
当我的笔记本电脑开始向我吐出文字时,我真的有一种感觉,世界即将再次发生变化。
AI 世界的一切都在以闪电般的速度发展。GPT-3 级别 AI 模型现已登陆笔记本电脑、手机和 Raspberry Pi。
上周五,一位名叫 Georgi Gerganov 的软件开发者创建了“llama.cpp”的工具,能够在 Mac 笔记本电脑上本地运行 Meta 最新的类 GPT-3 大语言模型 LLaMA。Georgi Gerganov 为大家打开了用消费级电子产品运行大模型的大门,之后不久,人们又找到了在Windows上运行LLaMA的办法。接着有人展示如何在Pixel 6手机上运行,最离谱的是连 Raspberry Pi 都宣布实验成功(尽管速度非常缓慢)。如果这种情况持续下去,也许我们即将迎来“能装进口袋的”ChatGPT 竞争对手。
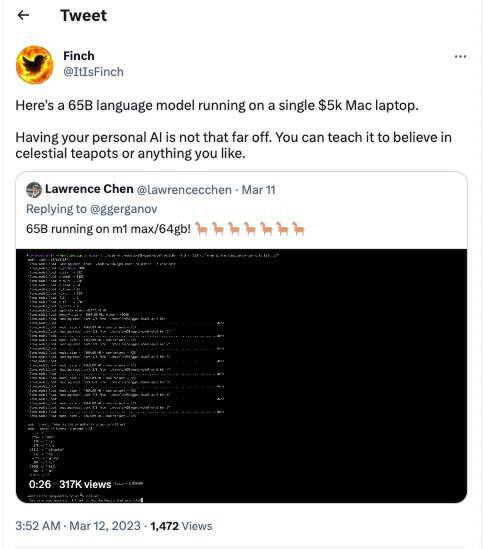
Georgi Gerganov 成功地让大家将 65B 的大语言模型运行在 5000 美元的笔记本电脑上
Georgi 是保加利亚索非亚的一名开源开发人员(根据他的 GitHub 个人资料)。在此之前,他还发布了whisper.cpp,OpenAI Whisper 语音识别模型的 C++移植版本。Whisper 是一个通用的开源语音识别模型,可以进行多语种语音识别,也可以进行语音翻译和语种识别,对应的人类职位就是速记员和转录员。Georgi 的工作使 Whisper 适用于大量新硬件,可能因此创造出很多新用例。
前几天他又对 LLaMA 做了同样的事情,再次发布了llama.cpp项目。他在自述文件中描述道:
主要目标是在 MacBook 上使用 4 比特位量化运行模型;同时适用于 x86;可运行在 CPU 上。
4 比特位量化(4-bit quantization support)是一种减小模型大小的技术,因此它们可以在功能较弱的硬件上运行。它还减少了磁盘上的模型大小——7B 模型减少到 4GB,13B 模型减少到不到 8GB。并且完全有效!
