
“通过使用 AWS,桐树基因同样一个样本分析时间比原来快了 30-40 分钟。”
——桐树基因 高级副总裁、首席信息官 全雪萍博士
关于桐树基因
上海桐树生物科技有限公司(以下简称“桐树基因”)是一家专注于肿瘤精准医疗领域的高新技术企业,总部位于上海宝山科技创新园,已分别在常州和广州设立有 GMP 标准的生产中心和国际标准的医学临检中心。
桐树基因与世界顶尖的高通量测序生物公司——赛默飞世尔(ThermoFisher)达成战略合作关系,目前已形成基于高通量基因测序技术与生物信息分析的 ctDNA 精准检测体系,500 多项分子病理检测项目,实现了对肿瘤无创、准确、动态的基因分析,为临床提供精准用药、疗效监测、术后复发监测、风险预测和早期检测等咨询服务。其产品线全面满足临床及科研的不同需求,检测服务网络现已覆盖全国五大区域 500 多家核心医院。短短三年内,桐树基因的业务量呈现出指数级增长,销售额已居同行业前列。
面临的挑战
在过去二十年,科学家对人类基因组的研究促成了基因检测等一系列新技术的出现,还带来基因诊断、基因治疗、靶向药物等医学新手段,生物医学已经进入建立在基因组大数据基础上的精准医学时代。
肿瘤的基因检测是桐树基因的重要业务,属于精准医学范畴。基于检测技术的发展,以及 1990 年启动的“人类基因组计划”和 2006 年启动的国际癌症基因组计划等大型研究,揭示出许多与癌症相关的重要突变,获得 50 余种肿瘤的特定分子异常谱型,让人类更深入地了解了癌症发生发展的分子机制。
但肿瘤的基因检测是十分复杂的,涉及很多的基因、位点。目前肿瘤基因检测大多基于二代高通量测序技术进行的,这种技术能够同时对上百万个甚至到数十亿个基因分子进行测序,产生的数据非常大。在检测时,每个样本可以产生 10 的 8 次方至 10 的 9 次方的短序列片段,每个序列片段又约是 150 个基因碱基长度,因此每个样本的原始数据十分庞大。从文件大小表现来看一般是从 10GB 到 30GB 之间。在这样的情况下,对于数据的存储、I/O、计算的要求都非常高。
而桐树基因与 AWS 合作之前,采用的是租赁服务器的方式,在公司内进行维护,每个月维护成本很高,包括服务器本身的成本和电费、空调费以及 1-2 个运维人员的成本等。同时随着业务发展,需分析的样本量的增加也使总成本越来越高。另外,此前出现服务器故障或者断电还会导致分析流程中断,影响业务进程。因此,桐树基因亟需通过上云来达到解决本地分析能力不足、提高分析效率、节约成本等目标。
为什么选择 AWS
AWS 的冷热存储分离、面向对象的存储、容器化应用、一键式构建并行化集群和分布式集群等功能,十分有效地解决了精准医学数据,特别是由二代高通量测序产生的数据量大,对存储、I/O、算力要求高的问题,有助于根据不同的临床场景、检测技术、分析特征组合不同的容器化分析模块、搭建不同的分析流程,准确快速完成大批量、大样本的数据分析解读,以极快的速度将检测结果呈递到医生和患者面前。目前,桐树基因使用的 AWS 服务包括 Amazon Simple Storage Service (Amazon S3)、 Amazon Elastic File System (EFS)、 Amazon Elastic Block Store (EBS)、 Amazon Elastic Compute Cloud (Amazon EC2) 、 Amazon Elastic Container Registry (ECR)、 AWS CloudFormation 、 AWS ParallelCluster 、 AWS Batch 、 AWS Lambda 等等。
冷热存储分离及多样化存储能力解决精准医学数据量大、存储要求高问题
对于桐树基因来说,基因样本分析的数据量是源源不断增加的,不同数据的存储要求不同,需要进行冷热存储分离。对于正在分析的数据,需要频繁调用进行处理,则放在热存储里。对于已经分析完的数据,包括原始数据或者热数据的结果等,这些数据可能需要长期存储不需要经常调用,则放在冷存储中。
