简介:之前分享过一例集群节点 NotReady 的问题。在那个问题中,我们的排查路劲,从 Kubernetes 集群到容器运行时,再到 sdbus 和 systemd,不可谓不复杂。那个问题目前已经在 systemd 中做了修复,所以基本上能看到那个问题的几率是越来越低了。
之前分享过一例集群节点 NotReady 的问题。在那个问题中,我们的排查路劲,从 Kubernetes 集群到容器运行时,再到 sdbus 和 systemd,不可谓不复杂。那个问题目前已经在 systemd 中做了修复,所以基本上能看到那个问题的几率是越来越低了。
但是,集群节点就绪问题还是有的,然而原因却有所不同。
今天这篇文章,跟大家分享另外一例集群节点 NotReady 的问题。这个问题和之前那个问题相比,排查路劲完全不同。作为姊妹篇分享给大家。
问题现象
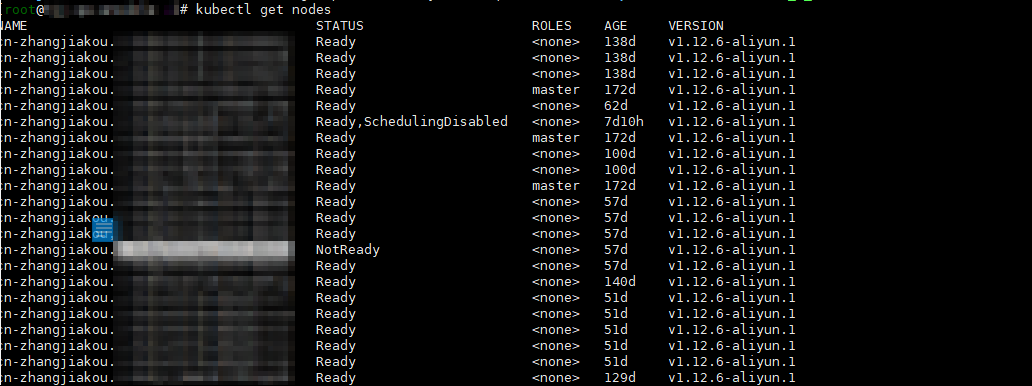
这个问题的现象,也是集群节点会变成 NotReady 状态。问题可以通过重启节点暂时解决,但是在经过大概 20 天左右之后,问题会再次出现。
问题出现之后,如果我们重启节点上 kubelet,则节点会变成 Ready 状态,但这种状态只会持续三分钟。这是一个特别的情况。
大逻辑
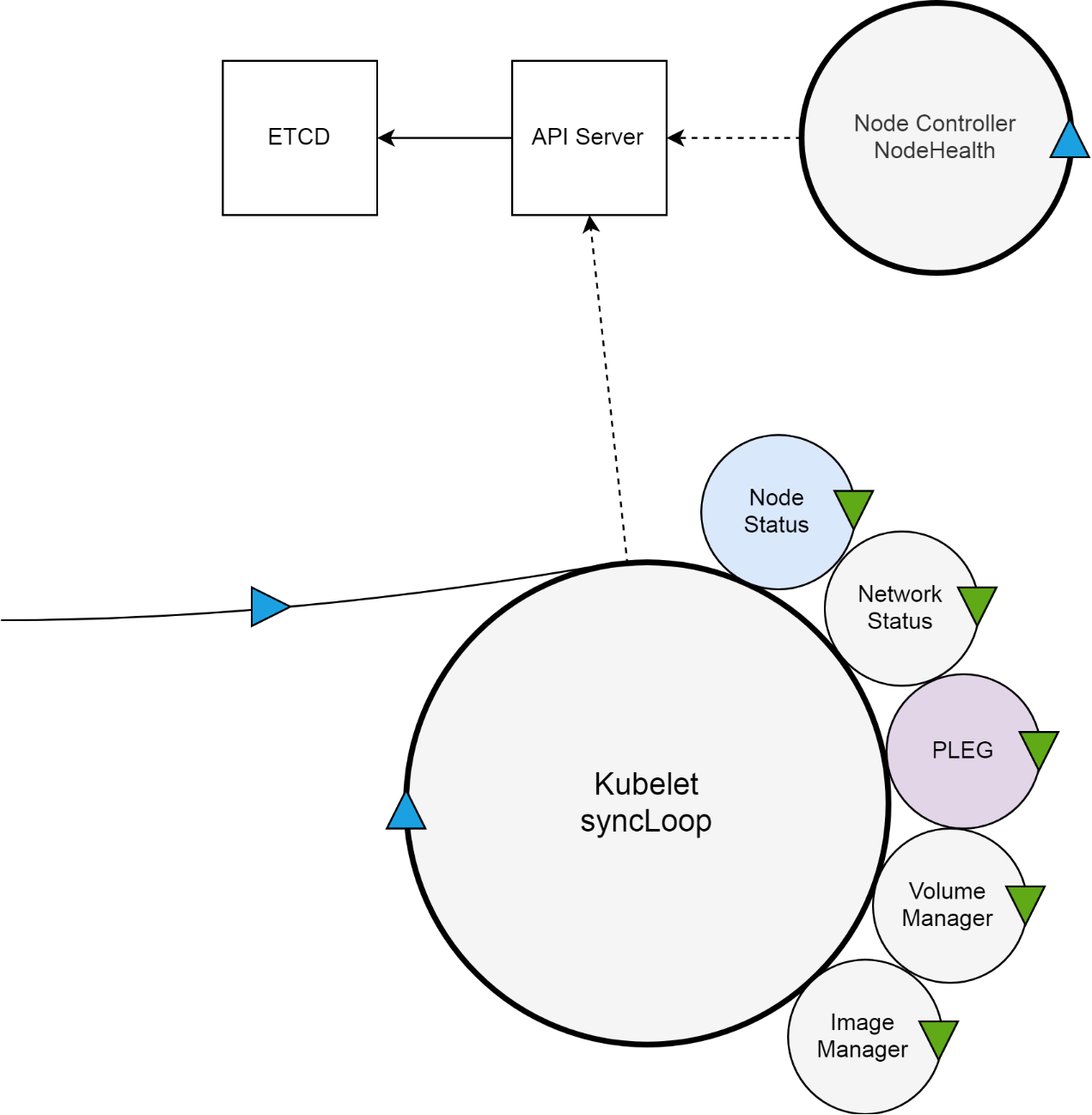
在具体分析这个问题之前,我们先来看一下集群节点就绪状态背后的大逻辑。Kubernetes 集群中,与节点就绪状态有关的组件,主要有四个,分别是集群的核心数据库 etcd,集群的入口 API Server,节点控制器以及驻守在集群节点上,直接管理节点的 kubelet。
一方面,kubelet 扮演的是集群控制器的角色,它定期从 API Server 获取 Pod 等相关资源的信息,并依照这些信息,控制运行在节点上 Pod 的执行;另外一方面,kubelet 作为节点状况的监视器,它获取节点信息,并以集群客户端的角色,把这些状况同步到 API Server。
在这个问题中,kubelet 扮演的是第二种角色。
Kubelet 会使用上图中的 NodeStatus 机制,定期检查集群节点状况,并把节点状况同步到 API Server。而 NodeStatus 判断节点就绪状况的一个主要依据,就是 PLEG。
PLEG 是 Pod Lifecycle Events Generator 的缩写,基本上它的执行逻辑,是定期检查节点上 Pod 运行情况,如果发现感兴趣的变化,PLEG 就会把这种变化包装成 Event 发送给 Kubelet 的主同步机制 syncLoop 去处理。但是,在 PLEG 的 Pod 检查机制不能定期执行的时候,NodeStatus 机制就会认为,这个节点的状况是不对的,从而把这种状况同步到 API Server。
而最终把 kubelet 上报的节点状况,落实到节点状态的是节点控制这个组件。这里我故意区分了 kubelet 上报的节点状况,和节点的最终状态。因为前者,其实是我们 describe node 时看到的 Condition,而后者是真正节点列表里的 NotReady 状态。
就绪三分钟
在问题发生之后,我们重启 kubelet,节点三分钟之后才会变成 NotReady 状态。这个现象是问题的一个关键切入点。
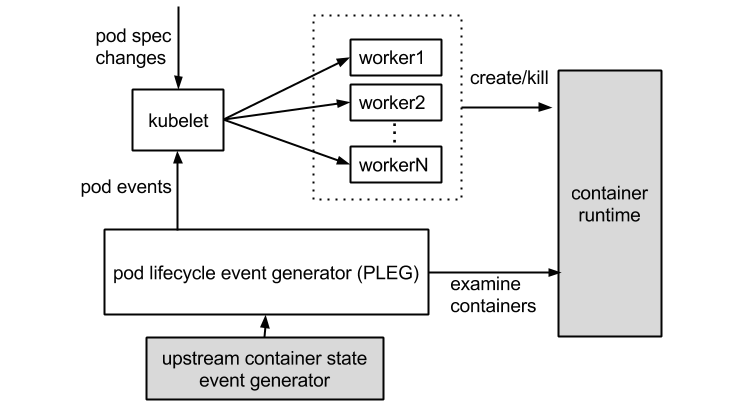
在解释它之前,请大家看一下官方这张 PLEG 示意图。这个图片主要展示了两个过程。一方面,kubelet 作为集群控制器,从 API Server 处获取 pod spec changes,然后通过创建 worker 线程来创建或结束掉 pod;另外一方面,PLEG 定期检查容器状态,然后把状态,以事件的形式反馈给 kubelet。
在这里,PLEG 有两个关键的时间参数,一个是检查的执行间隔,另外一个是检查的超时时间。以默认情况为准,PLEG 检查会间隔一秒,换句话说,每一次检查过程执行之后,PLEG 会等待一秒钟,然后进行下一次检查;而每一次检查的超时时间是三分钟,如果一次 PLEG 检查操作不能在三分钟内完成,那么这个状况,会被上一节提到的 NodeStatus 机制,当做集群节点 NotReady 的凭据,同步给 API Server。
