核心要点
- 为了可靠且高效地处理大规模的视频流数据,需要有一个可扩展、能容错、松耦合的分布式系统;
- 本文中的示例应用使用开源的技术来构建这样的系统,这些技术包括 OpenCV、Kafka 和 Spark。另外,还可以使用 Amazon S3 或 HDFS 进行存储;
- 该系统包含了三个主要的组件:视频流收集器(Video Stream Collector)、流数据缓冲(Stream Data Buffer)以及视频流处理器(Video Stream Processor);
- 视频流收集器需要与一个网络摄像机(IP camera)集群协同工作,这些摄像机提供视频内容的实时流数据,并且还会使用 OpenCV 视频处理库把视频流转换为帧,将数据以 JSON 的格式传递给 Kafka Broker,供流数据缓冲组件使用;
- 视频流处理组件基于 Apache Spark 构建,同样会使用 OpenCV 进行视频流数据的处理。
在非结构化数据领域,技术带来了前所未有的爆炸性变化。移动设备、Web 站点、社交媒体、科学仪器、卫星、IoT 设备以及监控摄像头这样的数据源每秒钟都会产生大量的图片和视频。
管理和有效分析这些数据是一个很大的挑战,我们可以考虑一下某个城市的视频监控网络。试图监控每个摄像头的视频流来发现感兴趣的对象和事件是不现实且低效的。相反,计算机视觉(computer vision,CV)库能够处理这些视频流并提供智能的视频分析和对象探测结果。
但是,传统的 CV 系统有一定的局限性。在传统的视频分析系统中,带有 CV 库的服务器会同时收集和处理数据,所以服务器的故障将会丢失视频流数据。探测节点故障并将处理进程转移到其他节点上可能会导致碎片化的数据。
有很多的实际任务将大数据相关的技术推进到了视频流分析领域:并行且按需处理大规模的视频流、从视频帧中抽取不同的信息集、使用不同的机器学习库分析数据、将分析得到的数据以流的方式发送到应用的不同组件中以便于后续处理、将处理后的数据以不同的格式进行输出等等。
视频流分析——动作感应
为了可靠且高效地处理大规模的视频流数据,需要有一个可扩展、能容错、松耦合的分布式系统。在本文所讨论的视频流分析中,我们将会讨论这些原则。
视频流分析包括如下的类型:
- 对象跟踪(object tracking)
- 动作感应(motion detection)
- 面部识别(face recognition)
- 手势识别(gesture recognition)
- 增强现实(augmented reality)
- 图像分割(image segmentation)
本文中示例应用的使用场景将会是视频流中的动作感应。
动作感应指的是查找一个物体(通常会是人)相对于其周边环境位置变化的过程。它大多数用于持续监视特定区域的视频监控系统。CV 库提供的算法会分析这种摄像机所提供的实时视频并查找所发生的动作。如果感应到动作的话,将会触发一个事件,这个事件可以发送消息给应用或提示用户。
在本文中,用于视频流分析的应用由三个主要的组件组成:
- 视频流收集器(video stream collector)
- 视频数据缓冲(stream data buffer)
- 视频流处理器(video stream processor)
视频流收集器要接受来自网络摄像机集群的视频流数据。这个组件将视频帧序列化为流数据缓冲,这是一个用于视频流数据的可容错数据队列(queue)。视频流处理器消费缓冲中的流数据并进行处理。这个组件将会使用视频处理算法在视频流数据中探测动作。最后,处理过的数据或图片文件会存储到 S3 bucket 或 HDFS 目录中。这个视频流处理系统在设计时使用了 OpenCV 、Apache Kafka 以及 Apache Spark 框架。
OpenCV、Kafka 和 Spark 简介
如下简单介绍了相关的框架。
OpenCV
OpenCV(Open Source Computer Vision Library)是一个基于 BSD 许可证开源的库。这个库使用 C++ 编写,但是也提供了 Java API。OpenCV 包含了数百个 CV 算法,能够用来处理和分析图片及视频文件。请参考该文档了解更多细节。
Kafka
Apache Kafka 是一个分布式的流平台,它提供了一个发布和订阅流记录(streams of records)的系统。这些记录能够按照可容错的方式进行存储,消费者可以处理这些数据。关于 Kafka 的更多信息,请参见该文档。
Spark
Apache Spark 是一个快速、通用的集群计算系统。它提供了用于 SQL 和结构化数据处理的模块、用于机器学习的 MLlib、用于图像处理的 GraphX 以及 Spark Streaming。该文档中包含了关于Spark 的更多细节。
系统架构
图1 展现了视频流分析系统的架构图。
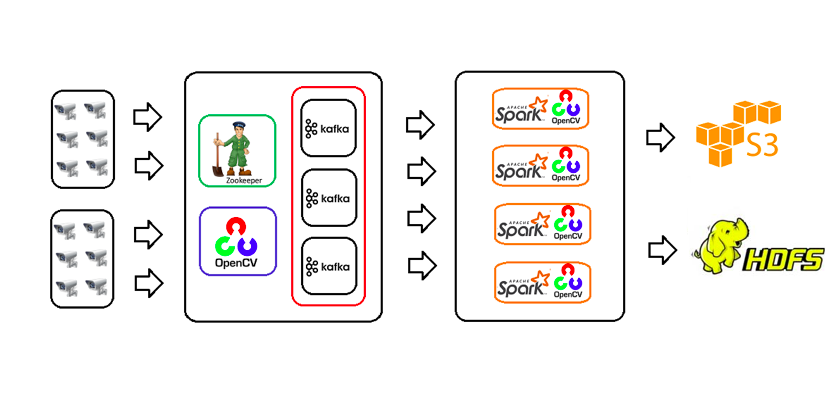
图1 视频流分析系统的架构图
设计与实现
本示例应用的代码可以通过 GitHub 获取。
如下的章节介绍了样例中视频流收集器、流数据缓冲以及视频流处理器的设计与实现细节。
视频流收集器
