

1. 概述
机器翻译旨在利用计算机实现自然语言之间的自动翻译,一直是自然语言处理与人工智能领域的重要研究方向。随着深度学习的到来,机器更是取得了突破性进展,已成为大众较为熟知和常用的技术。近几年,从 RNN 到 Transformer 的演进,不仅全面提升了翻译性能,也为并行加速训练提供了可能性。但是传统的 Transformer 架构在解码时仍是逐词产生译文,即每一步译文单词的生成都依赖之前的翻译结果(如图 1 左所示),随着 Transformer 模型规模的增加,使得解码的时间开销非常大。为了打破解码速度的瓶颈,非自回归神经机器翻译系统(NAT)于 2018 年被提出[1]。其摆脱了自回归分解的约束,并行地生成所有目标词(如图 1 右所示)。这使得解码速度得到了极大提升,从 NAT 快速解码得到的收益可以允许在工业界的特定延迟和预算下部署更大更深的 Transformer 模型。
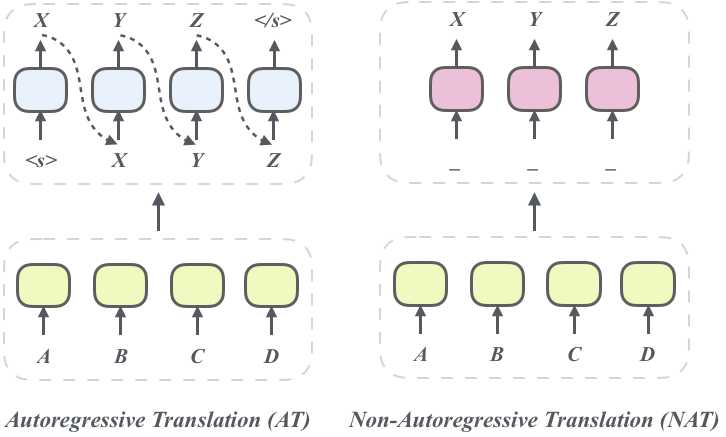
图 1. 自回归翻译(AT)和非自回归翻译(NAT)对比
但是,生成中的多模性(Multimodality)对 NAT 提出了根本的挑战。我们都知道语言是高度多模态的(multimodal),例如日语句子彼は日本語が上手です可以翻译成两个等价的英文句子 he is very good at Japanese 和 he speaks Japanese very well 。但是,看起很像的两个句子:he speaks very good at Japanese 或 he is very good at very well 则没有任何意义。但是在条件独立的解码中很难避免后者的出现,这导致 NAT 的性能显著弱于 AT 模型。因此,我们通常引入自回归模型(AT)作为教师,借助序列级知识蒸馏(Knowledge Distillation, KD)[2] 来降低原始数据的复杂度,使得 NAT 更容易学习到确定性的翻译知识,最终得到与 AT 可比较的翻译质量。因此,KD 也成为 NAT 训练的常用技术。
