

介绍
在构建 web 应用程序时,可扩展性是非常重要的部分。有多种方法可用于扩展 web 应用程序层和数据库层。我将通过微软 Azure 服务示例来解释这些方法。
1. 扩展 web 应用程序
假设你有一个托管在 VM 上的 web 应用程序。一开始,网站每秒接收 10 个请求。但是现在,在你推出了一个很酷的新产品或服务后,网站每秒会接收到数千个请求。VM 将接收所有的负载,在某个时刻,它将拒绝请求,如果没有发生宕机,至少会慢下来,这对业务的增长来说是个坏消息。怎样解决这个问题?你也许会说:我需要更强大的 VM!而你所说的其实是所谓的垂直扩展。
a. 垂直扩展
如果 8GB RAM、13 核处理器和 HDD 硬盘不够用的话,你可以再启动另一个 VM。新的 VM 配备了 512GB RAM、Xeon 处理器和最新的 SSD 硬盘。这就是垂直扩展。这是扩展 web 应用程序最容易,也是最快的方法。只需要把 web 应用程序的内容迁移到更大的新 VM 上,无需修改源代码。Azure 提供高达 448GB 的 VM 专用 RAM。
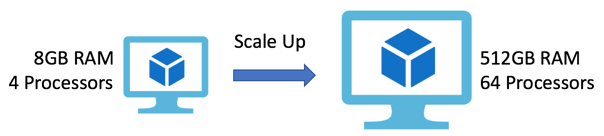
扩展到更大的 VM
在迁移到另一个 VM 上时,该应用程序也许会停止运行一段时间,并可能丢失用户的 HTTP 会话和 Cookie。
即使用这样巨型的 VM,应用程序还是无法处理所有的负载,那么垂直扩展就达到其极限了,毕竟 VM 无法拥有无限的 RAM 和 CPU。那么,如果我们可以在多个 VM 实例上分享这些负载呢?这就是水平扩展。
b. 水平扩展
垂直扩展关注的是使用更强大的单台机器,而水平扩展则是使用多台机器。这样,我们就可以拥有更多 RAM 和 CPU,不是只在一台 VM 上,而是在 VM 集群上。同样的解决方案可用于通过更多的处理器来获得更强大的计算能力,也即从单个处理器/线程迁移到多个处理器/线程上。
水平扩展需要重新思考应用程序的架构,在某些场景中还需要修改源代码。

水平扩展到多实例
这种方法需要一个方式来决定将用户或 HTTP 请求发送到哪个 VM 实例。这就是负载均衡器或流量管理器。
c. 负载均衡器、流量管理器
负载均衡器和流量管理器用于在多个实例之间分配网络流量负载。
它们使用了多种算法,以下是其中一些:
轮询调度(Round Robin):按顺序轮流。
最少连接(Least Connection):请求被发送给服务活动会话数量最少的服务器。
链式故障转移:只有在前一个服务器无法接收更多请求时,才将请求重定向到下一个服务器。
加权响应时间:将请求重定向到当前响应最快的服务器。
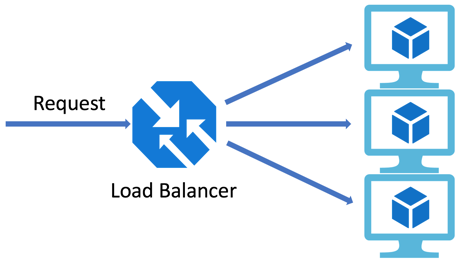
使用了负载均衡器的路由请求
如果采用了这个解决方案,你可以在 Azure 中启动 20 个 VM 实例。但是,如果尝试访问部署在离用户较远的服务器上的图像、视频、Html 或其他静态资源,请求太耗时,这个时候该怎么办?这个时候可以使用 CDN。
d. 内容交付网络(CDN)