视频流收集器会与一个网络摄像机集群协同工作,这些摄像机会提供实时视频。该组件必须要从每个摄像机读取数据并将视频流转换为一系列的视频帧。为了区分每个网络摄像机,收集器要通过 camera.url 和 camera.id 属性维护摄像机 ID 与 URL 之间的映射,这两个属性会在 stream-collector.properties 文件中定义。这些属性在定义时,可以按照逗号分隔的格式定义摄像机 URL 和 ID 的列表。不同的摄像机可能会以不同的规格来提供数据,比如编解码器(codec)、分辨率或者每秒的帧数。在通过视频流创建帧的时候,收集器必须要保留这些细节数据。
收集器使用 OpenCV 视频处理库将视频流转换为帧。每帧都会调整为所需的分辨率(比如 640x480)。OpenCV 将每帧或每幅图片存储为 Mat 对象。Mat 需要转换为可连续的(字节数组)形式,在这个过程要保留帧的完整信息,比如 rows、cols 和 type。视频流收集器使用如下的 JSON 信息格式来存储这些细节。
{"cameraId":"cam-01","timestamp":1488627991133,"rows":12,"cols":15,"type":16,"data":"asdfh"}``cameraId是摄像机的唯一 ID。timestamp是帧生成的时间。rows、cols和type是 OpenCV Mat 特定的细节信息。data是基于 base-64 编码的字符串,代表了帧的字节数组。
视频流收集器使用 Gson 库将数据转换为 JSON 消息,这些消息会被发送至video-stream-event topic 上。它会使用 KafkaProducer 客户端将 JSON 消息发送至 Kafka broker。KafkaProducer 会将每个 key 发送至相同的分区并保证消息的顺序。
JsonObject obj = new JsonObject();
obj.addProperty("cameraId",cameraId);
obj.addProperty("timestamp", timestamp);
obj.addProperty("rows", rows);
obj.addProperty("cols", cols);
obj.addProperty("type", type);
obj.addProperty("data", Base64.getEncoder().encodeToString(data));
String json = gson.toJson(obj);
producer.send(new ProducerRecord<String, String>(topic,cameraId,json),new EventGeneratorCallback(cameraId));
图 2 以 JSON 消息的格式发送图片的代码片段
Kafka 的设计场景主要是用来处理较小的文本信息,但是这里的 JSON 信息中包含了视频帧的字节数组,它会比较大(比如能够达到 1.5MB),所以 Kafka 在处理较大的信息之前,需要进行配置的变更。如下的 KafkaProducer 属性需要进行调整:
batch.sizemax.request.sizecompression.type
请参见 Kafka 文档的 Producer Configs 章节以及本项目 GitHub 上的代码和属性文件了解更多细节。
视频数据缓冲
为了无丢失地处理大量的视频流数据,将这些视频数据保存到临时存储中就是非常必要的了。对于收集器所产生的数据,Kafka broker 的作用就像是一个缓冲队列(buffer queue)。Kafka 使用文件系统来存储信息,对这些信息的保存时间是可以配置的。
如果在处理之前就将数据保存到存储中,那就能保证它的持久性,同时还能提升系统的整体性能,因为处理器可以根据负载在不同的时间按照不同的速度来处理数据。当数据的生成速度超过数据的处理速度时,这种方式能够提升系统的可靠性。
Kafka 能够保证在单个分区中给定 topic 的消息顺序。如果数据的顺序比较重要的话,在处理这类数据时,该特性就是非常有用的。为了存储较大的信息,在 Kafka 服务器的server.properties文件中需要调整如下的配置:
message.max.bytesreplica.fetch.max.bytes
请参见 Kafka 文档的 Broker Configs 章节来了解这些属性的详细信息。
视频流处理器
视频流处理器会执行下面的三个步骤:
- 从 Kafka broker 中以
VideoEventDatadataset 的形式读取 JSON 信息; - 根据摄像机 ID 对
VideoEventDatadataset 进行分组并将其传递给视频流处理器; - 根据 JSON 数据创建一个 Mat 对象并处理视频流数据。
视频流收集器是基于 Apache Spark 构建的。Spark 提供了 Spark Streaming API,该 API 能够使用离散的流(discretized stream)或 DStream,并且还提供了基于 dataset 的新 Structured Streaming API。本应用中的视频流收集器使用 Structured Streaming API 来消费和处理来自 Kafka 的数据。需要注意的是,本应用所处理的格式化数据是 JSON 消息的形式,视频流处理器所要处理的非结构化视频数据会作为 JSON 消息的属性。Spark 的文档这样写道“Structured Streaming 提供了快速、可扩展、容错、端到端且保证仅执行一次的流处理功能,用户无需考虑流的相关事宜”。这也是视频流处理器围绕 Spark 的 Structured Streaming 设计的原因所在。Structured Streaming 为结构化的文本数据提供了内置的支持,并且支持聚合查询(aggregation queries)的状态管理。该引擎还提供了一些其他的特性,比如处理非聚合查询以及 datasets 外部的状态管理(Spark 2.2.0 的新特性)。
