

腾讯游戏分析 iData 是国内领先的智能化数据服务平台,致力于为游戏提供一站式数据分析,上线至今覆盖了 567+款业务,涵盖 15 亿以上的游戏用户数据。精炼游戏多年经验核心指标,60 万个以上的可视化图表服务加专业化游戏多维分析,基于用户生命周期提供完整的数据化方案,实现数据驱动的精细化运营,对公司游戏运营提供了完善的数据化运营工具,帮助游戏更全面,准确,实时的分析数据。
腾讯 iData 分析中心是 iData 产品的重要组成部分之一,负责号码包提取、画像分析、工作分析等围绕用户号码包的数据分析功能。在长达几年的运营之后,针对运营中产生的一些问题和用户的新需求,我们意识到了旧系统的不足,开始打造新的分析中心后台。我们将以系列文章,围绕新分析中心后台 TGMars 的计算平台的方方面面,来探讨、介绍我们是如何思考、研发新分析中心的。
本文将探讨我们在计算平台上的选型,为什么选择基于 Spark 构建计算平台,我们是如何使用 Spark 的,以及基于此又做了什么更多的工作。
巨人的肩膀,站的更远
为什么要用 Spark?一开始我们讨论的时候可能还不会把 Spark 当成第一选择,因为旧分析中心的计算能力已经有目共睹:很快,有时候一分钟以内就能得到想要的结果;似乎我们只需要扩展一下计算能力就好了,比如支持 SQL 语句的解析,通过计划器转变为动作,然后通过执行器执行这个动作。
那么上一篇文章是怎么说的?旧的分析系统是一个近似于 MapReduce 的结构,就算 MapReduce 比较过时,也不能说它不行,毕竟 Hive 也是在 Hadoop 之上实现了 SQL 计算能力,而且可以到 T 级的数据量也不在话下。
但是旧的分析系统并不是完整的 MapReduce 结构,有些关键地方决定了它不能实现一个较为完整的 SQL 计算:
只支持一次的 MapReduce 过程,原来的思路是单个任务从分片到计算到合并便落地结果,没有计算的迭代能力,这样较复杂的查询无法实现;
完全没有 Shuffle 能力,虽然杜绝了 Shuffle 计算的确让计算变得快,但是当某些情况下需要聚合结果时,不允许 Shuffle 是不可能的——我们只能尽量去避免,而不是完全拒绝。
当然要硬要说这都不算是问题,我们完全可以继续扩展,比如加上 Shuffle 服务器,负责数据分发;完善任务调度模块,使得任务可以一步步迭代计算;这都可以做到,但是再算一下工作量:
开发一个 Shuffle 服务:应该还好,只是个数据分发服务。
任务调度增加迭代计算模型:这也还好,重写下之前的任务调度器。
开发 SQL 解析器:学习下编译原理,应该也行。
开发 SQL 优化器:再学习下数据库原理,不过优化器知识储备应该要不少。
开发 SQL 执行 App:旧 App 是写死的逻辑,这里肯定要重写了。
…
似乎我们好像没有那么多人力了,作为一个小型开发团队,野心也不应该这么大吧?我们似乎只是需要一个更符合我们需求的 OLAP 系统而已,既然都是 2019 年了,大数据范围内有很多开源框架可选,为什么不看看开源的平台呢?踩在巨人的肩膀上应该会轻松不少吧。
为什么选择了 Spark?
先来看看之前的探索,在选择 Spark 前我们尝试过什么,后来我们又意识到了什么:
1. ElasticSearch
ES 的尝试是较早期的一个方向:考虑到 ES 的水平扩展能力强,文本检索能力近乎实时,如果我们将数据以日志的形式导入 ES 中,利用其强大的检索能力,应该可行。
虽然 ES 不太像一个数据库,但是和数据库相关概念是可以一一对应的。虽然不支持 SQL,但是基于 JSON 的元信息描述也不算什么问题,由于我们当时已经使用了 Spark,于是选择 Spark 来做 ES 的导入工具,将用户行为数据每天导入到 ES 中。
跟踪分析的实现是通过构造一个查询 JSON 串到 ES 中实现的,对于 ES 来说,实际的查询速度很快,1 分钟以内往往可以实现数月的统计任务。但是对于数据提取的操作则十分可怕,结局往往是 ES 查询节点变红而结束,这意味着查询节点已经无法提供服务了:实际测试在保证 TS80 机器下有足够节点部署时,号码包提取只能提取百万级别的数据。
因此 ES 虽然强大也有不可为的事情,而且我们的需求想来还有些无理但是又必须的。
2. TiDB,强大的 HTAP 数据库
TiDB 是在部门内精英计划中看中的一款 HTAP 数据库,作为我们的研究对象深入了解了很多。它号称 100%的 TP 能力和 80%的 AP 能力,同时完全支持 MySQL 客户端的查询,事实上我们可以把数据直接通过“导入到 MySQL”的 TDW 任务对 TiDB 做测试,他支持的各种特性真是诱人:
横向扩展,数据量再大都不怕。
MySQL 兼容,就像我说的,真的是所有平台都 Ready。
强一致的分布式事务,虽然对我们来说没那么有用。
最小化的 ETL,这可是 TP,不是 AP 那帮还需要 ETL 的家伙可比的。
那么赶紧拿来看看,似乎不吃亏。TiDB 的架构很有意思,存储是一个 KV 存储引擎 RocksDB,上层会发送加载需求,同时带上计算下推表达式,使得 KV 存储可以只需上传上层想要的数据。事实上可以看出他们也站在一位小巨人肩膀上了!
