
摘要:
9 月 25 日,全球权威 AI 基准测评组织 MLCommons® 公布了 MLPerf® v1.0 存储性能基准测试的结果。焱融科技在此次测试中表现出色,焱融全闪存储产品在 3D-Unet、ResNet50 和 CosmoFlow 三种 AI 深度学习模型的评估中均展现了卓越的性能和效率。
焱融科技作为中国自主研发的高性能存储领导者,与 DDN、Nutanix、Weka、Hammerspace、Solidigm 和 Micron 等众多国际优秀厂商同场竞技,测试结果显示,在带宽、模拟 GPU 数量以及 GPU 利用率等关键性能指标上,焱融科技的产品获得了多项世界第一。
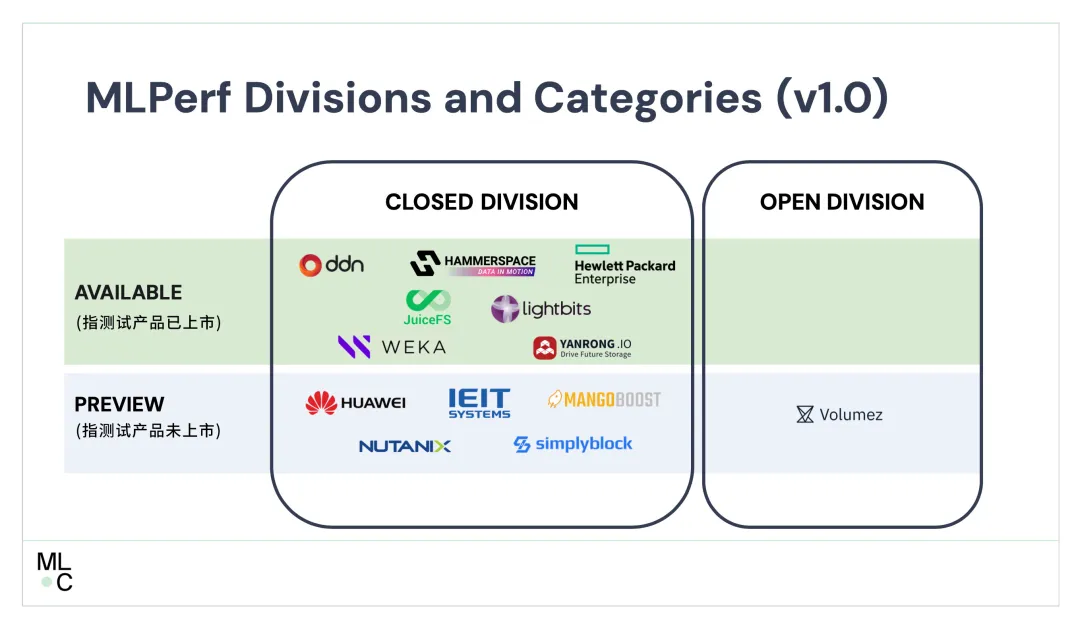
在 MLPerf® Storage v1.0 的基准测试中,焱融全闪存储显著提升了 GPU/ML 工作负载的处理速度,这表明焱融高性能存储产品具备支持各种 AI 模型训练和高性能计算场景的能力。在 AI 领域,尤其是在大规模模型训练方面,焱融全闪存存储解决方案发挥着至关重要的作用,为 AI 技术的发展和应用提供了强有力的支持。
MLPerf® Storage 全球首个且唯一的 AI/ML 存储基准测试