CDN 用于降低从服务器获取静态内容到用户位置的延迟。造成该延迟的主要原因有两个。第一个原因是用户和服务器之间的物理距离太长。CDN 位于全球多个称为 POP(Point-of-Presence)的位置上,因此可能存在一个比服务器更接近用户的 CDN。第二个原因是访问磁盘上的文件。CDN 可能使用 HDD、SSD 或 RAM 组合来缓存这些数据,具体取决于数据的访问频率。缓存具有生存时间(time-to-live,简称 TTL),表示缓存内容在某个时刻过期。
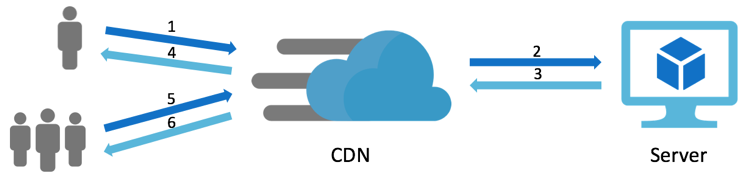
使用 CDN 获取缓存内容
CDN 缓存的是静态内容文件。但是,如果需要缓存一些动态数据,那该怎么办?可以用缓存来解决这个问题。
e. 缓存
当很多对数据库的 SQL 请求生成相同的结果时,最好可以将这些结果缓存在内存中,以确保更快的数据访问,并减少数据库的负载。比如,一种典型的用例是在网站主页上为所有用户列出排名前 10 的产品。缓存位于 RAM 中而不是硬盘上,可以保存跟 RAM 同样多的数据。数据以键值对的形式存储。缓存可以跨多区域分布。
Azure Redis Cache 可以存储高达 530GB 的数据,不过 Azure 没有提供 Memcahed 缓存服务。
如果底层基础设施出现故障,可能会发生潜在的数据丢失。Redis 为数据持久性提供了一种解决方案,而 Memcached 没有。
当用户在网站中搜索特定信息时,服务器会收到请求,并从数据库获取相关的数据。大多数请求在形式上是类似的。那么,为什么不缓存这些结果呢?这就是 Elasticsearch 大展身手的时候了。
f. Elasticsearch
Elasticsearch 可以用于存储预定义搜索查询及其结果。因为它是在内存中保存数据,所以比从数据库中检索这些数据要快得多。它还可以在你输入搜索关键字时提供几乎实时的搜索建议。这样可以减少数据库的负载,同时也减少了服务器负载,因为处理请求用时更少。Elasticsearch 可以通过 REST API 访问,不过需要修改应用程序的代码。
Elasticsearch 还可以用于日志分析和实时应用程序监控。
当使用多个单体 web 应用程序副本仍然不足以或不能有效地处理所有用户请求时,需要考虑把应用程序分成 2 个部分:web app 和 web API。
g. 前后端分离
单体架构 web 应用程序通常由 2 层组成:Web API 和前端 web app。ASP. NET MVC 应用程序就是这种情况,其中视图和业务逻辑存在同一个服务器上。在这种情况下,服务器不仅要处理用户获取数据的请求,还要渲染 web 页面以生成 HTML 内容。第 2 个任务可以通过在客户端使用 SPA(Single Page Application,单页面应用程序)来实现。因此,应用程序的视图部分可以迁移到另一台单独的服务器上。现在是由两台服务器而不是一台服务器为用户提供服务。
这种方法需要重写应用程序。
把应用程序分成 2 个部分还不够?那么就分成多个部分,怎么样?现在轮到微服务出场了。
h. 微服务和容器
微服务是一种把单个应用程序作为一组小型服务而不是单个巨型应用程序来开发的方法。每个小型的服务在自己的进程中运行,而不是依赖单个进程来运行整个应用程序。典型的例子是将电子商务应用程序分成多个微服务,用于支付、前端用户界面、电子邮件通知、管理评论和推荐。
