

背景
我们当前的应用每天生产近 30 亿条日志,这些日志被 fluent-bit 从 K8S 中收集并保存到 Kafka 中,再使用 Logstash 从 Kafka 中消费日志,并对日志进行格式化等操作,最终写入到 Elasticsearch 中供查询。
为了满足上述体量的日志处理,我们运行了 20 台 2 核 8 G 的 Logstash 服务器,但是在业务高峰期,日志消费性能依然捉襟见肘,导致 Kafka 相关的 Topic 出现积压的情况。
由于业务快速发展,日志量还在不断增加,单纯增加服务器的缺点也很明显,管理成本和实际花销都在增加,这时寻找性能更高的替代品势在必行。
终于找到你:Vector
如果直接在搜索引擎中查找 "vector",结果可能会让人大失所望,搜索结果基本和日志收集处理毫无关系,这与 Logstash 铺天盖地的文档形成了鲜明对比,这说明 Vector 相对于 Logstash 还很年轻,很多公司的大多数场景下仍在使用 Logstash 等老牌工具收集、处理日志,但是随着 FinOps 等概念的兴起,真正义意上的降本增效是企业发展的重点,其功在点滴,成本优化工作积少成多,本文讲解如何使用 Vector 处理日志以降低成本,旨在抛砖引玉,希望有更多人测试使用、并探索推动 Vector 的更佳实践,来切实为企业降本增效出一份力。
Vector 简介
引用官网的内容:“A lightweight, ultra-fast tool for building observability pipelines”,即一个轻量级的、快速的可视化管道构建工具,通俗来讲,它能作为一个管道,连接不同上下游组件,比如从 Kafka 消费数据并写入到 AWS S3。
其由 Datadog 公司开源并主导维护,力求做到不同厂商间的中立,目前被 Atlassian、T-Mobile、Comcast、 Zendesk、Discord 和国内的豆瓣等公司使用,其中最大的用户每天使用 Vector 处理超过 30 TB 的日志。
Vector 性能如何
现代管理学之父彼得·德鲁克说:如果你不能衡量它,你就不能改进它。 IT 领域技术选型也是如此,如果我们决定使用 Vector,首要先确定它是适合我们的,是优于其它方案的。
常见的老牌日志收集/处理软件如 Logstash、Fluentd 采用 Ruby 语言开发,其 CPU 和 内存占用较高,性能一般。而 Vector 采用 Rust 语言开发,单从语言性能来讲可比肩 C 语言,从部署使用的角度来看,Vector 仅占用极少的内存就能高效的工作,而且能充分利用 CPU 的多个核心。
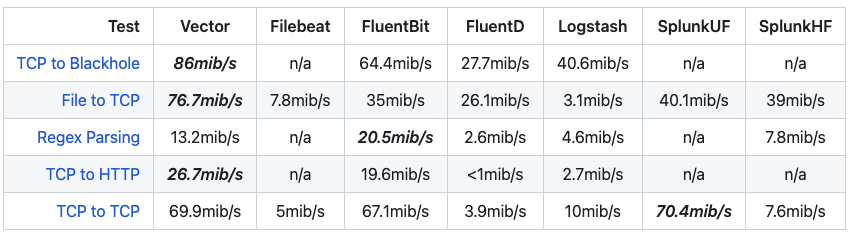
下图是 Vector 与其它日志收集器的性能测试结果对比,可以看到,Vector 的各项性能指标都优于 Logstash,综合性能也不错,加上其丰富的功能,完全可以满足我们的日志处理需求。
生产环境下的安装和监控
很多教程注重软件的理论讲解,安装使用一带而过,仿佛这是最不重要的环节,但服务器软件和个人电脑上的软件有很大差别,如何管理进程的运行、如何合理规划配置文件等都是服务稳定性中重要的一环,所以值得花些时间来讲解 Vector 的安装实践。
使用 yum 安装
