几十年来,编排软件在集群启动和管理中发挥了重要作用。从以往的 SunCluster、PSSP 和社区解决方案(如 CFEngine)等解决方案至今,同时启动诸多资源来支持大型并行应用程序的需要始终是高性能计算 (HPC) 环境的重要组成部分。AWS 拥有许多在 AWS 上运行集群工作负载的云原生方法,但是在将工作负载迁移到 AWS 时,必不可少的第一步或许就是需要重现或复制与数据中心内当前运行的环境类似或几乎相同的环境。
如果您可以使用 AWS 云原生资源构建熟悉的集群环境,结果会怎样呢?
今天,我们宣布推出 AWS ParallelCluster,这是一款由 AWS 支持的开源集群管理工具,使科学家、研究人员和 IT 管理员可以轻松地在 AWS 云中部署和管理高性能计算 (HPC) 集群。借助 AWS ParallelCluster,可以利用许多 AWS 云原生产品来启动运行 HPC 工作负载的人员应该十分熟悉的集群环境。例如:AWS CloudFormation、AWS Identity and Access Management (IAM)、Amazon Simple Notification Service (Amazon SNS)、Amazon Simple Queue Service (Amazon SQS)、Amazon Elastic Compute Cloud (Amazon EC2)、Amazon EC2 Auto Scaling、Amazon Elastic Block Store (Amazon EBS)、Amazon Simple Storage Service (Amazon S3) 和 Amazon DynamoDB。
AWS ParallelCluster 通过 Python Package Index (PyPI) 发布,可以通过 pip 安装。它无需额外费用,您只需要为运行应用程序所需的 AWS 资源付费即可。ParallelCluster 利用 CloudFormation 构建您的集群环境。CloudFormation 就是您用于仅启动一个实例、VPC 或 S3 存储桶的服务,只不过现在是用它来启动整个 HPC 集群环境。
很多人都非常熟悉 CfnCluster。ParallelCluster 使用了 CfnCluster 的构建代码,然后我们将其扩展为包含新特性、功能,当然还包含了错误改进和修复。如果您之前就使用过 CfnCluster,我们建议您根据具体情况开始使用 ParallelCluster,然后仅使用 ParallelCluster 创建新的集群。您可以将现有的 CfnCluster 配置文件与 ParallelCluster 结合使用。(虽然您仍然可以使用 CfnCluster,但该服务已停止开发。)
ParallelCluster 初始版本包含 CfnCluster 没有的一些重要功能,包括:
开始使用
喝杯咖啡提提神,让我们开始吧!
您需要准备好:
文档。
aws-parallelcluster GitHub 存储库(我们稍后将展示代码编辑和 pull 请求)。
决策时间 1。您可以在任何能够接入互联网的位置使用 ParallelCluster,但是需要 AWS API 密钥,或者需要设置 IAM 角色并将其分配给实例以启动集群所需的资源。在这篇博文中,我假设您使用的是 Linux 或 MacOS 操作系统,具有管理员权限,并且拥有 API 密钥访问权限。如果您对使用 IAM 角色有疑问,请与 AWS 解决方案架构师联系。
在安装 ParallelCluster 之前,我要确保自己能使用 AWS CLI 访问控制台。要安装 AWS CLI,可以按照安装 AWS 命令行界面中的步骤操作;如果要在 Python 虚拟环境中安装,可以按照在虚拟环境中安装 AWS 命令行界面中的方法操作。我更喜欢使用 Python 虚拟环境处理所有任务。
对于想使用 Python 虚拟环境的人来说,可选的第一步如下:
[duff]$ virtualenv ~/Envs/pcluster-virtenv[duff]$ source ~/Envs/pcluster-virtenv/bin/activate(pcluster-virtenv) [duff]$
复制代码
现在,我们通过创建存储桶来安装 AWS CLI 并验证其功能:
(pcluster-virtenv) [duff]$ pip install --upgrade awscli(pcluster-virtenv) [duff@]$ aws configureAWS Access Key ID []: <aws_access_key>AWS Secret Access Key []: <aws_secret_access_key>Default region name []: us-east-1Default output format []: json(pcluster-virtenv) [duff]$ aws s3 mb s3://duff-parallelclustermake_bucket: duff-parallelcluster
复制代码
我已安装、设置 AWS CLI,并验证了它的功能。现在我们来安装 ParallelCluster。
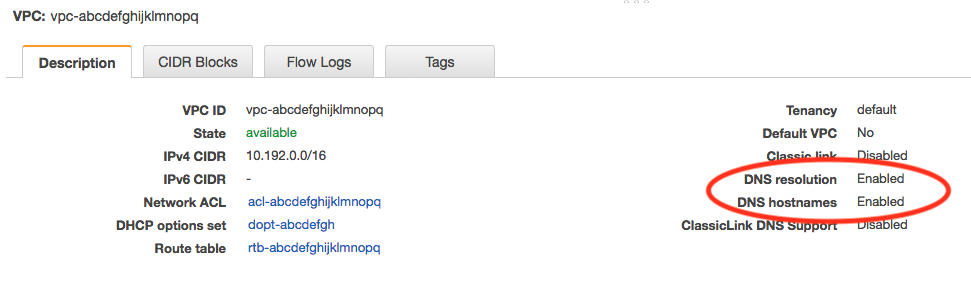