MLPerf 是由图灵奖得主大卫·帕特森(David Patterson)联合谷歌、斯坦福大学、哈佛大学等顶尖学术机构共同发起的国际权威 AI 性能基准测试,被誉为全球 AI 领域的“奥运会”。MLCommons 组织在 2023 年首次推出了 MLPerf 存储基准测试(MLPerf Storage Benchmark),这是首个也是目前唯一一个开源、公开透明的 AI/ML 基准测试,旨在评估存储系统在 ML/AI 工作负载中的表现。这一基准测试为 ML/AI 模型开发者选择存储解决方案提供了权威的参考依据,帮助他们评估合适的存储产品。
MLPerf Storage 基准测试目前有两个版本:v0.5 和 v1.0。2023 年发布的 v0.5 版本初步包含了 Unet-3D 和 BERT 两个模型,并仅支持模拟 NVIDIA v100 GPU。而今年最新发布的 v1.0 版本进行了重大更新,引入了更具代表性的测试模型,这些模型在业界具有广泛的应用,能够更好地代表实际工作负载。
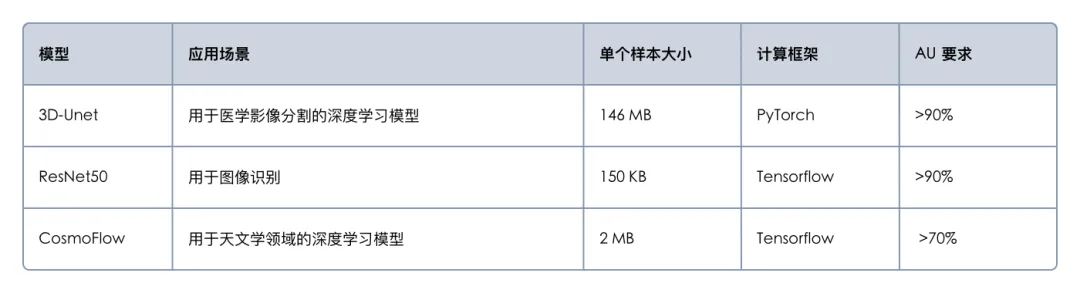
为确保测试结果的可靠性,MLPerf Storage v1.0 基准测试的规则非常严格,关键要求如下:
1. 高 GPU 利用率
在 U-Net 3D 和 ResNet-50 模型测试中,GPU 利用率需维持在 90% 以上。
CosmoFlow 模型的 GPU 利用率需达到 70% 以上。
2. 禁止缓存