大多数情况下,使用社区编译好的版本即可,怎么简单怎么安装,不必吹毛求疵自已编译,这里介绍在 CentOS 7 操作系统上使用 yum 进行安装的流程,其它系统和安装方式官方文档中有详细介绍。
添加 yum 源:
执行安装命令:
启动 Vector 并设置开机自启动:
配置文件管理实践
软件安装完成后,在 /etc/vector/ 目录下有默认的 vector.toml 配置文件,这也是 Vector 启动时默认会读取的配置文件,但是思考一个问题,当项目、环境、规则等十分庞杂时,将所有配置写到一个配置文件里合理吗?答案是否定的,好的方法是把配置文件根据需要进行拆分,比如按项目拆分成 project_xxx.toml 等多个配置文件,按环境拆分成 prod_xxx.toml、test_xxx.toml 等多个配置文件,而默认的 vector.toml 文件中可以写入一些全局配置。注意 Vector 除 .toml 格式外,还支持其它配置文件格式,如 Yaml,大家可根据习惯自行选择。
配置 Vector 读取指定目录下所有配置文件
上面提到要把复杂的配置文件拆分为多个,使用 yum 安装的 Vector 由 systemctl 命令管理,下面修改相关配置,让 Vector 读取指定目录下所有配置文件,而非默认的 vector.toml 文件。
将 Vector systemd 配置文件第 12 行由 ExecStart=/usr/bin/vector 修改为:ExecStart=/usr/bin/vector "--config-dir" "/etc/vector":
修改 vector 配置目录环境变量,将 VECTOR_CONFIG_DIR="/etc/vector/"追加到 /etc/default/vector 文件最后:
重新加载 systemd 配置并重启 Vector:
至此 Vector 的安装就完成了,当服务器因某些原因宕机再重启后,Vector 会自启动并开始工作,后续有需要对配置文件进行修改时,由于前期已经做了基本的拆分,所以看起来也不至于是庞杂的一坨。
Vector 的监控
在运维领域,运行服务不加监控,就等于闭着眼晴开车。对 Vector 的监控可以从两个方面进行。
周期性访问 Vector 的健康检查端口,检查状态是否正常。
首先打开 Vector 的 api 功能,在 vector.toml 配置文件中加入以下内容即可:
重启 Vector,获取 Vector 的健康状态:
将 Vector 内部指标 Sink 到 Prometheus,据此建立更为详细的 Dashboard 和告警。
在 vector.toml 配置文件中加入以下内容即可,vector 内置的指标将打入指定的 Prometheus。
Vector 基本原理
使用一项新的技术前,了解其工作原理和设计理念,在此大的框架上再进行细节的补充配置,就能快速将其应用,下面是 Vector 官网提供的 Vector 架构图。
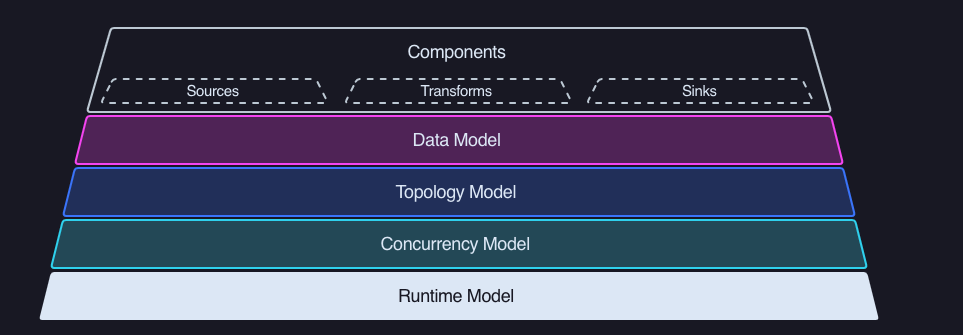
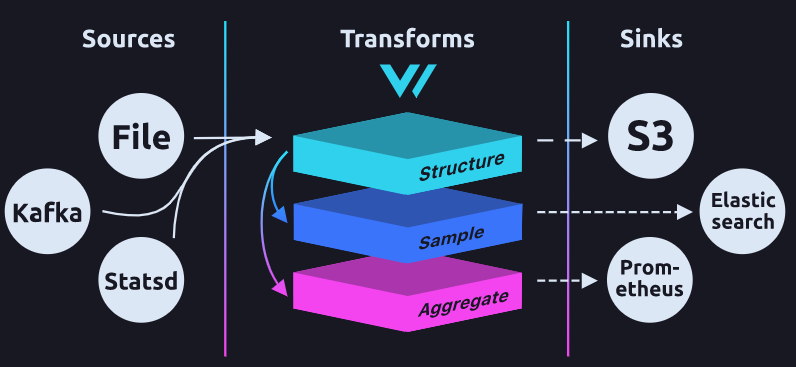