围绕提升 NAT 的翻译质量,前人从模型结构、训练目标等方面进行了广泛探索。而腾讯 AI Lab 近期发表一篇工作则另辟新径,从数据角度发现了知识蒸馏对 NAT 训练的副作用:词汇选择问题。为了缓解该问题,其提出将原始数据暴露给 NAT 模型,以恢复蒸馏数据中被遗漏的低频信息。实验结果表明,该方法在多种语言对和模型结构上能够有效地、通用地提升翻译质量。大量分析证实该方法通过减少低频词的词汇选择错误来提高整体性能。令人鼓舞的是,该方法在 WMT14 英德和 WMT16 罗英数据集上将 SOTA NAT 效果分别提高到 27.8 和 33.8 BLEU 值。本论文已被 ICLR 2021 接收[3]。以下为分析方法和解决方案的详细解读。
2. 方案详解
首先,本文通过定性和定量的分析,发现了 KD 的副作用:使原始数据的分布更加不平衡,从而带来了严重的词汇选择错误(特别是在低频率的词汇上)。这种低频词的错误会通过知识蒸馏传递到 NAT 模型中。如表 1 所示,训练数据中仅出现 3 次的“纽马基特”,在原始语料中均被翻译为“Newmarket”。但是,在蒸馏后分别被错译成了人名“Newmargot”(Margot Robbie 是澳洲女演员)、机构名“Newmarquette”(Marquette 是威斯康星的一所大学)甚至错译成无意义的“Newmarquite”。

表 1. 训练样本中包含“纽马基特”的所有样本,“SRC”表示源端中文句子,“RAW-TGT”和“KD-TGT”分别表示原始目标端和蒸馏后的目标端
为了更好地理解 KD 带来了什么样的变化,本文同时考虑了两种不同效果的教师模型 KD (Base) 和 KD (Big),将语料分解为高中低三种词频,并且从两个角度重新审视了他们:训练数据(图 2)和解码后的译文(图 3)。本文首先可视化了训练数据中的词频密度,如图 2 所示,其发现 KD 数据的词频密度分布的峰度显著高于原始数据,而且这种现象随着采用更强的教师 KD (Big)而更加显著。KD 的副作用也很明显,即原始数据中的高/低频词汇会变得更加高频/低频。为了更好的理解 KD 对不同词频的影响,其在图 3 中列出了不同词频的翻译精度(Accuracy of Lexical Choice, AoLC)。发现采用更好的教师模型,中、高词频的翻译精度会显著提升,因此整体上提升了翻译的表现,但是这严重破坏低频词的翻译精度。