通常,运行 GPT-3 需要多块数据中心级 A100 GPU(而且 GPT-3 的权重也不公开)。但 LLaMA 之所以引发轰动,就是因为它能在单块高端消费级 GPU 上运行。现在,通过所谓“量化”技术对模型体量进行优化,LLaMA 已经能够在 M1 版 Mac 或者英伟达消费级 GPU 上跑起来。
事情发展得如此之快,我们甚至难以跟上最新发展进度。而且 Georgi 在 GitHub 的文件中说,完成这些工作只花费了“一个晚上”的时间。这种高效也震惊不少网友:“Georgi 真是个天才”。
打破运行大模型的种种限制
自从 ChatGPT 横空出世以来,人们就对这套 AI 模型的内置约束诟病不已。你只可以通过他们的 API 和 Web 界面访问 ChatGPT,但微软不会发布模型给任何人在他们自己的机器上运行。这些限制令 ChatGPT 无法讨论被 OpenAI 视为敏感内容的话题。于是乎,推出开源大语言模型(LLM)的梦想迅速发酵升温,人人都想要一套既能在本地运行以回避审查、也不必向 OpenAI 支付 API 费用的随身 AI。
另一方面就是“硬件”带来的限制,这些模型都很大,即使你可以获得 GPT-3 模型,你也无法在商品硬件上运行它——这些东西通常需要多个 A100 级 GPU,每个零售价超过 8,000 美元。
而根据彭博社最新消息,微软为大模型训练还打造了一台由数万个 A100 GPU 组成的大型 AI 超级计算机,成本或超过数亿美元。这些大公司对自己的 AI 基础设施投资让普通人望而生畏。
开源方案倒是存在(例如 GPT-J),但它们往往也需要大量的 GPU 内存和存储空间。其他开源替代品也差不多,根本无法在现有消费级硬件上重现 GPT-3 级别的性能。
这就要请出 LLaMA 了——一套参数范围从 7B 到 65B 的大语言模型(这里的 B 指“10 亿参数”,是存储在矩阵内的浮点数,表示模型“知晓”多少内容)。LLaMA 做出了令人振奋的声明,表示其模型体量更小,但在输出质量和速度方面完全可以与 OpenAI 的 GPT-3(为 ChatGPT 提供支持的基础模型)相媲美。之前 Meta 虽然发布了 LLaMA 开源代码,但仅只向认证研究人员开放“权重”(即神经网络中存储的、由训练得到的“知识”)。
以 LLaMA 为翼,振翅高飞