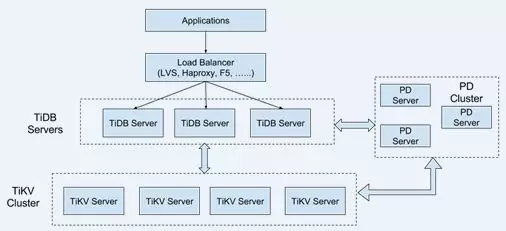
TiDB 计算部分则依赖 TiDBServer 完成,不过 Server 间是无数据共享的,也就是说数据的计算是部分下推到 KV 完成,再汇总到单台 Server 的!官方的理由倒是很充分,因为目前是采用偏 MPP 架构的,完全 SMP 架构工作量太大,而且只是支持 TP 的话(毕竟要 100%支持)这样也就足够了(因为往往都是些汇总查询,到 Server 的数据量很小了)。测试结果也表明如果我们需要大结果集(即我们需要提包)的时候,TiDB 就会挂掉,这样就没有意义了,我们可是经常就需要提各种单列多列包的,结果集往往都是百万千万甚至上亿,稍微联想一下位图系统中包合并经常挂掉的原因可能也是因为单节点处理最后的结果,一种完全无数据共享的计算模型的确不太适合我们的场景。
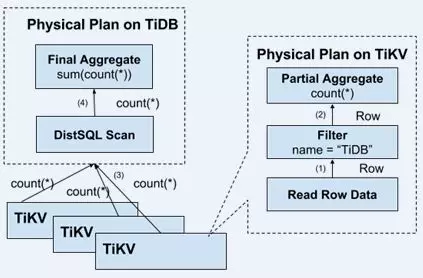
从 ES 和 TiDB 的测试中,我们意识到了我们基本的功能,只有保证数据的并行处理才能实现—不仅仅是抽取数据的过程,还有数据的加工计算过程和数据的落地过程。虽然位图系统撑住了,但是由于最后的落地仍然不是并行的,虽然相比那些开源方案更快更有效,但是仍然存在潜在的隐患,事实上我们对于上亿的结果集落地就是很吃力的(虽然这种情况仅占总任务的 5%,但是仍要支持)。
刚才官方有解释过他们没有采用完整的 SMP 架构,而是更偏向于 MPP 架构,那么这两个到底意味着什么呢?
3. MPP 和 SMP
MPP 和 SMP 其实是并行计算的概念,MPP 意味着大规模并行处理机,它是 Share Nothing 的,即意味着所有的计算一开始是并行的,彼此之间不知道对方在做什么,只有最后才把汇总结果到一起,这么一来大数据集的汇总必然在最终节点压力巨大。
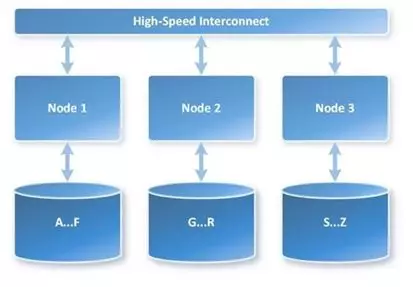
而 SMP 代表了对称多处理架构,数据和计算间有一层通路彼此交换数据,这样缺点其实也很明显,就是交换数据会有很大开销,传统上超级计算机会有一个非常非常快的网络结构去保障数据的级数交换,但是在普通网络下则会使计算性能下降明显。经管如此,他还是比 MPP 更适合 OLAP 型计算——至少它算的出来嘛。
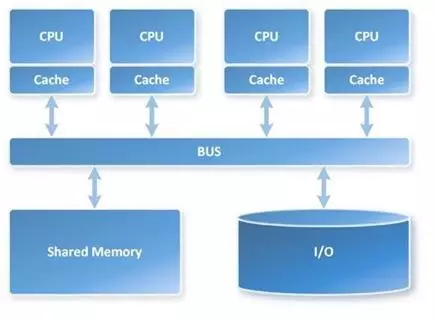
因此位图系统的局限在于完全的 MPP,虽然计算节点无数据交换而很快,但是最终数据汇总会有瓶颈。TiDB 虽然不是太 MMP 了,更偏向 SMP 一些,但是问题在于,它是 MapReduce 的,抽取数据是并行的,计算也的确有交换(特别是 JOIN 过程中),但是还是会存在最终节点的汇总,这些仍然解决不了 OLAP 的巨大计算量。
4. TiDB 的 SMP 方案
对于 TiDB,既然仍然有这种 MPP 存在的局限,对于他们来说 SMP 架构工作量大,也暂时没有人力实现,那么就没有方案么?