在基准测试开始前,不能在主机节点上缓存训练数据。
连续测试运行之间,必须清除主机节点中的缓存以确保测试的准确性。
整体数据集的大小务必远超过主机节点的内存大小。
国内唯一全面参与所有模型测试的厂商,荣登多项世界第一
本次焱融科技参与 MLPerf 测试使用了最新发布的 F9000X 全闪分布式一体机产品。F9000X 每个存储节点搭载最新的英特尔® 至强® 第 5 代可扩展处理器,存储介质采用 10 块 Memblaze PCIE 5.0 NVMe 闪存 ,同时配备 2 块 NVIDIA ConnectX-7 400Gb NDR 网卡。测试环境网络拓扑如图所示:
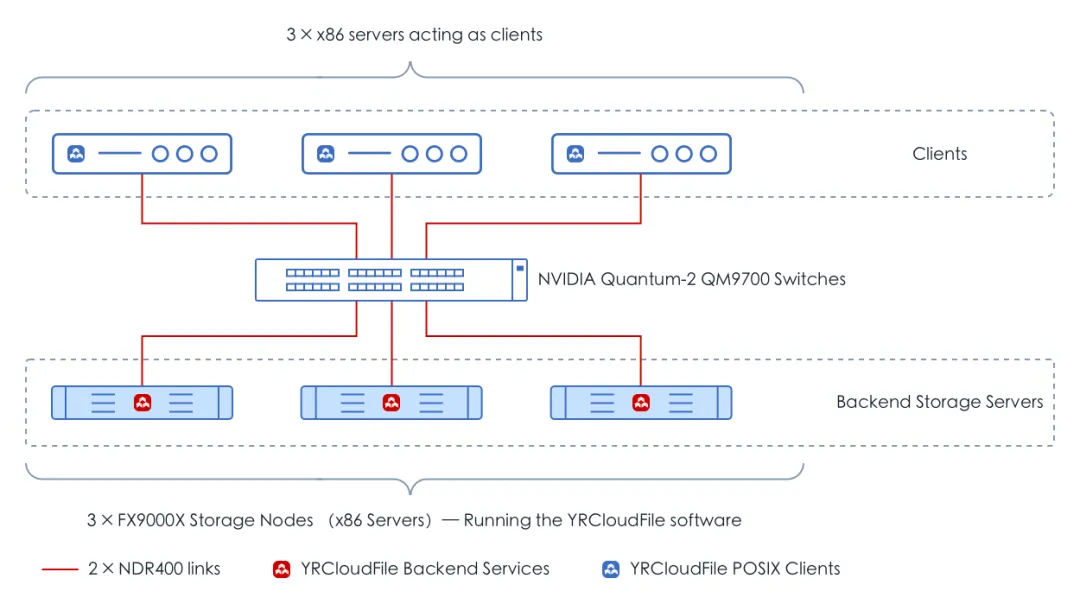
部署环境架构图
为了深入理解 MLPerf Storage 基准测试内容,我们先解释两个核心概念:
ACC:即 Accelerators(加速器),MLPerf Storage Benchmark 测试工具通过 accelerator emulation,来模拟真实的 GPU,如:NVIDIA A100、H100 等。在无需真实 GPU 的情况下就能进行大规模的存储性能压测,用以评估存储系统在 AI 模型训练场景的适用性。
说明:在 MLPerf Storage Benchmark v1.0 版本中 ACC 可以模拟 NVIDIA A100 和 H100 两款 GPU 型号。本次 MLperf 测试焱融提交了基于 H100 的测试数据。
