整个 Web 世界正在发生剧烈的转变,包含语义注解的 Web 页面让数据的提取和重用变得越来越容易,而为了提供更好的用户体验搜索引擎和社交媒体网站对这种数据的使用也越来越多。要获取这些数据离不开网络爬虫的支持,为此,Yahoo 创建了 Anthelion 项目,一个旨在爬取语义数据的 Nutch 插件,最近,该项目已在 GitHub 上开源。
Anthelion 是为了更好地爬取嵌在 HTML 页面中的结构化数据而设计的,它采用了一种全新的方法来爬取含有丰富数据的页面上的内容:将线上学习和 Bandit 探索方法有效地结合起来,根据页面上下文以及从之前页面提取到的元数据反馈预测 Web 页面的数据丰富程度。 这种方法明显优于主题爬取(Focused Crawling)目前所采用的其他技术,极大地提升了爬取效率。
整个数据爬取的流程如下:
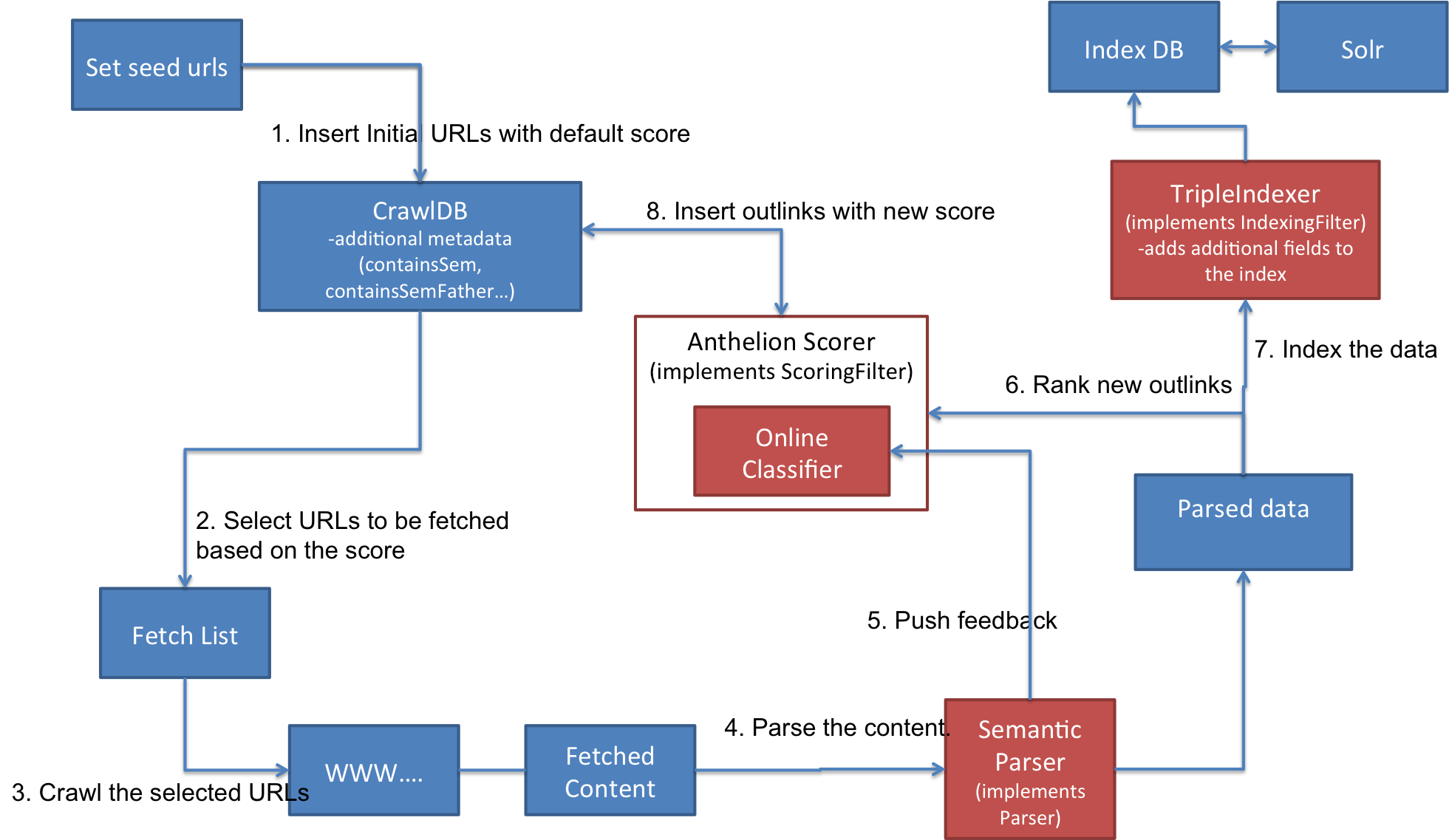
正如上面的流程图所展示的,为了执行主题爬取,该插件实现了三个扩展:
- AnthelionScoringFilter(实现了 ScoringFilter 接口):在线分类器,它对每一个外链打分,同时将新发现的外链分为相关的和不相关的两类。
- WdcParser(实现了 Parser 接口):解析 Web 页面内容并提取语义数据。该扩展基于 any23 类库实现,能够从 HTML 中提取 Microdata、Microformats 和 RDFa 注解。
- TripleExtractor(实现了 IndexingFilter 接口):将新域存储到索引中供之后的查询使用。
