Node.js 需要按顺序执行异步逻辑时一般采用后续传递风格,也就是将后续逻辑封装在回调函数中作为起始函数的参数,逐层嵌套。这种风格虽然可以提高 CPU 利用率,降低等待时间,但当后续逻辑步骤较多时会影响代码的可读性,结果代码的修改维护变得很困难。根据这种代码的样子,一般称其为"callback hell"或"pyramid of doom",本文称之为回调大坑,嵌套越多,大坑越深。
坑的起源
后续传递风格
为什么会有坑?这要从后续传递风格(continuation-passing style–CPS) 说起。这种编程风格最开始是由 Gerald Jay Sussman 和 Guy L. Steele, Jr. 在 AI Memo 349 上提出来的,那一年是 1975 年, Schema 语言的第一次亮相。既然 JavaScript 的函数式编程设计原则主要源自 Schema,这种风格自然也被带到了 Javascript 中。
这种风格的函数要有额外的参数:“后续逻辑体”,比如带一个参数的函数。CPS 函数计算出结果值后并不是直接返回,而是调用那个后续逻辑函数,并把这个结果作为它的参数。从而实现计算结果在逻辑步骤之间的传递,以及逻辑的延续。也就是说如果要调用 CPS 函数,调用方函数要提供一个后续逻辑函数来接收 CPS 函数的“返回”值。
回调
在 JavaScript 中,这个“后续逻辑体”就是我们常说的回调 (callback) 。这种作为参数的函数之所以被称为回调,是因为它一般在主程序中定义,由主程序交给库函数,并由它在需要时回来调用。而将回调函数作为参数的,一般是一个会占用较长时间的异步函数,要交给另一个线程执行,以便不影响主程序的后续操作。如下图所示:
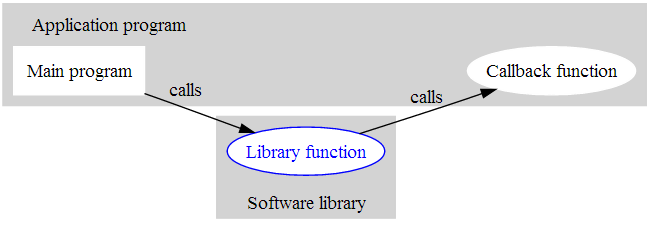
在 JavaScript 代码中,后续传递风格就是在 CPS 函数的逻辑末端调用传入的回调函数,并把计算结果传给它。但在不需要执行处理时间较长的异步函数时,一般并不需要用这种风格。我们先来看个简单的例子,编程求解一个简单的 5 元方程:
x+y+z+u+v=16
x+y+z+u-v=10
x+y+z-u=11
x+y-z=8
x-y=2
对于 x+y=a;x-y=b 这种简单的二元方程我们都知道如何求解,这个 5 元方程的运算规律和这种二元方程也没什么区别,都是两式相加除以 2 求出前一部分,两式相减除以 2 求出后一部分。5 元方程的前一部分就是 4 元方程的和值,依次类推。我们的程序写出来就是:
代码清单 1. 普通解法 -calnorm.js
var res = new Int16Array([16,10,11,8,2]),l= res.length;
var variables = [];
for(var i = 0;i < l;i++) {
if(i === l-1) {
variables[i] = res[i];
}else {
variables[i] = calculateTail(res[i],res[i+1]);
res[i+1] = calculateHead(res[i],res[i+1]);
}
}
function calculateTail(x,y) {
return (x-y)/2;
}
function calculateHead(x,y) {
return (x+y)/2;
}
方程式的结果放在了一个整型数组中,我们在循环中依次遍历数组中的头两个值 res[i] 和 res[i+1],用 calculateTail 计算最后一个单值,比如第一和第二个等式中的 v;用 calculateHead 计算等式的"前半部分",比如第一和第二个等式中的 x+y+z+u 部分。并用该结果覆盖原来的差值等式,即用 x+y+z+u 的结果覆盖原来 x+y+z+u-v 的结果,以便计算下一个 tail,直到最终求出所有未知数。
如果 calculateTail 和 calculateHead 是 CPU 密集型的计算,我们通常会把它放到子线程中执行,并在计算完成后用回调函数把结果传回来,以免阻塞主进程。关于 CPU 密集型计算的相关概念,可参考本系列的上一篇 Node.js 软肋之 CPU 密集型任务。比如我们可以把代码改成下面这样:
代码清单 2. 回调解法 -calcb.js
var res = new Int16Array([16,10,11,8,2]),l= res.length; var variables = []; (function calculate(i) { if(i === l-1) { variables[i] = res[i]; console.log(i + ":" + variables[i]); process.exit(); }else { calculateTail(res[i],res[i+1],function(tail) { variables[i] = tail; calculateHead(res[i],res[i+1],function(head) { res[i+1] = head; console.log('-----------------'+i+'-----------------') calculate(i+1); }); }); } })(0); function calculateTail(x,y,cb) { setTimeout(function(){ var tail = (x-y)/2; cb(tail); },300); } function calculateHead(x,y,cb) { setTimeout(function(){ var head = (x+y)/2; cb(head); },400); }
跟上一段代码相比,这段代码主要有两个变化。第一是 calculateTail 和 calculateHead 里增加了 setTimeout,把它们伪装成 CPU 密集型任务;第二是弃用 for 循环,改用函数递归。因为 calculateHead 的计算结果会影响下一轮的 calculateTail 计算,所以 calculateHead 计算要阻塞后续计算。而 for 循环是无法阻塞的,会产生错误的结果。此外就是 calculateTail 和 calculateHead 都变成后续传递风格的函数了,通过回调返回最终计算结果。
