
经典书籍《持续交付》[1] 的作者曾就分支合并和代码演化等问题详细地讨论过滥用分支对持续集成的负面影响。而我今天要说的是这样一个故事,一个只能申请到非常有限的硬件设备的团队,他们是如何在多分支策略下实践持续集成的。
一个团队接手了一个项目,需要在开发新特性的同时维护几个发布分支。团队计划实践持续集成,但手头的硬件资源严重不足,无法满足所有分支的部署流水线同时运转。
流水线分为三个阶段,分别是:
- commit 编译、单元测试和部分集成测试并打包
- at 部署应用程序并运行自动化验收测试
- uat 部署应用程序并由测试工程师执行手工验收测试
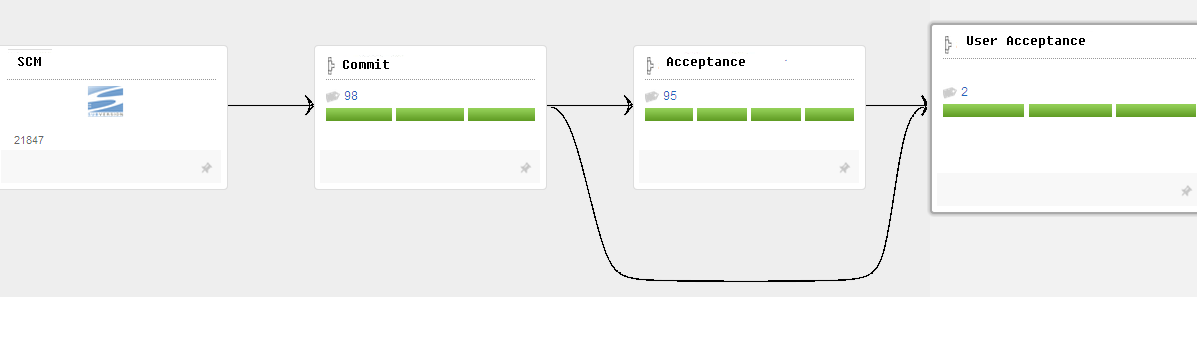
这里我们略去了性能测试阶段和发布阶段,它们一般需要额外安排硬件设备,与这个故事关系不大。流水线的每一个阶段都可能依赖于某些外部服务,比如Web容器、数据库等。为防止不必要的干扰,每个阶段通常会尽可能地使用专用的外部服务,测试工程师在 uat 阶段做手工测试时可不喜欢Web容器由于at阶段被触发而被重启。
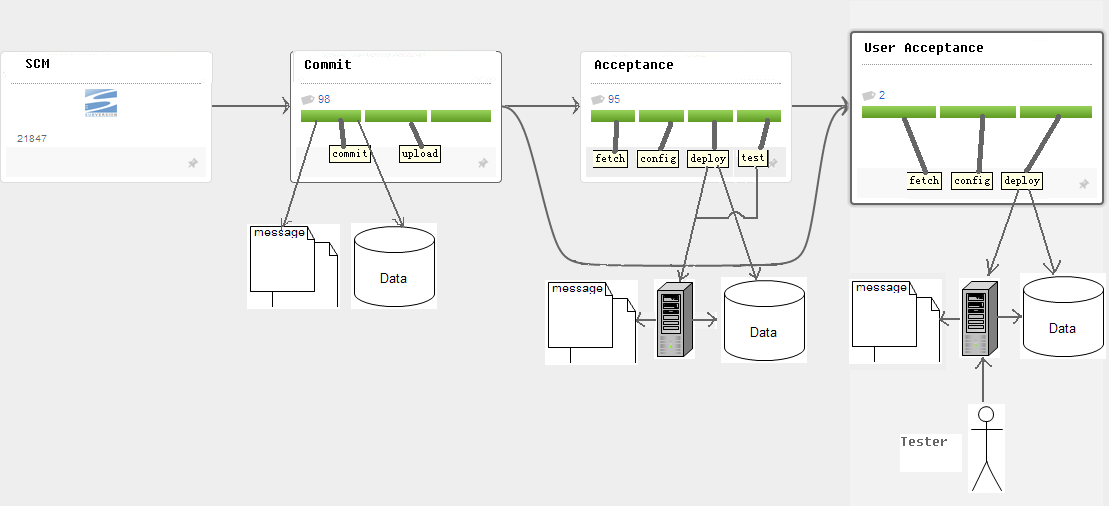
长生命周期的分支同主干一样也需要部署流水线,也就需要更多的外部服务。如果主干的 at 阶段依赖于数据库,那么某个发布分支的 at 阶段也同样需要依赖于数据库。而通常你得为它们准备不同的数据库实例以防互相干扰。外部服务的安装和运行是需要硬件资源的,在资源拮据时,分支无疑加剧了这个问题。由于一些特殊情况,在好几个项目中我们只申请到了一台破旧的 PC server 作为团队的测试设备。但我们并不打算因此放弃持续集成,所以让我们看看能不能在螺蛳壳里做道场吧。
相对其他外部服务,数据库是一个吃硬件资源的大户。这个项目的生产环境将使用 Oracle 数据库,如果流水线的每个阶段都是用独立的 Oracle 实例,那么一个主干和两个发布分支就需要 9 个 Oracle 实例。
在流水线的某些阶段,可以使用一些替代方案,比如commit阶段,可以把持久化测试运行在embedded的hsqldb上,这样可以去除此阶段对数据库实例的需求,而且这样commit阶段的构建时间应该会有所减少 [2]。
后续 at 和 uat 的功能验收测试最好运行在与生产环境相同类型的数据库上。我们曾考虑过采用增量式的数据库开发策略 [3],那么不同阶段、不同分支的数据库模式(schema)应该是兼容的,这样就只需要一个数据库实例。不过这个技术门槛比较高,而且不同分支的流水线的测试可能由于清理和准备测试数据而互相干扰。于是我们决定利用数据库用户 [4] 来隔离不同的环境,比如主干的at环境使用用户at_trunk,而分支的at环境使用at_branch_0816。
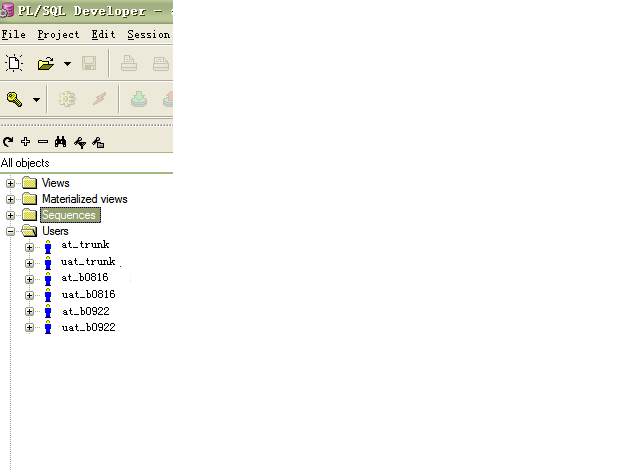
这对应用程序的代码和架构有更高的要求,由于数据库用户名变为环境相关配置了,就必须去除硬编码,例如在 SQL 语句中不能有明确的用户名
select * from billing.t_order where .....
改为
select * from t_order where .....
