

HDFS 作为运行在通用硬件上的分布式文件系统,和现有的分布式文件系统既有很多的共同点,也存在很多的差异。本文从 HDFS 是什么开始介绍,包括了 HDFS 架构、HDFS 的读写、各个组件的作用、具体操作以及优缺点。给出了 HDFS 在分布式存储上的具体方案,可以使读者快速、清晰的理解 HDFS 系统。
1 主要内容
1.HDFS 是什么?是干什么用的?
2.HDFS 的架构是怎么样的?
3.HDFS 的怎样进行读写?副本怎样放置?
4.HDFS 各个组件的作用?
5.HDFS 的文件操作命令有哪些?
6.HDFS 的优缺点是什么?
2 引言
有这样一个需求:
由于公司某业务 mysql 服务器过保,为防止数据丢失,需要备份 mysql 数据库,这些库目前已经只读,每个库约 1.5T,大概有 130 个库,共需要 200T 左右的空间,并且希望数据不易丢失,恢复数据速度快。
部分解决方案:
1)单机存储

有如下问题:
1.磁盘损坏或机器 down 机则无法下载;
2.单块磁盘的读写 io 会很高;
3.单块磁盘不能完整存储 3 个完整的库(存储大文件),只能存储 2 个,空间部分浪费;
4.平时如果不用做数据恢复,机器 cpu、内存等利用率低。
2)分布式存储
可选用分布式存储,如 HDFS、CEPH、S3 等等。
3 HDFS 是什么?是干什么用的?
HDFS(Hadoop Distributed File System)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS 是一个高度容错性的系统,适合部署在廉价的机器上。HDFS 能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS 放宽了一部分 POSIX 约束,来实现流式读取文件系统数据的目的。HDFS 在最开始是作为 Apache Nutch 搜索引擎项目的基础架构而开发的。HDFS 是 Apache Hadoop Core 项目的一部分。
首先来看看 Hadoop 架构,HDFS 为 Hadoop 其他组件提供存储支持。
直观对比 Linux 文件系统和 HDFS 文件系统(执行 ls 命令)。
Linux:
HDFS:
可以看出 HDFS 和 Linux 文件系统很类似,都是有权限、文件所属用户、用户所在的组、文件名称等,但是也有不同:HDFS 中的第 2 列表示副本数。
4 HDFS 的架构是怎么样的?