为了处理较大的信息,如下的 Kafka 消费者配置必须要传递给 Spark 引擎:
max.partition.fetch.bytesmax.poll.records
请参见 Kafka 文档的 Consumer Configs 章节了解这些属性的更多信息。
该组件的主类是VideoStreamProcessor。这个类首先创建一个SparkSession对象,它是与 Spark SQL 引擎协作的入口点。下一步是定义传入消息的模式(schema),这样的话,Spark 就能够使用该模式将消息从字符串格式解析为 JSON 格式。Spark 的 bean encoder 能够将其转换为Dataset<VideoEventData>。VideoEventData 是一个 Java bean 类,它会持有 JSON 消息的数据。
Dataset<VideoEventData> ds = spark.readStream().format("kafka")
.option("kafka.bootstrap.servers",prop.getProperty("kafka.bootstrap.servers"))
.option("subscribe",prop.getProperty("kafka.topic"))
.option("kafka.max.partition.fetch.bytes",prop.getProperty("kafka.max.partition.fetch.bytes"))
.option("kafka.max.poll.records", prop.getProperty("kafka.max.poll.records"))
.load().selectExpr("CAST(value AS STRING) as message")
.select(functions.from_json(functions.col("message"),schema).as("json"))
.select("json.*").as(Encoders.bean(VideoEventData.class));
3 spark streaming 处理 kafka 消息的代码片段
接下来, groupByKey 会根据摄像机的 ID 对数据集进行分组,得到 KeyValueGroupedDataset<String, VideoEventData>。它会使用一个 mapGroupsWithState transformation 并作用于一组 VideoEventData (Iterator
请阅读 GitHub 上的属性文件和代码了解更多细节。
技术和工具 Technologies and Tools
如下的表格列出了该视频流分析系统所用到的技术和工具
请参考文档了解这些工具的安装和配置。 Kafka 文档和 Spark 文档详细介绍了如何搭建环境以及如何以独立模式和集群模式运行应用。要安装 OpenCV 的话,请参考 OpenCV 文档。OpenCV 也可以通过 Anaconda 安装。
构建与部署
本节详细介绍了如何构建和运行示例应用的视频流收集器和视频流处理器组件。这个应用既能用来处理离线的视频文件,也能处理实时的摄像机数据,但是在这里我们配置它分析一个离线示例视频文件。请按照下述的步骤构建和运行应用。
1.下载并安装上述表格中所列的工具。确保 ZooKeeper 和 Kafka 服务器已处于启动运行的状态;
2. 该应用会使用 OpenCV 原生库(.dll 或.so),所以使用System.loadLibrary()加载它们。在系统环境变量中设置这些原生库的目录路径或者将路径作为命令行参数传递进来。例如,对于 64 位的 Windows 机器,原生库文件(opencv_java320.dll 和 opencv_ffmpeg320_64.dll)的路径将会是{OpenCV Installation Directory} \build\java\x64。
3.stream-collector.properties文件会将 Kafka topic 作为video-stream-event。在 Kafka 中创建该 topic 和分区(partitions)。我们可以使用 kafka-topic 命令来创建 topic 和分区;
4.stream-processor.properties文件有一个processed.output.dir属性,它指定了处理后图片的保存路径。创建文件并为该属性设置目录路径;
5.stream-collector.properties文件有一个camera.url属性,它保存了视频文件或视频源的路径或 URL。确保路径或 URL 的正确性 ;
6.检查VideoStreamCollector和VideoStreamProcessor组件中的log4j.properties文件,设置stream-collector.log和stream-processor.log文件的目录路径。检查应用在这些日志文件中所生成的日志信息,如果应用在运行中出现错误的话,这些日志会有一定的用处;
