2016 年 4 月 13 日,都柏林的 Liffey 河畔,Hadoop Summit 2016 在 Convention 会展中心盛大开幕。大会主要议程历时 2 天,有 100 多场演讲,与会者超过 1400 人。主要内容包括 Apache Committer 洞察、数据科学、运营管理、开发技术、数据商务、物联网、Hadoop 未来几大系列。本文就数据科学、数据商务、物联网这三方面的一些内容做一个简单回顾。
It’s Not the Size of Your Cluster, It’s How You Use It**** 演讲
由 Big Fish Games 的 David Darden 和 Don Smith 带来。介绍 Big Fish 从零开始上线 Hadoop 的过程,尤其是如何获得业务支持,启动庞大的技术工程。对那些受困于大数据项目启动成本的听众很有启发。在 Big Fish,Hadoop 集群主要用于入口分析、用户行为探索、以及分流计算压力。如何获得初始投资一直是个大问题。经验是保持良好沟通,明确地告知用户技术能做到什么(不能做到什么),然后等待,直到大量业务需求积累,推动技术项目启动。尽量用业务项目预算来覆盖技术基础设施投资。专注关键业务,高速迭代开发,尽早展示商业价值,获得用户认可从而推动下一轮投资。另外试图预测外来是行不通的,Hadoop 技术的发展常常快于公司的计划,试图满足所有的用户需求也是不可能的,目前还没有能搞定一切需求的万能大数据技术。
MLLeap: Or How to Productionize Data Science Workflows using Spark**** 演讲

由 TrueCar 的 Mikhail Semeniuk 和 Hollin Wilkins 带来。MLeap 的关键特性是能在 Spark 上训练机器学习模型,但又没有对 Spark API 的依赖,做到了模型和运行库的轻量化,能在物联网的各种微小设备上运行。MLeap 包括核心、运行库、Spark 集成和序列化几个部分。核心包含线性代数、特征提取、线性回归、分类器等通用工具。运行库包含 LeapFrame(类似 DataFrame) 和 MLeap Transformer。MLeap Transformer(非常类似 Spark Transformer,有一对一的关系) 用核心提供的类库转换 LeapFrame,完成训练。Spark 集成提供从 Spark Transformer 到 MLeap Transformer 的方便转换。序列化相当灵活,支持 JSON 或者 Protobuf。提供了一个测试报告,显示 MLeap Transform 比 Spark Transform 快 1000 倍。这个比较有明显的不公平,因为逐条记录运行,Spark Transform 对每一条记录都会重复一个初始化的过程,好比每个微批次都只有一条记录。当场演示了从简单的模型训练到部署的全过程,训练后的模型可以方便的发布在 MLeap API Rest Server 上使用。未来工作包括核心类库向 Spark 全面靠拢,统一 API,支持所有的 Spark Transformer,支持 Python/R 的接口,以及部署在非 JVM 的嵌入式设备运行。