可以把微服务视为 OOP 中的关注点分离和单一责任原则,只是这些原则作用的不是类层面,也而是组件层面。
使用这种方法,可以只扩展应用程序的特定部分,以便接收更多负载。因此,你可以有 5 个运行前端微服务的实例和 2 个运行支付微服务的实例。
这些微服务使用轻量级的机制进行通信,这些轻量级机制通常是 HTTP API。因为它们是轻量级的,在运行时不需要占用整个 VM 实例。相反,它们可以在容器上运行。容器是 OS 虚拟化的另一种形式。与 VM 不同,容器只提供了运行应用程序所需的最少资源,比 VM 具有更好的扩展性。
这些容器可以通过像 Kubernetes 或 Swarm 这样的编配器进行管理。
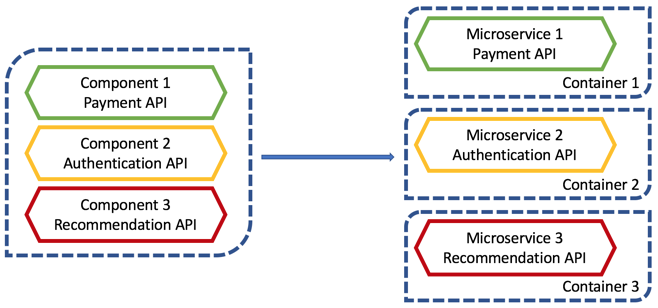
将每个微服务托管在一个容器中
从单体到微服务需要对应用程序源代码进行大量更改。要求从头重写整个应用程序并不罕见。
Azure 支持 Docker 容器,还支持像 Kubernetes、Service Fabric 和 Swarm 这样的容器编配器。
借助微服务,单体应用程序可以按照业务领域分成小块。除了把应用程序分成更小的块之外,我们还可以更进一步吗?接下来,无服务器应用程序登场了。
i. Azure Function(无服务器应用程序)
无服务器应用程序是一小部分应用程序,它托管在自身的实例上。该实例受到管理,因此用户不需要关心任何容器或 VM 的问题。它可以根据负载情况自动水平扩展。通常,可用它调整图像的大小或处理图像、在数据库上启动一项作业等操作,这些操作通常独立于业务逻辑。
现在我们运行很多层,每一层都在不同的端点上,客户端应用程序会问:我应该去哪里?API 管理就是设计用来解决这个问题的。
j. Azure API Management
负载均衡器在 VM 上分发负载,而 API Management 可以在不同 API 端点或微服务上分发负载。这种分发机制考虑到了每个端点上的负载。
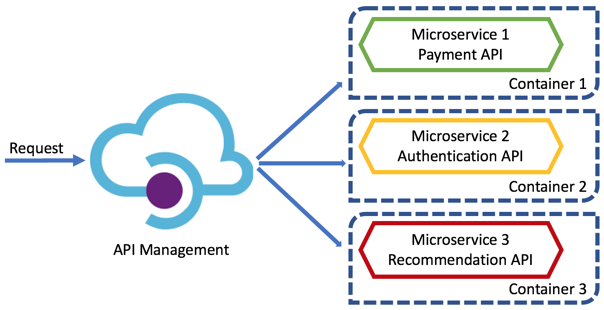
API Management 在不同的 API 服务之间分配负载
我们把单体应用程序分成多个小模块,这些模块彼此间需要通信。很显然,它们可以使用 REST web 服务。有些通信不需要使用同步的方式,既然可以不使用同步的方式,那为什么还要等待响应呢?这个时候可以使用队列。
k. Azure Queue Storage
队列为软件组件之间的通信提供了异步解决方案。在使用 REST web 服务进行通信时,所请求的服务器必须可用,否则请求就会失败。而在使用队列时,及时请求的服务器不可用也没问题。请求可以在队列中等待,当服务器稍后可用时继续处理请求。这种方法有助于解耦不同的组件,使它们易于扩展并具有弹性。
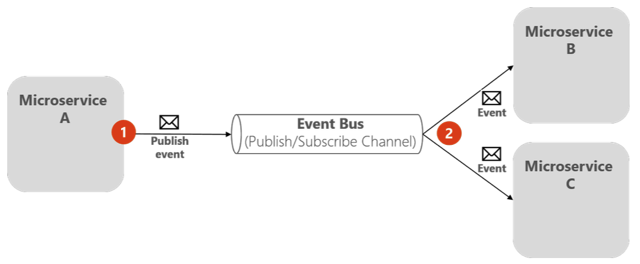
基于消息的微服务间通信
还有其他一些技术可用来减少服务器负载。除了服务器之外,还有谁可以处理数据?在某些场景中,前端也许是个不错的选择。
l. 把任务推送到客户端