对于想亲身感受 Anthelion 的用户而言,直接从GitHub 上下载整个项目包或许是一个不错的选择,因为它包含了完整的Nutch 1.6 代码和相关插件,不需要任何修改和设置就能运行。如果只想下载插件,那么需要从文件的根目录下下载 nutch-anth.zip 并进行相关的设置。
在构建好项目之后,导航到\target 文件夹,执行 CCFakeCrawler 类的 main 函数就能启动爬虫,例如:
java -Xmx15G -cp ant.jar com.yahoo.research.robme.anthelion.simulation.CCFakeCrawler [indexfile] [networkfile] [labelfile] [propertiesfile] [resultlogfile]其中,indexfile 是 ID 和 URL 之间的映射文件,networkfile 是索引中 ID 的图,labelfile 是满足目标函数的 ID 列表,propertiesfile 是配置文件,resultlogfile 存储性能和爬取流程信息。
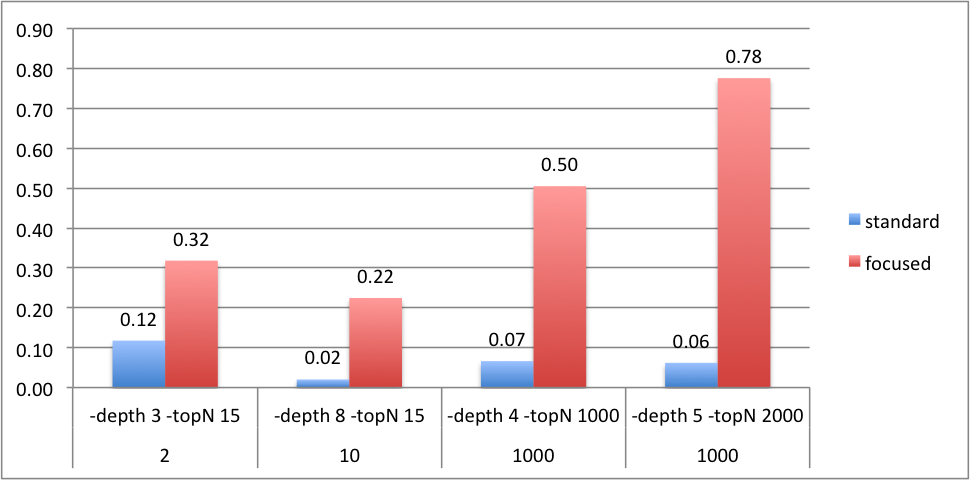
Anthelion 支持 init、start、stop 和 exit 操作,在爬取的过程中,用户还可以通过 status 命令查看爬取进程的状态。另外,对于 Anthelion 爬取数据的精确度 Yahoo 也进行了评测,结果如下:
感谢魏星对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