AU:Accelerator Utilization(AU,加速器利用率)在 MLPerf Storage Benchmark 中,通常被定义为 GPU 计算时间占整个基准测试运行时间的百分比。这是一个衡量加速器在给定任务中的有效利用程度的关键指标,GPU 计算时间占比越高,代表存储速度越快,GPU 越能被充分利用。AU 太低,说明存储性能不足以支撑 GPU 高效运行,只有 AU 高于指定值时,提交的数据才是有效数据。
焱融在 MLPerf Storage v1.0 的测试表现
最全面最完整,国内唯一一家参加了全部模型测试的存储厂商
焱融科技是国内唯一一家参与了 MLPerf Storage 全部模型测试的存储厂商,这些测试包括 3D-Unet、CosmoFlow 和 ResNet 50。在本次测试环节,焱融追光全闪存储一体机 F9000X 展现了卓越的性能,全面覆盖目前主流模型应用数据负载需求。F9000X 不仅能够处理大规模的数据集,还可以根据 AI 集群规模弹性扩展,完美匹配 GPU 算力性能。
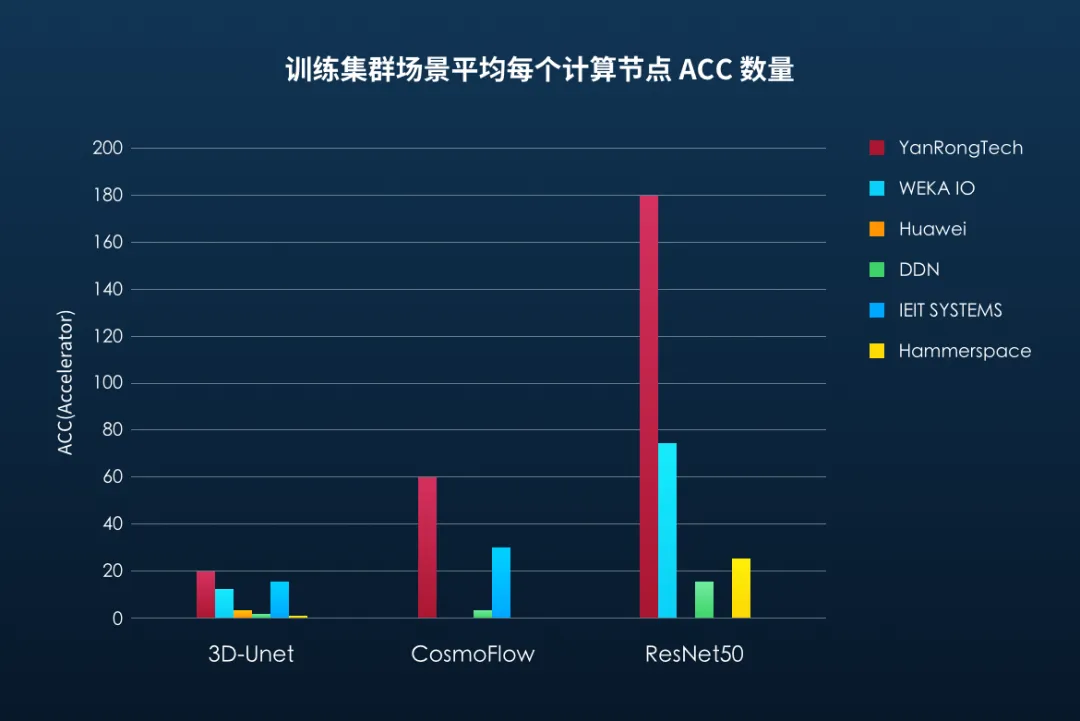
在分布式训练集群场景,平均每个计算节点 ACC 数量最多,存储带宽最高
