
随着互联网 Web2.0 的发展,在应对超大规模和高并发的 SNS 类型的 Web2.0 动态网站等的高性能挑战时,关系型数据库会遇到性能瓶颈。再加上当前移动互联网的发展,关系数据库已经不能满足应用的扩展性、灵活性、高可用性的需要,而 NoSQL 数据库则显得更加能够适应这些需求。NoSQL(即 Not Only SQL),即“不仅仅是 SQL”,它是一种非关系型(结构化 / 半结构化)的数据库,它已经引起了一项全新、革命性的数据库运动,并引发了多种相关协议和算法的研究以及实践,从而总结出了一些行之有效的数据库构建方法。
在专注于大数据、NoSQL 和高扩展性的软件工程方面报道的博客“ Highly Scalable Blog ”中报道了一篇关于 NoSQL 数据库中的分布式算法的文章。在这篇文章里,作者从数据一致性、数据布局、系统协调三个方面以及分布式相关策略(数据复制策略、数据恢复策略、数据分布策略、集群领导选举算法等)对NoSQL 数据库的分布式特点进行了一系列系统化的描述。
在数据一致性方面,鉴于一致性问题是由数据隔离和复制引起,所以文章首先对复制的可用性、读写延迟、读写扩展性、容错性、数据持久性、一致性等特点进行了分析,尤其对一致性中的读写一致性、写一致性进行了详细讨论。还以图例的形式分析了不同复制技术之间的逻辑关系和不同技术在系统的一致性、扩展性、可用性、延迟性之间的权衡以及每个技术的详细情况,如下两图所示:
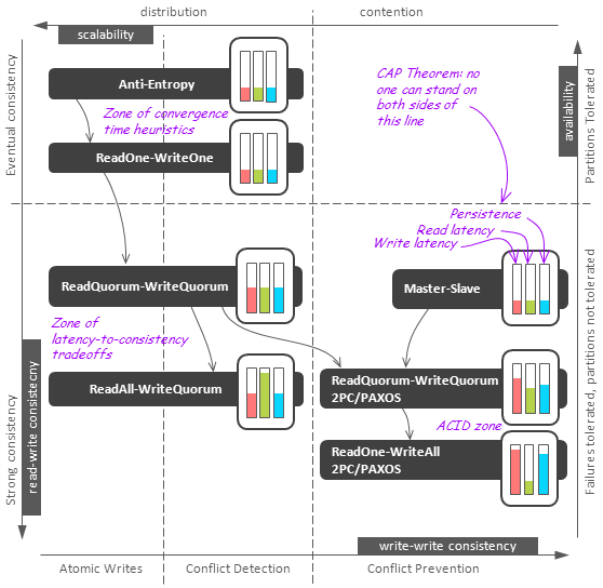
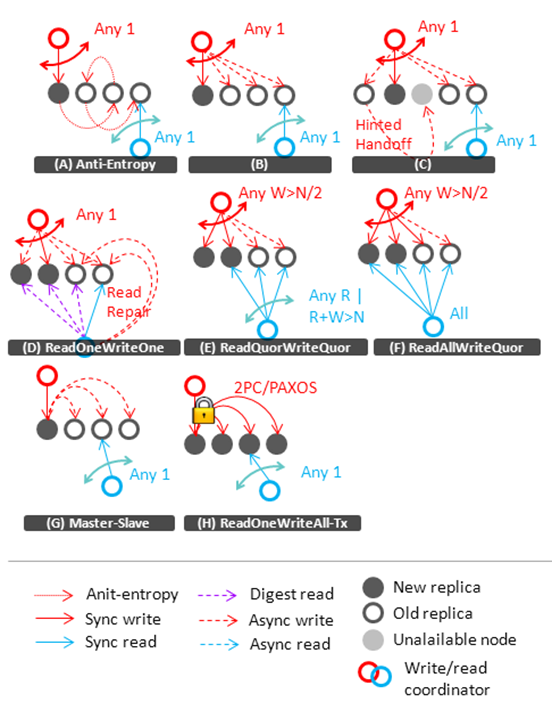
文章还针对能够处理数据一致性维护和集群状态同步的反熵协议以及能够使得所有副本都最终达到语义上正确的数据最终一致性进行了介绍。
在数据布局方面,文章主要讲述了控制分布式数据库中如何高效放置数据的算法。这些算法主要负责把数据项映射到合适的物理节点上以及在节点间迁移数据和分配内存资源。对于如何在集群扩容时做到数据的平衡分配、如何合理在动态环境中进行数据分片和复制以实现把记录合理地映射到物理节点上、如何按照多个属性进行数据分片以及如何合理利用内存而提高数据随机读取性能的要求等方面进行了一一介绍。
在如何系统协调方面,文章讨论了与系统协调相关的故障检测和协调者选举两种技术。故障检测是任何一个拥有容错性的分布式系统必须具有的基本功能,且所有的故障检测协议都是基于心跳通讯机制实现。而真正的分布式系统还有一些额外的功能要求,如能够应对短暂的网络故障和延迟、集群拓扑和负载、应对带宽变化、应对节点失效、应对作业重新分配、分布式系统中失败检测功能的可扩展性和健壮性等要求。协调者选举是保证数据库强一致性的一个重要技术,而 Bully 算法是一种相对简单的协调者选举算法, MongoDB 就用了该算法来决定副本集的主机节点。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论