今天,在各种软件开发项目中,领域特定语言(或者所谓的 DSL)都在逐渐变成一种现实的、甚至必要的方案。你应该已经听说过 DSL 了,也知道它分为两种不同的方格,外部 DSL 和内部 DSL。但是,到底什么是外部 DSL 和内部 DSL?如何在这两种 DSL 中做出选择?更重要的,如何开发复杂的外部 DSL?本文将实际开发一种复杂的外部 DSL,为你解答这些疑问。
领域特定语言的定义
领域特定语言(DSL)是一类计算机程序语言,开发 DSL 可以解决某一个特定领域的问题。“领域”自身有多方面的内涵。它可能特指某一产业,比如保险、教育、航空、医疗等;它也可能是指一种方法或者技术,比如 JavaEE、.NET、数据库、服务、消息、架构以及领域驱动设计。
开发 DSL 语言的目的在于,我们要以一种更优雅、更简洁的方式面对领域中的一些列挑战。之所以能够这样,是因为这个语言刚好够用于解决领域中唯一存在的一系列挑战,一点儿不多、也一点儿不少。当然,其他人如果也想使用同一种语言解决自己的问题的话,必然需要对语言进行一些扩展,但是依然算不上困难。开发 DSL,其目的之一在于让 DSL 更加自然,这有别于通用目的的编程语言以及其他不是特定于领域的工具。
在本文中要重点区分两个概念,内部DSL 和外部DSL。这是两种不同风格的 DSL。理解哪种风格的 DSL 适用于哪种特定的问题域是非常重要的。本文并不会深入探究 DSL 的普遍定义以及内部与外部的 DSL 有什么区别。 Martin Fowler 和其他一些人已经对这个领域进行了思考,并积累了大量的经验。我建议你阅读这些文献以获取更多的细节。不过我会在本文中给出一个基本的理论框架。
内部 DSL
内部 DSL 是指与项目中使用的通用目的编程语言(Java、C#或 Ruby)紧密相关的一类 DSL。它是基于通用编程语言实现的。
Rails 框架被称为基于 Ruby 的 DSL,用于管理 Ruby 开发的 Web 应用程序。Rails 之所以被称为 DSL,原因之一在于 Rails 应用了一些 Ruby 语言的特性,使得基于 Rails 编程看上去与基于通用目的的 Ruby 语言编程并不相同。
如果把 Rails 看作是一种语言,它应该是基于 Ruby、以 Ruby 为根基的,同时它自身也有独立的特性。
我不确定 Dave Thomas( PragDave )是不是把 Rails 都看作一个很大的 DSL,不过他提到过一些 Rails 的特性是由不同的 DSL 支持的。其中一个可以看作 DSL 的示例就是 Active Record Declarations 。通过使用一些特定于领域模型实体关联中的简单术语,Rails 开发者自己可以关注于高层实体的关联概念,而让 DSL 管理背后所有的复杂基础设施和操作。
无论 Rails 的创建者或者它众多的使用者将完整的 Rails 看作 DSL,还是将其一些特性(Active Record Declarations)看作 DSL 都不重要,我在此讨论的是内部DSL。这种风格的 DSL 之所以被贴为“内部”的标签,是因为它与基本的编程语言关系紧密,并且实现于其上,同时 DSL 中包含了一些其他的技术,使它自身看上去更像是一种特定的编程语言。
根据 Martin Fowler 和 Eric Evans 的观点,框架或者程序库的 API 是否满足内部 DSL 的关键特征之一就是它是否有一个流畅(fluent)的接口。这样,你就能够用短小的对象表达式去组织一个原本很长的表达式,使它读起来更加自然。
我从事设计和使用流畅的 API 的工作已经有一段时间了。比如,我早期关于流畅 API 的主要经验都集中于 Smalltalk。在 Smalltalk 的世界里,有两种方法可以开发和使用流畅的 API。第一种是你可以让一个对象消息表达式(方法调用)的结果(返回值)成为下一条消息的接收者:(你可以使结果成为新的消息接收者)
1 + 2 + 4
在上面的这行代码中,数字(对象)1 接收到消息“+”,参数为数字(对象)2,运算后的结果是数字 3(隐式。的);数字 3 又成为下一个消息“+”的接收者,参数为数字 4。(为了保持清晰,在 Smalltalk 中数字字面量不是原生类型,而是第一类对象。)这当然对我们所有人来说都是非常自然的,甚至于都没有从编程的角度去考虑。这就是问题所在了。我可以用下面的代码完成同样的事情:
result := 1 add: 2.
result := result add: 4.
