
作为一名高级工程师,最近我和我的团队经历了我职业生涯中最严重的一次事故。在 2023 年旧金山 QCon 大会的演讲中,我分享了这次故事。一个基础设施变更引入的自动化意外删除了关键客户数据。我们花了三天时间才完全解决故障并恢复数据。
回顾过去,有许多方面我们本可以做得更好——从防止最初的事故到改进我们的响应流程。我也看到了高级工程师在事故过程的各个阶段都有机会推动积极的变化。
事故简况
在发生事故的公司,基础设施是通过 Terraform 来管理的。平台团队(我的团队)评审并通过了 Terraform 的变更 PR,但这些变更是由产品团队提交的。当时,我们没有集中的系统来应用 Terraform 变更,这导致了基础设施变更的透明度较低,不清楚谁在什么时候做出了什么样的变更。这次事故是由一小段 Terraform 代码变更引起的,它判断自动化在 24 小时后过期并将数据对象标记为软删除。如果我们没有及时发现并解决问题,那么在下一个 24 小时后将永久删除这些关键的客户数据对象。
过了一天,我们的监控系统才开始向我们发出问题警报。在最初的问题诊断阶段,我们止住了损失并防止数据丢失,但不慎引发了第二次事故。不幸的是,这次事故被我们的客户率先发现。到了这个时候,许多处理事故的人已经感到疲倦或心烦意乱,而且试图解决问题的多个团队之间没有很好的协调。
花了三天时间,我们的高级和技术员工程师才修复了问题,几乎涉及了平台的每个部分。这是一系列问题和失误的汇合,就是这些问题和失误的汇合让这个变更成为漏网之鱼。
影响因素
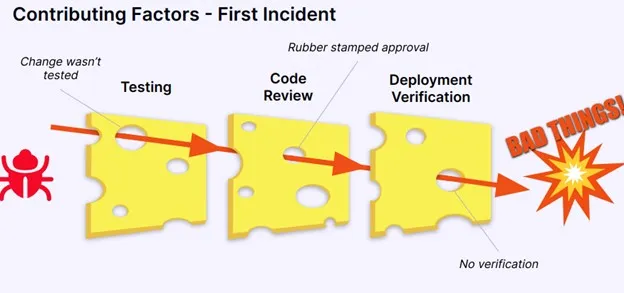
瑞士奶酪模型是一种在风险分析或根本原因分析中经常用到的隐喻,说明使用多层次系统方法来保证安全性的必要性。我第一次了解到这个模型是在肯尼迪航天中心参与航天飞机项目时,在那里,安全性是重中之重。如果将这个模型应用于软件事故,那么每一片奶酪都代表我们对事故的一层防御。
在最初的事故中,虽然我们设置了多层防御来保护自己免受事故的影响,但所有的漏洞都神奇般对齐了,让这个问题成为漏网之鱼:
测试——没有在预生产环境中测试变更,验证是否按照预期的行为运行。
代码评审——代码评审批准了变更,但没有任何问题或讨论。
部署验证——在部署到生产环境后,没有验证变更是否按照预期行运行。
让防御性增强形成文化
我们已经拥有一个充满支持性和包容性的文化。然而,没有哪种环境是完美的,甚至是一成不变的。即使是一个很好的文化仍然可能存在盲点,我们也是如此。在一个企业里,不断关注和培育文化是非常重要的。没有完美的文化,文化也不存在终点。作为技术领导者,你可以成为关注和培育文化的倡导者。
回顾这次事故,加强支持性文化可能会为我们的防御提供更多的保护。作为技术领导者,我可以树立积极的行为榜样——提升工作的透明度,承认知识上的不足,不断收集信息,并质疑假设。我也可以指导队友这么做。改进安全网可以让工程师们更出色地完成工作。
测试与文化
变更提交者应该知道测试的重要性。在后来的讨论中,我了解到他们不知道如何为这个变更制定适当的测试计划。深入挖掘后,我们发现他并不熟悉做出变更的领域。我们可以问,如果他不熟悉并且不知道如何测试,为什么不寻求帮助呢?问题是,我们没有问他为什么没有寻求帮助,只能推测他可能不愿意向任何人寻求帮助。
如果不知道他们为什么会有这种感觉,深入探究造成这种不适的因素可能具有挑战性。这是组织文化中需要持续关注和培育的重要方面。高级工程师在这方面具有很大的影响力。花点时间问问自己:“应该如何让他们更愿意寻求帮助?”然后跟进这些变化,这是非常值得的。我们可以推测,如果变更提交者知道他们应该测试他们所做的变更,并且愿意寻求帮助,可能就能够避免这次事故。
代码评审与文化
只要求进行代码评审是不够的。评审人员可能不会提出问题或关注点,即使他们不完全理解这些变更。我承认我也是这样的评审人员,我也不会提出问题,也不去进行调查,即使我知道这个变更属于我们平台的一个关键部分。我很关心代码,但不愿意向我的新团队承认我不理解潜在的影响。如果我提出问题,如果我有勇气袒露出自己的脆弱,并公开表示我不知道某些事情,也许能够帮我们避免这次的事故。
要解决人们不敢提问或承认自己不了解某些事情的问题并不容易。这是一个人类心理问题。即使你可以创造最具支持性、包容性的环境,人们有时仍然可能感到不舒适或不安全。作为领导者,我们应该始终努力改善环境,尽可能地包容每个人。
部署验证与文化
对于部署验证防御层,我们可以问变更提交者为什么在部署后没有验证他们的变更。虽然在事后分析中我们没有专门讨论这个问题,但我可以猜测可能是因为对如何验证这个问题并没有明确的期望。这一点,再加上变更提交者不了解如何验证他们的变更,很可能导致根本没有进行部署验证。这是另一个可以改善我们的文化来加强防御的地方。
我们可以将开发和测试的最佳实践融入到文化中,并清晰地定义开发人员或变更提交者完成任务需要完成哪些职责。高级工程师可以在培育这样的文化方面发挥重要作用。他们可以做出榜样,监督和指导队友遵循这些最佳实践。