而我们之所以观察到节点会在重启 kubelet 之后就绪三分钟,是因为 kubelet 重启之后,第一次 PLEG 检查操作就没有顺利结束。节点就绪状态,直到三分钟超时之后,才被同步到集群。
如下图,上边一行表示正常情况下 PLEG 的执行流程,下边一行则表示有问题的情况。relist 是检查的主函数。
止步不前的 PLEG
了解了原理,我们来看一下 PLEG 的日志。日志基本上可以分为两部分,其中 skipping pod synchronization 这部分是 kubelet 同步函数 syncLoop 输出的,说明它跳过了一次 pod 同步;而剩余 PLEG is not healthy: pleg was last seen active ago; threshold is 3m0s,则很清楚的展现了,上一节提到的 relist 超时三分钟的问题。
17:08:22.299597 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.000091019s ago; threshold is 3m0s]17:08:22.399758 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.100259802s ago; threshold is 3m0s]17:08:22.599931 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.300436887s ago; threshold is 3m0s]17:08:23.000087 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m0.700575691s ago; threshold is 3m0s]17:08:23.800258 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m1.500754856s ago; threshold is 3m0s]17:08:25.400439 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m3.100936232s ago; threshold is 3m0s]17:08:28.600599 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m6.301098811s ago; threshold is 3m0s]17:08:33.600812 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m11.30128783s ago; threshold is 3m0s]17:08:38.600983 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m16.301473637s ago; threshold is 3m0s]17:08:43.601157 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m21.301651575s ago; threshold is 3m0s]17:08:48.601331 kubelet skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 3m26.301826001s ago; threshold is 3m0s]
复制代码
能直接看到 relist 函数执行情况的,是 kubelet 的调用栈。我们只要向 kubelet 进程发送 SIGABRT 信号,golang 运行时就会帮我们输出 kubelet 进程的所有调用栈。需要注意的是,这个操作会杀死 kubelet 进程。但是因为这个问题中,重启 kubelet 并不会破坏重现环境,所以影响不大。
以下调用栈是 PLEG relist 函数的调用栈。从下往上,我们可以看到,relist 等在通过 grpc 获取 PodSandboxStatus。
kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc/transport.(*Stream).Header()kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc.recvResponse()kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc.invoke()kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc.Invoke()kubelet: k8s.io/kubernetes/pkg/kubelet/apis/cri/runtime/v1alpha2.(*runtimeServiceClient).PodSandboxStatus()kubelet: k8s.io/kubernetes/pkg/kubelet/remote.(*RemoteRuntimeService).PodSandboxStatus()kubelet: k8s.io/kubernetes/pkg/kubelet/kuberuntime.instrumentedRuntimeService.PodSandboxStatus()kubelet: k8s.io/kubernetes/pkg/kubelet/kuberuntime.(*kubeGenericRuntimeManager).GetPodStatus()kubelet: k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).updateCache()kubelet: k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).relist()kubelet: k8s.io/kubernetes/pkg/kubelet/pleg.(*GenericPLEG).(k8s.io/kubernetes/pkg/kubelet/pleg.relist)-fm()kubelet: k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil.func1(0xc420309260)kubelet: k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil()kubelet: k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.Until()
复制代码
使用 PodSandboxStatus 搜索 kubelet 调用栈,很容易找到下边这个线程,此线程是真正查询 Sandbox 状态的线程,从下往上看,我们会发现这个线程在 Plugin Manager 里尝试去拿一个 Mutex。
kubelet: sync.runtime_SemacquireMutex()kubelet: sync.(*Mutex).Lock()kubelet: k8s.io/kubernetes/pkg/kubelet/dockershim/network.(*PluginManager).GetPodNetworkStatus()kubelet: k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).getIPFromPlugin()kubelet: k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).getIP()kubelet: k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).PodSandboxStatus()kubelet: k8s.io/kubernetes/pkg/kubelet/apis/cri/runtime/v1alpha2._RuntimeService_PodSandboxStatus_Handler()kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).processUnaryRPC()kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).handleStream()kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).serveStreams.func1.1()kubelet: created by k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).serveStreams.func1