7. 应用会使用来自 OpenCV JAR 文件的 OpenCV API,但是在 Maven 中央仓库中并没有包含 OpenCV JAR 文件。在本应用中打包了 OpenCV JAR 文件,可以将其安装到本地 Maven 仓库中。在 pom.xml 文件中,maven-install-plugin已经进行了配置,它会与 clean 阶段(phase)关联来安装这个 JAR 文件。为了将 OpenCV JAR 安装到本地 Maven 仓库中,切换至 video-stream-processor 文件夹并运行如下命令:
mvn clean8. 为了让应用的逻辑尽可能简单,VideoStreamProcessor 只处理新的消息。VideoStreamProcessor应该要先于VideoStreamCollector组件启动并运行。如果要通过 Maven 运行VideoStreamProcessor,切换至 video-stream-processor 文件夹并执行如下命令:
mvn clean package exec:java -Dexec.mainClass="com.iot.video.app.spark.processor.VideoStreamProcessor"9.在VideoStreamProcessor启动之后,我们接下来就可以启动VideoStreamCollector组件了。切换至 video-stream-collector 文件夹并执行如下命令:
mvn clean package exec:java -Dexec.mainClass="com.iot.video.app.kafka.collector.VideoStreamCollector" -Dexec.cleanupDaemonThreads=falseGitHub 项目上打包了一个 sample.mp4 视频文件。这个视频文件的 URL 和 ID 已经通过camera.url和camera.id属性在 stream-collector.properties 文件中进行了配置。在处理完视频文件之后,图片将会存储到预先配置的目录中(参见第 4 步)。图 4 展现了应用的示例输出。

图 4 动作感应的示例输出
这个应用能够配置并处理多个视频源(包括离线的和实时的)。例如,除了 sample.mp4 文件之外,假设我们还要添加来自 webcam 的 feed 视频,编辑 stream-collector.properties 文件,在camera.url属性中添加逗号分隔的整数值(第一个 webcam 对应 0,第二个 webcam 对应 2,以此类推),添加对应的摄像机 ID 到camera.id属性中(cam-01,cam-02 等等),同样要使用逗号分隔。如下是一个样例:
camera.url=../sample-video/sample.mp4,0
camera.id=vid-01,cam-01## 结论
大规模的视频流分析需要有一个大数据技术作为支撑的健壮系统。像 OpenCV、Kafka 和 Spark 这样的开源技术能够用来构建可容错的分布式系统,并基于此来进行视频流分析。我们使用 OpenCV 和 Kafka 构建视频流收集组件,它会从不同的源接收视频流,并将其发送至视频流缓冲组件。Kafka 作为视频数据的缓冲组件,它为流数据提供了可持久化的存储。视频流处理组件使用 OpenCV 以及 Spark 的 Structured Streaming 进行构建。这个组件会从流数据缓冲中获取流式数据,并对数据进行分析。处理后的文件可以放到预先配置好的 HDFS 或 S3 bucket 中。我们使用动作感应作为视频流分析的用例,并提供了一个示例应用。
参考资料
- Online Security Analytics on Large Scale Video Surveillance System ( Spark Summit East 2016 )
- Large Scale Image Processing in Real-Time Environments with Kafka ( CS & IT )
- OpenCV 文档
- Kafka 文档
- Apache Spark 文档
- ZooKeeper 文档
关于作者
 Amit Baghel是一位软件架构师,他在使用 Java 生态系统的技术设计和开发企业级应用与产品方面有超过 16 年经验。他目前关注于 IoT、云计算、大数据解决方案、微服务、DevOps、持续集成与交付。您可以通过 e-mail:baghel_amit@yahoo.com 联系到 Amit Baghel。
Amit Baghel是一位软件架构师,他在使用 Java 生态系统的技术设计和开发企业级应用与产品方面有超过 16 年经验。他目前关注于 IoT、云计算、大数据解决方案、微服务、DevOps、持续集成与交付。您可以通过 e-mail:baghel_amit@yahoo.com 联系到 Amit Baghel。
查看英文原文: Video Stream Analytics Using OpenCV, Kafka and Spark Technologies
感谢张卫滨对本文的审校。