但是这看起来既不自然,也不流畅。第一个流畅的表达式清楚地告诉你结果是 7;而第二个却不然。对于 Smalltalk 来说,由于这项技术并不只局限于数字数学领域,Smalltalk 语言骨子里的流畅性很容易应用到很多不同领域的领域特定方面中去。另外,我建议你看一看 Smalltalk 的级联(cascades)特性,它是第二个支持流畅接口的语言特性。这里我只示范了第一种方法,因为现在的面向对象语言都支持这种方法(但有时支持的方式与此不同)。
这里的重点在于,对于 API 的流畅性而言,它的目的是为了可以更优雅、更有效地解决给定的领域问题,即使是领域专家看了也会感到很自然。这便是所谓的 DSL 了。
当然了,对于这个问题本是仁者见仁、智者见智的。对于给定的 API,我们是否把它看作是 DSL,完全取决于我们的选择。不过一定要认识到 Martin Flowler 和其他人将我上文说描述的内容视为内部 DSL。它们正在业界的想法上和做法上产生越来越大的影响。这个术语我们先暂时留在这里,待会儿还会再次讨论它。
按照我的经验而言,当需要一套技术 API 并且提供给程序员使用的话,我们会不自觉地设计并且开发内部 DSL。如果承载内部 DSL 的通用目的编程语言具有非常丰富的特性,支持实现内部 DSL,那事情就好办多了。很明显,使用 Smalltalk 和 Ruby 这样的语言能够容易地实现内部 DSL,而 Java 和 C#就稍微复杂一些。流畅的 API 和其他的内部 DSL 的特性,可以让大幅降低程序的复杂度和程序员的开发时间。然而,如果我们打算简化问题,并且让没程序员背景的领域专家们能够发挥更大的能量,很遗憾,内部 DSL 是不足以完成此重任的。
外部 DSL
说实话,在研究和使用领域特定语言的过程中,我从未想过将它与使用、设计、开发流畅的 API 联系起来。我必须得承认,由于流畅 API 具有很长的历史,我很难将这个概念硬塞到内部 DSL 之中。但是我一直在学习。另一方面,当我第一次看到 DSL 的时候,想到我自己的关于创建多种“小语言”的工作,就立刻将这两件事联系到一起了。鉴于此,我相信,如果你觉得理解上面关于内部 DSL 的定义时有些困难,那么这一部分会让你感觉好一些。
为外部DSL 下定义要远比内部 DSL 简单得多。创建外部 DSL 和创建一种通用目的的编程语言的过程是相似的,它可以是编译型或者解释型的。它具有形式化的文法;这意味着,它只允许使用良好定义的关键字和表达式类型。使用外部 DSL 编写的程序源代码可以保存在一个或者多个文本格式的文件中,或者是表格化、甚至是图形化格式文件中。对于文本化的 DSL 来说,你需要一个文本编辑器或者一个功能齐全的 IDE 来编写源代码。然后你编译源代码,让它和最终的程序一起运行;也可以由解释器直接运行源代码。
通用目的编程语言的源代码和外部 DSL 的源代码之间的主要区别在于,经过编译的 DSL 通常不会直接产生可执行的程序(但是它确实可以)。大多数情况下,外部 DSL 可以转换为一种与核心应用程序的操作环境相兼容的资源,也可以转换为用于构建核心应用的通用目的编程语言。
举两个由外部 DSL 转换为资源的实例。第一个是 Hibernate 和 NHibernate 中使用的对象 - 关系映射文件。另一个例子是由 ThoughtWorks 的 Jay Fields 倡导的“业务特征语言(Business Natural Languages)”。他提到一种包含了应用程序所需的元数据(比如验证用户输入的规则)的外部 DSL。你要读取这些元数据,将它转换为一种有效的内部格式,然后在运行时中使用它。
再举两个由外部 DSL 转换为目标应用所使用的源代码的例子。第一个是使用 MetaCase MetaEdit + Workbench 和 Jetbrains Meta Programming System(MPS)开发的语言。另一个例子是 Markus VÖlter 关于“将架构作为语言”的文章。文章中,Markus 可以定义一种软件架构,检验它,然后从文本化的架构描述中生成源代码。
外部 DSL 可以直接用于提高软件开发者们设计和开发的效率,他们会使用它。这种情况下,外部 DSL 会生成源代码,这些源代码再调用由内部 DSL 所呈现的一套流畅的 API。如果恰当地设计外部 DSL,那么没有程序员背景的领域专家们也是能够利用外部 DSL 的。
很多时候,外部 DSL 还需要诸如工具提供的语言支持,才能发挥最大的效力。当外部 DSL 的用户只是一小部分软件开发者(包括 DSL 的作者)的时候,一个简单的文本编辑器就足够了。但是,当 DSL 需要发布到更大的圈子的时候,或者要让没有程序员背景的领域专家们使用的时候,一个具有语法高亮和代码辅助功能的编辑器就是 DSL 能够成功的关键了。除此以外,还有其他一些有益和必需的功能。
语言复杂度
我认为外部 DSL 若能称得复杂,在于:
- 语法分析不容易。解析一个逗号分隔的文本记录文件相对容易一些;而 Java 这样的编程语言相对不容易解析。从某种程度上讲,解析复杂的外部 DSL 的难度介于它们两者之间,而且可能更接近于解析 Java 的难度,而不是解析 CSV。(你可能还想为 CSV 开发一个形式化的文法,不过我认为它的作用不大,如果不做的话可能会更快一些。)
- 语法分析后,需要一种复杂的内部表现形式。复杂的内部表现形式是一棵树或者对象图,它包含了针对源代码中的表达式进行优化和便于处理的形式。这个表现形式还要支持验证,还要支持解释和\或生成工具。
- 要能够从一个或者多个源文件生成一个、几个甚至更多复杂的目标工件。当然,需要这样做的前提是你的语言不仅要被解释执行,还要用于其他的生成工具。试想,如果你的目标工件和源 DSL 的区别并不大,那么就需要反问自己,为什么不直接使用目标语言呢?