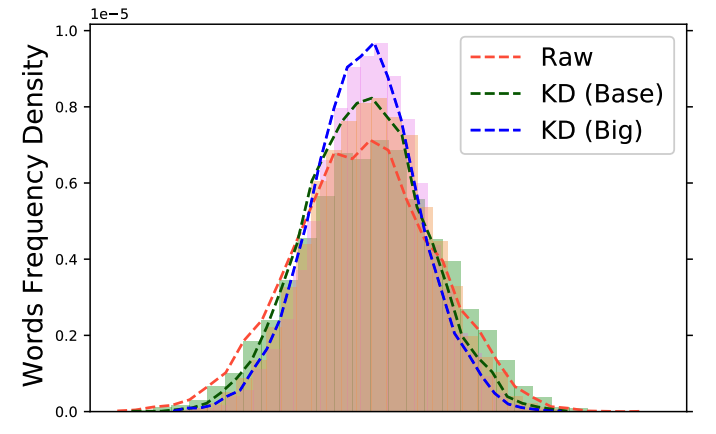
图 2. 原始数据、两种教师模型蒸馏后的数据的词频密度对比
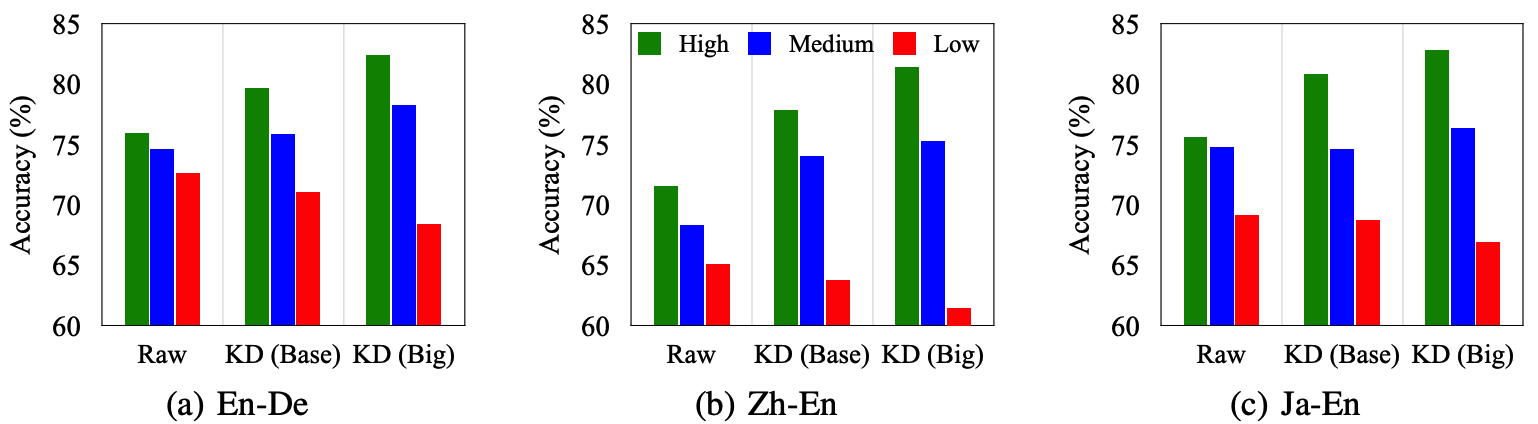
图 3. 不同数据集上采用不同教师模型进行蒸馏对不同词频的翻译精度对比
基于上述有趣的发现,本文提出将原始数据暴露给 NAT 模型,以恢复蒸馏数据中被遗漏的低频信息。为此,作者引入了一个额外的 KL 散度项来约束 NAT 模型和原始数据中的词汇选择。实验结果表明,该方法在多种语言对和模型结构上能够有效地、通用地提升翻译质量。大量分析证实该方法通过减少低频词的词汇选择错误来提高整体性能。
本文的目标是增强 NAT 模型,让其从原始数据中可以学到所需要的词汇选择(尤其低频词),以此获得更好的性能。如图 4 左所示,目前的 NAT 训练 pipeline 为先使用 AT 模型对原始数据进行蒸馏,然后 NAT 只学习蒸馏后的数据。我们的方案(图 4 右)不仅利用蒸馏后的数据,同时也考虑从原始数据中学习必要的知识(如低频词)。
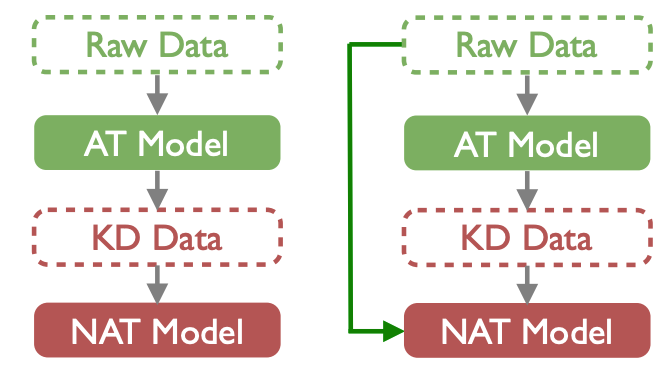
图 4. 左为目前 NAT 训练方案:经过 AT 模型对数据蒸馏;右为暴漏原始数据到 NAT 的策略
为此,作者在目前 NAT 的训练目标上引入了一个额外的双语数据相关的先验约束。这个先验约束采用 KL 散度来引导 NAT 模型的预测去匹配从原始数据中提取的双语先验分布。随着训练的进行,这种先验约束的影响会对数级衰减,在训练的后半程模型只学习蒸馏过的数据。具体地讲,我们从原始数据中抽取两种双语先验分布,一种基于统计词对齐模型额次对齐分布,另一种基于 NAT 模型自蒸馏的分布。实验主结果如表 2 所示,本文选择了多个 NAT 模型来验证我们方法效果,多个数据集上的实验均表明我们的方法可以有效提高低频词的翻译准确度,从而带来 BLEU 的提升。
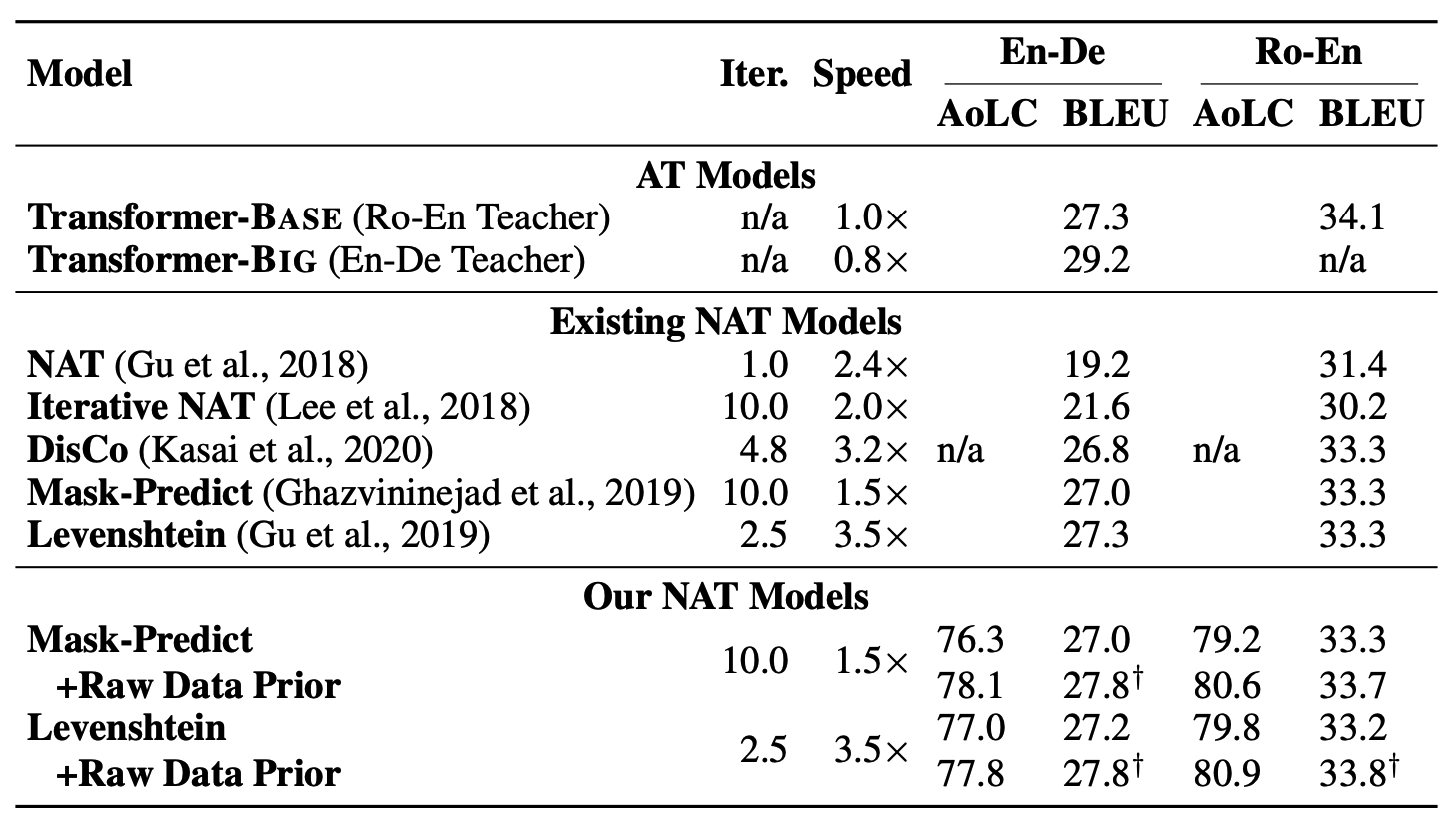