但 Meta 对 LLaMA 的限制并没有持续多久。就在 3 月 2 日,有人用种子文件的形式泄露了 LLaMA 的权重。自那之后,围绕 LLaMA 的开发就出现了爆发式增长。然后,Georgi 的llama.cpp项目出现了......
包括独立 AI 研究员 Simon Willison 在内的开发者们纷纷迫不及待地在自己电脑上运行了一把 LLaMA。
今天早上,我第一次在自己的笔记本电脑上运行了类 GPT-3 语言模型!
当我的笔记本电脑开始向我吐出文字时,我真的有一种感觉,世界即将再次发生变化。我本来以为还需要几年时间才能在我自己所拥有的硬件上运行 GPT-3 类模型,真没想到“未来”这么快就已经到来了。
Simon Willison 将这种情况与去年 8 月推出的开源图像合成模型 Stable Diffusion 相提并论,在博文中写道:“在我看来,去年 8 月的 Stable Diffusion 时刻开启了人们对于生成式 AI 的全面关注——而 11 月底发布的 ChatGPT 真正标志着 AI 新时代的开启。”“对于大语言模型(也就是 ChatGPT 采用的基础技术),Stable Diffusion 时刻已经再次来临。AI 技术已经很神奇了,但它将变得更神奇。”
下面来看 Willison 在 Hacker News 评论中列出的,关于 LLaMA 各重要节点的时间清单:
2023 年 2 月 24 日:Meta AI 公布 LLaMA。
2023 年 3 月 2 日:有人通过种子文件泄露了 LLaMA 模型。
2023 年 3 月 10 日:Georgi Gerganov 创建 llama.cpp,能够在 M1 版 Mac 上运行。
2023 年 3 月 11 日:Artem Andreenko 在一台 4 GB 内存的 Raspberry Pi 4 上成功运行了 LLaMA 7B,但速度很慢,每个令牌要消耗 10 秒。
2023 年 3 月 12 日:LLaMA 7B 成功登陆 NPX,一款 node.js 执行工具。
2023 年 3 月 13 日:有人在 Pixel 6 手机上运行了 llama.cpp,但速度同样很慢。