了解了语言复杂度之后,你会问,究竟如何真正实现一个复杂的外部 DSL 呢?下面我将阐述这个问题。
设计与开发
任何一种复杂语言的设计与开发都是一个巨大的挑战。即使你对即将实现的语言有很多不错的想法,在处理它众多复杂的细节时,仍然免不了受到挫折。这就好像你认为自己已经找出了所有的语言特性,并且也设计好了语法,这时未来的使用者(包括你自己)又想到了一些新的东西。而这种情况比起设计一种通用目的编程语言来说,要显得更加频繁了。
当然了,就像任何有价值的东西一样,一种语言也要经历一次又一次的改进。在这个过程中,我们要确保能够支持那些改进。因此,语言的设计也需要拥抱变化。更进一步讲,一个好的语言设计应该使得语言未来的改进更容易。
我在本节里提到了很多种语言语法,包括图形的与文本的。不过我必须将范围限制在一种语法上,这样才能保证文章有一个合理的长度。因此,我选择关注在文本的 DSL 上。文本 DSL 更易理解,即使正在使用一个图形 DSL,文本 DSL 仍然是能够接受的(原因见下文)。
为今天和未来设计语法
所幸大多数的语言设计者不会在某天早上醒来时说“今天我要设计一种新语言,我想知道它将会是什么样子的”。如果我们正在考虑开发一种新的语言,那么最好先想清楚“为什么”。这一点非常重要,因为如果我们对语言没有一个清晰的远景,最终的设计将会一文不值。因此,语言设计的第一个重要步骤就是搞清楚你希望自己的语言能够做什么。
仅仅知道语言应该做什么还不够,它不足以让你明确语言的语法。一个语言的语法不仅是其可用性的关键,并且还会影响到对语言进行改进的能力。不过,语言的语法首先要适合它的受众。如果语言的使用者具有计算机技术背景,甚至就是程序员,那么语法的选择就会有别于为不具备程序员背景的领域专家们设计的语言。
在讨论语法的时候,尽管后文将一直关注于文本 DSL,但是此时我并没有把上下文限定在它上面。你可能会让语言拥有两种语法:一种用语言用户界面表示;另一种则保存在文件中,并被进一步分析和翻译。对于这种情况,你可能会将以使用者为核心的语法实现为一个图形用户接口(比如带有行与列的表格),或者是一个基于图形的语言(类似于 Visio 图),这样使用者不必关心语法,只要将它们画出来即可。在后台文件的层次上,你的语言可以按照需要尽量技术化。我们倾向于考虑将图形化的语法用作模型,但是模型并不局限于图形;这就好像复杂的 DSL 并不局限于文本一样。一会儿你将看到,有时你能从模型的角度来考虑语言,而忽略其语法的形式。
如果某个偏重于技术的 DSL 语法不够灵活,不支持未来的改进,这会影响到向后兼容性,甚至彻底牺牲向后兼容性。也就是说,你加入了一个新特性,导致改进前的源代码全部失效了。我相信,如果需要支持多重语法的话,这种风险将更加明显。当然,你可以提供一个源文件(模型)的更新转化工具。然而即使文件语法更新工具有一定的帮助(这还要取决于对语法进行了什么类型的改进以及改进自身的复杂度),但它们仍然不会受到用户的青睐,也会阻碍进一步的更新。
关于如何选择一个适当的、可扩展对语法,我有一些建议。越排在前面的建议越应该在设计语言之初进行尝试:
- 研究其他语言。思考为什么像 Java 和 C#语言要设计成现在的样子,并且获得成功。可以肯定的是,Java 和 C#的语法设计是为了迎合社区中的开发者,而这些开发者大都有使用其他语言的经验。不过,还有其他原因。利用块来区分作用范围的语言,其本质上就是可扩展的,因为不同类型的新块可以加入并嵌入到相应的现有块之中。这并不是说你不能重新发明这类语言。你应该在自己的语言中重用那些获得成功的语言的优秀方面。你也应该钻研一下像 Ruby、Smalltalk、Perl 和 Python 等语言。你喜欢它们的什么?不喜欢什么?如果你能修改和融合各种不同的语言,你会怎么做?你能利用当前语言的成功因素去改进你的语言吗?
- 利用敏捷技术不断试验不同的语法构思。写不同语法时的感觉如何?其他人对这种语法怎么看?这种语法能够被定义为形式文法吗?支持你最喜欢的语法的工具会是什么样的?