表 2. 在两个通用数据集上我们方法可以有效的改善译文质量并且超过之前方法
此外,本文还进行了大量的分析实验,发现该方法的确能够减少译文中的错翻现象,显著提高低频词的翻译效果并且输出更多低频的词汇(表 3 所示)。同时,发现现随着 AT 教师模型的增强,所提出的方法都能取得稳定的提升(表 4 所示)。
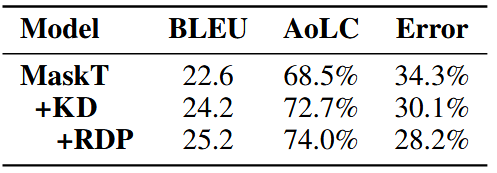
表 3. 在 Zh-En 数据集上的错翻问题的主观评价
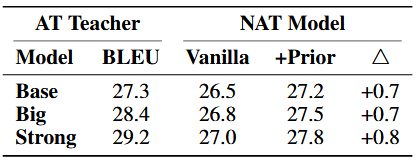
表 4. 在 En-De 数据集上不同的 AT 老师模型上的效果
3. 总结及展望
非自回归翻译(NAT)是目前最受关注的机器翻译子领域之一。NAT 模型有快速解码优势但其性能却弱于传统的自回归翻译方法。围绕提升 NAT 的翻译质量,前人主要从模型结构、训练目标等方面进行探索。而本工作另辟新径,从数据角度发现了知识蒸馏的副作用,并定义了词汇选择问题。这将改变传统的 KD 训练,并引导后续工作提出更合理的训练策略。
参考文献:
[1] Non-Autoregressive Neural Machine Translation. ICLR 2018.
[2] Sequence-Level Knowledge Distillation. EMNLP 2016.
[3] Understanding and Improving Lexical Choice in Non-Autoregressive Translation. ICLR 2021.
相关阅读:
公众号推荐:
AGI 概念引发热议。那么 AGI 究竟是什么?技术架构来看又包括哪些?AI Agent 如何助力人工智能走向 AGI 时代?现阶段营销、金融、教育、零售、企服等行业场景下,AGI应用程度如何?有哪些典型应用案例了吗?以上问题的回答尽在《中国AGI市场发展研究报告 2024》,欢迎大家扫码关注「AI前线」公众号,回复「AGI」领取。


InfoQ 主编

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论