2023 年 3 月 13 日:斯坦福发布了 Alpaca 7B,这是 LLaMA 7B 的指令微调版本,“其行为类似于 OpenAI 的 text-davinci-003”,但可以在性能更弱的硬件上运行。
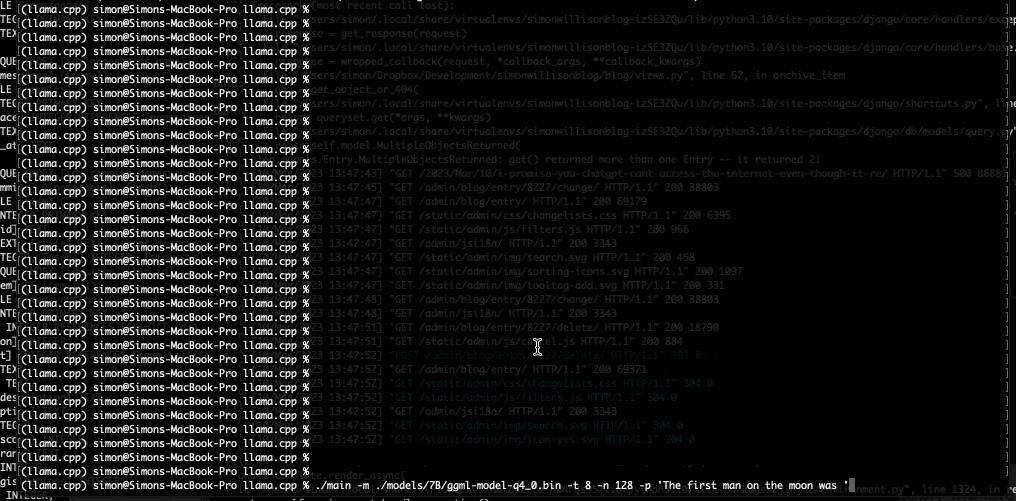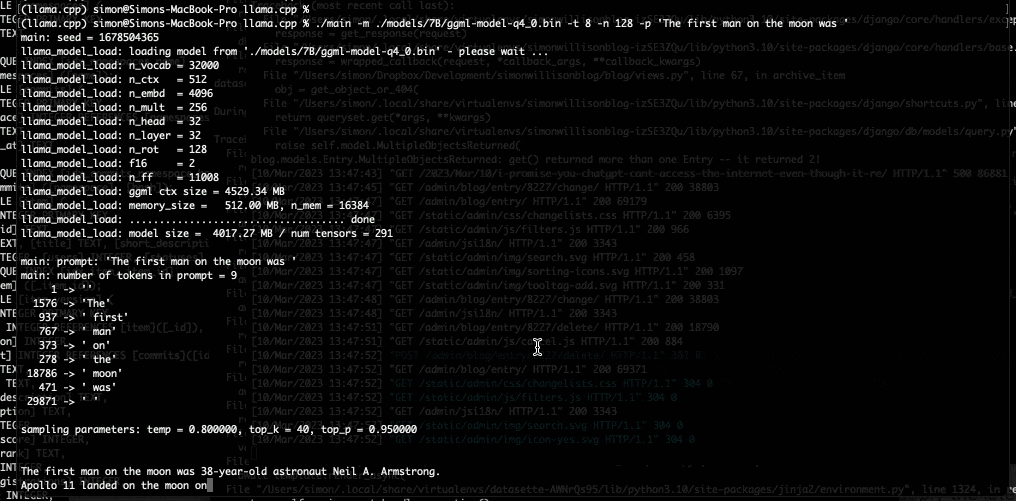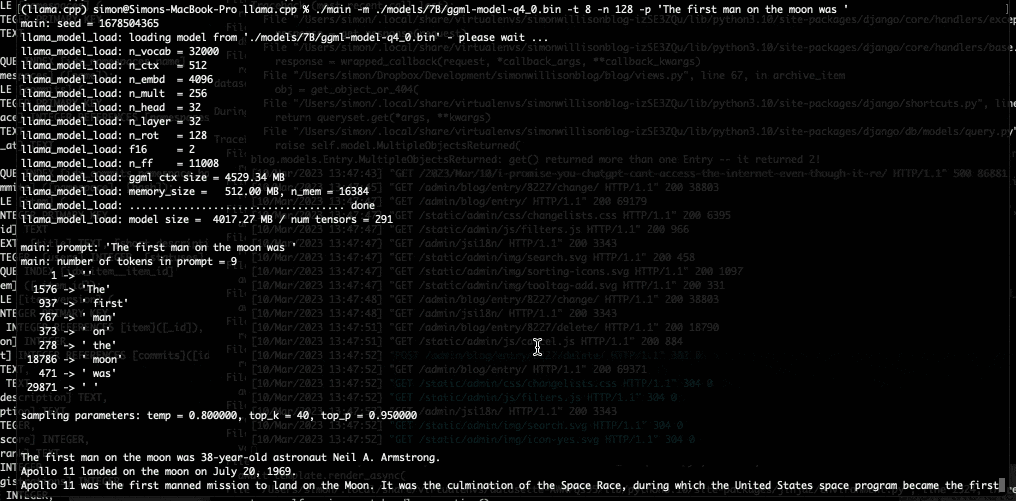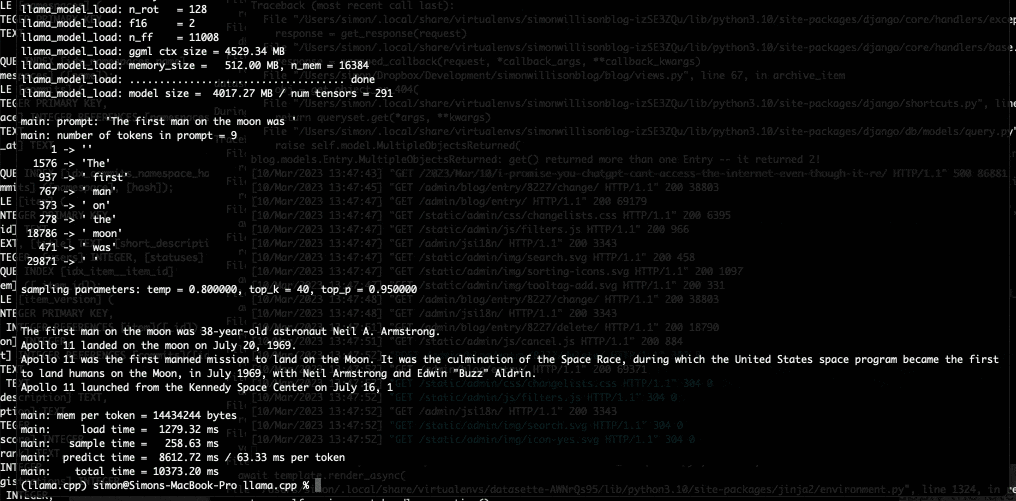
在拿到 LLaMA 的权重之后,我们也按照 Willison 整理的说明得到了 7B 参数的版本,并在一台 M1 Macbook Air 上运行了起来,且速度还算可以。大家可以在命令行脚本的方式通过提示进行调用,LLaMA 则会尽可能以合理方式给出回应。
MacBook Air 通过 llama.cpp 运行 LLaMA 7B 模型的截屏
但目前还不清楚量化处理对于模型的输出质量有多大影响。在测试中,LLaMA 7B 的 4-bit 量化在 MacBook Air 上的运行效果令人印象深刻,但仍无法与 ChatGPT 相比肩。也许更好的提示技术可以带来更好的结果。
另外,由于代码和权重已经全面外流,相信优化和微调将很快出现(尽管 LlaMA 也提出了相当严格的使用条款)。斯坦福大学此次发布的 Alpaca,就证明微调(针对特定目标的额外训练)可以提高性能。而且 LLaMA 毕竟还处于开发早期,后续肯定有不错的提升空间。
截至本文撰稿时,在 Mac 上运行 LLaMA 仍然相当繁琐复杂。你需要安装 Python 和 Xcode,并熟悉命令行的各项操作。好在 Willison 已经整理出详尽的分步说明(https://til.simonwillison.net/llms/llama-7b-m2)。而且随着开发者不断编写代码,相信 LLaMA 会变得越来越易用。
至于目前的这一切到底有什么意义,还没人说得清楚。有些人担心 AI 的“便携化”会制造大量垃圾邮件和错误信息,但 Willison 却认为“AI 的出现已成现实,我们的首要任务应该是找到更具建设性的使用方法。”
所以还是老句老话,“世界上唯一不变的,就是变化。”
参考链接:
https://github.com/ggerganov/llama.cpp