复制代码
而这个 Mutex 只有在 Plugin Manager 里边有用到,所以我们查看所有 Plugin Manager 相关的调用栈。线程中一部分在等 Mutex,而剩余的都是在等 Terway cni plugin。
kubelet: syscall.Syscall6()kubelet: os.(*Process).blockUntilWaitable()kubelet: os.(*Process).wait()kubelet: os.(*Process).Wait()kubelet: os/exec.(*Cmd).Wait()kubelet: os/exec.(*Cmd).Run()kubelet: k8s.io/kubernetes/vendor/github.com/containernetworking/cni/pkg/invoke.(*RawExec).ExecPlugin()kubelet: k8s.io/kubernetes/vendor/github.com/containernetworking/cni/pkg/invoke.(*PluginExec).WithResult()kubelet: k8s.io/kubernetes/vendor/github.com/containernetworking/cni/pkg/invoke.ExecPluginWithResult()kubelet: k8s.io/kubernetes/vendor/github.com/containernetworking/cni/libcni.(*CNIConfig).AddNetworkList()kubelet: k8s.io/kubernetes/pkg/kubelet/dockershim/network/cni.(*cniNetworkPlugin).addToNetwork()kubelet: k8s.io/kubernetes/pkg/kubelet/dockershim/network/cni.(*cniNetworkPlugin).SetUpPod()kubelet: k8s.io/kubernetes/pkg/kubelet/dockershim/network.(*PluginManager).SetUpPod()kubelet: k8s.io/kubernetes/pkg/kubelet/dockershim.(*dockerService).RunPodSandbox()kubelet: k8s.io/kubernetes/pkg/kubelet/apis/cri/runtime/v1alpha2._RuntimeService_RunPodSandbox_Handler()kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).processUnaryRPC()kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).handleStream()kubelet: k8s.io/kubernetes/vendor/google.golang.org/grpc.(*Server).serveStreams.func1.1()
复制代码
无响应的 Terwayd
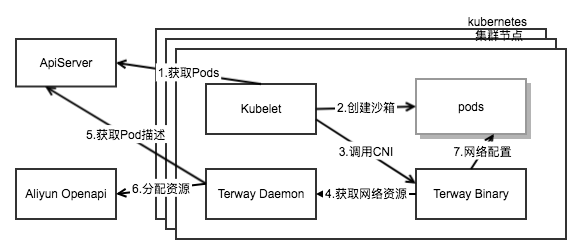
在进一步解释这个问题之前,我们需要区分下 Terway 和 Terwayd。本质上来说,Terway 和 Terwayd 是客户端服务器的关系,这跟 flannel 和 flanneld 之间的关系是一样的。Terway 是按照 kubelet 的定义,实现了 cni 接口的插件。
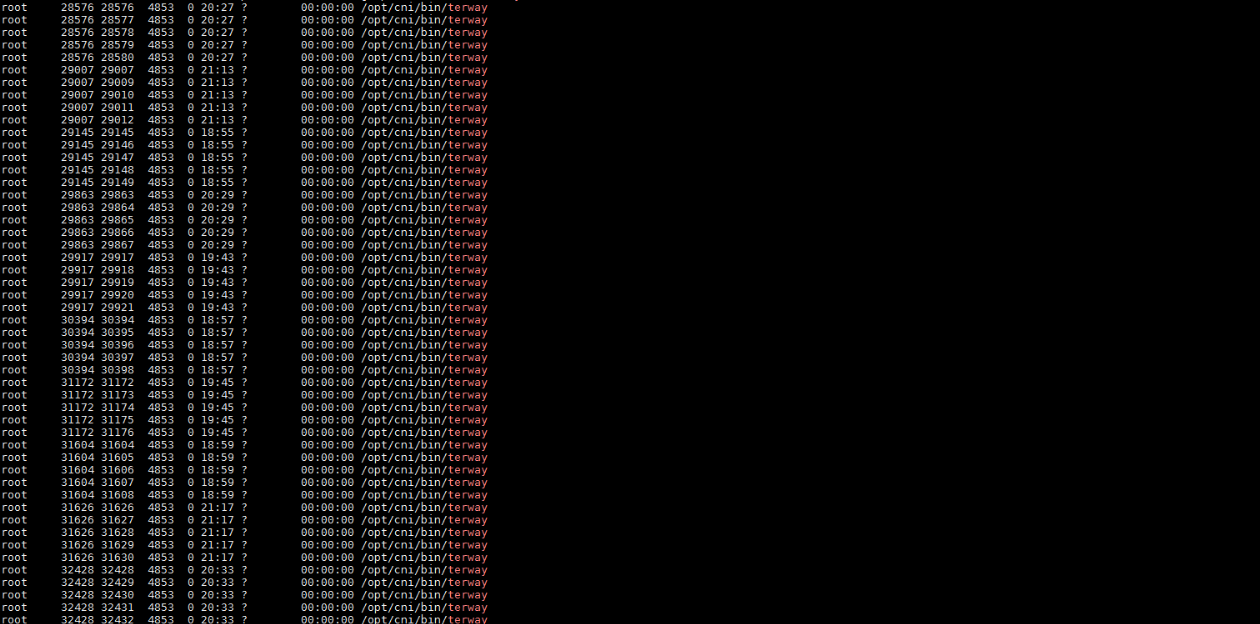
而在上一节最后,我们看到的问题,是 kubelet 调用 CNI terway 去配置 pod 网络的时候,Terway 长时间无响应。正常情况下这个操作应该是秒级的,非常快速。而出问题的时候,Terway 没有正常完成任务,因而我们在集群节点上看到大量 terway 进程堆积。
