

6 月 21 日,由北京智源人工智能研究院主办的 2020 北京智源大会正式开幕(直播入口:https://2020.baai.ac.cn),大会为期四天,各主题论坛和分论坛将围绕如何构建多学科开放协同的创新体系、如何推进人工智能与经济社会发展深度融合、如何建立人工智能安全可控的治理体系、如何与各国携手开展重大共性挑战的研究与合作等一系列当下最受关注的问题进行交流和探讨。会上,卡内基梅隆大学教授 Ruslan Salakhutdinov 进行了主题为“Integrating Domain Knowledge into Deep Learning”的演讲,以下为 InfoQ 带来的内容整理。
首先,Ruslan Salakhutdinov 展示了近期所做的一系列研究,主要围绕深度学习带来的影响而展开,涉及的领域包括语音识别、计算机视觉、推荐系统、语言理解、药物发现 &医疗影像分析。

Ruslan 教授表示,当人们构建 AI 时通常倾向于从算法着手,因为开发计算机算法可以让计算机看到并感知人类身边的事物。如今,我们在机器学习和深度学习领域所面临的主要挑战有四方面,这四种挑战之间又是相互联系的,包括自然语言理解;具象化人工智能,深度强化学习和控制;如何将结构化的领域知识结合到模型中;多模型,半监督、自监督学习。