- 尽可能多地寻找语言的特性。像建议 2 中所说,试验能够支持 70%-80% 这些特性的语法,忽略剩下的 20%-30%。当你认为已经得到了一个足够吸引人的语法时,再考虑怎样增加对剩下的特性提供支持的语法。语言的第一个版本是脆弱的还是可扩展的?除了那些被推迟增加的语法特性以外,还可以故意实现一些错误的语法。考虑一下如何修正这些错误,并且问问自己:如果必须同时支持错误的语法和经过改进的语法,你应该怎么办。哪些行径可以减轻或者加重语法的问题,有什么方法能够更容易修复语法问题?
- 提前将你的语言展示给它潜在的用户。他们认为这个语法怎么样?它会不会令一些人产生胁迫感?要让使用者感到这种语言确实解决了他们的实际问题。
- 对你的语言进行 Beta 测试。在语言处于 0.9 版本的时候,如果出现什么大的变动,用户会相对容易接受一些;如果到了 1.0 版就麻烦了。Beta 测试者的反馈有可能对语言产生很大的影响。
当然,如果你在开发一个图形化的 DSL,它永远不会被用在图形环境之外,那么最恰当的选择无疑是 XML。但是我永远不会建议别人直接使用 XML schema 作为文本 DSL 的文法。想像一下你的客户编写 Ant(或者 Nant)的场景,你就能明白我的意思了。Martin Fowler 曾经说过,“XML 很容易解析,但是作为一种自定义数据格式其可读性却太差了。很多人都觉得满篇的尖括号太伤眼睛,于是为 IDE 加入插件来辅助处理 XML 文件。”现在,你是否愿意设计一个可直接编辑的文本 DSL,来避免像瘟疫一样的基于 XML 的文法。
关于 DSL 文法最后再强调一点,一个复杂的文本 DSL 应该是可以使用 BNF(或者 EBNF)以形式文法的形式进行定义的。如果你的语言无法用形式文法表达出来,那么它的分析将会非常困难甚至是不可能的。下面几节会介绍更多关于分析与 BNF 的内容。
设计语言的元模型
假设有一份符合语言文法(语法)的源代码,现在将它想象成你所描述的概念的模型。这里的概念可能是数据、结构、行为等典型的计算机领域的事物。从语言设计者的角度来看,对这些概念的描述不仅仅是源代码,更是一个模型。因此,你要分析蕴藏在源代码中的模型,并把表现性的内容放在某个对象中,而这个对象就叫做元模型。
如果语言的源代码被加载到一个抽象语法树中(AST),那么这个 AST 也可以算一个元模型。虽然 AST 和语法非常紧密地绑定到了一起,但是从描述语法抽象结构的角度来看,它仍然是一个差强人意的元模型。我从来不建议将复杂的文本 DSL 载入到 AST 中,而是应该载入到一个更丰富的元模型中。在必要的时候,我喜欢将元模型设计为一个图,这样它看起来更像 Model-View-Controller 模式中的模型层;一个领域模型。这时,图还算不上一个真正的模型,只是源码模型的元模型。(请注意,Martin Fowler 使用术语“语义模型(Semantic Model)”描述我所谓的元模型。他还将这个概念定义为一个对象模型——这也是一类领域模型。)
虽然本文的主题是语法设计,这并不意味着语言元模型的重要性就不如最终语法。事实上,语言元模型对于 DSL 的内部运作的重要性,相当于语法对于语言的接受度和未来改进能力的重要性。由于元模型没有(也不应该)和语法紧密地绑定,所以元模型的设计可以先于语言语法的构建。
举个例子说明这一点,James Gosling 曾经表示过 Java 的形式文法(语法)是一个“冒牌货”(大概在视频的27:00 和60:00 的位置),因为Java 最初的设计并没有考虑类似于C 风格的语法。虽然如此,Java 内部仍然具有接口、类、方法、域、线程、原生类型,并且以字节码的形式存在。Java 为了吸引C/C++ 的程序员,而使用与其类似的语法;如果没有这一因素的影响,Java 的语法或许和今天看到的会有很大的不同。然后有一点可以肯定,即使增加了C 风格的语法,Java 的元模型也不必变化(至少不会有巨变,可能像前置递增和后置递增运算这样的概念会导致一些变化,因为很多非C 风格的语法并不支持那些概念)。这是因为底层的元模型以一种抽象的方式定义了语言的概念,它可以映射到多个语法之上。正是由于这个特性,使得Java VM 成为了Groovy 和JRuby 之类脚本语言的绝佳宿主。