这个例子比较简单,既不能充分体现回调在处理异步非阻塞操作时在性能上的优越性,坑的深度也不够恐怖。不过也可以说明“用后续传递风格实现几个异步函数的顺序执行是产生回调大坑的根本原因”。下面有一个更抽象的回调样例,看起来更有代表性:
module.exports = function (param, cb) {
asyncFun1(param, function (er, data) {
if (er) return cb(er);
asyncFun2(data,function (er,data) {
if (er) return cb(er);
asyncFun3(data, function (er, data) {
if (er) return cb(er);
cb(data);
})
})
})
}
像 function(er,data) 这种回调函数签名很常见,几乎所有的 Node.js 核心库及第三方库中的 CPS 函数都接收这样的函数参数,它的第一个参数是错误,其余参数是 CPS 函数要传递的结果。比如 Node.js 中负责文件处理的 fs 模块,我们再看一个实际工作中可能会遇到的例子。要找出一个目录中最大的文件,处理步骤应该是:
- 用 fs.readdir 获取目录中的文件列表;
- 循环遍历文件,获取文件的 stat ;
- 找出最大文件;
- 以最大文件的文件名为参数调用回调。
这些都是异步操作,但需要顺序执行,后续传递风格的代码应该是下面这样的:
代码清单 3. 寻找给定目录中最大的文件
var fs = require('fs') var path = require('path') module.exports = function (dir, cb) { fs.readdir(dir, function (er, files) { // [1] if (er) return cb(er) var counter = files.length var errored = false var stats = [] files.forEach(function (file, index) { fs.stat(path.join(dir,file), function (er, stat) { // [2] if (errored) return if (er) { errored = true return cb(er) } stats[index] = stat // [3] if (--counter == 0) { // [4] var largest = stats .filter(function (stat) { return stat.isFile() }) // [5] .reduce(function (prev, next) { // [6] if (prev.size > next.size) return prev return next }) cb(null, files[stats.indexOf(largest)]) // [7] } }) }) }) }
对这个模块的用户来说,只需要提供一个回调函数 function(er,filename),用两个参数分别接收错误或文件名:
var findLargest = require('./findLargest')
findLargest('./path/to/dir', function (er, filename) {
if (er) return console.error(er)
console.log('largest file was:', filename)
})
介绍完 CPS 和回调,我们接下来看看如何平坑。
解套平坑
编写正确的并发程序归根结底是要让尽可能多的操作同步进行,但各操作的先后顺序仍能正确无误。服务端的代码一般逻辑比较复杂,步骤多,此时用嵌套实现异步函数的顺序执行会比较痛苦,所以应该尽量避免嵌套,或者降低嵌套代码的复杂性,少用匿名函数。这一般有几种途径:
- 最简单的是把匿名函数拿出来定义成单独的函数,然后或者像原来一样用嵌套方式调用,或者借助流程控制模块放在数组里逐一调用;
- 用 Promis;
- 如果你的 Node 版本 >=0.11.2,可以用 generator。
我们先介绍最容易理解的流程控制模块。
流程控制模块
Nimble 是一个轻量、可移植的函数式流程控制模块。经过最小化和压缩后只有 837 字节,可以运行在 Node.js 中,也可以用在各种浏览器中。它整合了 underscore 和 async 一些最实用的功能,并且 API 更简单。
nimble 有两个流程控制函数,_.parallel 和 _.series。顾名思义,我们要用的是第二个,可以让一组函数串行执行的 _.series。下面这个命令是用来安装 Nimble 的:
npm install nimble
如果用.series 调度执行上面那个解方程的函数,代码应该是这样的:
...
var flow = require('nimble');
(function calculate(i) {
if(i === l-1) {
variables[i] = res[i];
process.exit();
}else {
flow.series([
function (callback) {
calculateTail(res[i],res[i+1],function(tail) {
variables[i] = tail;
callback();
});
},
function (callback) {
calculateHead(res[i],res[i+1],function(head) {
res[i+1] = head;
callback();
});
},
function(callback){
calculate(i+1);
}]);
}
})(0);
...