在进行监督学习训练时,我们将输入通过一些神经网络训练,最后产生输出内容。例如,当我们问到哪些冠状病毒会感染人群时,我们把从文本、表格或知识本体中得到的领域知识输入到模型中,然后就可能得到 MERS-CoV、SARS-CoV 或 Covid-19 这样的答案,因此领域知识对于模型十分重要。
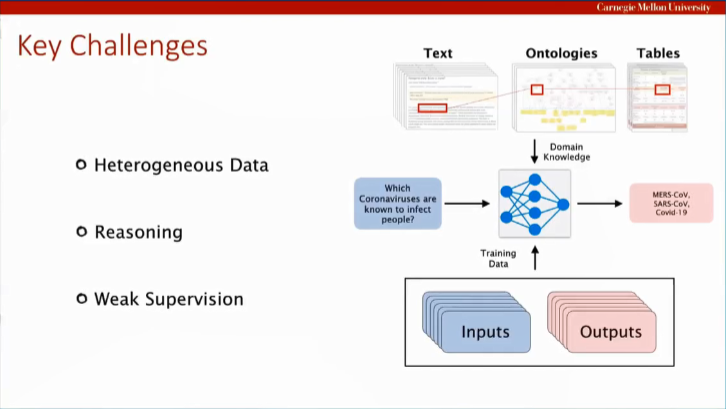
同样地,我们可考虑构建一个知识库,目前很多公司已经构建了这样的知识库,这里蕴含了相关的领域知识,例如糖尿病可能引起病痛性神经病变,可以通过服用一些药物进行治疗,我们可以人工地建立一种内含各种关联的知识库,然后将这个知识库作为知识的来源,再把这些领域知识结合到模型中,最终得出答案,这个过程能够有效地将深度学习和知识库相结合。
但是,很多时候知识库并不是完整的,我们还需要从网络、文本和图谱中获得一些补充信息,而将这些信息结合在一起再进行训练可以很大程度上提高系统的性能。
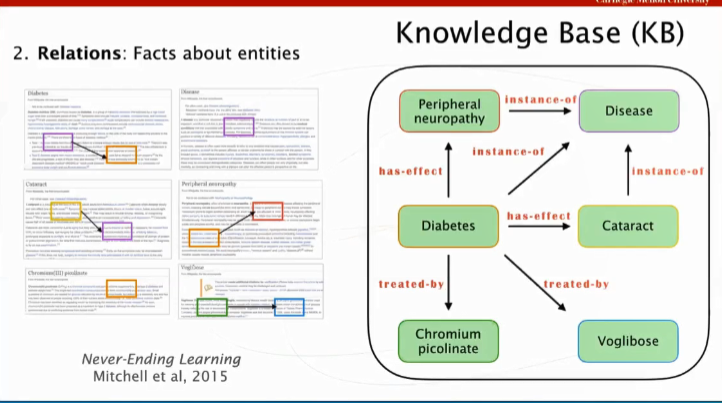
另一个需要思考的问题是,当我们处理复杂的、多种情况并存的问题时,应该怎么办?仅使用深度学习模型和递归神经网络来解决这类问题是相当困难的。Ruslan 教授举了如下例子:
当问到“生产伏格列波糖片的公司总部在哪里”时,我们需要回答两个问题,首先是哪个公司生产伏格列波糖,一旦我们知道了这个问题的答案后,就可以问这家公司的总部在哪里。所以在这个案例中,当我们回答这家公司的总部在哪里时,首先要知道伏格列波糖片是武田药物公司的产品,该公司是日本最大的制药公司,然后就可以知道这家公司的总部位于日本大阪。这也就是我们提到的复杂的、多种情况并存的问题,当我们无法立即知道答案时,就需要将未知信息与从维基百科等不同渠道获取的信息相结合,才能最终回答出这个问题。
如今,面对这种复杂的问题,很多系统是回答不上来的,因为系统无法理解这种复杂的问题,甚至再遇到一个复杂的问题里面包含了 3 个提问时,回答问题的步骤和顺序又是怎样的,Ruslan 教授对此问题进行了讲解。
他认为,回答这种复杂问题,要首先注意回答问题的顺序,也就是优先级。但是优先问题不好归纳,而且归纳起来也会很慢,所以我们在思考能否利用深度学习模型来解决这一问题,将模型反向传播到架构上,以及我们能否更有效地实时回答这类问题。这时候利用领域知识来解决问题就是个非常理想的方式。他表示他的一名学生创立了这样一个可以实时回答复杂问题的系统,接下来,Ruslan 教授举了一个例子来进一步解释这个系统。
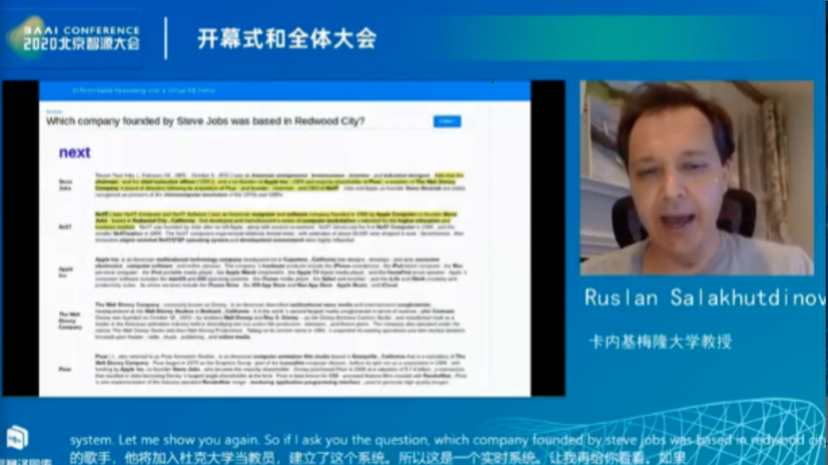
当我们问及,Steve Jobs 创办的公司哪家总部位于 Redwood City 时,这个模型就会实时地运行,它就是一台 CPU,能搜索出 500 万篇关于 Steve Jobs 创办的公司哪家总部位于 Redwood City 的文章,第一阶段需要检索出 Steve Jobs 创办了多少家公司,结果显示他创办了苹果和 next,但只有 next 才是正确答案,接下来模型就会给你一些信息,比如 next 公司的总部在哪,哪家公司总部位于 Redwood 市,你就可以实时地检索到这两条信息,然后将两条信息结合起来,可以得到正确的答案。
Ruslan 教授也对该系统如何做到这一点进行了解释。系统中非常关键的点是要做到一些能产生跟随关系的事情,我们给定一组实体,通常是一组特定的名词 X,然后找出其跟随关联 R,然后我们得到了一个答案,我们跟随另一个关联关系,得到了第二个答案,以此类推得到了一系列实体 Y,这里的 X 可以表示一种药品名称,而这里的跟随关联可能是生产商,基于这个就可以知道哪家公司生产了这种药品。

