
Microsoft 正在实验用人工合成 DNA 实现数字化数据存储,并于最近向遗传学初创公司 Twist Bioscience 购买了一千万条 DNA。
据悉 Microsoft 有关 DNA 存储的实验是与华盛顿大学(University of Washington)合作进行的。联合研究团队最近提交了一份描述下图所示完整 DNA 归档存储系统架构述的论文。
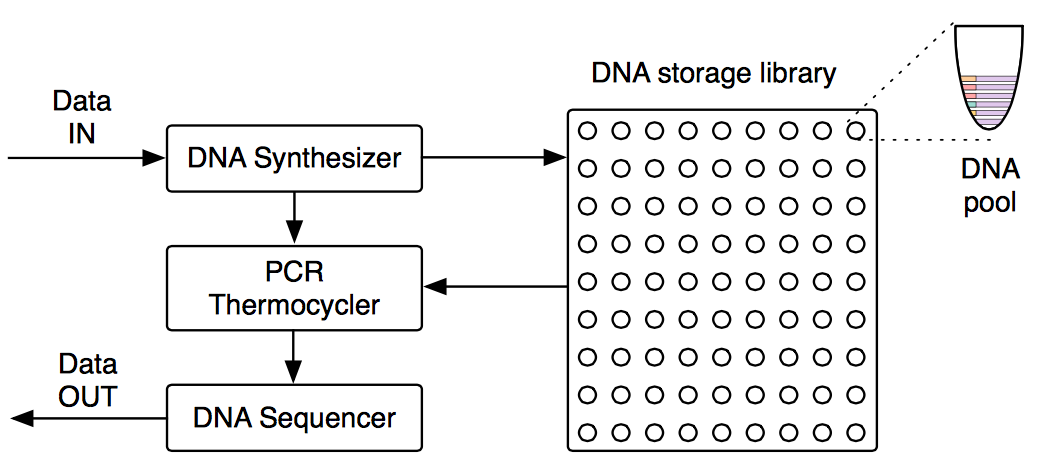
DNA 存储系统由一个对数据进行编码,以便将数据存储在 DNA 中的 DNA 合成器;一个包含大量“隔间”,将 DNA 的存储池与数据卷进行映射的存储容器;以及负责读取 DNA 序列并将其重新转换为原始数据的 DNA 序列器组成。
DNA 存储技术目前有个非常有趣的问题需要解决:寻址。DNA 链是 DNA 存储的基本单位,DNA 链由大约 100-200 个核苷酸组成,可存储 50–100 比特信息。这意味着一个典型的数据对象需要映射至大量 DNA 链。研究人员目前使用了键 - 值架构,因此这里的关键在于首先需要关联至包含所需链的池,随后通过随机访问机制访问池中的链。
另一个有趣之处在于数据的呈现方式。DNA 由 4 个碱基(A、C、G、T)组成,因此 base-4 是最直接的数据呈现方法,例如 01110001 可通过 base-4 的方式转换为 1301,并映射为 DNA 序列中的 CTAC 结构。然而除此之外,研究人员还选择了一种 base–3 呈现方式,借此可通过一个核苷酸实现纠错。那么在上述的例子中,01100001 可转换为 base-3 格式的 01112,并映射至为 DNA 序列中的 CTCTG 结构。
有关 DNA 存储原理的详细信息,包括如何通过编码改善可靠性,以及目前进行过的几个实验,可参阅上文提及的 PDF 论文。
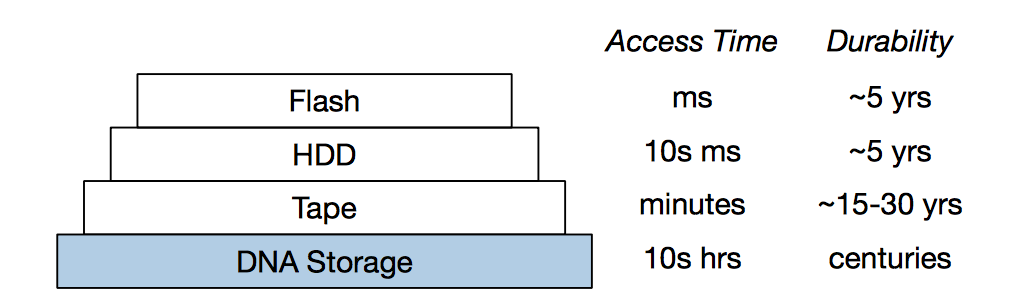
根据 Twist Bioscience 公司介绍,相对传统数字化存储,基于 DNA 的归档技术可提供两个重要优势:寿命更长,最新研究数据显示 DNA 数据存储的寿命高达 2000 年;并且数据密度更高,一克 DNA 即可存储一兆 GB 数据。
根据 Microsoft 和华盛顿大学研究人员的介绍,DNA 存储并不是闪存或硬盘的替代品:
我们将 DNA 存储视作一种最持久的深层存储体系,可提供高密度且持久的归档存储方案,以及数小时乃至数天的访问时间。
这种想法的重点在于,DNA 的合成和排序可以任意程度的序列化方式进行,因此可以轻松获得所需的读写带宽。
Microsoft 公司 DNA 存储项目主管 Doug Carmean 澄清说,他们使用 Twist 提供的 DNA 进行初步测试“证明了数字化数据可通过这种方式进行编码,并可 100% 还原为原始数据”,但在这种技术正式商用之前还有很多工作有待完成。
作者:Sergio De Simone
阅读英文原文: A Look at Microsoft DNA Storage
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论