决策时间 2。 ParallelCluster 要使用的 VPC 必须设置为 DNS Resolution = yes 和 DNS Hostnames = yes。此外,其 DHCP 选项必须根据区域设置正确的域名,详见此文档中的定义:VPC DHCP 选项。将要使用的子网必须能够接入互联网,您可以通过多种方法来启用互联网连接。 在这篇博文中,我将使用公共子网(附加了 IGW 并路由到互联网的子网),但只要子网路由到互联网(例如通过 NAT 网关或代理服务器),您就可以使用专用子网。
您可以转到控制台并查看配置来验证 VPC 设置,您应该看到以下内容:
现在,我将使用之前设置好的虚拟环境安装 ParallelCluster:
(pcluster-virtenv) [duff]$ pip install aws-parallelcluster... output snipped...Successfully installed aws-parallelcluster-2.0.0rc1 ...
复制代码
我需要首先配置 ParallelCluster,之后才能启动集群。请注意,我将“AWS Access Key ID”(AWS 访问密钥 ID)和“AWS Secret Access Key ID”(AWS 秘密访问密钥 ID)留空,因为我已使用 AWS CLI 设置进行了相应配置。另外,由于我们想帮助您切实简化操作,所以我们会显示您的账户中可能的值:
(pcluster-virtenv) [duff@]$ pcluster configureCluster Template [default]:AWS Access Key ID []: <blank>AWS Secret Access Key ID []: <blank>Acceptable Values for AWS Region ID: ap-south-1 eu-west-3 eu-west-2 eu-west-1 ap-northeast-2 ap-northeast-1 sa-east-1 ca-central-1 ap-southeast-1 ap-southeast-2 eu-central-1 us-east-1 us-east-2 us-west-1 us-west-2AWS Region ID []: us-east-1VPC Name [public]:Acceptable Values for Key Name: <blank> duff_key_us-east-1Key Name []: duff_key_us-east-1Acceptable Values for VPC ID: vpc-12345678901234567 vpc-abcdefghigjlmnopqVPC ID []: vpc-abcdefghigjlmnopqAcceptable Values for Master Subnet ID: subnet-abcdefghigjlmnop1 subnet-abcdefghigjlmnop2 subnet-abcdefghigjlmnop3 subnet-abcdefghigjlmnop4 subnet-abcdefghigjlmnop5 subnet-abcdefghigjlmnop6Master Subnet ID []: subnet-abcdefghigjlmnop1
复制代码
我们来看看这段代码的作用。 它创建了 ~/.parallelcluster/config 文件,下面我们用 cat 命令显示这个文件的内容。
(pcluster-virtenv) [duff]$ cat ~/.parallelcluster/config[aws]aws_region_name = us-east-1
[cluster default]vpc_settings = publickey_name = duff_key_us-east-1
[vpc public]master_subnet_id = subnet-abcdefghigjlmnop1vpc_id = vpc-abcdefghigjlmnopq
[global]update_check = truesanity_check = truecluster_template = default
[aliases]ssh = ssh {CFN_USER}@{MASTER_IP} {ARGS}
复制代码
ParallelCluster 默认为所有配置参数使用 ~/.parallelcluster/config 文件。您可以在 github 存储库中看到示例配置文件 site-packages/aws-parallelcluster/examples/config。该配置文件包含几个部分(如果您是 Python 程序员,我们使用的是 ConfigParser)。每个部分都有一组用于启动集群的参数。如果我粗心大意地将一个配置参数放到了错误的部分,则系统会静默忽略该参数,而我会茫然不解究竟发生了什么。如果未在配置文件中指定参数,则使用默认值。
目前,ParallelCluster 支持三种调度程序:sge、torque 和 slurm。默认程序是 sge,这也是我要使用的调度程序。
目前,我要在配置文件中作出的唯一更改就是在 VPC 部分添加 SSH 源位置 ssh_from。默认情况下,我们允许来自任意源 IP (0.0.0.0/0) 的 SSH 入站请求,而我希望将此限制为仅允许我的 IP 地址。我建议您通过添加 IP 地址或可信 CIDR 块(例如 10.10.0.0/16)来执行类似操作。我已经更新了我的 [vpc public] 部分:
[vpc public]master_subnet_id = subnet-abcdefghigjlmnop1vpc_id = vpc-abcdefghigjlmnopqssh_from = 11.22.33.44/32