其实这种限制也有其好处,减少了团队不经意地使用数据库集成 [5](比如直接操作另一个用户中的数据)的机会,从而更谨慎地设计系统边界和集成方案。不过,若要改造使用数据库集成的遗留系统,还得曲线救国,先把其置入部署流水线的反馈循环再做改动,这时对于跨数据库用户操作可以采用数据库同名来处理,比如 Oracle 支持将另外一个用户的数据库对象映射到本用户的一个同名对象:
-- Create the synonym create or replace synonym t_billing_order for billing.t_order;
记得将这个脚本参数化,可以使用 Ant 和占位符替换,在执行脚本前,替换相应环境的用户名。
Web 中间件是另一个大头,不过这里目前团队也没发现有什么特别的办法。可以考虑在部署脚本中使用参数化的 contextPath,这样在同一个 Tomcat 或是 Weblogic 中可以部署多个环境的应用程序,但是这样一来加大了配置难度,二来节约的资源有限,所以基本上还是通过一个环境一个 Tomcat 或是一个 Weblogic 的一个 Domain 来实现的。
如果应用程序还依赖消息组件,那么还应该准备流水线各阶段专用的消息中间件。不像数据库,共享消息中间件而引发的问题比较隐蔽。有一次,我们正在为一个应用程序做发布前的回归测试,此前都没有发现问题,正当我们认为高枕无忧时,这个环节的测试却由于应用程序无法收到消息而失败。当时距离发布截止期的时间紧迫,我们被迫暂时放弃了异步消息的方案,改用同步处理。后来,我们发现问题的原因在于多个 Consumer 监听同一个消息队列,而一个意料之外的 Consumer“抢走”了我们的消息。
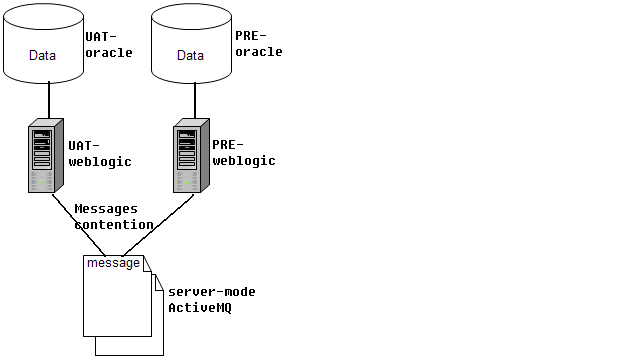
如你所见,我们只有一台 server 模式的 ActiveMQ,而手工测试环境和试生产环境都监听其中同一个消息队列,手工测试环境的应用程序消费了试生产环境的应用程序发出的消息。于是我们另外搭建了一台 server 模式的 ActiveMQ,让它们分别监听,问题就解决了。这件事让我意识到,作为一个有状态的组件,消息中间件也是环境敏感的。当然,一个好消息是消息中间件需要的硬件资源一般没有数据库那么多(多安装一个 ActiveMQ 和多安装一个 Oracle 实例相比),所以最简单的做法就是再装一个。但如果你的环境比较多(从而导致 ActiveMQ 比较多)时,也是很头疼的。一是由于消息是需要持久化的,所以每个 ActiveMQ 是需要一些自定义的配置的。如果你使用数据库作为消息存储,还得让不同的 ActiveMQ 依赖于不同的数据库实例,或至少是不同的用户,如果是文件存储,那么需要指定不同的目录,总之需要细心的配置。二是团队成员有可能被这些 broker 地址搞的晕头转向。有一段时间,我经常听到这样的对话:
John: 现在测试环境 8 月 16 号的发布分支用的是哪个 MQ?(看来这家伙被指派了一个缺陷修复 )
Jane: 我看看……(一小会之后),是 tcp:// 192.168.1.13:61617
过了一会……
Andy: 现在测试环境 8 月 28 号的发布分支用的是哪个 MQ?