同样的,我们可以发送 SIGABRT 给这些 terway 插件进程,来打印出进程的调用栈。下边是其中一个 terway 的调用栈。这个线程在执行 cmdDel 函数,其作用是删除一个 pod 网络相关配置。
kubelet: net/rpc.(*Client).Call()kubelet: main.rpcCall()kubelet: main.cmdDel()kubelet: github.com/AliyunContainerService/terway/vendor/github.com/containernetworking/cni/pkg/skel.(*dispatcher).checkVersionAndCall()kubelet: github.com/AliyunContainerService/terway/vendor/github.com/containernetworking/cni/pkg/skel.(*dispatcher).pluginMain()kubelet: github.com/AliyunContainerService/terway/vendor/github.com/containernetworking/cni/pkg/skel.PluginMainWithError()kubelet: github.com/AliyunContainerService/terway/vendor/github.com/containernetworking/cni/pkg/skel.PluginMain()
复制代码
以上线程通过 rpc 调用 terwayd,来真正的移除 pod 网络。所以我们需要进一步排查 terwayd 的调用栈来进一步定位此问题。Terwayd 作为 Terway 的服务器端,其接受 Terway 的远程调用,并替 Terway 完成其 cmdAdd 或者 cmdDel 来创建或者移除 pod 网络配置。
我们在上边的截图里可以看到,集群节点上有成千 Terway 进程,他们都在等待 Terwayd,所以实际上 Terwayd 里,也有成千的线程在处理 Terway 的请求。
使用下边的命令,可以在不重启 Terwayd 的情况下,输出调用栈。
curl --unix-socket /var/run/eni/eni.socket 'http:/debug/pprof/goroutine?debug=2'
复制代码
因为 Terwayd 的调用栈非常复杂,而且几乎所有的线程都在等锁,直接去分析锁的等待持有关系比较复杂。这个时候我们可以使用“时间大法”,即假设最早进入等待状态的线程,大概率是持有锁的线程。
经过调用栈和代码分析,我们发现下边这个是等待时间最长(1595 分钟),且拿了锁的线程。而这个锁会 block 所有创建或者销毁 pod 网络的线程。
goroutine 67570 [syscall, 1595 minutes, locked to thread]:syscall.Syscall6()github.com/AliyunContainerService/terway/vendor/golang.org/x/sys/unix.recvfrom()github.com/AliyunContainerService/terway/vendor/golang.org/x/sys/unix.Recvfrom()github.com/AliyunContainerService/terway/vendor/github.com/vishvananda/netlink/nl.(*NetlinkSocket).Receive()github.com/AliyunContainerService/terway/vendor/github.com/vishvananda/netlink/nl.(*NetlinkRequest).Execute()github.com/AliyunContainerService/terway/vendor/github.com/vishvananda/netlink.(*Handle).LinkSetNsFd()github.com/AliyunContainerService/terway/vendor/github.com/vishvananda/netlink.LinkSetNsFd()github.com/AliyunContainerService/terway/daemon.SetupVethPair()github.com/AliyunContainerService/terway/daemon.setupContainerVeth.func1()github.com/AliyunContainerService/terway/vendor/github.com/containernetworking/plugins/pkg/ns.