有效的事故响应
一旦事故发生,随之而来的压力和迅速恢复服务的紧迫性意味着响应者的行为是被动的,协调不足。我们缺少权威的事故指挥官来维持大局。糟糕的交接导致在碎片化的工作流中做着重复的工作。疲劳导致了覆盖范围的空白。有些人去休息了,但没有明确说明什么时候会重新上线。
事故指挥官角色
高级工程师具备担任事故指挥官的能力。保持冷静,建立结构,推动定期的进度更新,并适时升级事故,让参与修复问题的人可以集中精力。
我们并不总是有一个明确指定的人来担任事故指挥官。如果有,那个人也会深入到诊断、故障排除和修复问题中。他们过于专注于自己的工作,导致他们很难充分地看到大局,管理更新,并与利益相关者沟通,或在必要时寻求适当的帮助。
我们也没有人协调时间表、期望或可交付成果。人们只是自愿或不自愿地承担某些事情,随时进入和退出,没有明确的工作交接或计划时间表。
高级工程师是担任事故指挥官角色的理想人选,他们甚至不需要加入到受影响的团队,事实上,如果不这样做可能会更好。
在面对突发事故时,需要有人能够保持头脑清醒,看清大局。事故指挥官可以从那些忙于工作的人那里收集状态,并与利益相关者进行沟通,让实际做事的人专注于他们的工作。他们可以做协调工作和消除障碍。他们可以确保清晰的沟通和期望,指明谁在做什么、他们的时间表和计划是什么。如果需要交接,事故指挥官也可以确保交接顺利进行。
事故指挥官也可以为自己考虑一下,如果你是事故指挥官,需要休息,或者随着情况的变化不再适合这个角色,你可以要求其他人接替你。任何人都不应该因为认为自己会被困在指挥岗位上而犹豫要不要去承担这个角色。整个事故过程中的任何一个角色和责任都应该能够根据情况的变化而变化。当事情发生变化时,我们只需要明确地做出说明。
所有这些都是高级工程师应该具备的技能和能力。一个高效的事故指挥官确实可以决定事故响应的成败。
通过事后总结推动持续改进
在解决问题之后,一个无责备的事后分析可以发掘出有价值的见解。它确实对我们有所帮助。但是,如果没有后续的行动项,这些价值就会退化。这又是一个提供务实领导的机会——在不做评判的情况下促进强有力的对话,并在彻底分析根本原因的基础上制定解决方案。
我们使用了一个自动化事故管理工具,有一个自动生成事后总结文档的模板,还有了关于进行事后总结讨论会议的指南和格式。我们甚至在每次事后总结讨论会议开始时都会阅读回顾原则,提醒每个人我们的无责备风格:
“我们的事故处理过程是无责备的,我们不寻找或归咎责任,甚至不会将原因归咎于个人。无论我们发现了什么,我们都理解并真诚地相信每个人在当时的情况、他们的技能和能力、可用资源以及所处的情况下都已尽力而为。”

最近,我们注意到主持这些总结会议的人只是阅读模板和走过场。他们只是确保他们召开了总结会议并写了事后总结文档,但质量很低。在根本原因分析或回顾事故管理流程方面几乎没有付出什么努力。他们很少有行动项,而那些已确定的行动项经常被遗忘或没有坚持到底。
这就是培育文化可以带来改变的一个例子。增加流程并不会帮助我们进行更有效的事后总结——我们已经有了很多流程。人们在这些会议上只是走过场,并不是因为他们懒惰,而更可能是因为这些工程师对于管理和促进反思相对生疏,不知道如何推动这些对话。真正的差异在于环境和文化。
作为工程文化的引导者,高级工程师应该抓住事故提供的关键的成长机会。我们应该持续改进,在加强安全、信任和弹性的基础上取得进步。即使你不是会议的组织者,也可以问一些试探性的问题。你可以表现出好奇心而不加评判。你可以进行模式化和指导根本原因分析。你可以帮助一起确定务实的行动项解决方案。
即使你没有直接参与事故处理,作为高级工程师,你也应该参加事后总结讨论会并阅读文档,这样你就可以影响整个过程,帮助提高产出的质量。事故是总结教训和找到改进空间的关键机会,高级工程师的参与有助于实现这一目标。
根本原因分析
在事后总结讨论中,进行彻底的根本原因分析是至关重要的。这有助于确定可以防止将来发生类似事故的措施。然而,在进行根本原因分析时,我们不应该只停留在第一个起因上。我们需要回顾每一个起因,并不断问为什么,直到没有更多的起因为止。当你在进行这种程度的分析时,常常会发现,环境或文化的某些因素导致了我们的防御层出现了相应的漏洞。作为技术领导者,你有绝佳的机去发现可能导致事故的文化差异,并确定解决这些问题的方法。改善工程师的文化是理想的做法,而不是增加更多可能影响生产力的流程。
结论
你无法只是通过改善工程文化来阻止所有的事故发生,但可以减少事故数量,并显著缩短解决这些事故所需的时间。你可以塑造、培育和鼓励一种学习型文化,在这种文化中,问题和脆弱性都是可被接受的。你可以担任事故指挥官,并有许多机会来改进事故响应。当事故发生时,你可以帮忙高效地解决问题。你可以提高事后总结过程的质量。你可以按照最适合改进你的环境并防止未来类似事故发生的方式来推动确定行动项。
原文链接:
https://www.infoq.com/articles/staff-engineers-impact-incidents/