.series 数组参数中的函数会挨个执行,只是我们的 calculateTail 和 calculateHead 都被包在了另一个函数中。尽管这个用流程控制实现的版本代码更多,但通常可读性和可维护性要强一些。接下来我们介绍 Promise。
Promise
什么是 Promise 呢?在纸牌屋的第一季第一集中,当琳达告诉安德伍德不能让他做国务卿后,他说:“所谓Promise,就是说它不会受不断变化的情况影响。”
Promise 不仅去掉了嵌套,它连回调都去掉了。因为按照 Promise 的观点,回调一点也不符合函数式编程的精神。回调函数什么都不返回,没有返回值的函数,执行它仅仅是因为它的副作用。所以用回调函数编程天生就是指令式的,是以副作用为主的过程的执行顺序,而不是像函数那样把输入映射到输出,可以组装到一起。
最好的函数式编程是声明式的。在指令式编程中,我们编写指令序列来告诉机器如何做我们想做的事情。在函数式编程中,我们描述值之间的关系,告诉机器我们想计算什么,然后由机器(底层框架)自己产生指令序列完成计算。Promise 把函数的结果变成了一个与时间无关的值,就像算式中的未知数一样,可以用它轻松描述值之间的逻辑计算关系。虽然要得出一个函数最终的结果需要先计算出其中的所有未知数,但我们写的程序只需要描述出各未知数以及未知数和已知数之间的逻辑关系。而 CPS 是手工编排控制流,不是通过定义值之间的关系来解决问题,因此用回调函数编写正确的并发程序很困难。比如在代码清单 2 中,caculateHead 被放在 caculateTail 的回调中执行,但实际上在计算同一组值时,两者之间并没有依赖关系,只是进入下一轮计算前需要两者都给出结果,但如果不用回调嵌套,实现这种顺序控制比较麻烦。
当然,这和我们的处理方式(共用数组)有关,就这个问题本身而言,caculateHead 完全不依赖于任何 caculateTail。
这里用的 Promis 框架是著名的 Q ,可以用 npm install q 安装。虽然可用的 Promis 框架有很多,但在它们用法上都大同小异。我们在这里会用到其中的三个方法。
第一个负责将 Node.js 的 CPS 函数变成 Promise。Node.js 核心库和第三方库中有非常多的 CPS 函数,我们的程序肯定要用到这些函数,要解决回调大坑,就要从这些函数开始。这些函数的回调函数参数大多遵循一个相同的模式,即函数签名为 function(err, result)。对于这种函数,可以用简单直接的 Q.nfcall 和 Q.nfapply 调用这种 Node.js 风格的函数返回一个 Promise:
return Q.nfcall(FS.readFile, "foo.txt", "utf-8");
return Q.nfapply(FS.readFile, ["foo.txt", "utf-8"]);
也可以用 Q.denodeify 或 Q.nbind 创建一个可重用的包装函数,比如:
var readFile = Q.denodeify(FS.readFile);
return readFile("foo.txt", "utf-8");
var redisClientGet = Q.nbind(redisClient.get, redisClient);
return redisClientGet("user:1:id");
第二个是 then 方法,这个方法是 Promise 对象的核心部件。我们可以用这个方法从异步操作中得到返回值(履约值),或抛出的异常(拒绝的理由)。then 方法有两个可选的参数,分别对应 Promis 对象的两种执行结果。成功时调用的 onFulfilled 函数,错误时调用 onRejected 函数:
var promise = asyncFun()
promise.then(onFulfilled, onRejected)
Promise 被解决时(异步处理已经完成)会调用 onFulfilled 或 onRejected 。因为只会有一种可能,所以这两个函数中仅有一个会被触发。尽管 then 方法的名字让人觉得它跟某种顺序化操作有关,并且那确实是它所承担的职责的副产品,但你真的可以把它当作 unwrap 来看待。Promise 对象是一个存放未知值的容器,而 then 的任务就是把这个值从 Promise 中提取出来,把它交给另一个函数。
var promise = readFile()
var promise2 = promise.then(readAnotherFile, console.error)
这个 promise 表示 onFulfilled 或 onRejected 的返回结果。既然结果只能是其中之一,所以不管是什么结果,Promise 都会转发调用:
var promise = readFile()
var promise2 = promise.then(function (data) {
return readAnotherFile() // if readFile was successful, let's readAnotherFile
}, function (err) {
console.error(err) // if readFile was unsuccessful, let's log it but still readAnotherFile
return readAnotherFile()
})
promise2.then(console.log, console.error) // the result of readAnotherFile
因为 then 返回的是 Promise,所以 promise 可以形成调用链,从而避免出现回调大坑:
readFile()
.then(readAnotherFile)
.then(doSomethingElse)
.then(...)