(*netNS).Do.func1()github.com/AliyunContainerService/terway/vendor/github.com/containernetworking/plugins/pkg/ns.(*netNS).Do.func2()
复制代码
原因深入分析前一个线程的调用栈,我们可以确定三件事情。第一,Terwayd 使用了 netlink 这个库来管理节点上的虚拟网卡,IP 地址及路由等资源,且 netlink 实现了类似 iproute2 的功能;第二,netlink 使用 socket 直接和内核通信;第三,以上线程等在 recvfrom 系统调用上。
这样的情况下,我们需要去查看这个线程的内核调用栈,才能进一步确认这个线程等待的原因。因为从 goroutine 线程号比较不容易找到这个线程的系统线程 id,这里我们通过抓取系统的 core dump 来找出上边线程的内核调用栈。
在内核调用栈中,搜索 recvfrom,定位到下边这个线程。基本上从下边的调用栈上,我们只能确定,此线程等在 recvfrom 函数上。
PID: 19246 TASK: ffff880951f70fd0 CPU: 16 COMMAND: "terwayd" #0 [ffff880826267a40] __schedule at ffffffff816a8f65 #1 [ffff880826267aa8] schedule at ffffffff816a94e9 #2 [ffff880826267ab8] schedule_timeout at ffffffff816a6ff9 #3 [ffff880826267b68] __skb_wait_for_more_packets at ffffffff81578f80 #4 [ffff880826267bd0] __skb_recv_datagram at ffffffff8157935f #5 [ffff880826267c38] skb_recv_datagram at ffffffff81579403 #6 [ffff880826267c58] netlink_recvmsg at ffffffff815bb312 #7 [ffff880826267ce8] sock_recvmsg at ffffffff8156a88f #8 [ffff880826267e58] SYSC_recvfrom at ffffffff8156aa08 #9 [ffff880826267f70] sys_recvfrom at ffffffff8156b2fe#10 [ffff880826267f80] tracesys at ffffffff816b5212 (via system_call)
复制代码
这个问题进一步深入排查,是比较困难的,这显然是一个内核问题,或者内核相关的问题。我们翻遍了整个内核 core,检查了所有的线程调用栈,看不到其他可能与这个问题相关联的线程。
修复
这个问题的修复基于一个假设,就是 netlink 并不是 100%可靠的。netlink 可以响应很慢,甚至完全没有响应。所以我们可以给 netlink 操作增加超时,从而保证就算某一次 netlink 调用不能完成的情况下,terwayd 也不会被阻塞。
总结
在节点就绪状态这种场景下,kubelet 实际上实现了节点的心跳机制。kubelet 会定期把节点相关的各种状态,包括内存,PID,磁盘,当然包括这个文章中关注的就绪状态等,同步到集群管控。kubelet 在监控或者管理集群节点的过程中,使用了各种插件来直接操作节点资源。这包括网络,磁盘,甚至容器运行时等插件,这些插件的状况,会直接应用 kubelet 甚至节点的状态。
作者简介
罗建龙(花名声东),阿里云技术专家。多年操作系统和图形显卡驱动调试和开发经验。目前专注云原生领域,容器集群和服务网格。
相关阅读
深入浅出Kubernetes 实践篇 (一):节点就绪问题之一












评论