写点什么
创作场景
- 记录自己日常工作的实践、心得
- 发表对生活和职场的感悟
- 针对感兴趣的事件发表随笔或者杂谈
- 从 0 到 1 详细介绍你掌握的一门语言、一个技术,或者一个兴趣、爱好
- 或者,就直接把你的个人博客、公众号直接搬到这里
登录/注册
收录了 数据增强 频道下的 50 篇内容

很多实际的项目,我们都难以有充足的数据来完成任务,要保证完美的完成任务,有两件事情需要做好:(1)寻找更多的数据。(2)充分利用已有的数据进行数据增强,今天就来说说数据增强。

该数据增强方案虽然方法简单,但是效果很强大

本文将详细介绍StartDT AI Lab是如何采用数据增强技术实现场景落地与业务增值的。

本文讲述数据增强中的应用,这也是AutoML技术最早期的应用之一。

怎样才能拥有足够多且可供深度学习模型训练用的数据呢?

来自伯克利的人工智能研究团队提出了一种基于群体的数据增强算法(PBA),这是一种能快速有效地学习最新方法来增强神经网络训练数据的算法。
在AI模型开发的过程中,许多开发者被不够充足的训练数据挡住了提升模型效果的脚步,一个拥有出色效果的深度学习模型,支撑它的通常是一个庞大的标注数据集。因此,提升模型的效果的通用方法是增加数据的数量和多样性。但在实践中,收集数目庞大的高质量数据并
深度学习训练过程中如果遇到过拟合或者在测试集中泛化能力不足的问题的时候,你可能会想到更多的新数据、添加正则项等,数据增强也是其中一种,特别是对于机器视觉的任务,数据增强技术尤为重要。

当我们没有大量不同的训练数据时,我们该怎么办?这是在TensorFlow中使用数据增强在模型训练期间执行内存中图像转换以帮助克服此数据障碍的快速介绍。



通常,在使用多个数据存储时,其中一个用作主存储,其他用作次存储。现在的挑战是如何保持这些数据存储的同步。

构建“市场主导、政府引导、多方共建”的数据资产治理模式。
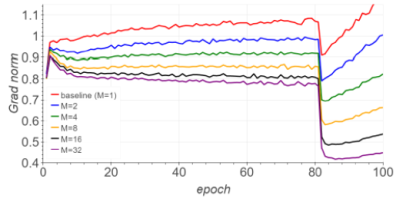
本文为数据增强的第三篇, batch augmentation; 顾名思义,在一个batch的数据中进行数据增强。

在数据增强(一)中介绍了imgaug图像增强库,本文介绍SamplePairing的数据增强策略。

探讨多模态数据的向量化策略,深入剖析检索增强和生成增强的关键技术与解决方案。
玩转字词句魔法:打造超强样本集的数据增强策略,句式变换揭秘同义句生成与回译在数据增强中的创新应用



传统的数据恢复手段往往耗时费力。带来的变革,能让这一切像回滚代码提交一样简单。

几周前,我们为 Amazon Kinesis Data Streams (KDS) 推出了两项重要的性能加强功能:增强扇出功能和 HTTP/2 数据检索 API。
 京公网安备 11010502039052号 | 产品资质
京公网安备 11010502039052号 | 产品资质