HDFS 架构如下:
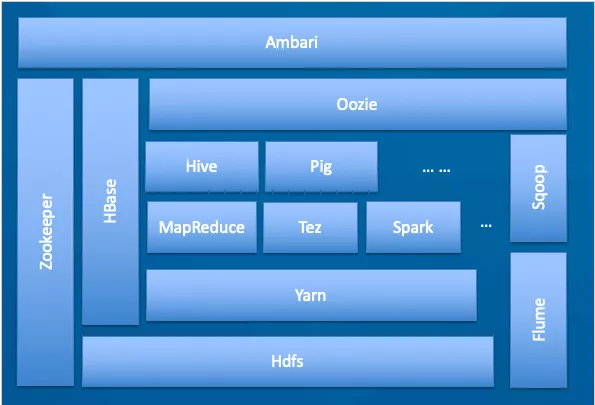
1.Client:客户端。
2.NameNode:master,它是一个主管、管理者,存储元数据,存储元数据格式会在后面介绍。
3.DataNode:slave,NameNode 下达命令,DataNode 执行操作并存储实际数据。
4.SecondaryNameNode:和 NameNode 不是主备关系。当 NameNode 挂掉的时候,它并不能马上替换 NameNode 提供服务。主要作用会在后面介绍。
5 HDFS 怎样进行读写
写文件
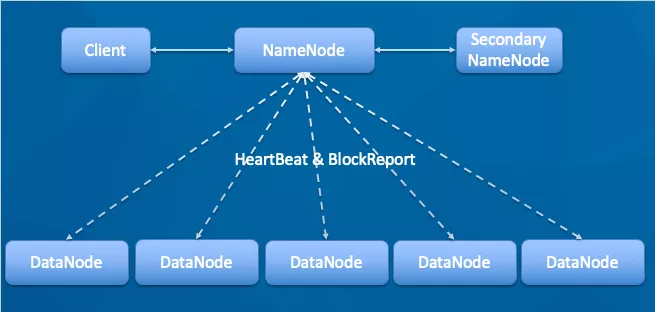
1.客户端调用 create 方法,创建一个新的文件;NameNode 会做各种校验,比如文件是否已经存在,客户端是否有权限等。
2.如果校验通过,客户端开始写数据到 DN(DataNode),文件会按照 block 大小进行切块,默认 128M(可配置),DataNode 构成 pipeline 管道,client 端向输出流对象中写数据,传输的时候是以比 block 更小的 packet 为单位进行传输,packet 又可拆分为多个 chunk,每个 chunk 都携带校验信息。
3.每个 DataNode 写完一个块后,才会返回确认信息,并不是每个 packet 写成功就返回一次确认。
4.写完数据,关闭文件。
读文件
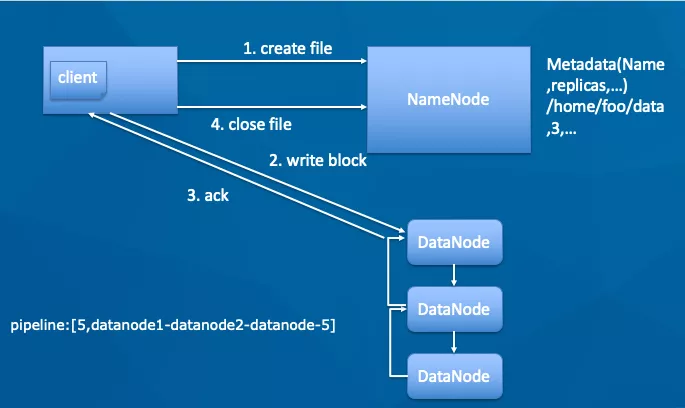
1.客户端调用 open 方法,打开一个文件。
2.获取 block 的 location,即 block 所在的 DN,NN(NameNode)会根据拓扑结构返回距离客户端最近的 DN。
3.客户端直接访问 DN 读取 block 数据并计算校验和,整个数据流不经过 NN。
4.读取完一个 block 会读取下一个 block。
5.所有 block 读取完成,关闭文件。
副本放置
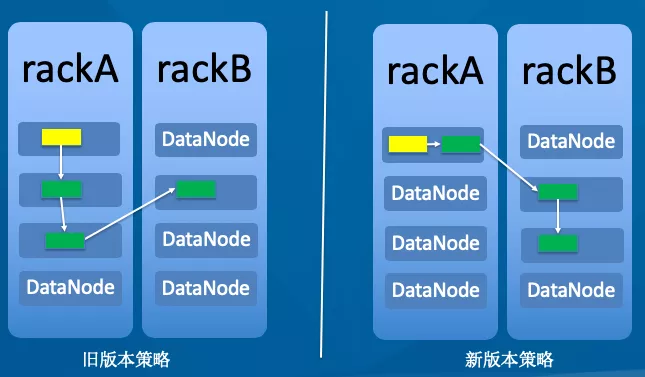
以经典的 3 副本为例(黄色方框表示客户端,绿色表示要写的 block),Hadoop 早期版本采用左边的放置策略,后期版本采用右边的放置策略放置副本。
图左:
副本 1:同机架的不同节点。
副本 2:同机架的另一个节点。
副本 3:不同机架的另一个节点。
如果还有其他副本:随机。
图右:
副本 1:同 Client 的节点。
副本 2:不同机架的节点。
副本 3:同第 2 副本相同机架的不同节点。
如果还有其他副本:随机。
两种策略的故障域都为机架,新版相对于旧版本,当本客户端再次读取新写的数据时,直接从本地读取,这样延迟最小,读取速度最快。
6 HDFS 各个组件的作用?
先大致看下启动流程:
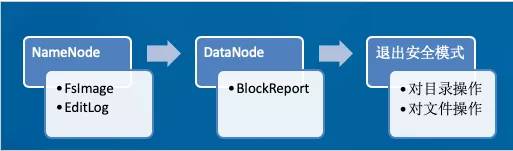
1.启动 NameNode,读取 FsImage 元数据镜像文件,加载到内存中;读取 EditLog 日志文件,加载到内存中,使当前内存中元数据信息与上次关闭系统时保持一致。
2.启动 DataNode,向 NameNode 注册,并向 NameNode 发送 BlockReport。
3.退出安全模式后,Client 可以对 HDFS 进行目录创建、文件上传等操作,改动的目录结构会记录在 EditLog 中,NameNode 的内存中的目录结构也会改变。
NameNode
1.管理 HDFS 的命名空间。
2.管理数据块(Block)映射信息。
3.配置副本策略。
4.处理客户端读写请求。
Fsimage 是一个二进制文件,格式如下:

FsImage 文件第 1 行为 image head,里面包含 image 的版本、文件和目录的个数等;第 2 行为一个目录格式(如果是目录,就是这种格式),包含了目录的路径、副本数、权限等,目录的 blocksize 都为 0;第 3 行为一个文件格式(如果是文件,则在 FsImage 存储的格式),文件和目录格式包含的字段差不多,多了 block 信息;通过加载此文件和 EditLog 日志文件来构建整个文件系统的目录结构。
通过观察 FsImage 文件,里面并没有 block 和 DN 的对应关系,它是如何查到块所对应的 DN 的呢?
block 和 DN 的对应关系并没有实际持久化,而是通过 DN 向 NN(NameNode)汇报,此过程为 BlockReport。通过 blockReport 构建 BlocksMap 的结构如下:
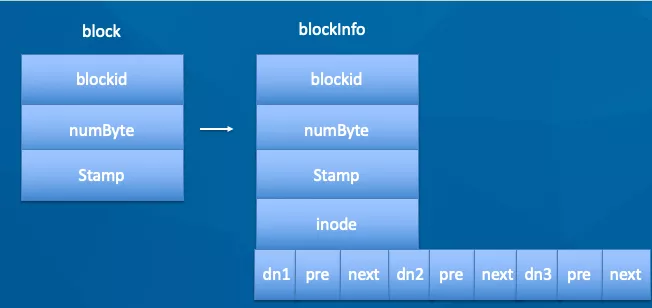
在 blockInfo 中保存了 block 所在的 DN 信息。
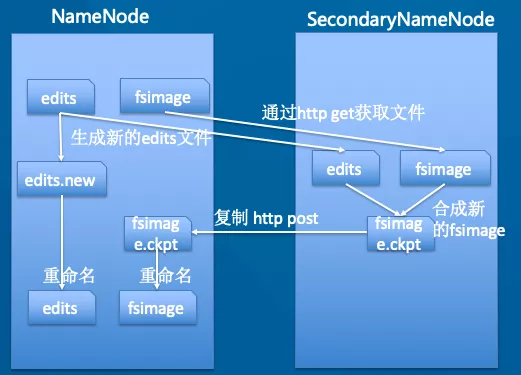
SecondaryNameNode
和 NameNode 并非主备关系,而是辅助 NN 进行合并 FsImage 和 EditLog 并起到备份作用。
7 HDFS 文件操作命令有哪些?
和 Linux 操作文件类似,只列出常见几个,和 Linux 命令的功能也是类似的,如:cp 即拷贝,rm 即删除等等。
在 HDFS 中,提供了 fsck 命令,用于检查 HDFS 上文件和目录的健康状态、获取文件的 block 块信息和位置信息等。
8 HDFS 的优缺点是什么?
最后根据以上内容总结 HDFS 优缺点如下:
优点:
支持海量数据的存储。
检测和快速应对硬件故障。
流式数据访问。
简化的一致性模型。
高容错性。
商用硬件。
缺点:
不能做到低延迟数据访问。
不适合大量的小文件存储。
不支持修改文件(HDFS2.x 开始支持给文件追加内容)。
不支持用户的并行写。
hadoop2.x 新特性 引入了 NameNode Federation,解决了横向内存扩展;引入了 Namenode HA,解决了 namenode 单点故障。
本文转载自公众号 360 云计算(ID:hulktalk)。
原文链接:
https://mp.weixin.qq.com/s/s-kOquVbIuJAMSQqkfmaAA

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论