MLPerf Storage 基准测试规则定义可以采用单个计算节点(客户端)运行多个 ACC(GPU 加速器),进行相应模型应用测试,同时支持大规模分布式训练集群场景,多个客户端模拟真实数据并行的方式并发访问存储集群。其中平均每个客户端能够运行的 ACC 数量越多,则代表该节点的计算能力越强,能够处理任务的数量也就越多,而对于存储数据并发访问性能要求也就越高。测试结果显示,在分布式训练集群场景,焱融存储在所有三个模型的测试中,能够支撑的每个计算节点平均 ACC 数量和存储带宽性能均排名第一。
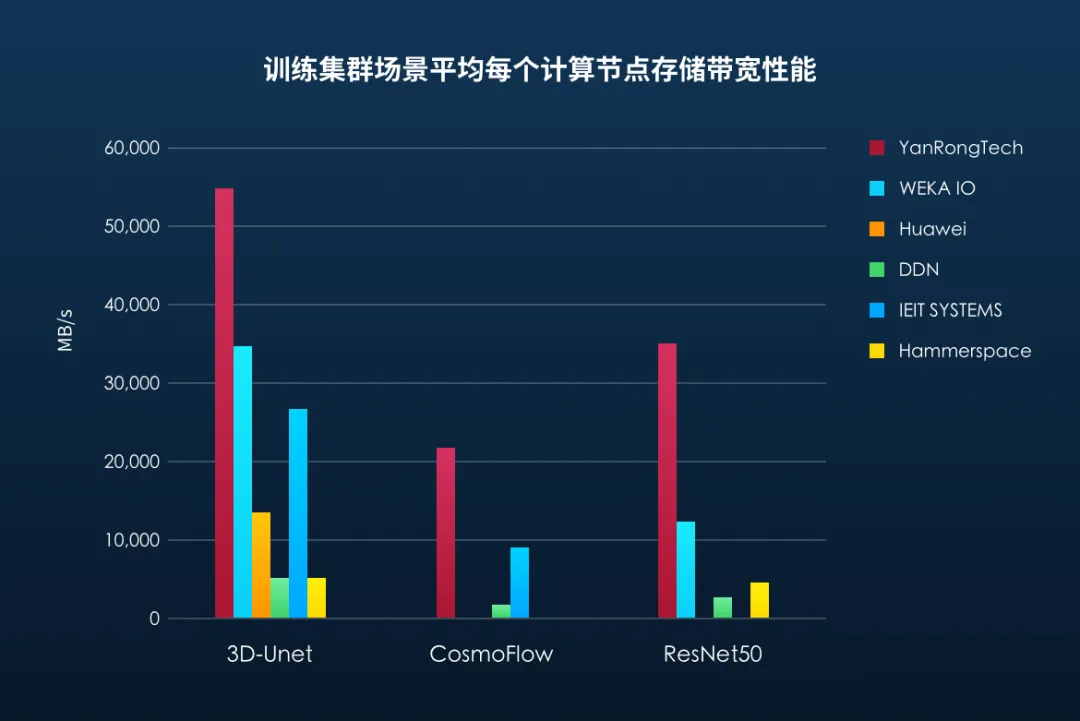
存储性能随计算规模同步线性增长
随着计算规模的扩大,存储性能应实现线性增长以满足 AI 训练的需求。以 3D-Unet 三维图像分割模型为例,其单个图像样本大小约为 146MB,而在多节点集群环境中,每秒处理的训练样本数可超过 1100 个,这导致训练数据的读取带宽需求超过 160GB/s。
在针对三个模型的测试中,焱融全闪存储一体机 F9000X 展现了出色的性能。测试结果显示:随着并发计算节点(ACC)数量的增加,存储系统的带宽性能保持明显的线性增长能力。此外,存储的可用性(AU)也始终保持在测试基准要求的范围内,确保了训练过程的高效和稳定。
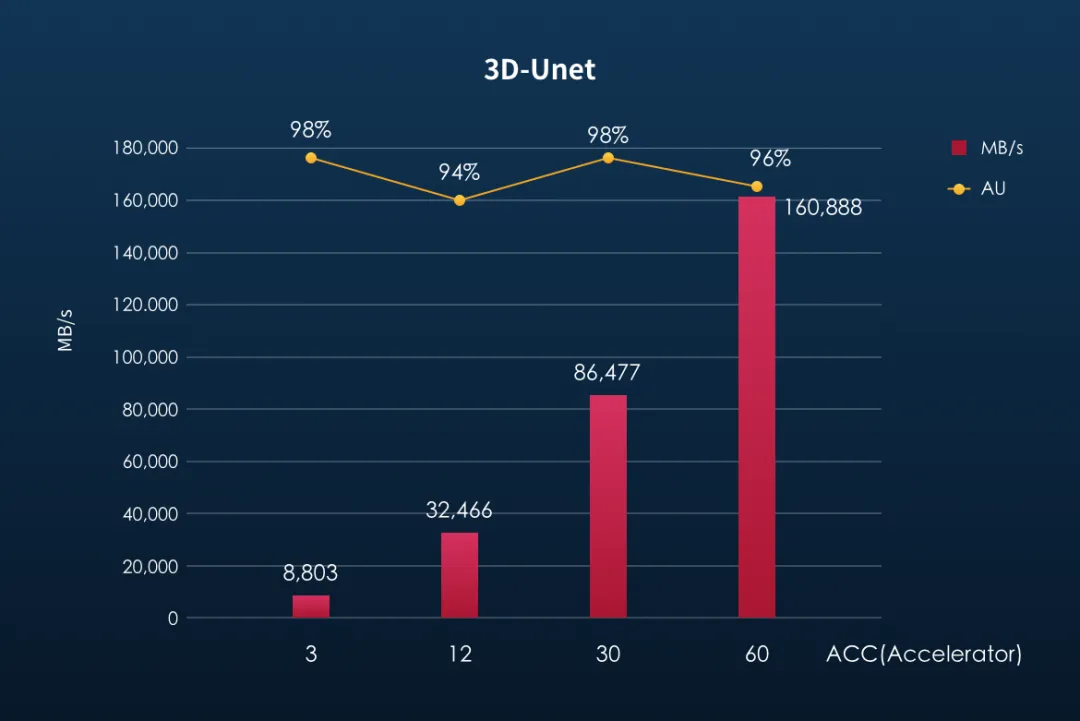
