过了传统 Compaction 复杂的读数据、排序、聚合、输出的流程,通过文件 Link 的方式直接操作底层文件生成 Compaction 的目标文件。
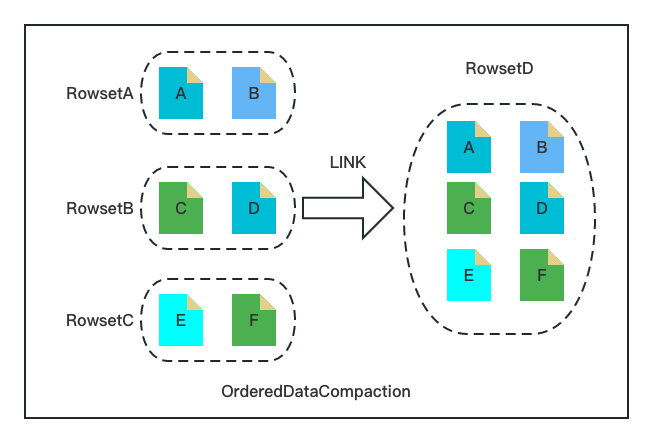
Ordered Data Compaction 执行流程包含如下几个关键阶段:
数据上传阶段。记录 Rowset 文件的 Min/Max Key,用于后续合并 Rowset 数据交叉性的判断;
数据检查阶段。检查参与 Compaction 的 Rowset 文件的有序性与整齐度,主要通过数据上传阶段的 Min /Max Key 以及文件大小进行判断。
数据合并阶段。将输入 Rowset 的文件硬链接到新 Rowset,然后构建新 Rowset 的元数据(包括行数,Size,Min/Max Key 等)。
可以看到上述阶段与传统的 Compaction 流程完全不一样,只需要文件的 Link 以及内存元信息的构建,极其简洁、轻量。针对时序场景设计的 Ordered Data Compaction 能够在毫秒级别完成大规模的 Compaction 任务,其内存消耗几乎为 ****0,对用户极其友好。
Ordered Data Compaction 在 2.0.0 版本中默认开启状态,如需调整在 BE 配置项中修改 enable_segcompaction 即可。
使用方式:BE 配置 enable_ordered_data_compaction=true
Compaction 工程实现
除了上述在触发策略和 Compaction 算法上的优化之外,Apache Doris 2.0.0 版本还对 Compaction 的工程实现进行了大量细节上的优化,包括数据零拷贝、按需加载、Idle Schedule 等。
数据零拷贝
Doris 采用分层的数据存储模型,数据在 BE 上可以分为如下几层:Tablet -> Rowset -> Segment -> Column -> Page,数据需要经过逐层处理。由于 Compaction 每次参与的数据量大,数据在各层之间的流转会带来大量的 CPU 消耗,在新版本中我们设计并实现了全流程无拷贝的 Compaction 逻辑,Block 从文件加载到内存中后,后续无序再进行拷贝,各个组件的使用都通过一个 BlockView 的数据结构完成,这样彻底的解决了数据逐层拷贝的问题,将 Compaction 的效率再次提升了 5%。
按需加载
Compaction 的逻辑本质上是要将多个无序的 Rowset 合并成一个有序的 Rowset,在大部分场景中,Rowset 内或者 Rowset 间的数据并不是完全无序的,可以充分利用局部有序性进行数据合并,在同一时间仅需加载有序文件中的第一个,这样随着合并的进行再逐渐加载。利用数据的局部有序性按需加载,能够极大减少数据合并过程中的内存消耗。
Idle schedule
在实际运行过程中,由于部分 Compaction 任务占用资源多、耗时长,经常出现因为 Compaction 任务影响查询性能的 Case。这类 Compaction 任务一般存在于 Base compaction 中,具备数据量大、执行时间长、版本合并少的特点,对任务执行的实时性要求不高。在新版本中,针对此类任务开启了线程 Idle Schedule 特性,降低此类任务的执行优先级,避免 Compaction 任务造成线上查询的性能波动。
易用性
在 Compaction 的易用性方面,Doris 2.0.0 版本进行了系统性优化。结合长期以来 Compaction 调优的一些经验数据,默认配置了一套通用环境下表现最优的参数,同时大幅精简了 Compaction 相关参数及语义,方便用户在特殊场景下的 Compaction 调优。

总结规划
通过上述一系列的优化方式, 全新版本在 Compaction 过程中取得了极为显著的改进效果。在 ClickBench 性能测试中,新版本 Compaction 执行速度 达到 30w row/s,相较于旧版本 提升 了 50 % ;资源消耗降幅巨大, 内存占用仅为原先的 10% 。高并发数据导入场景下,Compaction Score 始终保持在 50 左右,且系统表现极为平稳。同时在时序数据场景中,Compaction 写放大系数降低 90%,极大提升了可承载的写入吞吐量。
后续我们仍将进一步探索迭代优化的空间,主要的工作方向将聚焦在自动化、可观测性以及执行效率等方向上:
自动化调优。针对不同的用户场景,无需人工干预,系统支持进行自动化的 Compaction 调优;
可观测性增强。收集统计 Compaction 任务的各项指标,用于指导自动化以及手动调优;
并行 Vertical Compaction。通过 Value 列并发执行,进一步提升 Vertical Compaction 效率。
以上方向的工作都已处于规划或开发中,如果有小伙伴对以上方向感兴趣,也欢迎参与到社区中的开发来。期待有更多人参与到 Apache Doris 社区的建设中 ,欢迎你的加入!
作者介绍:
一休,Apache Doris contributor,SelectDB 资深研发工程师
张正宇,Apache Doris contributor,SelectDB 资深研发工程师

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论