下面对照架构图对 Vector 组成进行讲解,可以看到 Vector 由 Sources、Transforms 和 Sinks 三个组件构成,对应的中文可以翻译为:源、转换、以及下沉。用最通俗的理解方式来讲,我们把 Vector 想象成一条管道,日志可以从多个源头(source)流入管道,比如 HTTP、Syslog、File、Kafka 等等,当日志数据流入管道后,就可以被进行一系列处理,处理的过程就是转换(Transform),比如增减日志中的一些字段,对日志进行重新格式化等操作,日志被处理成想要的样子后,就可以进行下沉(Sink)处理,也就是日志最终流向何处,可以是 Elasticsearch、ClickHouse、AWS S3 等等,下面对这三个部分进行逐一讲解。
Sources
Vector 提供了丰富的 Sources 供使用,常用的有 File、Elasticsearch、Kafka 等,并且支持的种类还在不断增加,详情可查看 Vector 的 Sources 参考。
如下是 Kafka 的 Source 配置实例:
Transforms
Vector 提供了诸多 Transforms 类型来对日志进行处理,比如可以使用 Vector 专有的 VRL 语言对日志进行处理,它提供了非常丰富的函数,可以拿来即用。
如果 VRL 不能满足用户对日志的处理需求,Vector 也支持嵌入 Lua 语言对日志进行处理,但是这种方式要比 VRL 慢将近 60 %,所以如果不是针对十分复杂的日志处理需求,可以向 Vector 社区提出自己的需求,社区则会考虑将用户需要的功能完善到 VRL 中。
如下是使用 VRL 将日志解析成 json 格式的配置实例:
Sinks
Vector 同样提供了很多 Sinks 类型,其中有些和 Sources 是重合的,比如 Kafka、AWS S3 等,如果当前还没有你需要的 Sink 类型,同样可以向 Vector 社区进行反馈,让其考虑添加该功能。
VRL 实例
假设我们线上环境的日志架构如下,Vector 的任务是从 Kafka 中消费日志,把日志处理成特定格式,最终打入到 Elasticsearch 中:

处理需求 1:json 扁平化,很多时候日志是多层嵌套的 json,可以使用 VRL 将嵌套 json 中的字段平铺到最外层后再打入 Elasticsearch 中。下面实例使用 VRL 将 message 字段包含的 Country 及 Language 字段解析到最外层的 json 中,如果内层字段与外层字段重合,内层字段会覆盖外层字段。
处理需求 2:删除无用的字段,还是上面的例子,message 里的字段被解析到最外层后,如果不再需要 message 字段,则可将其删除。
处理需求 3: 字段重命名,VRL 支持将日志字段重命名,比如下面将 name 字段重命名为 my_name:
在编写复杂的 VRL 时,可以使用 VRL playground 来帮助我们进行即时的编写测试来大大提高效率。

结论
使用 Vector 替换 Logstash 后,我们线上的日志收集服务从 20 台 2 核 8 G 的机器减少为 5 台 4 核 8 G 的机器,整体服务器费用减少了 50 % 左右,虽然不同公司的使用场景不同,但 Vector 依然值得测试并使用。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 5 条评论