Jane: 我看看……(一小会之后),是 tcp:// 192.168.1.14:61617
事实上,有时不同的开发人员会向配置管理员询问同一个发布分支的 broker 地址。由于它们不容易与对应的环境联系起来而且多少还是需要占用一些硬件资源的,于是我们决定裁剪 ActiveMQ 实例。
首先改造的是集成测试。我们原来为流水线的 commit 阶段准备了一台 Server mode 的 ActiveMQ,但其实在集成测试中,我们更关心的是集成的代码和相关的配置。这时可以使用 embedded mode 的 ActiveMQ 替代,这样它们就变为了环境不敏感了,而且由于不需要持久化,每次集成测试都可以运行在一个“干净”的环境中。
runtime.properties: runtime.messaging.broker.url=vm://localhost:61616?broker.persistent=false
不过 embedded mode 不能解决所有问题,当流水线晋级到自动部署后的自动化验收测试或手工验收测试时,还是 server mode 的 ActiveMQ 在排查问题时更方便。我们发现,应用程序并不是对整个消息中间件依赖,而是对消息中间件中的某个队列依赖,而不同的队列之间是不需要相互通信的,所以其实我们只需要一台 server mode 的 ActiveMQ,让不同的环境依赖于不同的队列就可以了。这就要求不同环境使用不同的队列名字,但是队列的名字一般是通过代码中硬编码 /properties 文件配置或是通过 JNDI 查找的,我们也不想因此增加配置负担。因此使用了使用环境名 + 固定队列名的队列名字拼接办法,比如:
notificationReceivedQueue --> commit.notificationReceivedQueue --> uat.notificationReceivedQueue --> pre.notificationReceivedQueue --> pro.notificationReceivedQueue
于是我们引入了一个 Configurations 类,它有点类似于一个 Facade,提供易用的接口:
public class Configurations { private String jmsEnvironment = "commit"; public String getNotificationReceivedQueueName() { return jmsEnvrironmentSpecified("notificationReceivedQueue"); } private String jmsEnvrironmentSpecified(String destinationName) { return jmsEnvironment + "." + destinationName; } }
而配置中,可以使用 spring el 来注入队列名称
xml queue-name="#{configurations.getNotificationReceivedQueueName() }"
这样,开发人员可以只访问一个 broker,而通过队列名称来查找他的目标,uat0816.notificationReceivedQueue 的可读性可要好多了。

实践持续交付是一个长期的渐进式的过程,往往会遇到各种个性化的问题。有的组织硬件资源不足,有的组织硬件资源充足,但还不能做到自动化环境管理。于是许多准备尝试部署流水线的团队会在流水线环境准备上遇到困难,希望这个故事能对这样的团队有帮助。有时候,外部环境或自身资源的限制也不完全是件坏事,这使我们停下细细思考,到底流水线的方案还有哪些可以改进的余地,办法总比困难多。
[1] 《持续交付——发布可靠软件的系统方法》by Jez Humble & David Farley
[2] 虽然 hsqldb 提供了与 oracle 不错的兼容性,但团队需要留意一些细节上的差别。
[3] 即不修改数据库,只增加新的数据库对象或是在现有对象上新增字段等,一般情况下应用程序比较容易做到对此的兼容性
[4] 据我所知创建一个新的用户所消耗的硬件资源很少,主要是其本身数据的存储空间,如果团队对测试数据进行管理的话,这个测试数据集应该不会太大。
[5] 轻易的使用数据库集成很容易抵消你所做的解耦努力。各个模块和子系统表面上看来还不错,但当数据结构改动时牵一发而动全身。
作者简介
周宇刚( @黛丽被我抢了)是一位乐于磨练技艺的开发者。他的研究和兴趣包括 IT 架构、领域驱动设计和敏捷实践。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论