跟随关系可以给出一系列问题的答案,帮我们决定最终的正确答案是什么,这是非常理想地利用分析算法和利用归类法解决复杂问题的一种方式。
利用相关跟随关系方法能让我们根据一个实体建立起一个矩阵,这种方法的好处是可以双倍利用跟随关系创建很多矩阵,也就是相当于创建出了一个极为复杂的矩阵。之所以认为这种方式是高效的,是因为它可以在无需人工干预的情况下自动创建知识库。

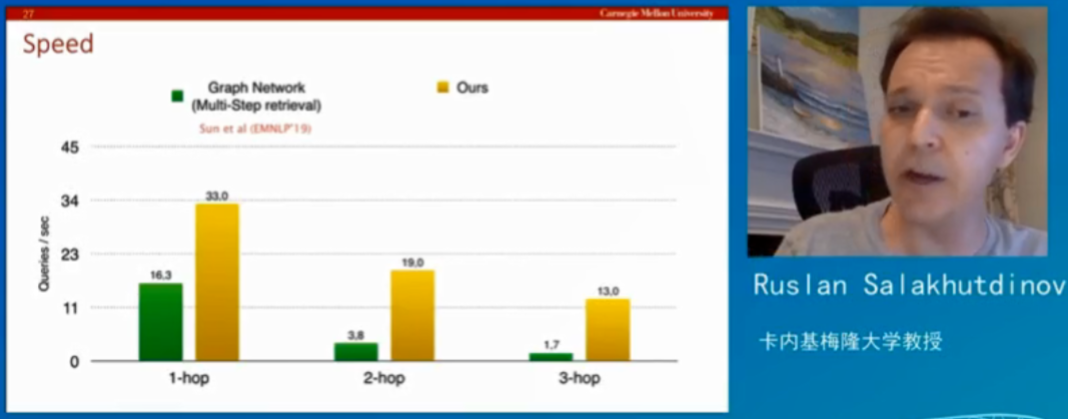
最后,Ruslan 教授展示了通过该方法回答复杂问题最后得到的结果,结果表明,通过这种模式比传统的现有模型效果要好很多,而回答阶段性问题的速度也要比图神经网络快很多。
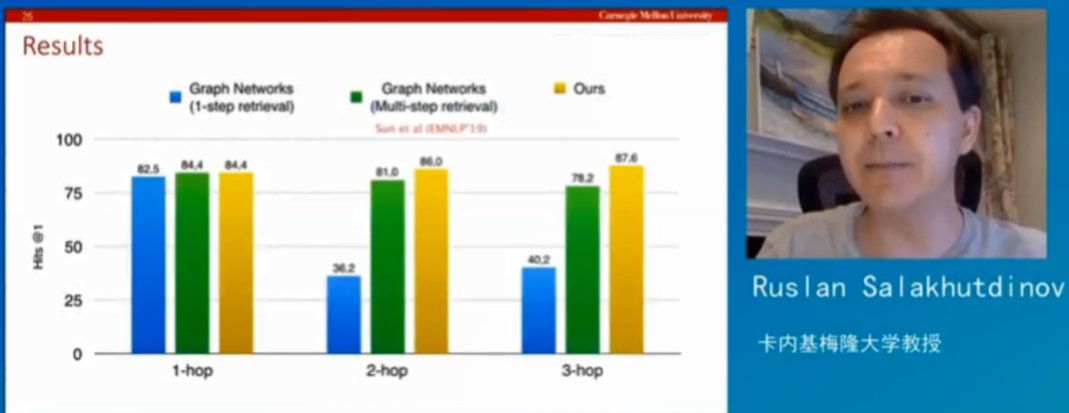
该模型在回答第一阶段问题时能在每秒钟处理 19 个问题,而在回答第三阶段每秒能处理 12-13 个问题。
更多智源大会相关演讲内容欢迎访问:
https://www.infoq.cn/event/?id=138

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论