第三个是 all 和 spread 方法。我们可以把几个 Promise 放到一个数组中,用 all 将它们变成一个 Promise,而 spread 跟在 all 后面就相当于 then,只是它同时接受几个结果。如果数组中的 N 个 Promise 都成功,那 spread 的 onFulfilled 参数就能收到对应的 N 个结果;如果有一个失败,它的 onRejected 就会得到第一个失败的 Promise 抛出的错误。
下面是用 Q 改写的解方程程序代码:
....
var Q = require('q');
var qTail = Q.denodeify(calculateTail);
var qHead = Q.denodeify(calculateHead);
(function calculate(i) {
Q.all([
qTail(res[i],res[i+1]),
qHead(res[i],res[i+1])])
.spread(function(tail,head){
variables[i] = tail;
res[i+1] = head;
return i+1;
})
.then(function(i){
if(i === l-1) {
variables[i] = res[i];
process.exit();
}else {
calculate(i);
}
});
})(0);
function calculateTail(x,y,cb) {
setTimeout(function(){
var tail = (x-y)/2;
cb(null,tail);
},300);
}
function calculateHead(x,y,cb) {
setTimeout(function(){
var head = (x+y)/2;
cb(null,head);
},400);
}
...
注意 calculateTail 和 calculateHead 中的 cb 调用,为了满足 denodeify 的要求,我们给它增加了值为 null 的 err 参数。此外还用到了上面提到的 denodeify、all 和 spread、then。其实除了流程控制,Promise 在异常处理上也比回调做得好。甚至有些开发团队坚决反对在代码中使用 CPS 函数,将 Promise 作为编码规范强制推行。
再来看一下那个找最大文件的例子用 Promise 实现的样子:
var fs = require('fs')
var path = require('path')
var Q = require('q')
var fs_readdir = Q.denodeify(fs.readdir) // [1]
var fs_stat = Q.denodeify(fs.stat)
module.exports = function (dir) {
return fs_readdir(dir)
.then(function (files) {
var promises = files.map(function (file) {
return fs_stat(path.join(dir,file))
})
return Q.all(promises).then(function (stats) { // [2]
return [files, stats] // [3]
})
})
.then(function (data) { // [4]
var files = data[0]
var stats = data[1]
var largest = stats
.filter(function (stat) { return stat.isFile() })
.reduce(function (prev, next) {
if (prev.size > next.size) return prev
return next
})
return files[stats.indexOf(largest)]
})
}
这时这个模块的用法变成了:
var findLargest = require('./findLargest')
findLargest('./path/to/dir')
.then(function (er, filename) {
console.log('largest file was:', filename)
})
.fail(function(err){
console.error(err);
});
因为模块返回的是 Promise,所以客户端也变成了 Promise 风格的,调用链中的所有异常都可以在这里捕获到。不过 Q 也有可以支持回调风格函数的 nodeify 方法。
generators
generator 科普
在计算机科学中, generator 实际上是一种迭代器。它很像一个可以返回数组的函数,有参数,可以调用,并且会生成一系列的值。然而generator 不是把数组中的值都准备好然后一次性返回,而是一次yield 一个,所以它所需的资源更少,并且调用者可以马上开始处理开头的几个值。简言之,generator 看起来像函数,但行为表现像迭代器。
Generator 也被称为半协程,是协程的一种特例(别协程弱),它总是把控制权交回给调用者(同时返回一个结果值),而不是像协程一样跳转到指定的目的地。如果要说得具体一点儿,就是虽然它们两个都可以 yield 多次,暂停执行并允许多次进入,但协程可以指定 yield 之后的去向,而 generator 不行,它只能把控制权交回给调用者。因为 generator 主要是为了降低编写迭代器的难度的,所以 generator 中的 yield 语句不是用来指明程序要跳到哪里去的,而是用来把值传回给父程序的。
2008 年 7 月, Eich 宣布开始 ECMAScript Harmony(即 ECMAScript 6)项目,从 2011 年 7 月开始,ECMAScript Harmony 草案开始定期公布,预计到 2014 年 12 月正式发布。generator 就是在这一过程中出现在ECMAScript 中的,随后不久就被引入了V8 引擎中。