很多任务不需要涉及数据库或服务器。比如,如果前端可以自行调整图像大小,那么还要什么服务器呢?多年前,服务器试图为客户端完成所有繁重的工作,因为那时候客户端还不够强大。现在,情况已经不同了:拥有 8 个内核的处理器及 4GB RAM 对于一台移动设备来讲已经不是什么令人惊讶的配置了。
不使用服务器的另一种解决方案是:如果确定能获得同样的响应,那么就不需要多次发出同样的请求。在客户端缓存 HTTP 响应是个好办法。
m. 缓存可重复的 HTTP 请求和响应
如果有必要,可以让浏览器智能地缓存 HTTP 请求及其响应。除此之外,它还为缓存的每一项数据提供 TTL(Time-To-Live)。这样,web 应用程序只在第一次需要连接服务器,以后就从缓存中获取响应。这不仅减少了服务器的负载,而且让客户端应用程序响应速度更快。该方案相对来说易于实现,因为只需要在请求中添加 HTTP 标头。浏览器将解释这些内容并负责从其自身的缓存返回数据或把请求路由到服务器。
到目前为止,我们已经解释了扩展 web 应用程序的几种选择。但是,几乎所有的应用程序都需要连接到数据库或服务器。当应用程序的负载增加时,通常会影响到数据库。与 web 应用程序一样,数据库每秒能接受的请求是有限的。不仅如此,SQL 数据库实例能存储的数据量也有上限。因此,需要扩展数据库。那么,如何扩展数据库呢?
2. 扩展数据库
我们用于扩展 web 应用程序的大多数原则都适用于扩展数据库,比如垂直扩展和水平扩展、缓存和复制。我们将一一解释它们,从简单到复杂,逐步深入。
提高数据库响应速度最简单的方法是利用数据库的内置特性。 我说的是缓存数据。
a. 缓存数据查询
SQL 数据库有个很好的数据缓存特性:缓冲区缓存。它允许在内存中缓存最频繁的查询。因此,数据访问速度更快。
缓存查询受限于可用内存的大小。当缓存无法为大量查询带来好处以及需要查询大型表格时,我们需要尽可能快地检索数据。这个时候需要使用索引!
b. 数据库索引
根据 ID 从表格中检索数据需要遍历几乎所有行,因为 ID 是无序主键。ID 为 5 的客户信息可能位于第 7 行。如果使用了索引,它将位于第 5 行。因此,如果我们确切地知道在哪里能够找到所需的信息,就无需遍历整个表。
即使使用了索引,也许还达不到所需的响应时间,可能是因为 SQL 查询没有经过优化,所以我们需要优化查询。
c. 存储过程和 ORM
性能测试显示,存储过程比 SQL 代码或 ORM 的查询更快,因为它们在数据库中经过预编译。这里存在一个权衡,因为另一方面,ORM 更容易使用,而且可以处理多个数据库,甚至可以优化 SQL 查询。我们可以把两者混合起来使用以获得最佳效果。
如果达到了单个数据库的上限,那么为什么不创建多个数据库实例呢?复制可以基于多种方式。我们从基于读或读写操作开始吧。
d. 复制数据库
SQL 查询不是读数据就是写数据。那么工程师可能会问:为什么不在一个数据库中写入,然后从另一个数据库读出呢?这样就可以通过在两个数据库而不是一个数据库实现负载均衡,可以将负载减少一半。写入数据库将负责更新读取数据库,这样两个数据库就拥有几乎相同的数据。
在 web 应用程序中,当我们想做的不只是复制实例时,可以把应用程序分解成若干小组件。那么我们可以把同样的逻辑应用在数据库上吗?复制数据库的另一个方式是基于拆分数据表。这叫做分区或分片。我们从分区开始讲。