复制代码
现在我们已经对配置文件有了一定的了解,也知道了如何添加配置参数,我们来使用 create 命令启动第一个集群:
(pcluster-virtenv) [duff]$ pcluster create hello-cluster1
复制代码
开始创建集群时,我们会在资源启动时看到状态更新。我希望查看启动一个集群需要多长时间,所以我要使用 time:
(pcluster-virtenv) [duff]$ time pcluster create hello-cluster1Beginning cluster creation for cluster: hello-cluster1Creating stack named: parallelcluster-hello-cluster1Status: parallelcluster-hello-cluster1 - CREATE_IN_PROGRESS
复制代码
在集群创建完成时,我同时获得了公共和私有 IP 地址以及供登录时使用的用户名。此外由于我使用了 time,我可以看到集群的创建用了 8 分 33 秒的时间:
MasterPublicIP: 35.153.251.20ClusterUser: ec2-userMasterPrivateIP: 172.31.0.14
real 8m33.425suser 0m2.620ssys 0m0.353s
复制代码
我们使用 ParallelCluster 随附的内置 ssh 别名 pcluster ssh <cluster_name> 登录,看看有哪些集群资源可用。
(pcluster-virtenv) [duff@]$ pcluster listhello-cluster1
(pcluster-virtenv) [duff@]$ pcluster ssh hello-cluster1The authenticity of host '35.153.251.20 (35.153.251.20)' can't be established.ECDSA key fingerprint is SHA256:u9+A0i6Y94JcRGYW8eyi5e4N+iiNtpPTPAwPY5PQcWk.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added '35.153.251.20' (ECDSA) to the list of known hosts.Last login: Sun Nov 11 20:12:12 2018
__| __|_ ) _| ( / Amazon Linux AMI ___|\___|___|
https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/
[ec2-user@ip-172-31-0-14 ~]$ qhostHOSTNAME ARCH NCPU NSOC NCOR NTHR LOAD MEMTOT MEMUSE SWAPTO SWAPUS----------------------------------------------------------------------------------------------global - - - - - - - - - -ip-172-31-10-95 lx-amd64 2 1 1 2 0.02 3.7G 156.2M 0.0 0.0ip-172-31-13-199 lx-amd64 2 1 1 2 0.02 3.7G 156.8M 0.0 0.0
复制代码
在上面的输出中,您可以看到已经有一个实例集群在运行。默认情况下,我们会使用 t2.micro 作为实例类型,并且由于启用了超线程,我们会看到每个实例具有两个 CPU 和一个内核。
我们提交一个简单的 hostname 作业,它会使用 mpirun 命令显示 ParallelCluster 的 AutoScaling 功能。
[ec2-user@ip-172-31-0-14 ~]$ echo /usr/lib64/openmpi/bin/mpirun hostname | qsub -pe mpi 16Your job 1 ("STDIN") has been submitted[ec2-user@ip-172-31-0-14 ~]$ qstatjob-ID prior name user state submit/start at queue slots ja-task-ID----------------------------------------------------------------------------------------------------------------- 1 0.00000 STDIN ec2-user qw 11/11/2018 20:25:38 16
复制代码
现在,有一个作业请求的实例数量超出了我拥有的实例数量,这会导致系统发起扩展操作。当我有足够的实例时(本例中总共需要 8 个实例),作业就会运行。几分钟后,我拥有了资源,作业也已经运行完成:
[ec2-user@ip-172-31-0-14 ~]$ qhostHOSTNAME ARCH NCPU NSOC NCOR NTHR LOAD MEMTOT MEMUSE SWAPTO SWAPUS----------------------------------------------------------------------------------------------global - - - - - - - - - -ip-172-31-0-72 lx-amd64 2 1 1 2 0.11 3.7G 189.0M 0.0 0.0ip-172-31-10-65 lx-amd64 2 1 1 2 0.29 3.7G 189.2M 0.0 0.0ip-172-31-14-49 lx-amd64 2 1 1 2 0.11 3.7G 189.1M 0.0 0.0ip-172-31-2-78 lx-amd64 2 1 1 2 0.06 3.7G 189.4M 0.0 0.0ip-172-31-3-226 lx-amd64 2 1 1 2 0.11 3.7G 185.5M 0.0 0.0ip-172-31-4-248 lx-amd64 2 1 1 2 0.11 3.7G 186.2M 0.0 0.0ip-172-31-5-112 lx-amd64 2 1 1 2 0.08 3.7G 188.9M 0.0 0.0ip-172-31-5-50 lx-amd64 2 1 1 2 0.08 3.7G 189.0M 0.0 0.0[ec2-user@ip-172-31-0-14 ~]$ qstat
复制代码
既然作业已经运行完成,这些实例都已经进入空闲状态,现在会怎样? 如果实例已运行超过 10 分钟但未运行任何作业,我们将为您终止这些实例。10 分钟后,我再次查看 qhost:
[ec2-user@ip-172-31-0-14 ~]$ qhostHOSTNAME ARCH NCPU NSOC NCOR NTHR LOAD MEMTOT MEMUSE SWAPTO SWAPUS----------------------------------------------------------------------------------------------global - - - - - - - - - -[ec2-user@ip-172-31-0-14 ~]$ qstat
复制代码
实例已经终止,我不必为空闲的实例付费。扩展功能是可配置的。
好了。我已经使用许多 AWS 云原生资源启动了外观和行为方式都类似传统 HPC 环境的环境,其中包含一个 AutoScaling 集群,该集群可以在实例未使用时终止相应的实例。如何在不产生调度程序开销的情况下使用环境?
不妨了解一下 AWS Batch。
AWS Batch 根据提交的批处理作业的数量和具体资源需求,动态调整计算资源的最佳数量和类型(例如,CPU 或内存优化型实例)。
使用 AWS Batch,您不需要安装和管理用于运行作业的批处理计算软件或服务器集群,从而可以专注于分析结果和解决问题。AWS Batch 在所有 AWS 计算服务和功能(如 Amazon EC2 和 Spot 实例)中计划、调度和执行批处理计算工作负载。
所以现在我将启动一个 Batch 环境,让 ParallelCluster 为我完成所有工作。启动 AWS Batch 环境时,我们将利用更多 AWS 资源。例如,主实例上将启动 AWS CodeBuild、Amazon Elastic Container Registry (Amazon ECR) 和 NFS 服务器。
首先我要编辑配置文件:~/.parallelcluster/config,并将 [cluster default] 部分中使用的某些相同的参数添加到此部分。
[cluster awsbatch]scheduler = awsbatchkey_name = duff_key_us-east-1vpc_settings = public
复制代码
限制我已经定义了一个单独的集群模板,接下来可以启动一个单独的主实例,它既是我的批处理作业的 NFS 服务器,也是这些批处理作业的提交主机。现在我要创建一个集群,指定我的 awsbatch 集群。
(pcluster-virtenv) [duff@]$ pcluster create awsbatch --cluster-template awsbatchBeginning cluster creation for cluster: awsbatchCreating stack named: parallelcluster-awsbatchStatus: parallelcluster-awsbatch - CREATE_COMPLETEMasterPublicIP: 54.158.75.19BatchComputeEnvironmentArn: arn:aws:batch:us-east-1:070582714313:compute-environment/parallelcluster-awsbatchBatchJobQueueArn: arn:aws:batch:us-east-1:070582714313:job-queue/parallelcluster-awsbatchClusterUser: ec2-userMasterPrivateIP: 172.31.15.217ResourcesS3Bucket: parallelcluster-awsbatch-6wjsibr8elx9km0r
复制代码
在上面的输出中,您可以看到我已经成功创建了 AWS Batch 提交主机。下面我会登录查看其中的内容:
(pcluster-virtenv) [duff@]$ pcluster ssh awsbatchThe authenticity of host '54.158.75.19 (54.158.75.19)' can't be established.ECDSA key fingerprint is SHA256:/K8LQYyLliS0+Q7+BZtkhe6ChyM9Oz/RZz0aTCKJ3KQ.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added '54.158.75.19' (ECDSA) to the list of known hosts.Last login: Tue Nov 13 00:46:30 2018
__| __|_ ) _| ( / Amazon Linux AMI ___|\___|___|
https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/[ec2-user@ip-172-31-15-217 ~]$ awsbhostsec2InstanceId instanceType privateIpAddress publicIpAddress runningJobs------------------- -------------- ------------------ ----------------- -------------i-05af380e4950366d4 c4.xlarge 172.31.4.66 18.209.11.53 0
复制代码
可以看到,我有一个准备运行作业的 c4.xlarge 实例。下面我来运行一个 hello world 测试。
[ec2-user@ip-172-31-15-217 ~]$ awsbsub echo hello worldJob 2387b7f5-14c7-41c1-bbf8-c5e50017580a (echo) has been submitted.
复制代码
作业成功提交,状态从 RUNNABLE 变为 STARTING 再变为 RUNNING,然后是 SUCCEEDED 或 FAIL。
[ec2-user@ip-172-31-15-217 ~]$ awsbstatjobId jobName status startedAt stoppedAt exitCode------------------------------------ --------- -------- ----------- ----------- ----------2387b7f5-14c7-41c1-bbf8-c5e50017580a echo RUNNABLE - - -[ec2-user@ip-172-31-15-217 ~]$ set -o vi[ec2-user@ip-172-31-15-217 ~]$ awsbstatjobId jobName status startedAt stoppedAt exitCode------------------------------------ --------- -------- ----------- ----------- ----------2387b7f5-14c7-41c1-bbf8-c5e50017580a echo STARTING - - -
[ec2-user@ip-172-31-15-217 ~]$ awsbstatjobId jobName status startedAt stoppedAt exitCode------------------------------------ --------- -------- ------------------- ----------- ----------2387b7f5-14c7-41c1-bbf8-c5e50017580a echo RUNNING 2018-11-13 00:52:31 - -
复制代码
现在可以看到我的作业正在运行,我还可以使用 awsbout 命令查看:
[ec2-user@ip-172-31-15-217 ~]$ awsbout 2387b7f5-14c7-41c1-bbf8-c5e50017580a2018-11-13 00:52:31: Starting Job 2387b7f5-14c7-41c1-bbf8-c5e50017580a2018-11-13 00:52:31: hello world
复制代码
作业完成后,可以使用 awsbstat 命令查看其状态:
[ec2-user@ip-172-31-15-217 ~]$ awsbstat -s SUCCEEDEDjobId jobName status startedAt stoppedAt exitCode------------------------------------ --------- --------- ------------------- ------------------- ----------2387b7f5-14c7-41c1-bbf8-c5e50017580a echo SUCCEEDED 2018-11-13 00:52:31 2018-11-13 00:53:02 0
复制代码
使用 AWS ParallelCluster,您可以利用 AWS 云的优势,同时保有一个自己熟悉的集群环境。我们对 ParallelCluster 的推出非常开心,也热切期待听到大家的反馈意见!
作者简介:
!
Jeff Barr
AWS 首席布道师; 2004 年开始发布博客,此后便笔耕不辍。
原文链接:
https://amazonaws-china.com/cn/blogs/china/aws-parallelcluster/

















评论