
本文最初发布于 THENEWSTACK。

消费电子巨头苹果公司发布了一个开源插件,可以帮助Apache Spark更有效地执行向量搜索,使开源数据处理平台在大规模机器学习数据处理方面变得更有吸引力。

这个基于Rust的插件名为Apache Spark DataFusion Comet。苹果工程师已经将其提交给了Apache软件基金会,使其成为Apache Arrow项目下的一个子项目。该插件是以可扩展的Apache DataFusion查询引擎(也是用Rust编写的)和Arrow列式数据格式为基础构建的。
“我们的目标是通过将 Spark 的物理计划执行委托给 DataFusion 的高度模块化执行框架来加速 Spark 查询执行,同时在 Spark 用户看来语义不变,”苹果软件工程师Chao Sun在Apache邮件列表中解释道。
Sun 指出,该项目的功能尚未全部开发完成,但部分功能已经应用于生产环境。
Apache Arrow项目管理委员会主席 Andy Grove 在X上指出:“对于最近每个人都在谈论的可组合数据系统概念,这就是一个很好的例子。利用 Spark 非常成熟的计划和调度,并将其委托给 DataFusion 进行本地执行。”
Apache Arrow DataFusion Comet 是什么?
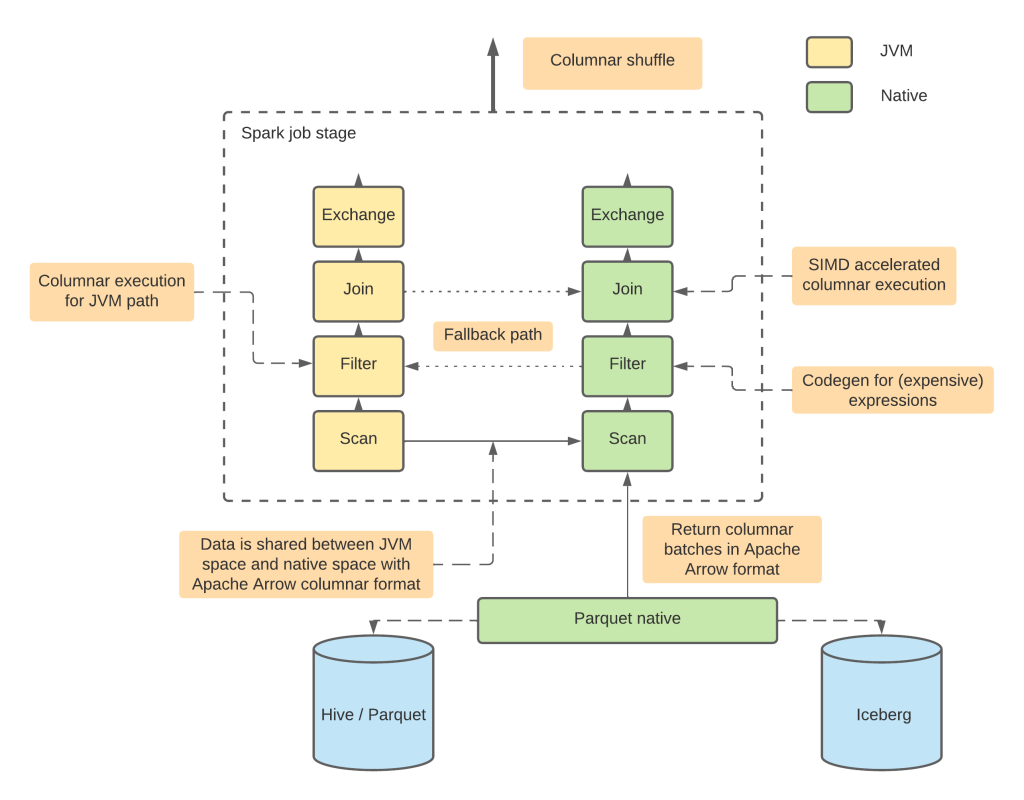
利用 Apache Arrow DataFusion 运行时,Comet 可以使用 Apache Arrow 列式格式查询数据。这种方法旨在通过本机向量化执行来改进查询效率和查询运行时。
Apache Spark创建于 2010 年,用于处理各种格式化和非格式化结构(“大数据”)中的大量分布式数据。
向量处理已经成为机器学习社区中最受欢迎的技术,因为它可以缩短分析大量数据的时间。
Fivetran 高级产品布道师Charles Wang在上个月的一篇分析文章中写道,“向量化查询可以操作批量数据并并行处理多个数据元素,改善了分析查询的性能、效率、可扩展性和内存占用。它与列式数据库架构有着千丝万缕的联系,因为它允许将整个列加载到 CPU 寄存器中进行处理。”
按照设计,Comet 的特性会与 Spark 保持对等(目前支持 Spark 3.2 到 3.4 版本)。也就是说,无论是否使用 Comet 扩展,用户都可以运行同样的查询。
Spark 内置的表达式和操作符(Filter/Project/Aggregation/Join/Exchange)可以在 Comet 中使用,Apache Parquet列式存储格式也可以,无论是读模式还是写模式。
Comet 可以在 Linux 或 Mac OS 上运行,需要 JDK 8 及以上版本和 GLIBC 2.17。
其他可加速向量处理的 Spark 插件
软件工程师 Chris Riccomini指出,苹果公司并不是FAANG俱乐部中唯一对向量处理感兴趣的成员。去年,Meta 也发布了自己的 Spark 向量处理项目:Velox。
类似的项目还包括英特尔的Gluten(最近被接收进入ASF孵化)、英伟达的GPU RAPIDS Spark加速器、Blaze(也可与Apache Arrow DataFusion搭配使用),以及Ballista分布式 SQL 查询引擎。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://thenewstack.io/apple-comet-brings-fast-vector-processing-to-apache-spark





{kind=link}
{kind=link}