当考虑元模型的时候,应该记住它是个对象模型,包含了从源码模型中抽取的元信息。因此,你的语言中的任何概念都应该在元模型中得以充分的表达。下面看一个熟悉的例子——面向对象语言的元模型。面向对象语言中的“类”应该包括:
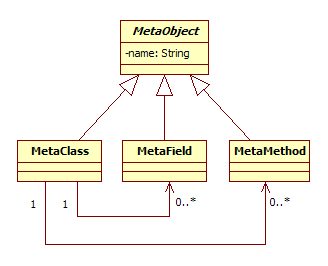
MetaClass 类应该包含关于源码模型所展现的类的元数据。例如,如果源代码定义了一个名为 EmailAddress 的类,那么你必须创建一个 MetaClass 实例,它的 name 属性(域)为字符串“EmailAddress”。MetaClass 还包含 MetaField 实例的集合以及一个 MetaMethod 实例的集合。如果原型类 EmailAddress 有一个域名为 address,那么对应的 MetaClass 至少要包含一个 MetaField 的实例,它的 name 属性(域)为字符串“address”。进一步说,每个 MetaField 的实例都应该有一个指向 MetaClass 的引用。因此,元模型最终表现为一个图。
元类可以用在与这个例子类似的情况下,但是不能用在你的 DSL 所表达的特定的模型上。我建议使用一个以抽象基类 MetaObject 为根的元类继承体系。MetaObject 为所有的元子类提供默认的状态和行为。例如,可能你的语言所支持的很多元对象都有一个名称。这时 MetaObject 应该包含一个 name 属性 / 域,并且让所有子类都能够访问和设置它。在确定了 MetaObject 之后,你可以开始设计元模型的完整的继承体系了。当然,一旦你的元模型发生了变化,你要不断地重构,把公共的属性和行为移到 MetaObject 中。
如果你熟悉 Eric Evan 的“领域驱动开发(DDD)模式”,也可以将这些模式应用到元模型之上,这样,可以把元模型的方法发展到更深的层次。我的 DomainMETHOD 工具就应用了这种方法,它是一套 DSL,能够促进 DDD 的应用,并且能够生成一个可以工作的应用领域层。这样我同时拥有了两个世界的精华:使用 DDD 设计并开发我的工具,并且能够设计、生成一个可运行的基于 DDD 的领域层。工具的设计完全使用实体、值对象、聚合、资源库等等。我从模型源中加载元模型对象的聚合,再将它们存储在 MetaObjectRepository 中。我使用 ProjectRepository 去查找项目配置信息和定制的生成指令,然后创建、查找、存储生成的目标工件,这些工件最终会被存储在输出文件中。我还有一个用于查找、管理源代码模板状态的资源库,它的名字自然是 TemplateRepository。
DDD 是一种可操作的、强大的方法,它可以帮你抽取元模型的概念,并设计、实现元模型。它并非永远有效,这还要取决于 DSL 的特性,但是如果可能,你应该考虑使用 DDD。
元模型与目标模型的关系
在本文中,我已经提到了外部 DSL 的三种潜在目标应用。这里,我要基于元模型重新讨论它们,以说明元模型与目标工件、目标模型之间有趣的关系。
我提到的三个目标应用是:第一,解析 DSL 源码模型并将它翻译为源代码,成为应用程序的一部分;第二,DSL 源码模型能够被解析并在应用程序的运行时被解释执行;第三,DSL 源码模型能够被解析并翻译为另一种形式的数据,应用程序会在运行时消费它。
元模型的第一种应用,即从 DSL 生成并输出源代码,是最直观的、通常也是复杂的情况。根本上说,你需要将一个或者多个源码模型转换为元模型,然后再转换为一系列目标模型(或者源代码)。
后两种情况都与数据格式的解释与翻译相关,它们是相似的,因为一个待解释的模型和任何一种经过翻译的数据不过只是元模型的不同形式而已。本质上说,将分析器构造的元模型转换成另一种应用程序支持的数据格式,这一过程可以看作是模型到模型的转换,而且转换过程甚至是可执行的。不过重点在于它可以保留一个元模型。虽然如此,如果你持久化了将数据格式元模型,而没有将它留在内存中,在生成过程中,不可避免地需要一个持久化转换的步骤。
后面两种形式可能还有其他的不同,因为一个待解释的模型可能还有行为,甚至是行为、状态以及状态转换的混合。但是,如果待解释的目标在本质上是简单的,那么就能够很容易地看出两者间的区别。
生成元模型