目前在 3D-Unet 模型应用的测试中,使用 3 个计算节点,共 60 个 ACC,可达到 160GB/s 的存储带宽性能。F9000X 3 节点存储集群实测最大可以达到 260GB/s 以上的带宽性能,这表明在实际业务环境中焱融全闪存可以支撑更多的 GPU 的计算节点。
以下是焱融全闪存储在 ResNet50、CosmoFlow 这两款模型测试的存储的可用性(AU)及带宽性能表现:
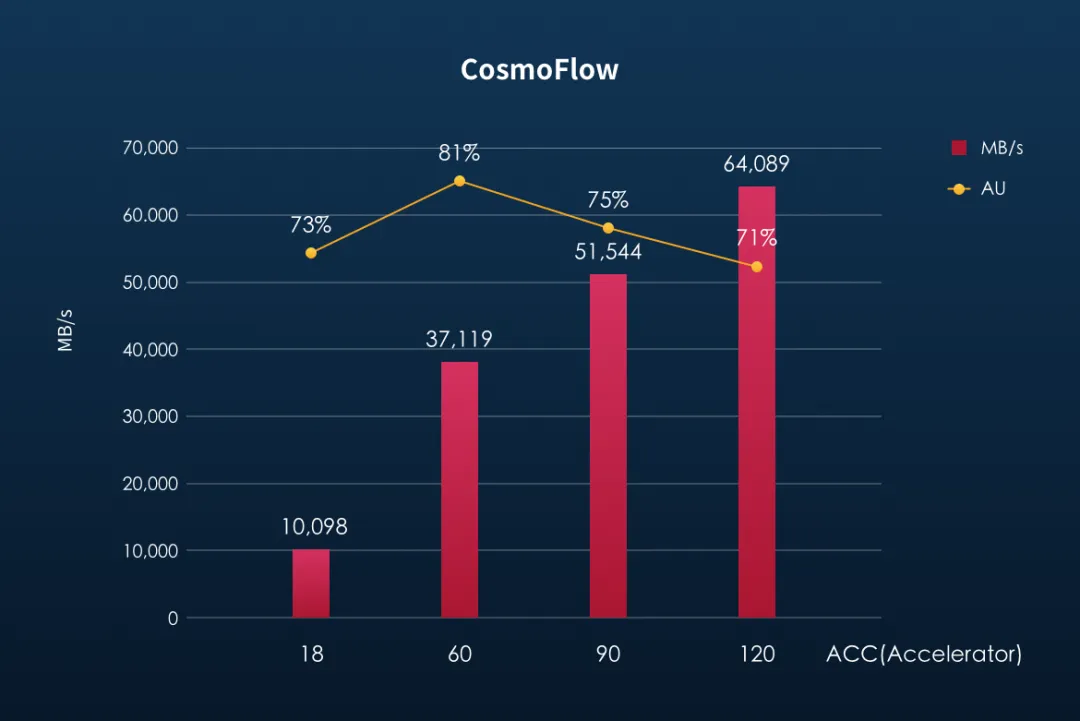
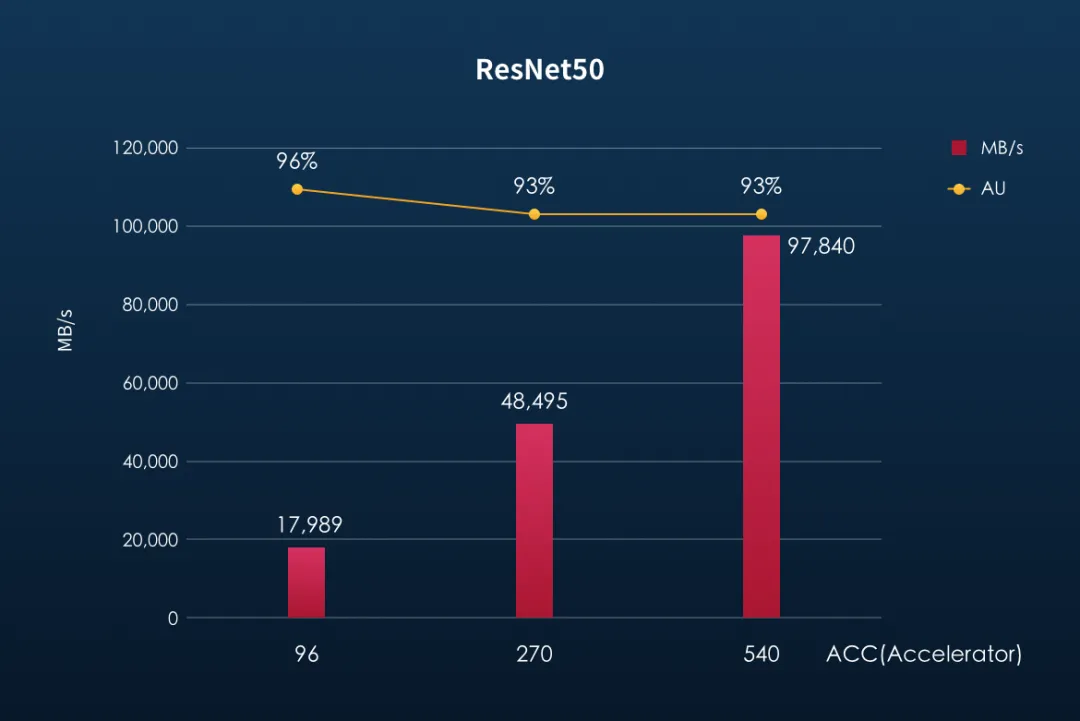
小结:
在进行 MLPerf Storage 基准测试时,我们发现为了满足 AI 计算存储的性能需求,存储系统需要具备以下关键特性:
高性能设备支持:MLPerf Storage 需要高带宽,因此存储系统必须支持如 200Gb 和 400Gb InfiniBand 或以太网等高性能网络设备。
MultiChannel 网络带宽聚合:YRCloudFile 支持在 InfiniBand 或 RoCE 网络上使用 MultiChannel 功能,以充分利用双卡的性能,实现数据读写的高效性。
🔗 更多了解,详情请见《90GBps 性能顶流!焱融科技发布最新 AI 大模型存储方案》
全链路 direct I/O:为了避免内存缓存导致的性能瓶颈,YRCloudFile 支持在计算节点上部署 kernel client,允许数据读写直接绕过内存缓存,通过 direct I/O 方式访问后端存储。
🔗 更多了解,详情请见《CPU 使用率飙升,Buffer IO 引发的性能问题》)
NUMA 优化:内存性能对存储性能至关重要。YRCloudFile 支持全链路 NUMA 优化,确保服务进程与 NVMe SSD 绑定到同一 NUMA 节点,优化数据传输路径。
🔗 更多了解,详情请见《YRCloudFile V6.8.0 发布:向全闪时代迈进》
焱融分布式文件存储 YRCloudFile 通过上述技术亮点,能够在本次 MLPerf Storage 测试中接近硬件性能极限,为 AI 计算提供所需的高性能存储解决方案。在实际测试中,YRCloudFile 已经展现出能够支持大规模 AI 训练任务的能力,即使在极端条件下也能保持系统的稳定性和性能。
引用链接:
[1] MLPerf Storage Benchmark Suite Results: https://mlcommons.org/benchmarks/storage/
[2] MLPerf Storage rules:
https://github.com/mlcommons/storage/blob/main/Submission_guidelines.md