Node.js 对 generator 的支持是从 v0.11.2 开始的,但因为 Harmony 还没正式发布,所以需要指明–harmony 或–harmony-generator 参数启用它。我们用 node --harmony 进入 REPL,创建一个 generator:
function* values() {
for (var i = 0; i < arguments.length; i++) {
yield arguments[i];
}
}
注意 generator 的定义,用的是像函数可又不是函数的 function*,循环时每次遇到 yield,程序就会暂停执行。那么暂停后,generator 何时会再次执行呢?在 REPL 中执行 o.next():
>var o = values(1, 2, 3);
> o.next();
{ value: 1, done: false }
> o.next();
{ value: 2, done: false }
> o.next();
{ value: 3, done: false }
> o.next();
{ value: undefined, done: true }
>
第一次执行 o.next(),返回了一个对象{ value: 1, done: false },执行到第四次时,value 变成了 undefined,状态 done 变成了 true。表现得像迭代器一样。next() 除了得到 generator 的下一个值并让它继续执行外,还可以把值传给 generator。有些文章提到了 send(),不过那是老黄历了,也许你看这篇文章的时候,本文中也有很多内容已经过时了,IT 技术发展得就是这样快。我们再看一个例子,还是在 REPL 中:
function* foo(x) {
yield x + 1;
var y = yield null;
return x + y;
}
再次执行 next():
>var f = foo(2);
> f.next();
{ value: 3, done: false }
> f.next();
{ value: null, done: false }
> f.next(5);
{ value: 7, done: true }
注意最后的 f.next(5),value 变成了 7,因为最后一个 next 将 5 压进了这个 generator 的栈中,y 变成了 5。如果要总结一下,那么 generator 就是:
- yield 可以出现在任何表达式中,所以可以随时暂停执行,比如 foo(yield x, yield y) 或在循环中。
- 调用 generator 只是看起来像函数,但实际上是创建了一个 generator 对象。只有调用 next 才会再次启动 generator。next 还可以向 generator 对象中传值。
- generator 返回的不是原始值,而是有两个属性的对象:value 和 done。当 generator 结束时,done 会变成 true,之前则一直是 false。
可是 generator 和回调大坑有什么关系呢?因为 yield 可以暂停程序,next 可以让程序再次执行,所以只需稍加控制,就能让异步回调代码顺序执行。
用 generator 平坑
Node.js 社区中有很多借助 generator 实现异步回调顺序化的库,比如 suspend 、 co 等,不过我们重点介绍的还是 Q。它提供了一个 spawn 方法。这个方法可以立即运行一个 generator,并将其中未捕获的错误发给 Q.onerror。比如前面那个解方程的函数,用 spawn 和 generator 实现就是:
....
(function calculate(i) {
Q.spawn(function* () {
i = yield Q.all([qTail(res[i],res[i+1]),qHead(res[i],res[i+1])])
.spread(function(tail,head){
variables[i] = tail;
res[i+1] = head;
return i+1;
})
if(i === l-1) {
variables[i] = res[i];
console.log(i + ":" + variables[i]);
process.exit();
}else {
calculate(i);
}
});
})(0);
...
代码和前面用 Promise 实现时并没有太大变化,只是去掉了 then,看起来更简单了。不过记得执行时要用 >=v0.11.2 版本的 Node.js,并且要加上–harmony 或–harmony-generator。你会看到和前面相同的结果。至于寻找最大文件那个例子,在 spawn 里定义一个 generator,然后在有 then 的地方放上 yield 就行了。具体实现就交给你了。
由于篇幅所限,本文没有展开介绍 Promise 和 generator 在错误处理上的优势,这在实际工作中也是很重要的部分,应该认真研究。参考资料 7 中对此介绍得比较详细,建议认真阅读。
参考资料
- Managing Node.js Callback Hell with Promises, Generators and Other Approaches ,Marc Harter,2014.02.03
- 在 Node.js 中用 Q 实现 Promise – Callbacks 之外的另一种选择
- 指令式 Callback,函数式 Promise:对 node.js 的一声叹息
- How-to Compose Node.js Promises with Q ,Marc Harter,2013.08.14
- Analysis of generators and other async patterns in node
- generators in v8 ,Andy Wingo,2013.05.08
- A Study on Solving Callbacks with JavaScript Generators ,James Long,2013.06.05
- V8 JavaScript Engine-Issue 2355:Implement generators
- 本文源码