你可以免费获得元模型。openArchitectureWare 的 Xtext 工具(现在是 Eclipse Modeling Framewok 的一部分)可以自动为你创建元模型。你要做的只是为 Xtext 定义出形式文法(这一步几乎在任何分析器生成工具中都不可避免),然后让 Xtext 为你生成预期的工件。与元模型一起生成的还有一个分析器。分析器分析 DSL 源码模型的时候,它会实例化元模型中相应的部分,并使得元模型可以用于验证、解释和\或代码生成。这是非常简单的事情。
定义语法分析器
我故意将本节的标题定为“定义语法分析器”,而不是“开发语法分析器”。由于复杂的外部 DSL 会有一个复杂的文法,难以分析,我相信手工设计并编写一个语言分析器是一件费力不讨好的工作。大多数有语法分析经验的人都会同意该观点。很少有哪些开发者能够创建一个自定义的语言词法分析器。即使那些有这方面能力的人,若不是性能问题过于严重,他们差不多都会选择使用一个允许自定义的工具,而不会手写一个分析器的代码,因为第一种选择更简单、快速、有效,减少犯错的机会。
大多数分析器生成器工具都支持使用巴科斯诺尔形式(Backus-Naur Form,BNF)或其扩展版本(EBNF),来描述语言的形式文法(语法)。BNF 提供了一种定义形式语法的规范方式,EBNF 还使这件事做起来更加容易:
INTEGER_LITERAL : ('-')? ('0'..'9')+ ;
正如在上面看到的,EBNF 对 BNF 做了一些改进,增加一些关于可选元素与重复元素的规约。在 INTEGER_LITERAL 的例子中,规范表明一个整数可以包含也可以不包含一个负号,后面接上一个或多个 0 到 9 之间的数字。如果你了解正则表达式,理解这里的内容会更容易些。尽管 EBNF 并不完全等同于正则表达式,但是它们看上去非常接近。
典型的通用目的编程语言的语言文法可能会这样定义它最高级别的文法规则:
prog : expr+ ;
它简单明了地说明程序(prog)是由一个或者多个表达式(expr)组成的。仅仅这些当然还是不够的,有趣的事情才刚刚开始:
expr : ... ;
进一步拆分语言的语法,从最高级别的抽象,到最底层的细节,这需要花很大精力去学习。尽管如此,比起手工编写一个充满 Bug 的词法、语法分析器而言,这种方法仍然简单、快速的多。只要运行分析器生成器工具,只需要一两秒钟,你就可以从正确定义的语言形式文法,获得一个可运行的、免受 Bug 侵扰的词法分析器和语法分析器。更有甚者,如果你的工具还支持 EBNF 的话,你的生产力还能得到大幅度的提升。
目前可以找到很多开源的,或者收费低廉的分析器生成器工具可用。由于众多原因,我非常亲睐开源的 ANTLR(读音是“antler”)。ANTLR 支持用很多种目标语言生成分析器。ANTLR version 3 有一个非常成熟的源码流向前看(lookahead)技术,它能为处理很多令人疯狂的二义性问题,从而替你节省几个小时(甚至几天)的时间。文法二义性是指语言文法的不同部分之间有冲突,从而迷惑了分析器。这个问题本身就非常复杂,我在本文中不可能提供更多的信息。但是相信我,如果你从未体验过这个问题,那你还是别碰到它为好;如果你曾经遭遇过它,那么现在你肯定只想去下载 ANTLR 3,并且只使用它。ANTLR 还允许你为规则的定义传递参数,甚至可以有返回值。其他更多的专业特性难以在这里说清楚。对了,ANTLR 的 EBNF 本身就是复杂外部 DSL 的一个绝佳示例!
大多数现代的分析器生成器允许你在元素的定义中关联定制的代码。分析器分析源码流,当匹配了一个元素的条件后,会在此刻插入你定制的代码。从 DSL 的角度而言,Martin Fowler 将它命名为“外部代码(Foreign Code)”模式,因为对于 EBNF 语言来说,你的定制代码只是个外来者而已。由于你在分析器中插入了代码,因此当分析器遇到匹配的元素时能够做很多事情,比如实例化你的元模型。再回想上面的面向对象语言的例子,下面是它运作的方式(经过简化的片段):
classDef[MetaObjectRepository repo]
: 'class' (ident = identifier) '{' cb = classBody '}'
{
MetaClass metaclass = new MetaClass($ident.text);
// ...