官方还真给出了一个答案,那就是 TiSpark,直接使用 Spark 来做计算部分,Spark 执行器通过 gRPC 加载 TiKV 存储引擎的数据,同样带上下推过滤条件,数据就可以利用 Spark 的 DAG 计算模型来随心所欲的做复杂计算了。
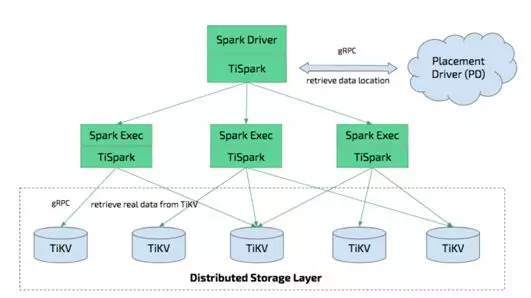
不过目前版本的 TiDB 还不支持 Spark 直接写回数据到 TiDB,且 KV 存储也是一个近似于行式的做法,我们也等不得他们 3.0 发布的 TiFlash 了。更加担忧的其实还有其他考虑:TiDB 的运维成本是否太大?KV 存储本身也是个坑,存储本身不在我们控制范围内,一旦数据毁损会怎么办?因此我们没有选择 TiSpark。
5. 基于 Spark 的其他方案
TiDB 打补丁似的 AP 方案虽然有些不那么优雅,不过让人耳目一新:Spark 还能这么玩啊?平时我们不就是写写 RDD 操作,高级点用个机器学习的库做点数据挖掘也能凑合用。
其实基于 Spark 之上的数据系统已经有了一些,而且变得越来越流行,看来选择 Spark 这位巨人没有错。这里主要简要介绍下 SnappyData 和 CarbonData。
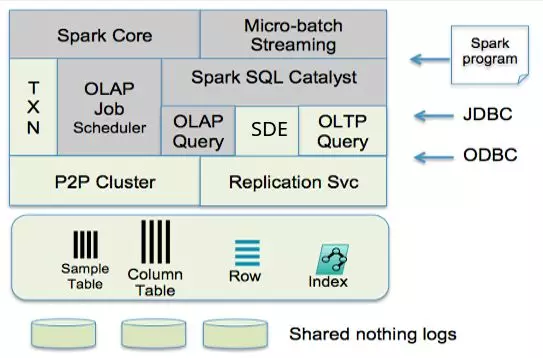
SnappyData 是一个 Apache Spark Database,官方直言不讳的介绍它是一款基于 Spark 的计算和 GemFire 的存储结合的 HTAP。GemFire 的优秀性能,可以让数据直接插入到 GemFire,实现数据的快速插入和更新,Spark 的计算能力和准实时处理能力又保证了强大的数据处理能力,同时还有一些定制的优化器使得 Spark 更好的对接存储,加速计算。
而 CarbonData 则更关心存储本身的格式,他是利用 Spark+HDFS 的传统结构实现的,不过通过构建自己的 CarbonData File,在文件之上构建了大量的索引,使得 CarbonData 在大数据集上的扫描速度比自带的 Parquet 快得多。
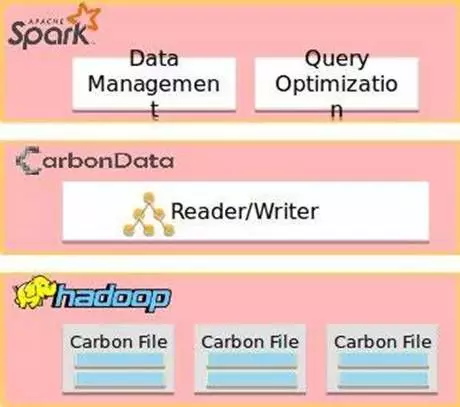
这里不再多探讨他们的架构和特色了,但是可以看出 Spark 不仅仅是功能强大,其扩展能力也有目共睹:我们可以扩展存储、我们可以扩展计算,我们可以根据自己的需求来让 Spark 更好的实现我们的需求。这无疑是相当吸引人的,因此最终选择了 Spark。
更多的工作
总结下,我们选择 Spark 是看上了什么:
Spark SQL,完整的 SQL 计算能力。
DAG 任务调度,强大的大数据处理能力。
那么回顾一下之前我们确定的原则,Spark 是否完美契合呢?