Hadoop and Friends as Key Enabler of the IoE – Continental**'s Dynamic eHorizon演讲 **
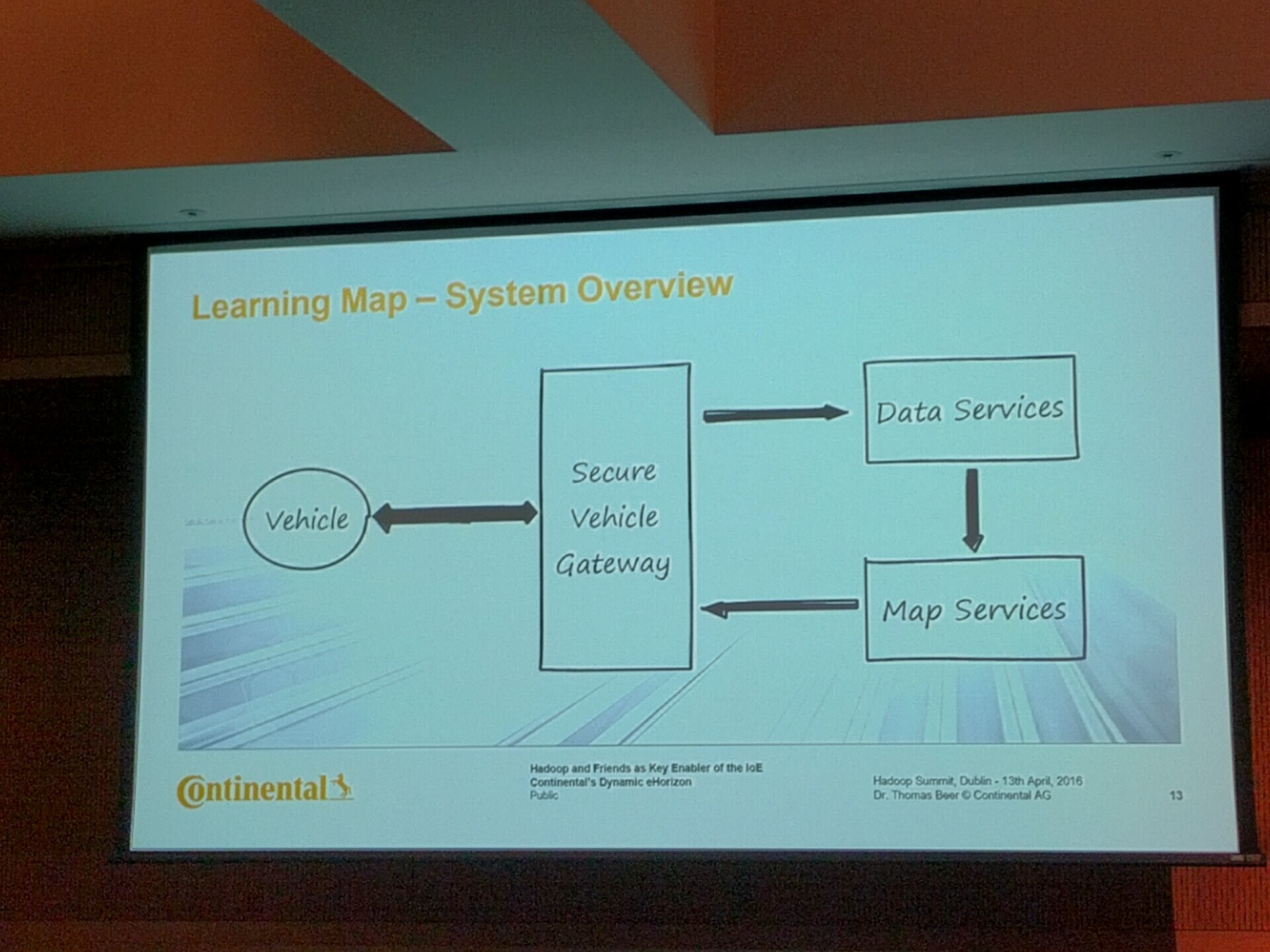
来自 Dr. Thomas Beer, Continental Automotive。这是非常有趣的一个大数据、机器学习和汽车一体的应用。Thomas 博士介绍了他们的 Learning Map 原型,利用每一辆汽车作路况信息采集,汇总到云端做机器学习,最后汇总生成精确的路况地图发送回每一辆汽车,从而实现自动驾驶。数据采集从每辆汽车开始,采集的数据不是原始图片,而是经过简单特征提取和加工的数据包,每条采集的信息大约 100KB 左右,通过安全网关送到云端。云端的数据导入用 Storm 和 Kafka 完成,数据验证和清洗用 Spark,结果数据仓库保存为 Hadoop Sequence 文件。地图学习运行在 Spark 上,暂时每天执行两次,生成的地图保存在 Amazon S3,再通过安全网关发还给每辆汽车。基础架构方面,现在原型系统主要是在 Amazon 上自行搭建的 Hadoop,正在考虑向 PaaS 过度,比如使用 Elastic MapReduce 执行机器学习任务,将大大减少机器上线时间从而节省成本。
Hadoop and Other Animals 演讲

来自 Matthew Aslett, 451 Research。演讲从到底什么是 Hadoop 说起,有狭义和广义两种理解。狭义指 Apache Hadoop 开源项目本身,由 HDFS、YARN、MapReduce 三部分组成的核心。而广义来说,Hadoop 生态系统不仅仅是那只黄色的小象,而是以它为中心的整个动物园!Hadoop 生态系统经过多年的发展,俨然已经成为大数据平台的事实标准,被世界范围内几乎所有的高科技公司一致采用(Google 大概是唯一的例外)。其底层由 HDFS 和 YARN 组成集群操作系统,之上有如 MapReduce 和 Spark 的运算框架,有如 HBase 和 Phoenix 的数据管理,有如 Zookeeper 和 Oozie 的协作模块,有如 Hive 和 Kylin 的数据分析,有如 Storm 和 Spark Streaming 的流式处理,有如 Mahout 和 Spark ML 的机器学习,有如 Ranger 和 Eagle 的安全监控等等。其覆盖大数据从采集到存储,从运算到分析,从安全到监控,无所不包,无所不有。如此强大的生态系统,已经完成了对大数据技术的事实垄断。与其从功能上来细分 Hadoop 的各种模块(如核心、流处理、数据库、分析工具等等),倒不如从用户角度来看整个 Hadoop 家族能提供什么样的解决方案,也许是个更好的方法。
作者介绍:李扬,Kyligence 联合创始人兼 CTO,Apache Kylin 联合创建者及项目管理委员会成员 (PMC), 主创团队架构师和技术负责人,专注于大数据分析,并行计算,数据索引,关系数学,近似算法,压缩算法等前沿技术。曾任 eBay 全球分析基础架构部大数据资深架构师、IBM InfoSphere BigInsights 的技术负责人,负责 Hadoop 开源产品架构,“杰出技术贡献奖”的获奖者、摩根士丹利副总裁,负责全球监管报表基础架构。