repo.addClass(metaclass);
}
;
当词法单元流具有下列的序列时,分析器会报告匹配了一个 classDef 元素:
- 字符串文本“class”
- 标识符元素(由别处定义)
- 字符串文本“{”
- 元素 classBody(由别处定义)
- 字符串文本“}”
在生成的分析器代码中(此处是 Java),classDef 元素的规则中包含了定制代码,它在两个没有加引号的花括号之间。如果分析器匹配了一个 classDef 元素,就会执行这段代码。这样,一个新的 MetaClass 实例会出现,它的类名等于 ident 变量的文本值。当分析器匹配一个标识符元素的时候,会为 ident 变量赋值(类似的,匹配 classBody 元素的时候会为 cb 变量赋值)。请注意,MetaObjectRepository 的实例 repo 是通过 classDef 元素定义的参数传递进去的,并且可由定制代码所用。一旦新的 MetaClass 被实例化,并且完全构造好以后(代码没有显示),就把它加到资源库中。
这里没有什么魔法。要想完全理解这一切是如何组合到一起的,关键是理解每个 EBNF 元素对会对应生成一个 Java 方法(或者其他分析器目标语言的元素)。因此,生成的分析器中具有一个 classDef 方法,对于 identifier、classBody 和文法中定义的其他元素,都有一个相应的方法。
分析一个或多个模型
你要确定生成一个单独的元模型实例,需要分析一个还是多个 DSL 源码模型。例如,如果原型 DSL 表现了目标原型应用程序的抽象,那么 DSL 的作者就很有可能会创建多个这样的原型。这样,你的分析器就要知道如何找到多个源码模型。
这实际上需要一个简单的目录 - 文件爬虫程序。DSL 工具可以接受一个项目的基路径,然后遍历目录结构,查找所有匹配特定文件扩展名的文件。对于每一个文件,都要进行读取和分析,然后把结果放到一个单独的元模型实例中。 元模型所表现的各种原型之间的关联形成一个图。 一旦多个 DSL 源码模型组成为一个元模型实例,你就可以执行下面三种行动之一了:翻译和生成、解释、或者转换为不同的模型,比如适合你的应用程序的数据格式。
如果你的 DSL 和工具只需要支持从单一的 DSL 源码模型创建元模型的话,分析器可以简单一些。你的工具只需要接受一个单独的源码模型,分析它,构造你的元模型,最后采取上文提到的三个行动之一。
如果需要从 DSL 生成代码或者其他形式的数据,那么下一节你会感兴趣。
生成代码
讨论代码生成的时候请注意,这里的所讨论的原则同样适用于生成数据。通常,生成数据要比生成代码简单一些,所以,我首先解决生成代码的问题。好消息是,如果你要做的工作只是从 DSL 生成一些数据格式的话,你需要用的策略会比这里讨论的简单得多。
通常元模型生成代码的过程看上去似乎非常简单,的确,如果你的 DSL、元模型和目标工件都不复杂的话,这件事确实不会太难。但是,以我的经验而言,复杂的外部 DSL 通常都意味着从它相应的元模型生成代码通常都不简单。我会先从普通的代码生成策略开始,然后介绍一些复杂的策略,重点介绍每种方法的优劣。
直接从源码模型生成代码
代码生成的第一种方法就是根本不创建元模型,直接输出目标工件。这项技术取代了前面所示的全部或至少大部分定制代码,这些定制代码和直接输出到目标工件的代码一起,可以构成你的元模型。如果你的能用上这项技术就不要犹豫。的确,这样你就不必费力地去设计元模型,然后自定义一个分析器来构造元模型,从而可以尽快开始关注核心任务,减少初期启动的开销。
如果你确信自己的 DSL 永远不需要元模型,那么我建议你首先考虑这个方法。唯一的告诫就是,如果 DSL 作为一种抽象,而与目标工件输出非常接近,那么你是不是应该直接编写目标工件的代码而非 DSL 呢?你应该先回答这个问题,这个问题的答案可能是“No”,你自己应该做出判断。
你是否希望通过单个源码模型生成多个目标工件呢?或者通过多个元模型生成多个目标工件?这种情况下,使用直接从源码模型生成代码的方法就有些不切实际了。
遍历(walking)元模型
当你通过 DSL 模型完全构建了元模型之后,就必须要遍历这个元模型,以此决定应该生成什么样的目标工件(源代码、配置文件等)。这需要从一个或者多个主要的聚合根对象开始,然后逐步地向下导航,寻找有意义的元数据,根据这些元数据,执行必要的领域行为。
这种方法的主要问题是,当到达某些元模型上下文的时候,你可能(始终)没有足够的上下文信息让你生成给定的目标工件。那些必要的元数据可能会渐渐地扩散到整个元模型之中:
如果每一种目标工件类型,都对应一个独立的专门的代码生成器,那么你必须多次遍历元模型,才能收集到生成每个目标工件所需的全部元数据。对于每个工件类型,你都要开发多个复杂的导航器,或者将元模型设计成更加复杂的图,让它关联所有必需的上下文的元数据。然而使用任何一种方法来满足导航的需要,都是非常困难的。
基于区域感知工件的事件元模型
对于多次遍历元模型而带来的复杂性,有一种很实际的解决方案,即使用事件元模型。它能由一个简单的发布者 - 提交者模式来实现。设计单独的一个元模型遍历器,它在遇到元模型的关键部分的时候,会产生事件。接着,发布者会发送这些事件。提交者会根据事件及时地生成代码。我自己生成 DSL 代码的过程已经证明了这个模式是非常有效的。
如果不能支持具有区域感知的工件和工作区,事件元模型是不完整的。所有类型的源代码工件都有各自的区域:

当事件发送到每一个代码生成器监听器上的时候,就将新生成的源代码插入到工件中相应的区域中。区域可以通过名称或者索引来管理。嵌套的区域工件管理更强大,因为这样可以按照需要更细致地追踪产生的输出:

但是,如果当生成器接收到一个事件时,它还有没有足够的关于当前元模型、元数据的上下文怎么办?最自然的想法是立即遍历模型,查找你现在需要的东西。但是,如果多一些耐心并有一个工件工作区的话,你可以等待足够的上下文信息,并且更加优雅地生成代码。当事件只发送了不完整的元数据上下文的时候,只要把这些部分的上下文存储到工件的一个良好定义的(唯一的)工作区空间中。当后续的事件发生后,不断地追加到已保存的工作区元数据上。最后,当所有必要的上下文信息全部满足时,各个代码片段也全部创建起来了。这样可以将代码片段从唯一的工作区中取出来,移除工作区空间,然后把完整的代码片段保存到相应的工件区域中:

一旦目标工件构建完成后,可以将它保存在相应的输出文件中。
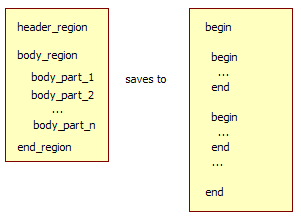
你还要设计一个工件的持久化设备,它要知道如何将内嵌的工件区域填充到正确的工件文件中。
代码模板
除非是待生成的源代码非常简单,否则使用代码模板和模板引擎会更加方便。认真考虑一下使用代码模板。例如,当你捕获到特定的源代码生成事件时,需要创建下面的 C#属性:
private string _address;
public string Address
{
get { return this._address; }
set { this._address = value; }
}
最常见的方法是创建下面的 C#源码片段的文本字符串:
string propertyDef =
“private” + propertyType + “ ” + hiddenPropertyName “;\n” +
“public ” + propertyType + “ ” + propertyName + “\n” +
“{” + “\n” +
indent + “get { return this._” + hiddenPropertyName + “; }\n” +
indent + “set { this._” + hiddenPropertyName + “ = value; }\n” +
“}” + “\n”;
坦白地说,在我写这个例子的时候,曾经疑惑很多次——我到底身处生成代码流中的什么位置。我固然知道如何创建 C#属性,但是试图将这些生成的片段组织在一起其实令人疑惑,不经历几次修改,很难获得正确的生成代码。事实上,我现在也不确定上面的代码是否正确。尽管如此,这个例子还是在生成 C#类的过程中遇到的最简单的代码片段。接下来,我们要考虑使用代码模板和模板引擎。首先看看创建 C#属性的模板:
property(propertyType, propertyName, hiddenPropertyName) ::= [[
private $propertyType$ $hiddenPropertyName$;
public $propertyType$ $propertyName$
{
get { return this.$hiddenPropertyName$; }
set { this.$hiddenPropertyName$ = value; }
}
]]
模板看上去要清晰多了。首先,模板定义需要一个名字、属性并且带有属性集——propertyType,propertyName 以及 hiddenPropertyName,因此它看上去像一个函数或者方法。模板本身(即::==<< 与 >> 之间的所有词语单元。请注意:由于格式的错误,在代码示例中无法显示这些字符,因此我使用 [[和]] 来代替)基本上和你手工编写的 C#代码非常相似,但还是有一些轻微的不同。模板是参数化的,通过用 $ 围起来的字符来标识参数化的值,模板引擎可以查找匹配 $propertyType$(以及其他占位符)的地方,用传递的值代替它们。
调用上面的模板,需要如下代码:
StringTemplate template = getTemplate(“property”);
template.setAttribute(“propertyType”, “string”);
template.setAttribute(“propertyName”, “Address”);
template.setAttribute(“hiddenPropertyName”, “_address”);
String code = template.toString();
对于实际的代码生成器,参数的值将作为模板的属性,因此你可以重用上面的代码,用于生成任意数量 DSL 源码模型指定的的 C#属性。
我建议你选择的模板引擎应该不仅支持参数化数值,也应该支持条件化、可重复的表达式(集合),以及自动缩进。上面的模板实例中的语法和 API 是 ANTLR 的 StringTemplate 子项目。StringTemplate 支持非常丰富的模板功能。
很明显,即使待生成的代码非常简单,你也应该使用模板引擎。
结论
在本文中,我整体地概述了什么是 DSL,以及详细地区分了什么是内部 DSL 和外部 DSL。我还探讨了开发复杂的外部 DSL 过程中遇到的主要挑战和所用的模式。本文介绍了如何开发有价值的 DSL 的基础知识,虽然简单但很有针对性。利用恰当的工具去定义并生成分析器和元模型,能够帮你提高效率,但是没有任何工具能够代替你的思考,你要设计语言的形式文法、元模型和代码生成的方式。
如果你还没有步入开发复杂外部 DSL 的大门,我希望这篇文章能够带给你一些抛砖引玉的启迪。我期待你的反馈,并愿意与你就这个主题的细节进一步讨论。
关于作者
Vaughn Vernon 是一位拥有 26 年行业经验的独立咨询师,他是一名软件开发者、架构师和设计师。他创建并开发了很多软件开发工具,包括 DomainMETHOD,一款基于领域驱动开发模式的,支持 DSL 的领域模型快速设计与开发的工具。Vaughn 发表过大量文章和模式,并且在各种技术会议上发言。你可以在 www.shiftmethod.com 找到更多信息,或者通过 vvernon at shiftmethod dot com 直接联系他。
查看英文原文: Developing a Complex External DSL
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