主键列按固定规则分片,方便匹配到记录。
存储计算绑定,没有 Shuffle 过程,减小网络开销。
位图,将时间维度横向转制,快速匹配到用户行为。
好像 Spark 原生的方案,没有所谓的主键分片、存储计算绑定,也不存在位图的啊?Spark+Parquet+HDFS 的确是没有的,原因有以下两点:
Parquet 格式简单来说是一种列式存储格式,虽然支持下推过滤和分片,不过分片倒是挺粗暴的:直接按目录分文件存储;而且作为通用的存储格式,索引是不会有把“时间”这个维度转置的说法,毕竟作为通用的方案,不可能照顾到这种情况。
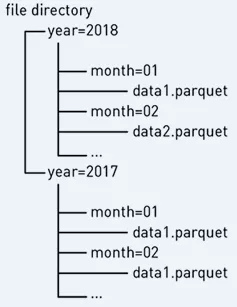
主键列固定规则分片和存储计算绑定更不可能照顾了,因为 HDFS 是按数据块而不是按照内容分片存储的,这也意味着,它会把数据按照固定长度拆分到存储节点上,这点其实有好的一面,后面可以展开谈谈。
既然如此,那么就需要定制我们的自己的文件格式和存储了,旧项目中的存储部分仍然有自己的特色,天生为分片存储而生,既然如此仍然保留。于是要做到的就是让 Spark 适配 TGMars 存储,让 Spark 按照我们想要的方式从本地加载记录和位图索引,实现本地计算。
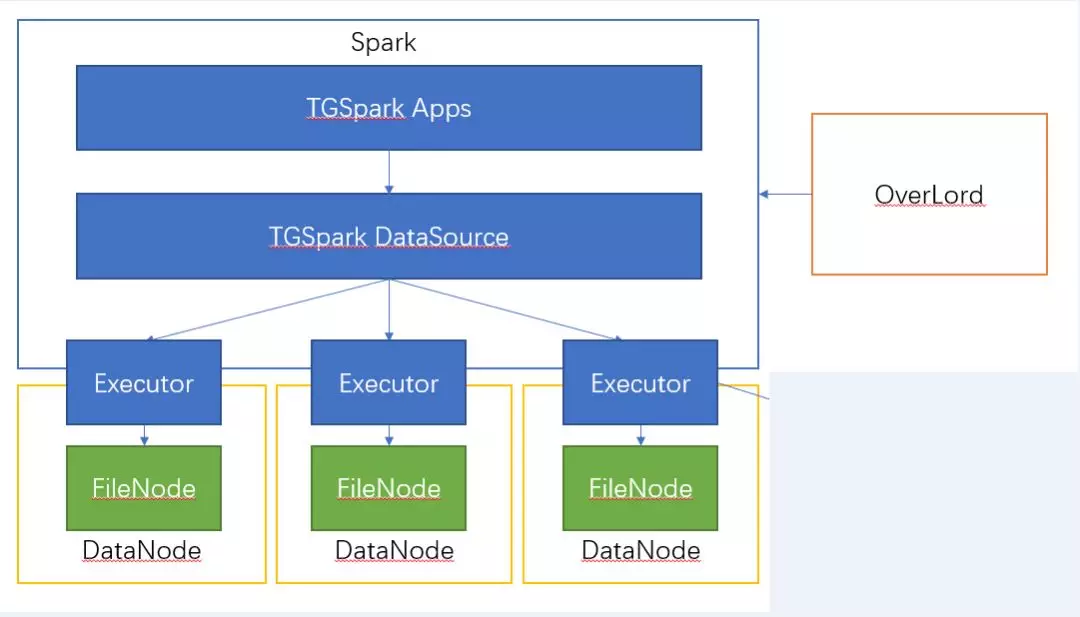
于是 TGSpark+TGMars 的方式便诞生了,将位图存储升级为 TGMars 存储,另外定制 TGMars File Format 作为自己的记录/位图文件格式,同时通过某种办法来绑定存储与计算,实现我们的目标!
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/N4iLpQEsXuD0uVtmB6XQlw

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论