桐树基因使用了 AWS 多种存储能力,Amazon S3 用于存储基因测序的原始数据以及分析完的数据等,利用 Amazon S3 的数据归档能力可以很好地降低成本。Amazon EFS 可以在多个 Amazon EC2 实例中共享网络文件系统,因此桐树基因通过 Amazon EFS 来管理多个服务器共享的一些公共数据,比如人类参考基因组是每个分析流程都会用到的共享文件。Amazon EBS 的 I/O 速度很高,主要用来做数据库或者托管应用程序,进行大数据分析。
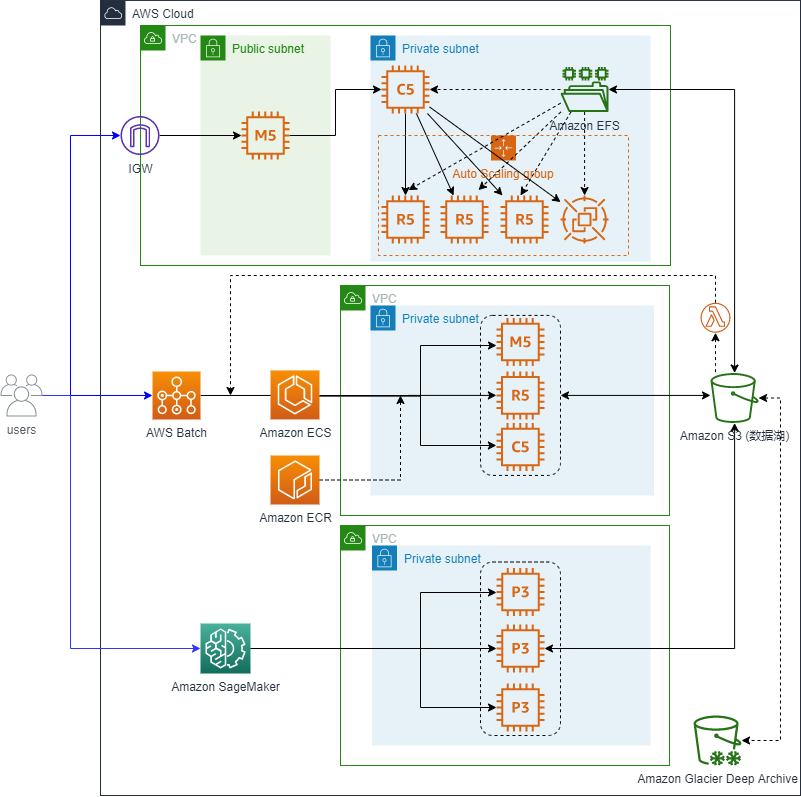
桐树基因基于 AWS 的数据分析架构示意图
一键式构建集群,提高批量样本及大型单个样本的分析能力
桐树基因以前常碰到这样的问题:在本地服务器上分析时,如果有一个计算节点宕机,整批分析都会终止,需要再次提交,重新分析。在业务上云后,AWS 提供的一键式集群构建能力,可以实现同时对几十个到几百个样本进行分析,单个计算节点宕机不会影响其他节点的数据分析。当桐树基因遇到需要在半天或一天内把数据解读完,再将报告发给用户的情况时,利用一键式构建并行集群,就可以对样本进行具体的处理和分析,同时也可以根据提交的样本数量的增加,随时增加计算节点。
除了一键式构建并行集群,AWS 一键式构建分布式集群也解决了桐树基因针对大型单个样本分析的难题。比如 WES 全外显子测序数据量非常大,在对此数据进行分析时,就需要利用分布式集群,将一个任务拆分再进行分析来缩短单个任务的分析时间。同时通过容器化管理,还可以把很多比较标准的分析步骤打包成容器。通过把已经打包好的容器相互组合,来搭建新的分析流程。
无服务器架构与弹性配置提升计算能力
在基因样本分析中,一个文件里会存储几百万个短序列 DNA 信息。在分析时,需要把这些短序列与参考基因组进行对比,识别患者个体与参考基因组之间的差异。在这一过程中生成的中间文件,除了要保存最初的短序列以及参考基因组的信息外,还要记录这些序列比对参考基因组上的位置,与参考序列之间的差异,以及比对的质量等多种维度的信息。因此中间分析过程产生的文件是呈指数级增长的,体量比原始数据暴增 5-10 倍。而在样本分析结束后,分析结果仅仅记录比对差异,例如哪个基因在哪个位点上有什么变化等,此时数据量又会逐渐下降。基于这样的数据特性,AWS 弹性的计算资源配置就显得十分重要。
桐树基因使用 AWS 搭建的架构是基于无服务器的,通过对 AWS Lambda 的应用,一方面可扩展性很好,另外节省计算资源,系统会根据样本分析任务的需求去申请计算资源,保证在业务高峰期弹性地进行配置。
获得的收益
在 AWS 完善的服务与技术支持下,桐树基因很好地解决了肿瘤基因测序中大批量数据存储与计算的难题。避免先前租赁服务器故障或者断电导致的分析流程中断的问题,同时在业务高峰时更能从容应对,用更少的费用获得更大的计算能力。
另外,依托 AWS 能力缩短了整体科研流程的分析时间。经过桐树基因的测试,同一个样本的分析时间比原来快了 30-40 分钟;对于批量样本的分析来说,整体节省了 2/3 的时间。在安全保障上,桐树基因在设置特有的权限策略之后,几乎不用担心外部安全问题。Amazon S3 和 Amazon EBS 之间批量的数据传递也不用担心泄露,有效地保护了数据安全;而且传输速度也有所提升,之前本地服务器之间传输速度在 100M/s 左右,现在 Amazon S3 和 Amazon EBS 之间传输速度提升到 150M/s 左右。
展望未来
面向未来,桐树基因在大数据和 AI 方向已经开始布局,对 Amazon Redshift 数据仓库、Amazon EMR 大数据平台等服务已经准备进行测试。在 AI 层面,桐树基因已经在 AWS 开通 GPU 的计算资源,开始使用 Amazon SageMaker 的一些功能以实现对患者进行更精细地诊断,以及对一些新的药物靶标的预测。同时桐树基因也在积极整合一些分子层面组织学表型的数据,如病理、影像等,从而把基因层面和表型层面的信息整合在一起研究新的 AI 模型。
为什么使用 AWS
弹性伸缩能力减轻计算压力
容器化应用节省计算时间
多样化存储能力满足存储要求
一键式构建集群提升分析能力