e. 垂直拆分(分区)
分区把一张表分成多张表,每张表拥有的列更少一些。包含 20 列数据的客户表格将被分成两张或更多张表。第一张表将拥有列 1 到列 7 的数据,而第二张表将拥有列 8 到列 20 的数据。当然,每张表都包含了主键,用于连接这两张表。如果只需要前 7 列的数据,那么这种拆分方式就会非常有用。由于它返回的数据列更少,所以运行时间也更短。这两张表可以放在同一个数据库中或者两个独立的数据库中。SQL 数据库为此提供了一些特性,能够识别从哪个分区获取需要的数据。
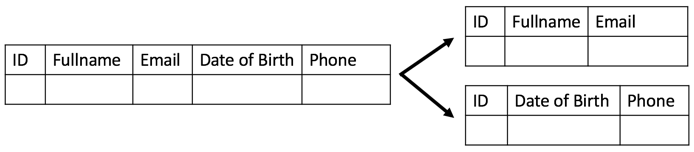
垂直分割表格
在考虑使用垂直分区时要慎重,因为如果要对数据进行分析,需要连接来自多个分区的数据。
我们通过拆分列对表格进行垂直拆分。那么,我们能否按行来拆分表格?这就是分片。
f. 水平拆分(分片)
分片把一张表分成多张表,每张表拥有相同数量的列,但更少的行。比如,客户表可以分成 5 张更小的表,每张表代表了一组客户。了解客户数据所在的位置有助于将查询定向到正确的分区,这样就可以处理更少的行。较小的表可以位于同一个或不同的 SQL 实例中,与垂直分区一样。水平分片和垂直分区可以混合使用。
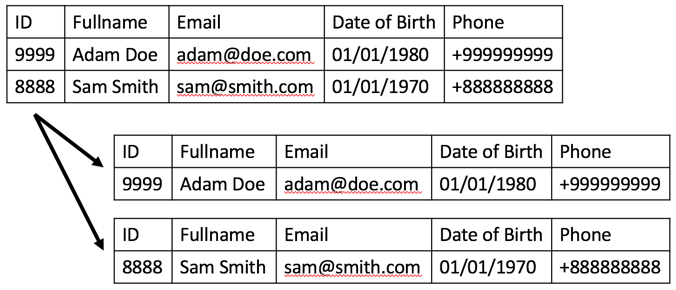
水平拆分表
表应该进行分区,以便查询引用尽可能少的表。否则,过多的合并查询(在查询时用于逻辑合并表)会影响性能。
到目前为止,我们已经看到基于列或行的表拆分。但是,我们能否把表分成一组表?我们来看看 DDD。
g. 领域驱动设计(DDD)
我们根据上下文或领域把 web 应用程序分成更小的微服务。同样的道理也可以应用于 DDD。这样,每个领域有自己的一组表:用于支付、评价的表,等等。
设想一下,现在每个微服务在同一个容器中都有自己的领域数据表。
DDD 的目标不是扩展数据库,但应用 DDD 就会得到这样的结果。但如果不是在项目开始阶段就进行设计,那么,在后续可能需要进行大量的源码修改。
如果 SQL 数据库还不足以处理所有的负载呢?那么,为什么不试试 NoSQL?
h. Azure Cosmos DB 和 Azure Tables(NoSql 数据库)
SQL 数据库以 schema 和表之间的关系为基础,这是导致其无法无限扩展的核心问题。另一方面,NoSQL 数据库用键值对的形式存储数据,不需要 schema,也不需要表间关系。因此,表可以进行无限的水平拆分。
NoSQL 消除了表间关系,但仍然可以做些调整来建立关系,不过不推荐这么做。
结语
在云端扩展应用程序不只是架构师的责任,开发人员也需要考虑无状态问题,数据库管理员需要考虑数据库分区。其他需要考虑重要事项:指标和分析。因为这些能够告诉我们是否需要进行垂直扩展还是水平扩展,以及哪些东西需要扩展。
英文原文:https://medium.com/devopslinks/scaling-applications-in-the-cloud-52bb6dfbac4e

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论